



一、paimon部署(每个节点都需要部署,节点为xx.xx.xx.xx1-xx.xx.xx.xx5五个节点)
1.1 添加JAR包
在/opt/cloudera/parcels/CDH/lib/hive/auxlib/目录下添加jar包
没有auxlib就创建auxlib文件夹
mkdir /opt/cloudera/parcels/CDH-6.3.2.1.cdh6.3.2.p0.1605554/lib/hive/auxlib/
将paimonjar包添加到auxlib并查看权限
cp /home/bigdata/paimon-hive-connector-2.1-cdh-6.3-1.1.1.jar /opt/cloudera/parcels/CDH-6.3.2.1.cdh6.3.2.p0.1605554/lib/hive/auxlib/
查看权限
ls -ltrh /opt/cloudera/parcels/CDH-6.3.2.1.cdh6.3.2.p0.1605554/lib/hive/auxlib/paimon-hive-connector-2.1-cdh-6.3-1.3-20250715.003327-26.jar
1.2 集群设置
在hive配置中搜索hive.aux.jars.path
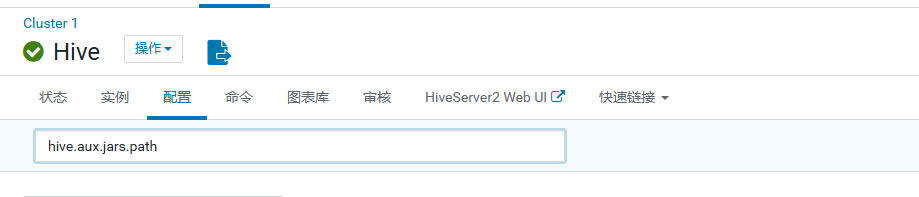
在 Hive 辅助 JAR ⽬录 新增 /opt/cloudera/parcels/CDH-6.3.2.1.cdh6.3.2.p0.1605554/lib/hive/auxlib/ ⽬录,如下:
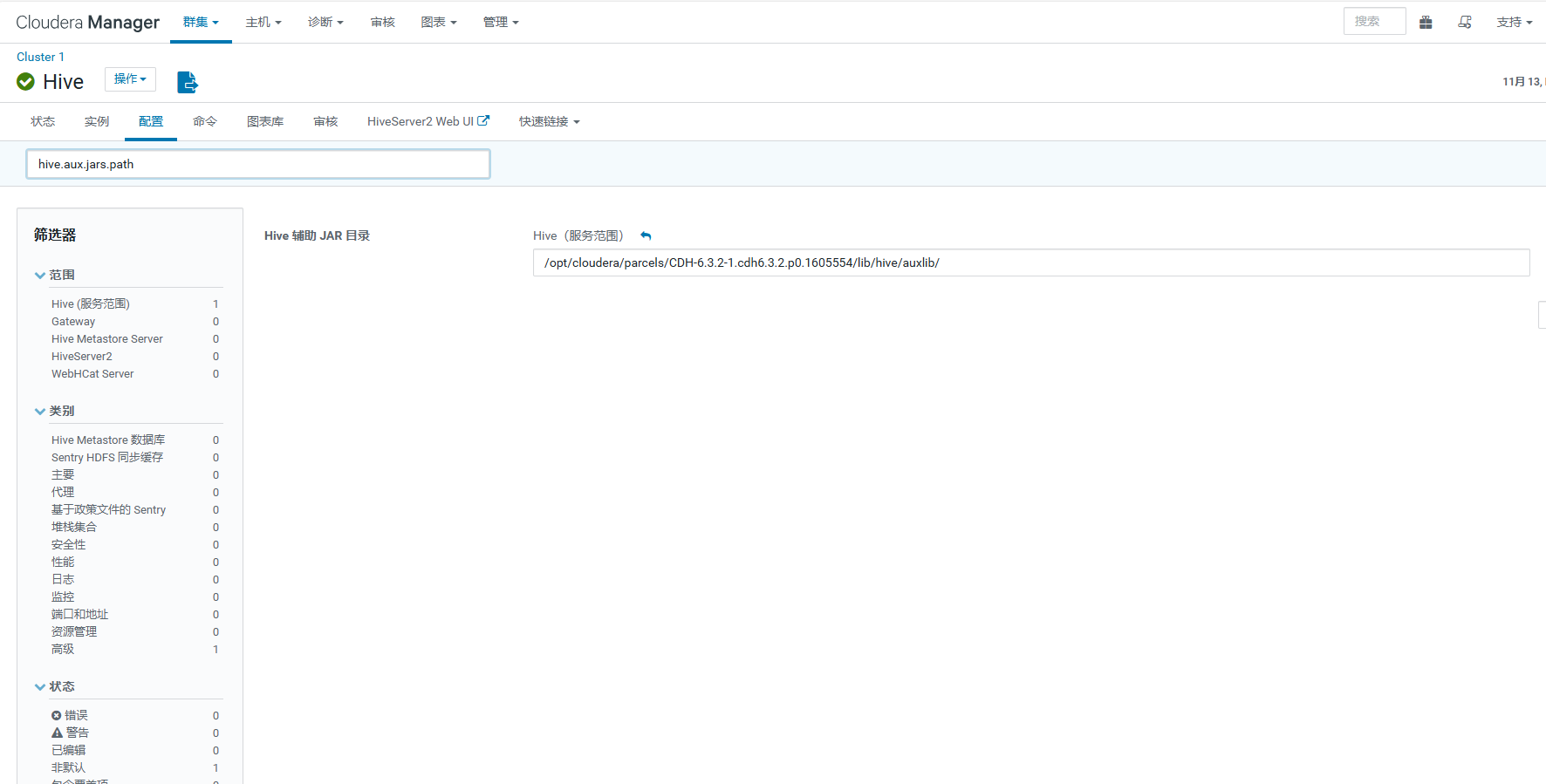

配置后重启hiveserver2服务
1.3 修改zstd版本
当前的zstd版本可能过低

下载相应版本的zstd
下载地址为:https://repo1.maven.org/maven2/com/github/luben/zstd-jni/1.5.5-11/zstd-jni-1.5.5-11.jar
上传到hive的lib⽬录

调整yarn上对应的版本(mapreduce.application.framework.path)
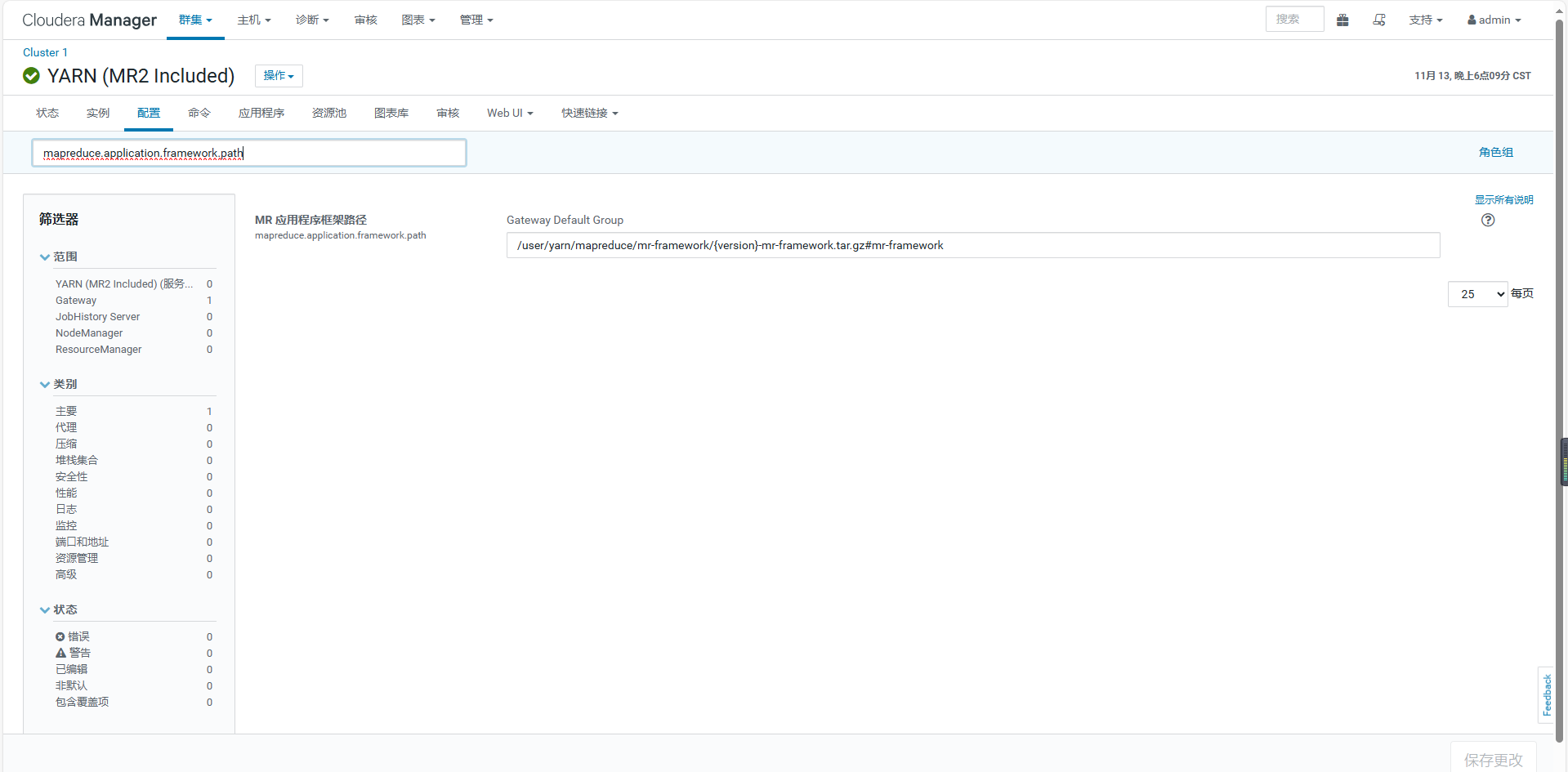

查看3.0.0-cdh6.3.2-mr-framework.tar.gz文件或zstd-jni-1.3.8-1.jar文件所在路径
sudo find / -type d -iname "*mr-framework*" 2>/dev/null
或者直接查看(优先使用,需要替换两个目录下的jar包)
sudo find / -type f -name "zstd-jni-1.3.8-1.jar" 2>/dev/null

将上传的zstd-jni-1.5.5-11.jar传入3.0.0-cdh6.3.2-mr-framework.tar.gz文件,并删除低版本的zstd-jni-1.3.8-1.jar
#上传文件
sudo cp /home/bigdata/zstd-jni-1.5.5-11.jar /opt/yarn/nm/filecache/10/3.0.0-cdh6.3.2-mr-framework.tar.gz/
#删除文件
sudo rm /opt/yarn/nm/filecache/10/3.0.0-cdh6.3.2-mr-framework.tar.gz/zstd-jni-1.3.8-1.jar
操作完毕以后,需要修改权限,否则yarn⽆权限访问
sudo chown -R yarn:hadoop /opt/yarn/nm/filecache/10/3.0.0-cdh6.3.2-mr-framework.tar.gz/
将zstd-jni-1.5.5-11.jar文件传入hive的
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/auxlib/目录和/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/目录下
将jar包传入hive目录
sudo cp /home/bigdata/zstd-jni-1.5.5-11.jar /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/auxlib/
传入jars目录
sudo mv zstd-jni-1.5.5-11.jar /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/
删除文件
sudo rm /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/zstd-jni-1.3.8-1.jar
上传完成后重启集群
1.4 操作paimon(主节点执行,10.8.16.201)
进入beeline模式
beeline -u jdbc:hive2://10.8.15.240:10000 -n root
set hive.metastore.warehouse.dir = hdfs:///user/hive/warehouse;
-- 上述的其实是默认值,不配置也可
-- 如果使⽤alluxio,也可以配置alluxio的地址:hive.metastore.warehouse.dir=allu
xio://zk@hadoop1:2181,hadoop2:2181,hadoop3:2181/user/hive/warehouse
set hive.cbo.enable=false;
set paimon.hadoop-load-default-config =false;
1.5 创建库和表
create database paimon;
#创建表
CREATE TABLE hive_paimon_t1(
age INT COMMENT '年龄',
name STRING COMMENT '姓名'
)
STORED BY 'org.apache.paimon.hive.PaimonStorageHandler';
1.6 插入数据,并查看数据
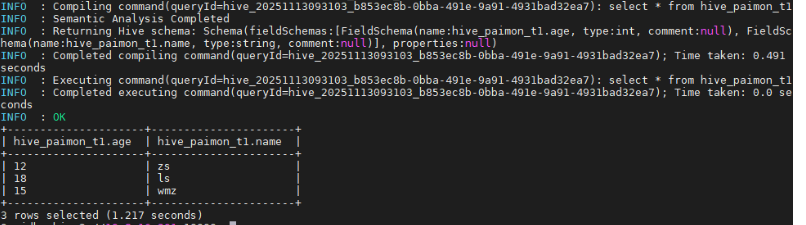
insert into hive_paimon_t1 values(12,'zs'),(18,'ls'),(15,'wmz');
select * from hive_paimon_t1;
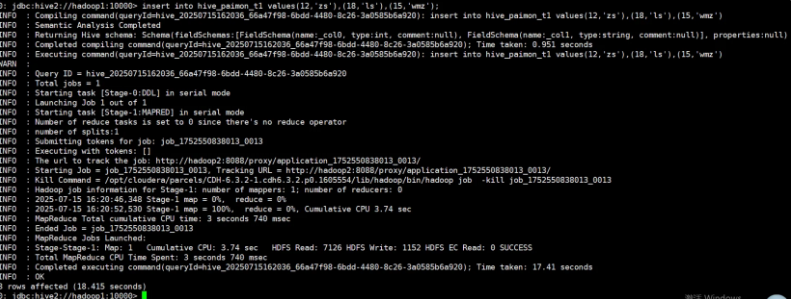
查看数据

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









