



Apache Paimon
1. Paimon 概述
1.1 什么是 Apache Paimon?
Apache Paimon 是一个开源的流式数据湖存储系统,专门为实时数据处理而设计。它结合了数据湖的灵活性和数据仓库的性能,为现代大数据应用提供了一个统一的存储解决方案。
Apache Paimon 的架构(来自官网):
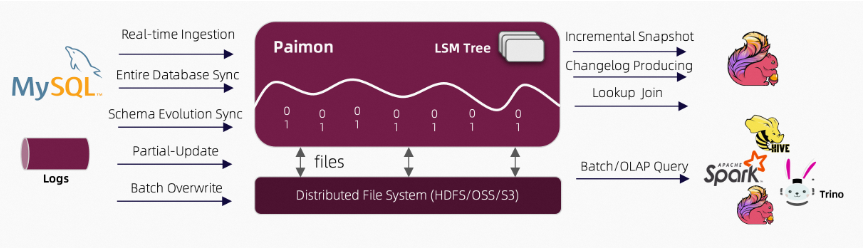
如上图所示架构:
读/写: Paimon 支持多种数据读/写方式和 OLAP 查询。
- 对于读取操作,它支持数据消费。
- 从历史快照(批量模式)
- 从最新的偏移量(在流媒体模式下)开始,或者
- 以混合方式读取增量快照。
- 对于写入操作,它支持
- 从数据库变更日志(CDC)进行流式同步
- 从离线数据批量插入/覆盖数据。
**生态系统:**除了 Apache Flink 之外,Paimon 还支持被其他计算引擎读取,如 Apache Hive、Apache Spark 和 Trino。
内部的:
- 在底层,Paimon 将列式文件存储在文件系统/对象存储中。
- 文件的元数据保存在清单文件中,提供大规模存储和数据跳过功能。
- 对于主键表,使用 LSM 树结构来支持大量数据更新和高性能查询。
1.1.1 Paimon 的核心价值
对于初学者来说,Paimon 解决了以下关键问题:
- 实时数据处理:传统数据湖(如Hive)主要面向批处理,而Paimon支持实时数据流处理
- 简化查询:无需编写复杂的SQL窗口函数即可查询最新数据
- 版本控制:内置类似Git的版本管理功能,支持数据回滚和时间旅行
- 统一存储:同一份数据同时支持流处理和批处理
统一存储 (https://paimon.apache.org/docs/1.0/concepts/overview/#unified-storage)
对于像 Apache Flink 这样的流式引擎,通常有三种类型的连接器:
- 消息队列(例如 Apache Kafka)在本管道的源阶段和中间阶段均有使用,以保证延迟保持在几秒以内。
- OLAP 系统(例如 ClickHouse)以流式方式接收处理后的数据,并响应用户的临时查询。
- 批量存储,例如 Apache Hive,支持传统批量处理的各种操作,包括
INSERT OVERWRITE:
Paimon 提供表抽象功能。它的使用方式与传统数据库并无二致:
- 在
batch执行模式下,它就像一个 Hive 表,支持各种批量 SQL 操作。查询该表即可查看最新快照。 - 在
streaming执行模式下,它就像一个消息队列。查询模式下,它就像从消息队列中查询流式变更日志,其中历史数据永不过期。
1.1.2 Paimon 与传统数据湖的对比
| 特性 | 传统数据湖(Hive) | Apache Paimon |
|---|---|---|
| 数据处理模式 | 批处理为主 | 流批一体 |
| 实时性 | 延迟较高(小时/天级) | 低延迟(秒/分钟级) |
| 查询复杂度 | 需要复杂SQL窗口函数 | 直接查询最新数据 |
| 版本管理 | 需要外部工具 | 内置Tag和快照机制 |
| 存储效率 | 中等 | 高(LSM树优化) |
1.2 为什么选择 Paimon?
1.2.1 适用场景
Paimon 特别适合以下应用场景:
- 实时报表系统:需要分钟级甚至秒级更新的业务报表
- 实时监控平台:业务指标的实时计算和展示
- 推荐系统:基于最新用户行为的实时推荐
- 数据质量监控:实时检测数据质量问题
- 数据审计追踪:完整的数据变更历史记录
1.2.2 技术优势
- 高性能写入:基于LSM树结构,支持高吞吐数据摄入
- 高效查询:快照机制直接定位最新数据,避免全表扫描
- 灵活扩展:支持水平扩展,适应大数据量场景
- 生态兼容:与Flink、Spark等大数据框架深度集成
2. Paimon与传统数据仓库hive的区别
2.1 基础概念
2.1.1 数据湖 vs 数据仓库
数据湖:存储原始数据的存储库,支持各种格式的数据,适合探索性分析
数据仓库:结构化数据的存储系统,适合报表和BI分析
Paimon:结合了两者的优势,既支持灵活的数据格式,又提供高性能的查询能力
2.1.2 流处理 vs 批处理
批处理:处理一批静态数据,如夜间ETL作业
流处理:实时处理连续的数据流,如实时监控
Paimon:支持两种处理模式,实现流批一体
3. Paimon 存储文件结构
3.1 整体文件布局
Apache Paimon 采用流式数据湖存储技术,基于 LSM(Log-Structured Merge-tree)树结构来存储数据,支持高吞吐、低延迟的数据摄入和实时查询。
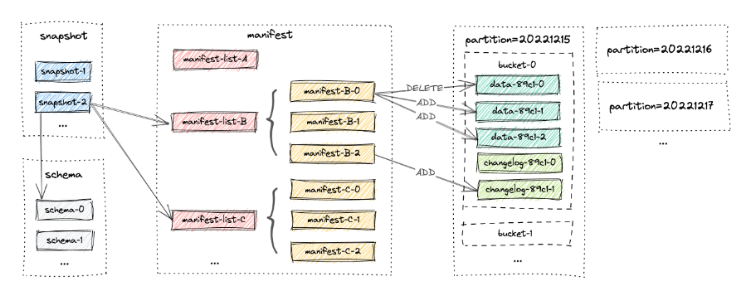
Paimon 表的存储目录结构如下:
以前paimon版本(<0.7)
表根目录/
├── snapshot/ # 快照目录
│ ├── snapshot-1 # 快照文件
│ ├── snapshot-2
│ └── ...
├── manifest/ # 清单文件目录
│ ├── manifest-list-1 # 清单列表文件
│ └── ...
├── data/ # 数据文件目录
│ ├── bucket-0/ # 桶0的数据文件
│ ├── bucket-1/ # 桶1的数据文件
│ └── ...
├── metadata/ # 元数据目录
│ ├── schema/ # 表结构定义
│ ├── tags/ # 标签目录
│ └── ...
└── changelog/ # 变更日志目录(可选)
现在版本paimon1.0.1
tbl/
├── bucket-*/ ← 数据文件
├── manifest/ ← 元数据:文件清单
├── schema/ ← 元数据:表结构版本
├── snapshot/ ← 元数据:快照指针
├── index/ ← 可选索引文件
└── tag/ ← 可选永保别名
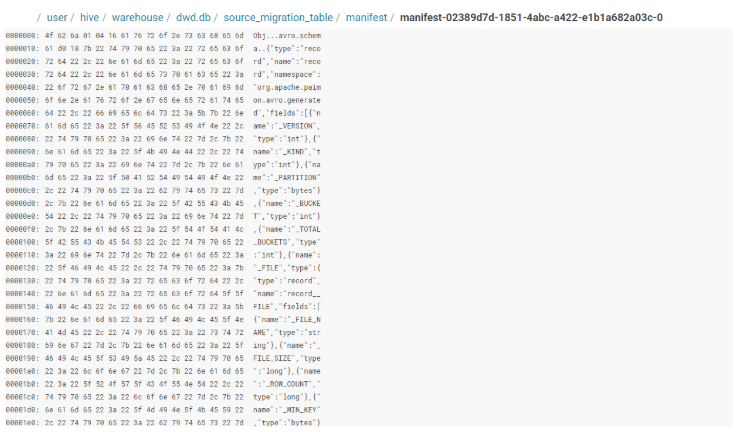
Manifest文件(数据文件的清单):
Manifest文件是Paimon用来存储元数据信息的文件,记录了数据文件的路径、分区信息、增量变更(添加或删除)、行数等。它是Paimon元数据管理的核心组件。
清单文件记录了数据文件的元数据信息,包括:
- 数据文件路径
- 数据统计信息(最小值、最大值等)
- 文件大小和记录数
- 数据文件的状态(新增、删除、修改)
Manifest-list文件(Manifest 的清单):
Manifest-list是一组manifest文件名的列表,用于组织和管理多个manifest文件。它充当了快照与具体manifest文件之间的桥梁。
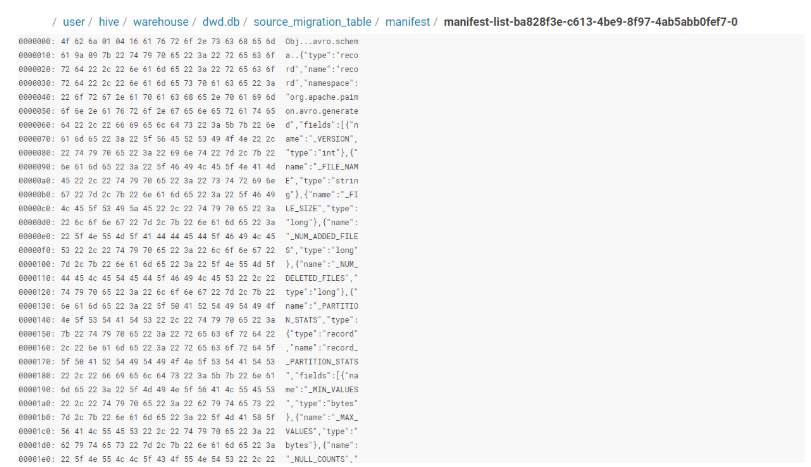
Paimon中的Manifest-list分为三种类型:
- baseManifestList(基础清单列表)
- 记录来自之前快照的所有变更
- 包含历史累积的manifest文件引用
- deltaManifestList(增量清单列表)
- 记录当前快照中发生的新变更
- 用于更快的过期和流式读取
- changelogManifestList(变更日志清单列表)
- 记录快照中产生的变更日志
- 为null表示没有变更日志或paimon版本≤0.2
| 特性 | Manifest 文件 | Manifest-list 文件 |
|---|---|---|
| 作用 | 记录一个 bucket 的数据文件变更 | 记录一次快照涉及的所有 Manifest 文件 |
| 内容 | 数据文件路径、统计信息、状态 | Manifest 文件路径、分区、bucket、统计信息 |
| 粒度 | 细粒度(bucket 级别) | 粗粒度(快照级别) |
| 生成频率 | 每次写入 bucket 有变更时 | 每次提交(commit)时 |
| 是否被索引 | 被 Manifest-list 索引 | 被快照(snapshot)索引 |
索引(Index)文件的 Manifest
Paimon 0.8+ 支持次级索引(如 bloom-filter、hash-index、vector-index 等)。
写入数据时,同步或异步生成对应的 index file(通常以 .index 结尾)。
为了快照隔离、增量清理、快速读取,这些索引文件同样需要走 Manifest 机制 → 于是就有了 indexManifest。
| 项目 | 普通 Manifest | indexManifest |
|---|---|---|
| 记录对象 | 数据文件(.parquet) | 索引文件(.index) |
| 文件前缀 | manifest-{uuid}-N | index-manifest-{uuid}-N |
| 内容字段 | file_path, rowCount, min/max 值… | index_type, file_path, size, bloom_bits… |
| 由谁生成 | Writer(commit) | IndexWriter(commit 或 async) |
| 由谁读取 | Scan / Compact / Audit | IndexLookup / Compaction / Clean |
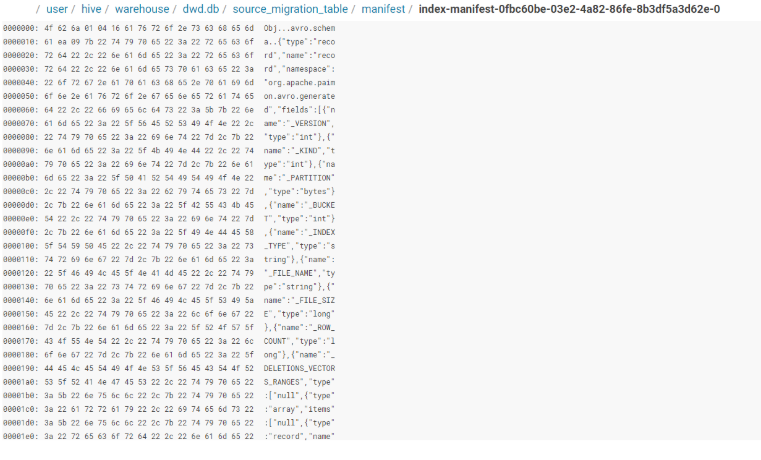
Schema文件:
Schema文件是定义表结构信息的元数据文件,存储表的字段定义、分区键、主键等信息。
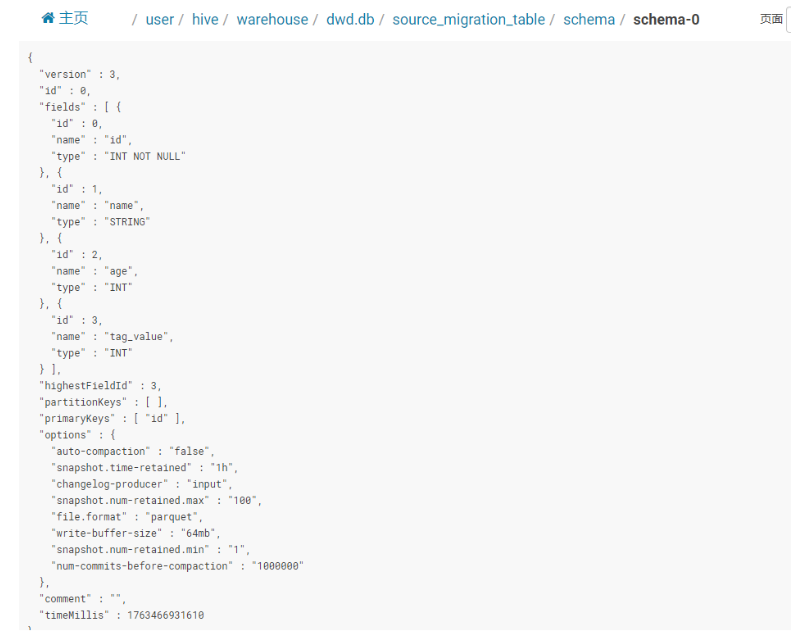
快照文件(Snapshot):
所有快照文件都存储在 snapshot 目录中。快照文件是一个 JSON 文件,包含以下信息
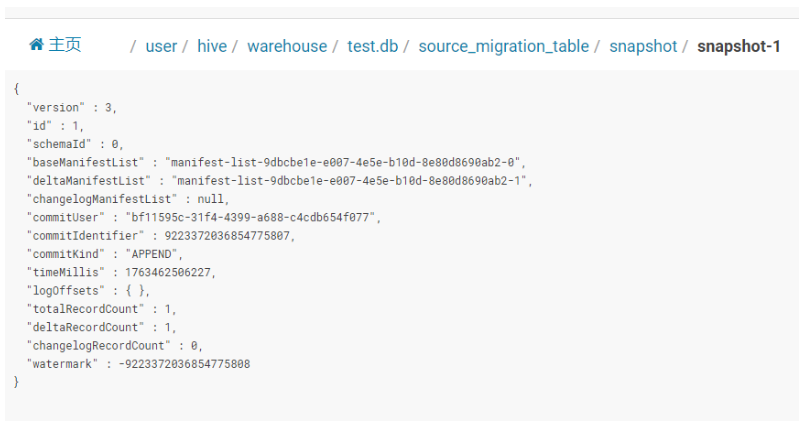
| 字段 | 值 | 含义 |
|---|---|---|
| version | 3 | 快照文件格式版本号(内部协议) |
| id | 1 | 快照序号(=1,说明这是表的第 1 次提交) |
| schemaId | 9 | 本次使用“编目规则 9 号”→ 去 schema/schema-9.json 看字段定义 |
| baseManifestList | manifest-list-9dbcbe1e…‑0 | 全量文件清单(首次提交时它就是全部) |
| deltaManifestList | manifest-list-9dbcbe1e…‑1 | 增量文件清单(本次追加的新文件) |
| changelogManifestList | null | 没有产生行级变更日志(非流式更新) |
| commitUser | bf11595c… | 谁提交的(Flink Job 或 Spark Application 的 UUID) |
| commitIdentifier | 9223372036854775807 | Long.MAX_VALUE → 批模式一次性提交 |
| commitKind | APPEND | 本次只是追加,不是 COMPACT 或 OVERWRITE |
| timeMillis | 1763462586227 | 提交瞬间的时间戳(毫秒) |
| totalRecordCount | 1 | 整张表现在共 1 条记录 |
| deltaRecordCount | 1 | 本次追加了 1 条记录 |
| watermark | -9223372036854775808 | Long.MIN_VALUE → 无事件时间概念(批) |
snapshot-1 ──schemaId─→ schema/schema-9.json
│
├─baseManifestList─→ manifest/manifest-list-9dbcbe1e…-0 (全量)
└─deltaManifestList─→ manifest/manifest-list-9dbcbe1e…-1 (增量)
│
▼
里面列出真正数据文件
bucket-0/data-xxxxx.parquet
tag文件:
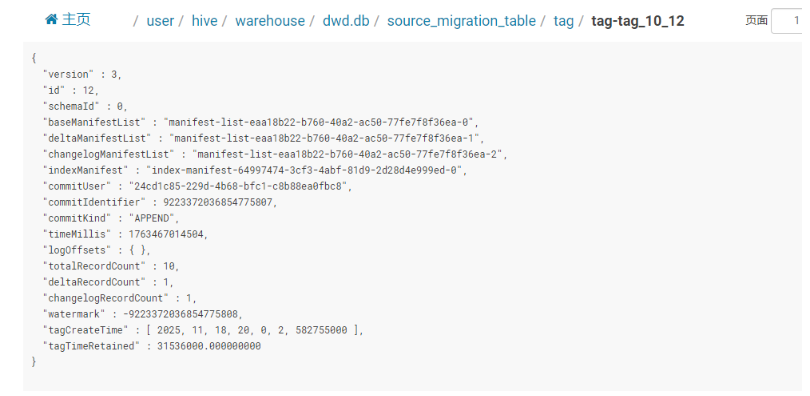
| 字段 | 值 | 含义 |
|---|---|---|
| version | 3 | 文件格式协议号(内部协议) |
| id | 12 | 被“裱”起来的快照序号 |
| schemaId | 9 | 用 9 号规则(schema/schema-9.json)解读数据 |
| baseManifestList | …-0 | 全量文件清单(首次提交时的全部) |
| deltaManifestList | …-1 | 增量文件清单(本次追加部分) |
| changelogManifestList | …-2 | 有行级变更日志(流式更新产生) |
| indexManifest | index-manifest-…-9 | 索引文件也有独立 manifest(建了 bloom/hash 等) |
| commitUser | 24cd1c85… | 提交者 UUID |
| commitIdentifier | 9223372036854775807 | 批模式一次性提交 |
| commitKind | APPEND | 只是追加,无覆盖 |
| timeMillis | 1763467914504 | 提交瞬间时间戳 |
| totalRecordCount | 19 | 整张表共 19 行 |
| deltaRecordCount | 1 | 本次追加 1 行 |
| changelogRecordCount | 1 | 变更日志里记录了 1 行(update/delete 明细) |
| watermark | -9223372036854775808 | 无事件时间 |
| tagCreateTime | 2025-11-18 20:00:02.582 | 打标签的瞬间(人眼可读) |
| tagTimeRetained | 31536000 s | 保质期 365 天(快照不会被后台清理) |
4. Tag 功能详解
4.1 Tag 的概念
Tag 是 Paimon 中的一个重要功能,它允许用户为表的特定快照创建标签,类似于 Git 中的标签功能。
4.2 Tag 的创建与存储
4.2.1手动创建标签
创建 Tag 时,Paimon 会根据当前快照进行创建:
-- 创建 Tag
CALL sys.create_tag('dwd.source_migration_table', 'tag_10_12', 12, '365d');
-- 查看所有 Tag
SELECT * FROM `source_migration_table$tags`;
Tag 信息存储在表的元数据中,可以通过系统表 table$tags 进行查询。
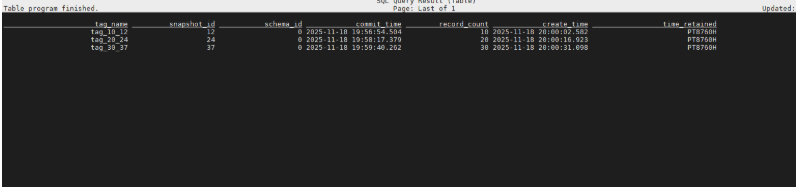
4.2.2自动创建标签
Paimon支持在写作任务中自动创建标签。
步骤 1:选择创建模式
您可以通过表选项设置创建模式'tag.automatic-creation'。支持的值包括:
process-time根据机器运行时间创建标签。watermark:根据 Sink 输入的水印创建标签。batch在批量处理场景中,当前任务完成后会生成一个标签。
步骤二:选择创建周期
标签生成频率是多少?您可以选择 -1、-2``'daily'和'hourly'`` ‘two-hours’-3 'tag.creation-period'。
如果需要等待延迟数据,可以设置延迟时间:'tag.creation-delay'。
步骤 3:自动删除标签
您可以配置'tag.num-retained-max'或tag.default-time-retained自动删除标签。
例如,配置表格,使其每天 0:10 创建一个标签,最大保留时间为 3 个月:
-- Flink SQL
CREATE TABLE t (
k INT PRIMARY KEY NOT ENFORCED,
f0 INT,
...
) WITH (
'tag.automatic-creation' = 'process-time',
'tag.creation-period' = 'daily',
'tag.creation-delay' = '10 m',
'tag.num-retained-max' = '90'
);
INSERT INTO t SELECT ...;
-- Spark SQL
-- Read latest snapshot
SELECT * FROM t;
-- Read Tag snapshot
SELECT * FROM t VERSION AS OF '2023-07-26';
-- Read Incremental between Tags
SELECT * FROM paimon_incremental_query('t', '2023-07-25', '2023-07-26');
4.3 Tag 的功能与应用场景
查询tag对应快照版本的数据:
#查询标签数据必须在批模式下
SET execution.runtime-mode=BATCH;
#查询数据tag_10_12这个tag的数据
SELECT * FROM source_migration_table /*+ OPTIONS('scan.tag-name' = 'tag_10_12') */;
5. Paimon 与 Hive 查询最新数据对比
5.1 Hive 查询最新数据的传统方式
在 Hive 中,查询最新数据通常需要使用复杂的 SQL 技巧,例如:
-- Hive 查询最新分区数据的传统方式
SELECT COUNT(*) FROM
(
SELECT partition_date,
ROW_NUMBER() OVER (PARTITION BY partition_date ORDER BY partition_date DESC) as rank_number
FROM dwd_core_enterprises_whitelist_info
WHERE partition_date > '2023-01-01' AND partition_date < '2023-12-31'
) a
WHERE a.rank_number = 1;
Hive 方式的缺点:
- 查询复杂度高:需要编写复杂的窗口函数
- 性能开销大:需要对全表数据进行排序和分区
- 维护困难:SQL 语句难以理解和维护
- 实时性差:无法支持实时数据查询
5.2 Paimon 查询最新数据的优势
Paimon 通过快照机制提供了更简单、高效的查询方式:
-- Paimon 查询最新数据(默认行为)
SELECT COUNT(*) FROM dwd_core_enterprises_whitelist_info;
-- Paimon 查询特定时间点的数据(时间旅行)
SELECT COUNT(*) FROM dwd_core_enterprises_whitelist_info
/*+ OPTIONS('scan.timestamp-millis'='1672531200000') */;
-- Paimon 通过 Tag 查询特定版本数据
SELECT COUNT(*) FROM dwd_core_enterprises_whitelist_info
/*+ OPTIONS('scan.tag-name'='v1.0') */;
Paimon 方式的优势:
- 查询简单直观:无需复杂SQL,直接查询即可获得最新数据
- 高性能:利用快照机制直接定位最新数据
- 实时性支持:支持流式数据实时查询
- 版本控制:内置的时间旅行和Tag功能
- 一致性保证:快照机制确保查询结果的一致性
5.3 性能对比分析
| 特性 | Hive | Paimon |
|---|---|---|
| 查询复杂度 | 高(需要窗口函数) | 低(直接查询) |
| 查询性能 | 中等(全表扫描) | 高(快照定位) |
| 实时性 | 不支持 | 支持 |
| 版本管理 | 需要外部工具 | 内置支持 |
| 数据一致性 | 需要手动保证 | 自动保证 |
| 存储效率 | 中等 | 高(LSM结构) |
6. 存储效率与技术优势分析
6.1 存储效率优化机制
Paimon 通过多种机制优化存储效率:
6.1.1 数据压缩与合并
- LSM 树合并操作:定期合并小文件,减少存储碎片
- 列式存储压缩:Parquet/ORC 格式提供高效的列压缩
- 增量存储:只存储变更数据,避免全量复制
6.1.2 快照存储优化
- 共享引用:多个快照共享相同的数据文件引用
- 增量快照:新快照只记录变更,不复制完整数据
- 自动清理:过期快照和未被引用的文件自动清理
6.2 技术优势总结
6.2.1 与传统数据湖的对比优势
| 技术特性 | 传统数据湖 | Paimon |
|---|---|---|
| 存储结构 | 文件列表 | LSM 树 |
| 写入性能 | 中等 | 高(顺序写入) |
| 查询性能 | 依赖文件扫描 | 快照定位 |
| 实时能力 | 有限 | 完整支持 |
| 版本管理 | 外部工具 | 内置 Tag |
| 存储效率 | 中等 | 高(压缩+合并) |
6.2.2 架构创新点
- LSM 树应用:将 LSM 树引入数据湖存储,优化写入性能
- 快照机制:轻量级的快照管理,支持时间旅行查询
- Tag 系统:Git-like 的版本标签管理
- 流批一体:同一存储支持流处理和批处理
7. 实际应用场景
7.1 数据湖架构升级
从传统的 Hive 数据仓库升级到 Paimon 数据湖,可以显著提升:
- 查询性能:快照机制减少数据扫描量
- 开发效率:简化数据查询逻辑
- 运维成本:自动化的快照和版本管理
7.2 实时数据分析
Paimon 支持流批一体架构,适用于:
- 实时报表:分钟级甚至秒级的数据更新
- 实时监控:业务指标的实时计算和展示
- 实时推荐:基于最新用户行为的推荐系统
7.3 数据治理与合规
通过 Tag 和快照机制,Paimon 支持:
- 数据审计:完整的数据变更历史记录
- 合规检查:标记符合法规的数据版本
- 数据质量:版本化的数据质量检查点
8. 总结
Apache Paimon 通过其创新的存储结构和快照机制,为大数据处理带来了革命性的改进:
8.1 核心技术优势
- 存储效率:LSM 树结构和数据压缩优化存储空间,快照存储不会翻倍增长
- 查询性能:快照机制显著提升查询效率,避免复杂 SQL
- 版本管理:Tag 功能提供灵活的数据版本控制
- 实时能力:支持流批一体的实时数据处理
- 架构创新:三层架构设计,与 Iceberg/Hudi/Delta 有明显区别
8.2 底层技术原理
- LSM 树存储:基于日志结构合并树的存储架构
- 快照机制:轻量级的版本管理,支持时间旅行
- Tag 系统:Git-like 的标签管理,存储在 metadata 目录
- 数据组织:基于哈希的分桶存储,优化查询性能
8.3 应用价值
对于需要处理大规模数据并追求实时性和查询性能的应用场景,Paimon 是一个值得考虑的优秀选择。特别是在以下场景下,Paimon 的优势尤为明显:
- 频繁查询最新数据:相比 Hive 的复杂窗口函数,Paimon 提供直接查询
- 时间旅行查询:内置支持历史数据查询
- 严格版本控制:Tag 系统确保数据版本一致性
- 实时数据处理:流批一体架构支持实时应用
Paimon 的创新存储架构和高效查询机制,为现代数据湖建设提供了强有力的技术支撑。
9. 初学者实践指南
9.1 快速开始:第一个Paimon项目
9.1.1 环境准备
系统要求:
- Java 8 或更高版本
- Apache Flink 1.14+(推荐)
- Maven 或 Gradle 构建工具
依赖配置(Maven):
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-flink</artifactId>
<version>1.0.0</version>
</dependency>
9.1.2 创建第一个Paimon表
步骤1:定义表结构
-- 创建用户行为表
CREATE TABLE user_behavior (
user_id BIGINT,
behavior_type STRING,
timestamp TIMESTAMP(3),
item_id BIGINT,
category_id BIGINT,
WATERMARK FOR timestamp AS timestamp - INTERVAL '5' SECOND
) WITH (
'connector' = 'paimon',
'path' = 'file:///tmp/user_behavior',
'auto-create' = 'true'
);
步骤2:插入测试数据
INSERT INTO user_behavior VALUES
(1001, 'click', TIMESTAMP '2024-01-01 10:00:00', 2001, 3001),
(1001, 'buy', TIMESTAMP '2024-01-01 10:01:00', 2001, 3001),
(1002, 'click', TIMESTAMP '2024-01-01 10:02:00', 2002, 3002);
步骤3:查询数据
-- 查询最新数据
SELECT * FROM user_behavior;
-- 按用户分组统计
SELECT user_id, COUNT(*) as click_count
FROM user_behavior
WHERE behavior_type = 'click'
GROUP BY user_id;
9.2 常用操作示例
9.2.1 数据写入操作
批量写入示例:
// Java代码示例:批量写入Paimon表
TableEnvironment tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode());
// 创建Paimon表
tableEnv.executeSql("
CREATE TABLE user_orders (
order_id BIGINT,
user_id BIGINT,
amount DECIMAL(10,2),
order_time TIMESTAMP(3)
) WITH (
'connector' = 'paimon',
'path' = 'file:///tmp/user_orders',
'auto-create' = 'true'
)
");
// 批量插入数据
tableEnv.executeSql("
INSERT INTO user_orders VALUES
(1, 1001, 99.99, TIMESTAMP '2024-01-01 09:00:00'),
(2, 1002, 199.99, TIMESTAMP '2024-01-01 09:01:00'),
(3, 1001, 49.99, TIMESTAMP '2024-01-01 09:02:00')
");
流式写入示例:
// 从Kafka流式写入Paimon
Table kafkaSource = tableEnv.from("kafka_source");
Table paimonSink = kafkaSource.select($("user_id"), $("behavior"), $("timestamp"));
paimonSink.executeInsert("user_behavior");
9.2.2 数据查询操作
时间旅行查询:
-- 查询1小时前的数据快照
SELECT * FROM user_behavior FOR SYSTEM_TIME AS OF TIMESTAMP '2024-01-01 09:00:00';
-- 查询特定标签版本的数据
SELECT * FROM user_behavior FOR SYSTEM_VERSION AS OF 'v1.0';
增量查询:
-- 查询最近5分钟的增量数据
SELECT * FROM user_behavior
WHERE timestamp >= NOW() - INTERVAL '5' MINUTE;
9.2.3 表管理操作
创建标签:
-- 为当前快照创建标签
CALL sys.create_tag('user_behavior', 'v1.0', 'Initial version with user behavior data');
查看表信息:
-- 查看表结构
DESCRIBE user_behavior;
-- 查看快照历史
SELECT * FROM user_behavior$snapshots;
-- 查看标签信息
SELECT * FROM user_behavior$tags;
数据清理:
-- 清理过期快照(保留最近7天)
CALL sys.expire_snapshots('user_behavior', 7);
9.3 最佳实践建议
9.3.1 表设计最佳实践
- 合理设置桶数量:根据数据量设置合适的桶数(通常4-32个)
- 选择合适的主键:为频繁查询的字段设置主键
- 设置合理的分区:按时间或业务维度分区
- 配置适当的TTL:根据业务需求设置数据保留时间
9.3.2 性能优化建议
- 批量写入:尽量使用批量写入而非单条插入
- 预聚合:对统计类查询进行预聚合
- 索引优化:为查询条件字段创建合适的索引
- 内存调优:根据数据量调整内存配置
9.3.3 运维监控建议
- 监控快照数量:定期清理过期快照
- 监控存储空间:关注数据文件增长情况
- 备份重要标签:对重要版本创建标签备份
- 定期健康检查:检查表状态和性能指标
9.4 故障排除与常见问题
9.4.1 常见错误及解决方案
问题: 无法连接到Paimon表
解决方案:
- 检查表路径是否正确
- 确认表是否存在(auto-create设置为true)
- 检查文件系统权限
问题: 查询速度慢
解决方案:
- 检查是否设置了合适的主键
- 考虑增加桶数量
- 优化查询条件,避免全表扫描
问题: 存储空间增长过快
解决方案:
- 设置合理的快照保留时间
- 定期清理过期数据
- 考虑数据压缩选项
9.4.2 调试技巧
日志分析:
启用详细日志来诊断问题:
# 在log4j.properties中设置
log4j.logger.org.apache.paimon=DEBUG
系统表查询:
使用系统表获取内部状态:
-- 查看表统计信息
SELECT * FROM user_behavior$schemas;
SELECT * FROM user_behavior$snapshots;
SELECT * FROM user_behavior$manifests;
性能分析:
使用EXPLAIN分析查询计划:
EXPLAIN PLAN FOR SELECT * FROM user_behavior WHERE user_id = 1001;

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









