




 本文详细介绍了Spark在本地模式和Standalone集群模式下的部署及应用,包括wordcount案例、圆周率计算、监控页面和日志管理。重点阐述了Standalone集群的架构、配置、HA高可用实现,以及基于Zookeeper的故障切换机制。
本文详细介绍了Spark在本地模式和Standalone集群模式下的部署及应用,包括wordcount案例、圆周率计算、监控页面和日志管理。重点阐述了Standalone集群的架构、配置、HA高可用实现,以及基于Zookeeper的故障切换机制。
创建软链接,方便后期升级
ln -s /usr/spark/spark-2.4.0-bin-hadoop2.7 /usr/spark/spark

Spark 本地模式
Spark-shell
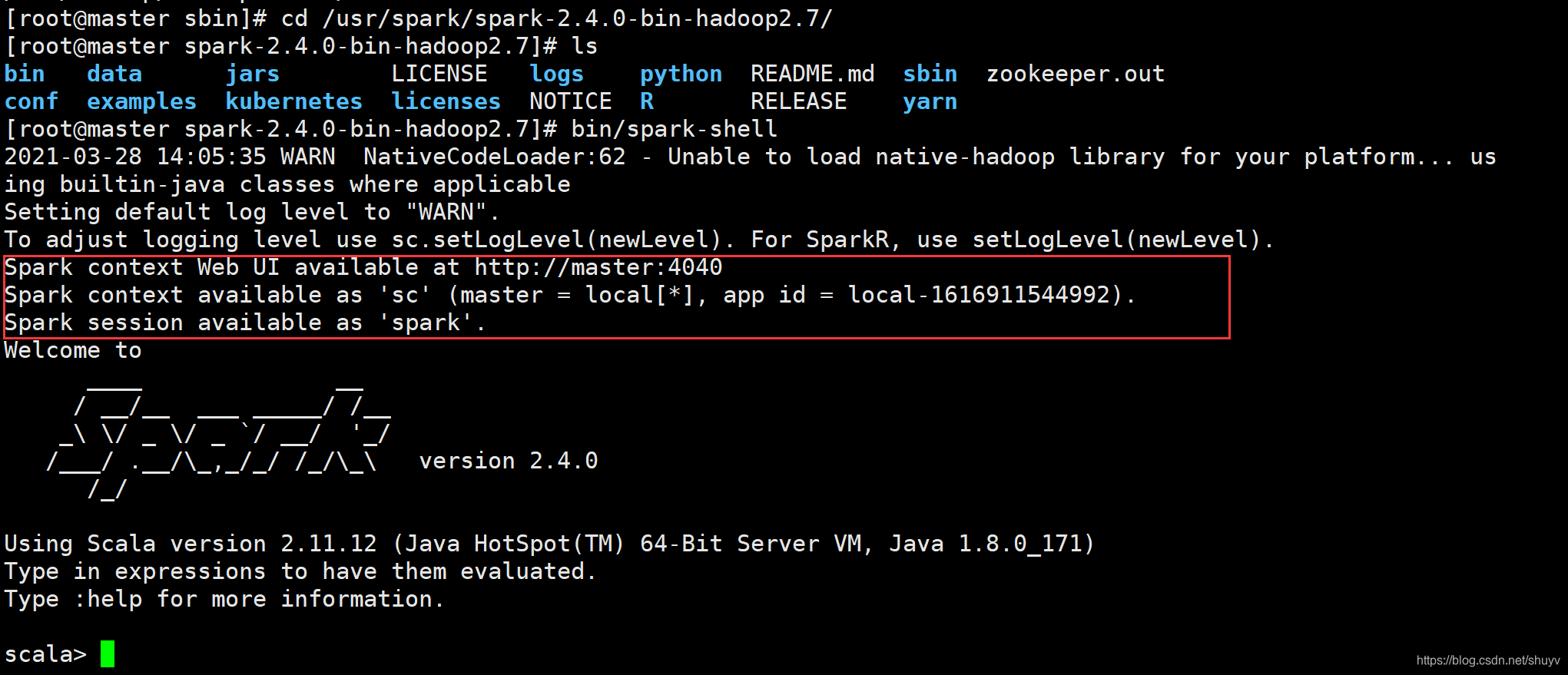
- Spark context Web UI available at http://master:4040
- 表示每个 Spark 应用运行时 WEB UI 监控界面,端口号为4040
- Spark context available as ‘sc’ (master = local[*], app id = local-1616911544992).
- 表示 SparkContext类实例名称为 sc
- 在运行 spark-shell 命令行的时候,创建 Spark 应用程序上下文实例对象 SparkContext
- 主要用于读取要处理的数据和调度程序执行
- Spark session available as ‘spark’.
- Spark2.x 的出现,封装 SparkContext 类,新的 Spark 应用程序的入口
- 表示的是 SparkSession 实例对象,名称为 Spark,读取数据和调度 Job 任务。
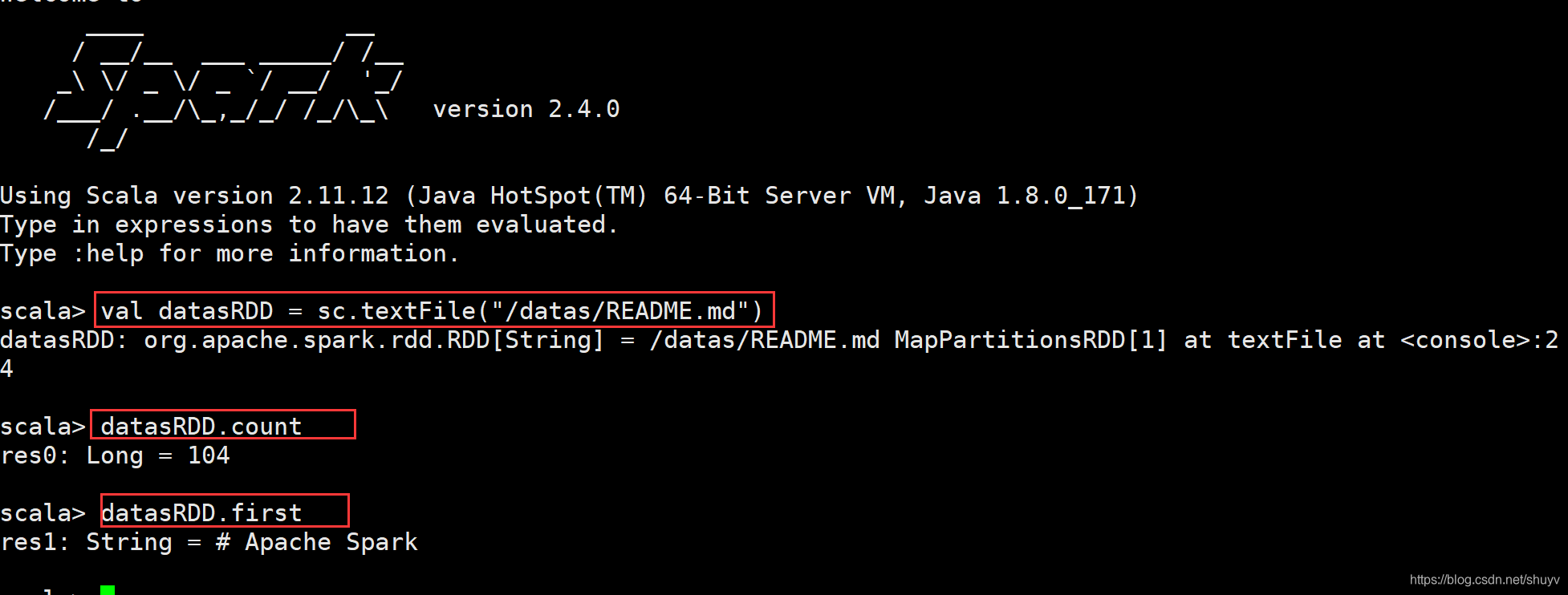
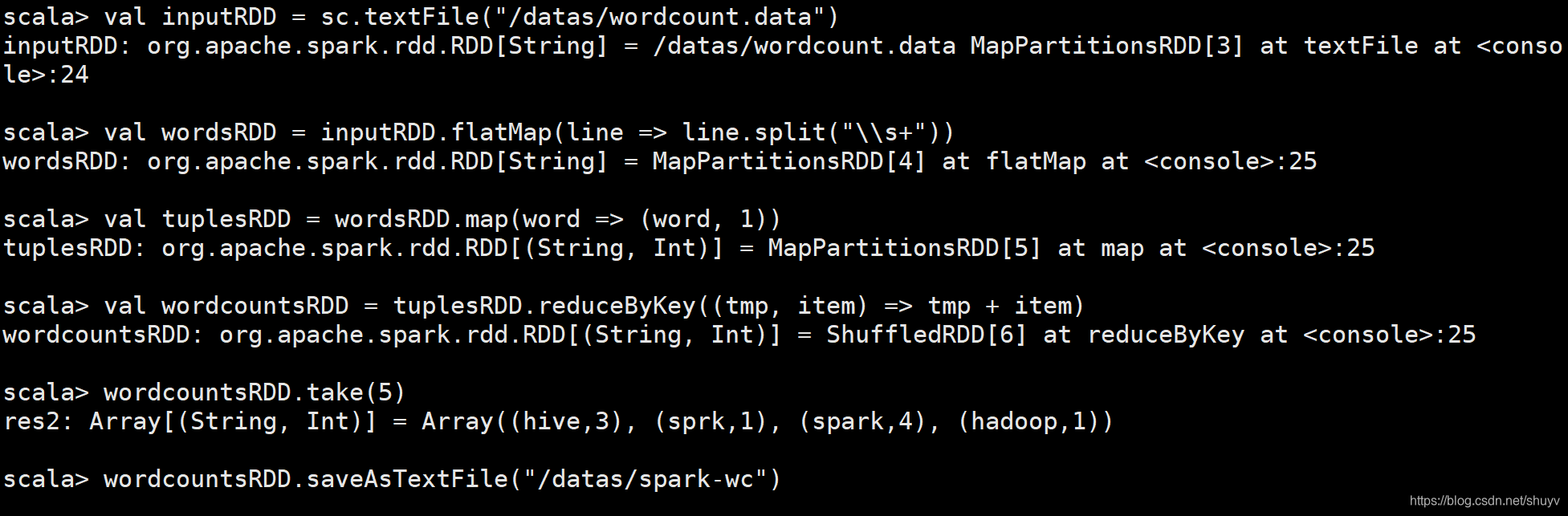
wordcount 程序案例
准备数据文件:wordcount.data,内容如下,上传HDFS目录【/datas/】
## 创建文件
vim wordcount.data
## 内容如下
spark spark hive hive spark hive
hadoop sprk spark
## 上传HDFS
hdfs dfs -put wordcount.data /datas/
编写代码进行词频统计:
## 读取HDFS文本数据,封装到RDD集合中,文本中每条数据就是集合中每条数据
val inputRDD = sc.textFile("/datas/wordcount.data")
## 将集合中每条数据按照分隔符分割,使用正则:https://www.runoob.com/regexp/regexp-syntax.html
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
## 转换为二元组,表示每个单词出现一次
val tuplesRDD = wordsRDD.map(word => (word, 1))
# 按照Key分组,对Value进行聚合操作, scala中二元组就是Java中Key/Value对
## reduceByKey:先分组,再聚合
val wordcountsRDD = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
## 查看结果
wordcountsRDD.take(5)
## 保存结果数据到HDFs中
wordcountsRDD.saveAsTextFile("/datas/spark-wc")
## 查结果数据
hdfs dfs -text /datas/spark-wc/par*
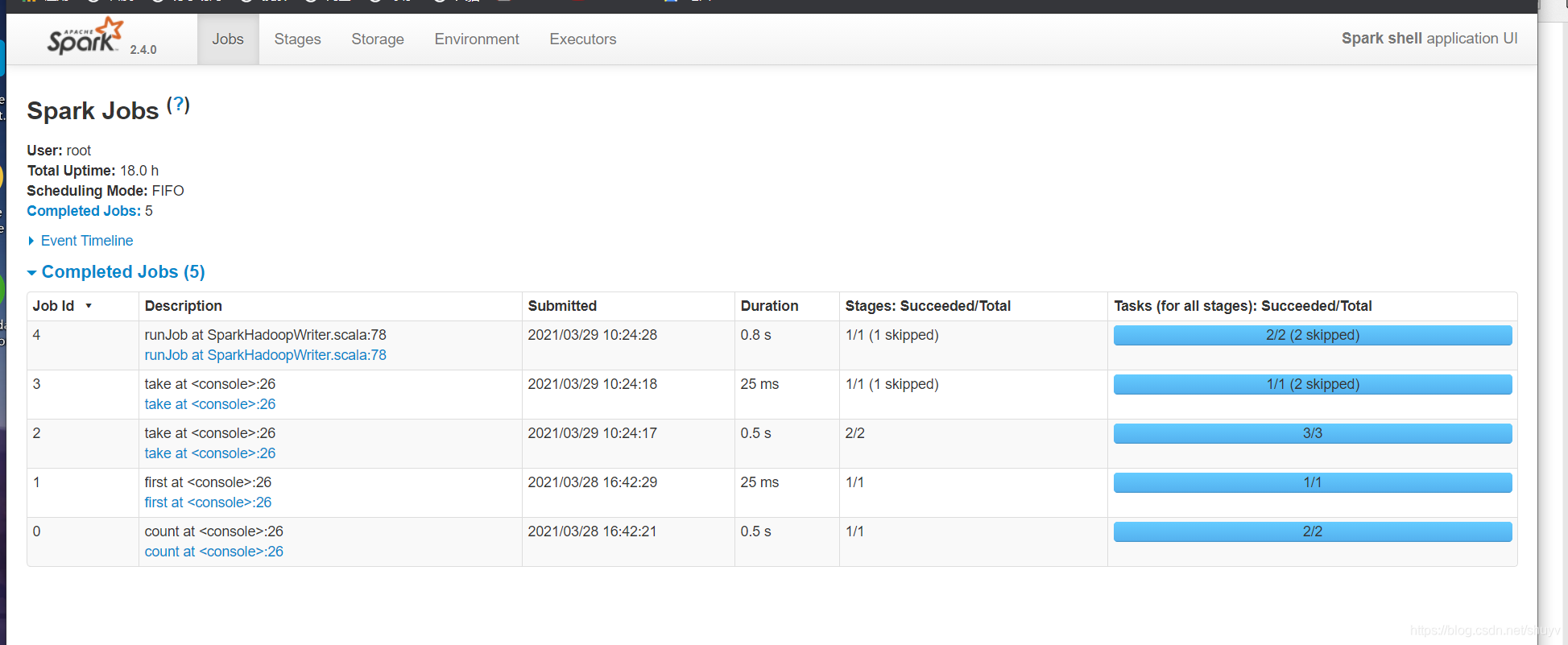
截图如下:

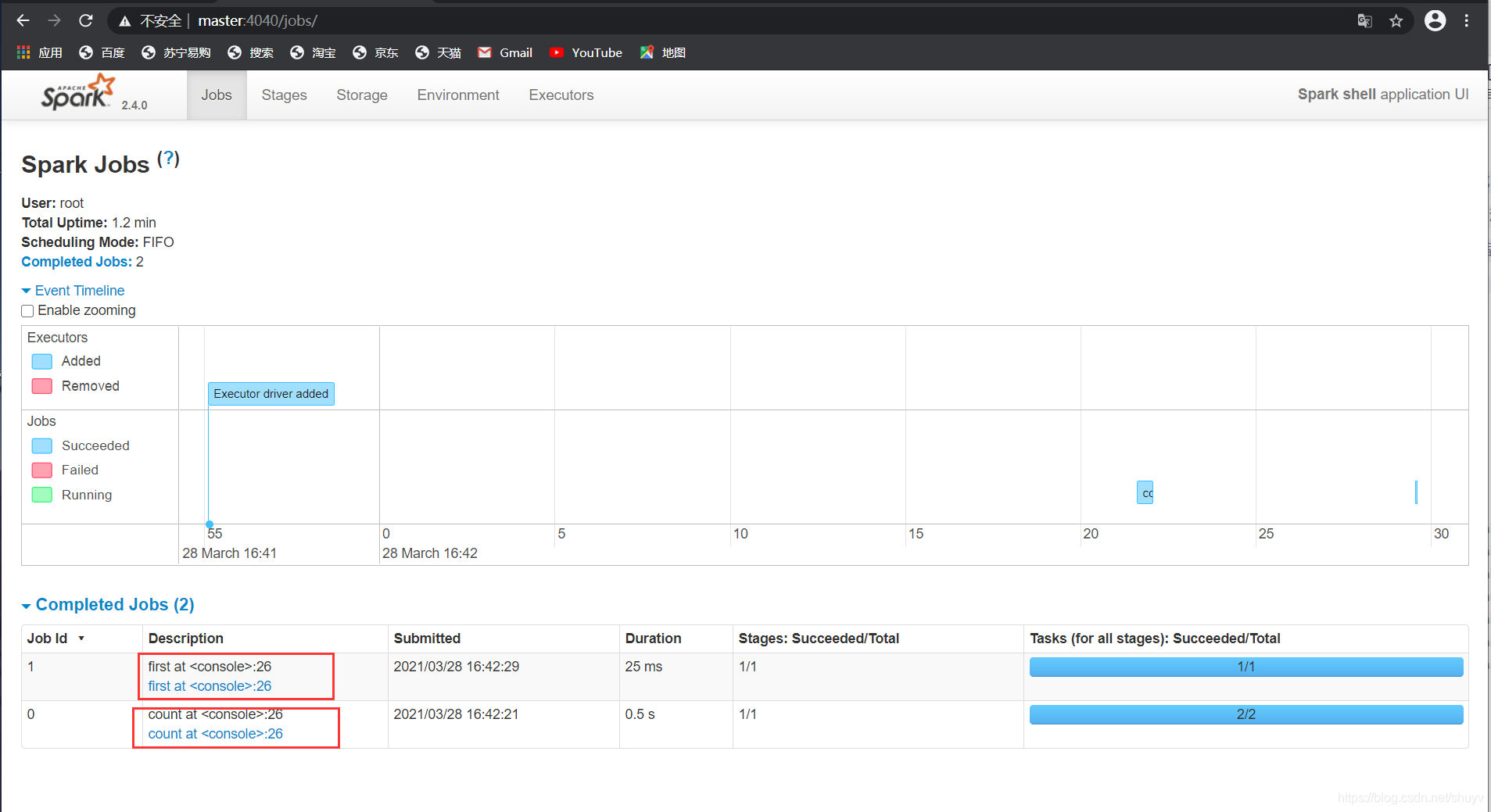
监控页面
每个Spark Application应用运行时,启动WEB UI监控页面,默认端口号为4040,使用浏览器 打开页面,如下:
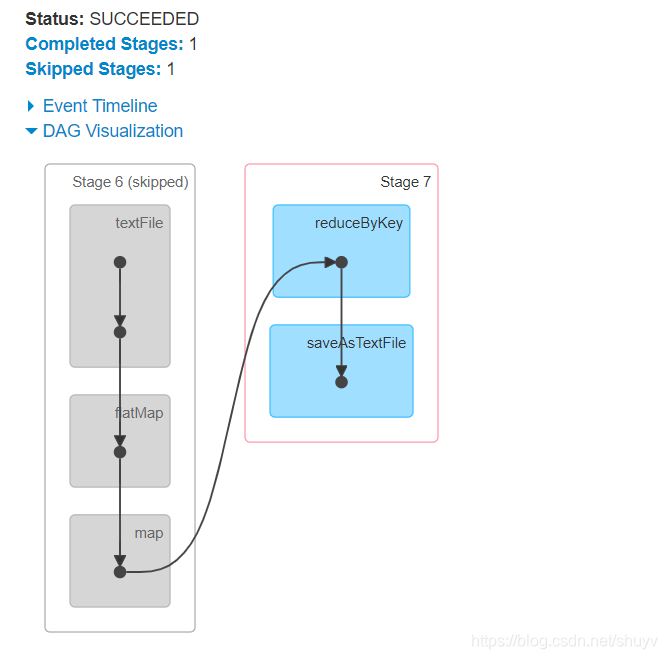
大多数现有的集群计算系统都是基于非循环的数据流模型。即从稳定的物理储存(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的 DAG(Directed AcyclicGraph ,有向无环图),然后写回稳定储存。DAG 数据流图能够在运行时自动实现任务调度和故障恢复。
运行圆周率程序案例(本地模式)
Spark 框架自带的案例 Example 中涵盖圆周率 PI 计算程序,可以使用 【$SPARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式。
而且 Spark 框架自带圆周率 jar 包

${SPARK_HOME}/bin/spark-submit --master local[2] --class org.apache.spark.examples.SparkPi ${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar 100
运行结果截图:
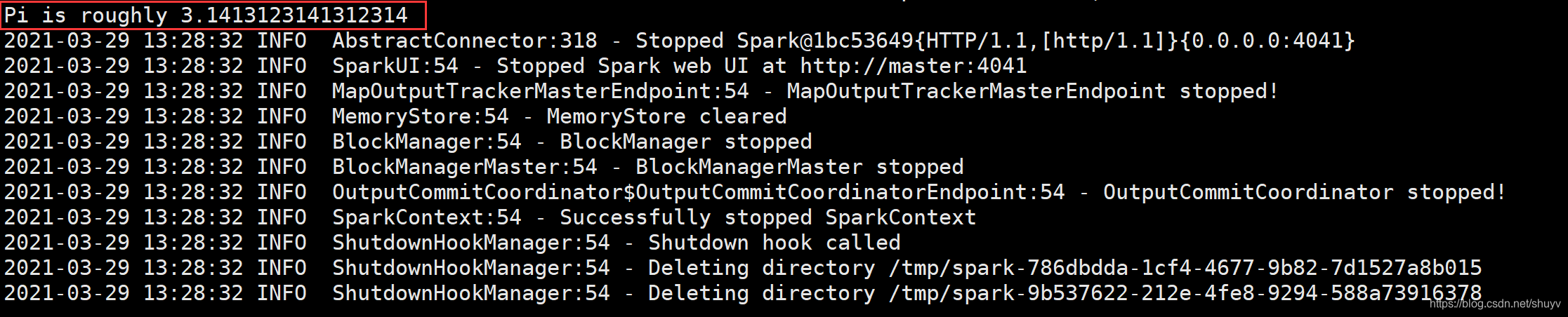
计算该圆周率的算法叫做 蒙特卡洛算法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3731
3731




 到【灌水乐园】发言
到【灌水乐园】发言







