






问题:
1,representing visual data is challenging for SSMs due to the position-sensitivity of visual data
(mamba is lack of positional awareness)
2,the requirement of global context for visual understanding
(mamba is a unidirectional model)
在MambaIRv2: Attentive State Space Restoration这篇文章中分别使用了positional embeding and "注意力机制"的引入C=(C+P),从而实现关注到全局
解决:
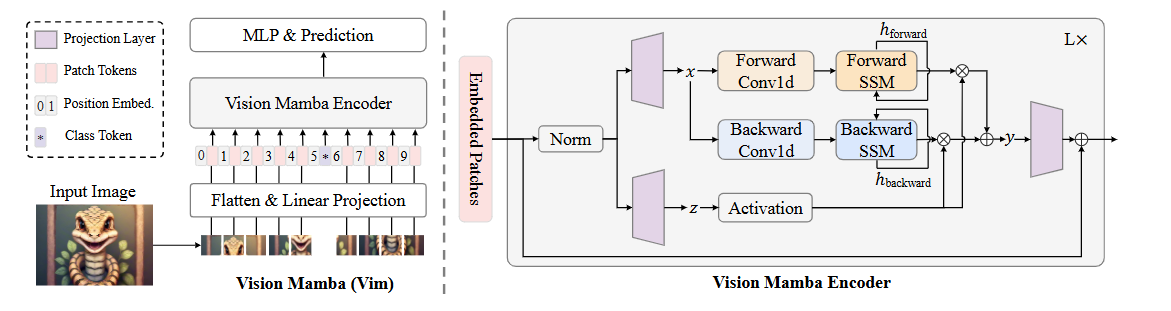
1,marks the image sequences with position embeddings
这完全跟vision transformer(ViT)干的事情一样啊
2,compresses the visual representation with bidirectional state space models.
感觉创新点的话就一个双向吧。
本文的大框架:
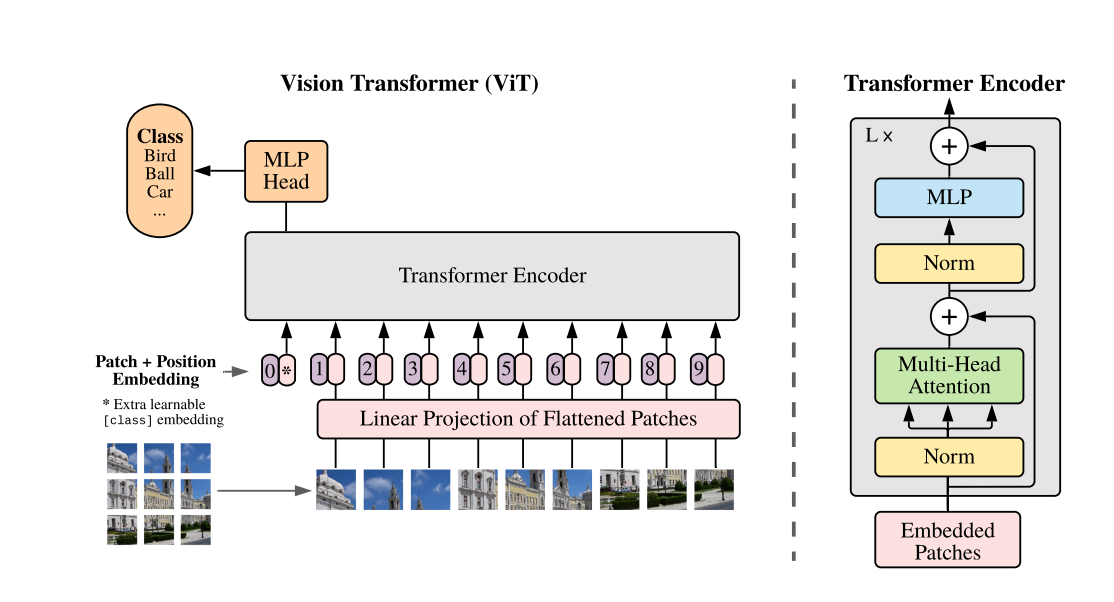
ViT:

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









