







写在前面
大模型技术如文心一言、chatGPT已经问世许久了,对于我来说,他们已经深深的改变了我学习和写代码的方式。我也曾问过我的老师和实习带教老师“我现在写代码基础全靠gpt,这是一件坏事吗”?相信不少人也有如此疑惑,我得到的回答是,“这就是一次生产力的进步,就像编译器的出现让程序员们从txt文本编辑代码升级到了vscode之类的编译器上以更‘先进、省力、专业’的方式完成他们的工作”,事实上,老师们自己也会常常使用gpt搭建基础框架,只要运用得到,绝对是事半功倍的。
网上有不少帖子分享如何部署一个属于自己的本地或云服务器上的大模型,那有什么办法让他更加“精细”一些,更符合自己的私人需求一些呢?本文就将主要分享大模型尤其是大语言模型的优化技术。
本文目录
低秩适应方法(Low-Rank Adaptation of Large Language Models, Lora)
基于实例的迁移学习(Instance based Transfer Learning)
基于特征的迁移方法 (Feature based Transfer Learning)
基于模型的迁移方法 (Parameter/Model based Transfer Learning)
基于关系的迁移学习方法 (Relation Based Transfer Learning)
BLEU(Biligual Evaluation understudy)
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
大模型基础概念
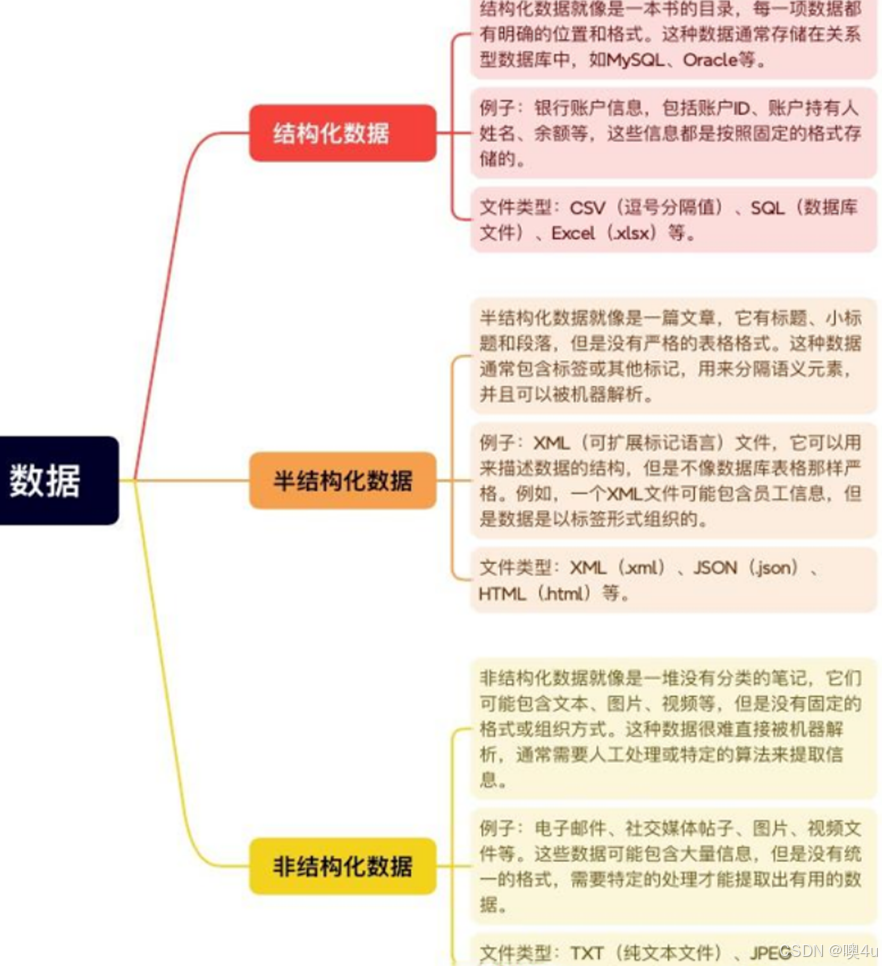
是什么
- 具有大规模参数和复杂计算结构的机器学习模型;
- 由深度神经网络构建而成;
- 拥有数十亿甚至数千亿个参数。
做什么
- 为了提高模型的表达能力和预测性能;
- 处理更加复杂的任务和数据;
- 自然语言处理、计算机视觉、语音识别和推荐系统等;
- 对未见过的数据做出准确的预测。
“大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。”
相关概念区分
- 大模型(Large Model):是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
- 超大模型:超大模型是大模型的一个子集,它们的参数量远超过大模型。
- 大语言模型(Large Language Model):通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。
- GPT(Generative Pre-trained Transformer):GPT 和ChatGPT都是基于Transformer架构的语言模型,但它们在设计和应用上存在区别:GPT模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。
按照输入数据的类型又分为:
- 语言大模型( Natural Language Processing ):指在自然语言处理领域中的一类大模型,通常用于处理文本数据和理解自然语言,在大规模语料库上进行了训练。
- 视觉大模型(Computer Vision ):指在计算机视觉领域中使用的大模型,通常用于图像处理和分析,可以实现各种视觉任务,如图像分类、目标检测、人脸识别等。
- 多模态大模型:指能够处理多种不同类型数据的大模型,结合了NLP和CV的能力。
按照应用领域又分为:
- 通用大模型L0:指可以在多个领域和任务上通用的大模型,利用大算力、使用海量的开放数据,具有巨量参数的深度学习算法,形成可“举一反三”的强大泛化能力,相当于AI完成了“通识教育”。
- 行业大模型L1:指针对特定行业或领域的大模型,通常使用行业相关的数据进行预训练或微调,提高在该领域的性能和准确度,相当于AI成为“行业专家”。
- 垂直大模型L2:指针对特定任务或场景的大模型,通常使用任务相关的数据进行预训练或微调,提高在该任务上的性能和效果。
基础技术
此处以LLM大语言模型为例:
Tokenization分词

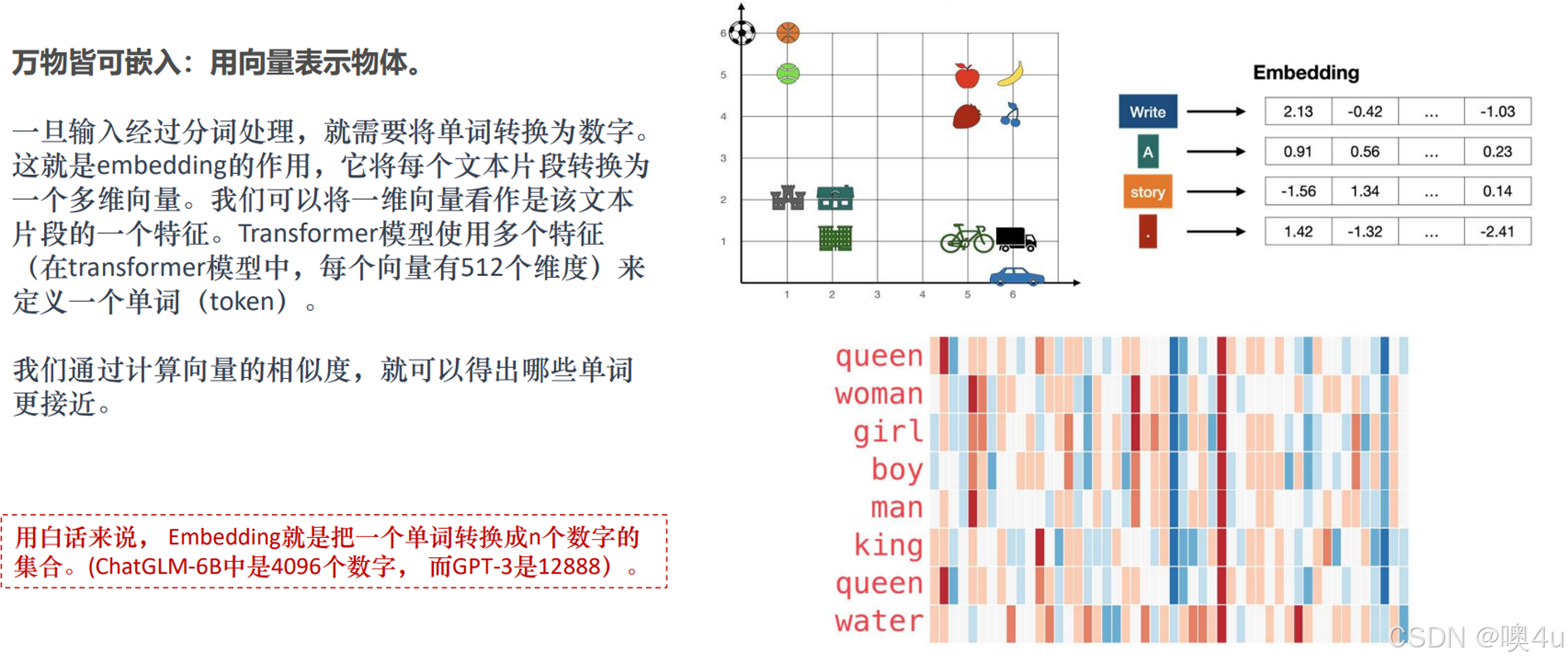
Embedding词嵌入
(在该专栏《4.0机器学习编码》已经具体介绍过几种嵌入算法)
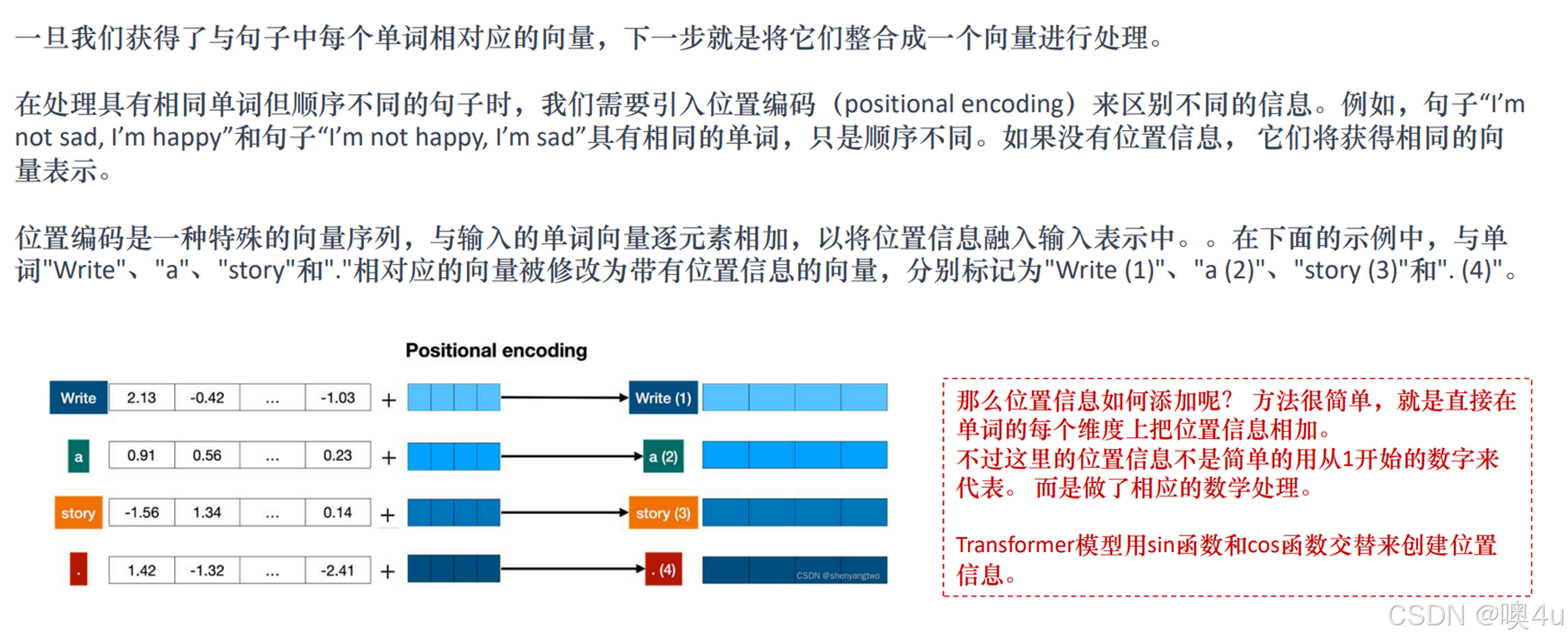
 Positional Encoding位置编码
Positional Encoding位置编码
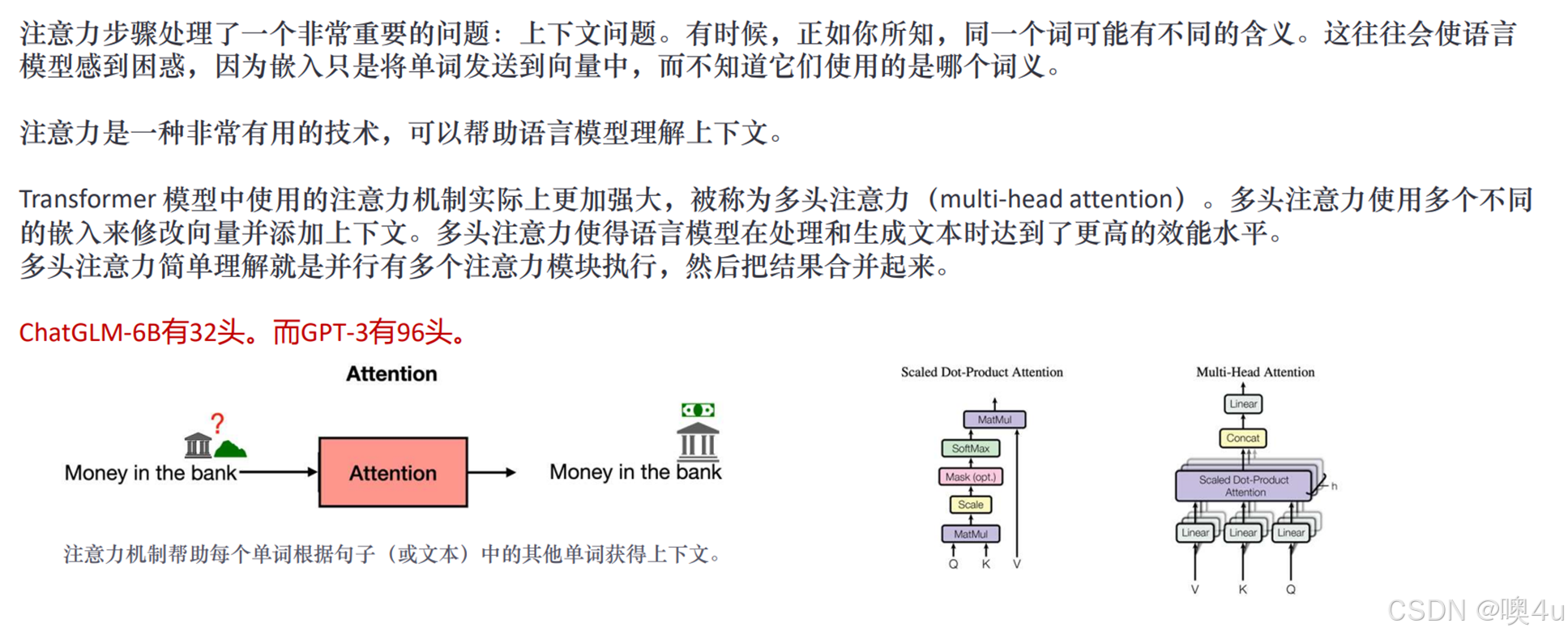
Self-attention自注意力机制
具体可见论文《self-attention is all you need》。
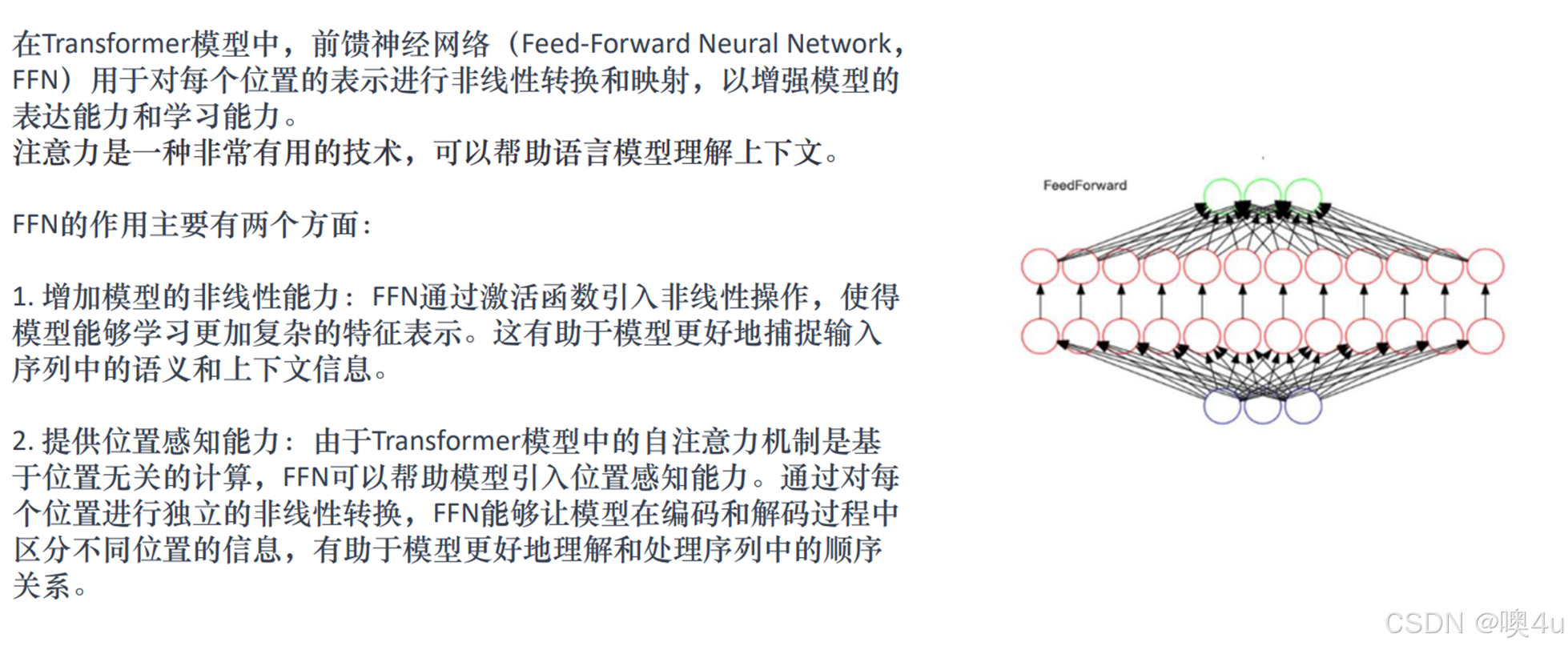
AIGC
这是当今另一个很火的概念,AI Generated Content,即使用人工智能生成内容,可以生成文字、图像、音频、视频、代码等。能够模拟人类的方式,在很短的时间内创作大量的内容。其基本模型有Transformer、预训练的语言模型:BERT、GPT等;
尽管使用了大量的训练数据,AIGC 也可能并不能总是很好的理解人类的意图,比如实用性和真实性。为了让 AIGC 的输出更接近于人类的偏好,从人类的反馈中不断进行强化学习(在该专栏《8》中有对强化学习的介绍和几种最常见策略的引入)也很重要,即reinforcement learning from human feedback(RLHF) 。
现在发展成熟的硬件、分布式训练、云计算等可以提供算力支持。
模型微调技术
接下来我们正式进入到模型微调技术,即让模型变得更加适合自己,更能给出自己所期待的答案而非泛泛而谈,更“听话”。相信大家在平时使用一些大模型工具的时候肯定碰到过大模型一本正经的胡说八道、文不达意的情况,那这个时候微调技术就能派上用场了。
例子
我们先来看两个例子:
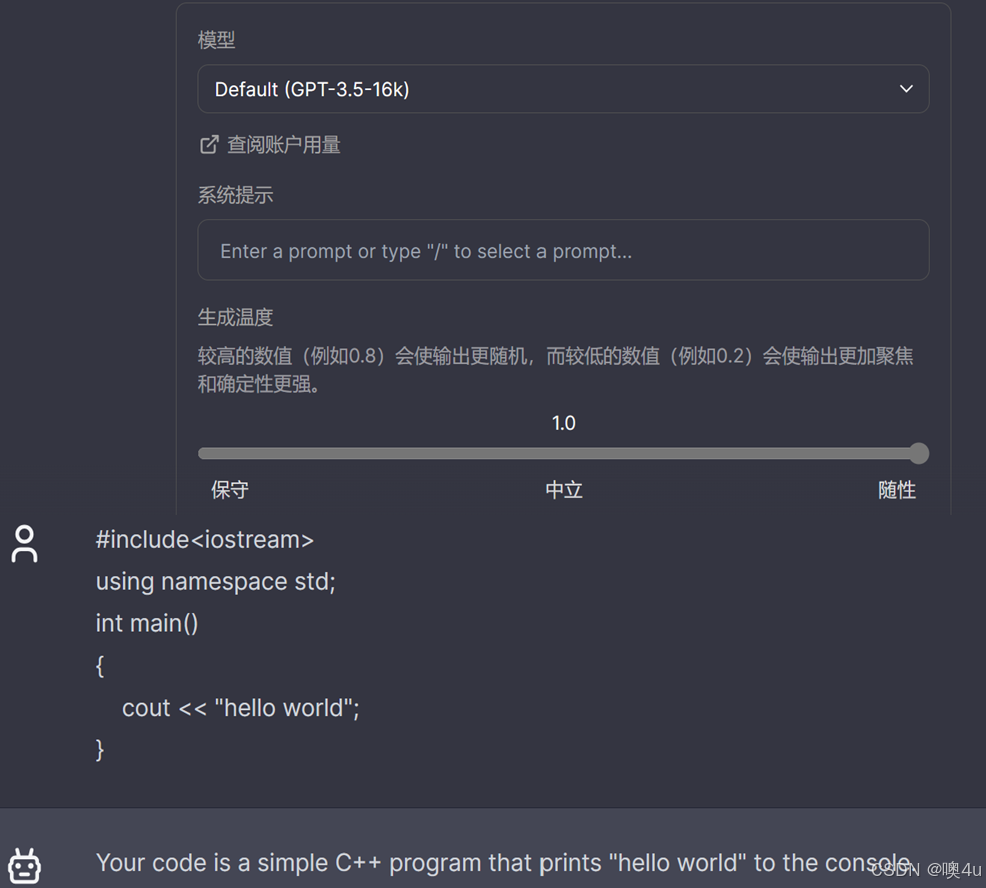
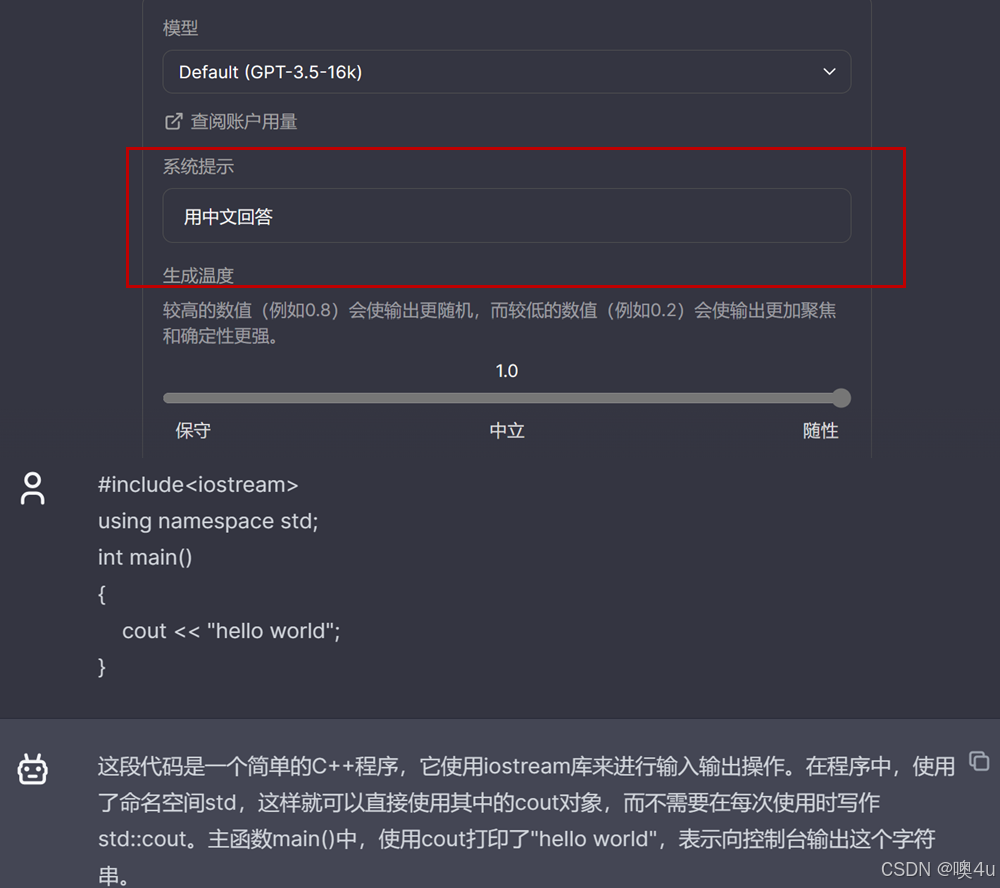
当我给gpt一段代码想让他帮我分析解释的时候,由于代码主要是用英语写的,所以gpt会默认输出英语的解释。如果我像右边这样给他加一句用中文输出的系统提示,那他才会直接使用中文输出。

 在第二个例子的左右对比中,我们可以看到,很明显更专业的提问会引发更专业的回答,但我们本身的出发点或许就是想通过大语言模型来学习一些东西或者获得一些解决问题的办法,没办法很精确的给到大模型很精确的输入提示。
在第二个例子的左右对比中,我们可以看到,很明显更专业的提问会引发更专业的回答,但我们本身的出发点或许就是想通过大语言模型来学习一些东西或者获得一些解决问题的办法,没办法很精确的给到大模型很精确的输入提示。
为了分别解决大模型不能针对问题精确回答的问题,就有了知识注入和指令微调两大类微调的方式。知识注入更简单、更便宜,就相当于让大模型进行开卷考。所以我们从它开始介绍,这种方法也可以称为检索增强生成、也叫知识外挂。
检索增强生成、知识注入、知识外挂(RAG)
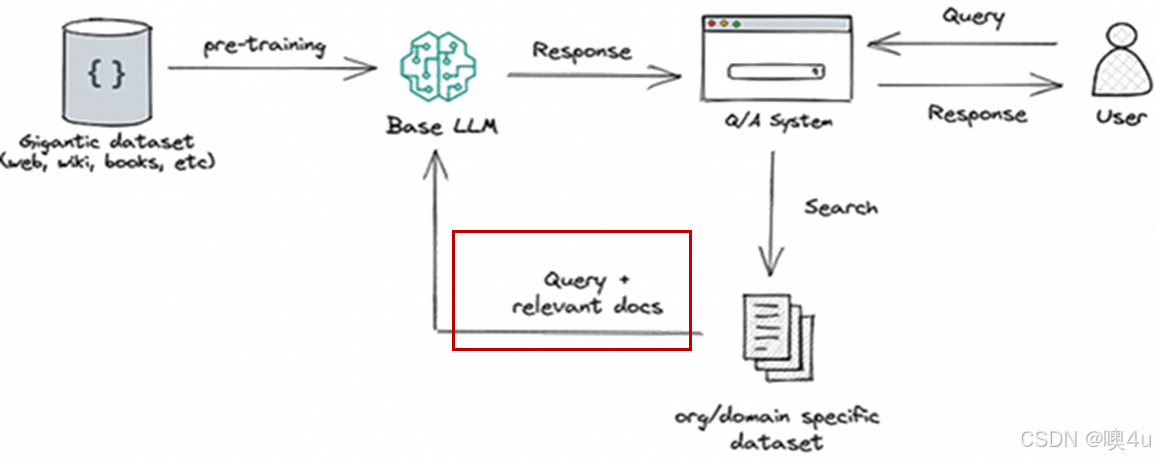
大模型应用的基本逻辑可以简单的表示成这样。
从外挂这个名字中我们就不难得出,这种方法将检索的能力集成到LLM文本生成中。它结合了一个检索系统和一个LLM,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。整个实现工作主要可以分为以下6个阶段:
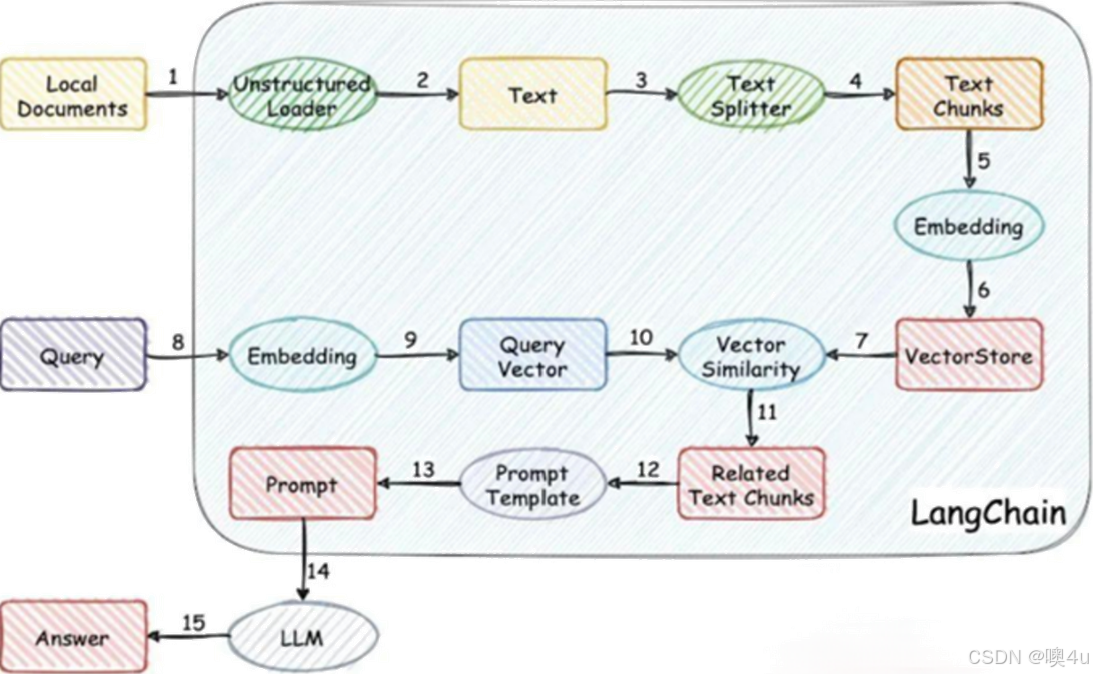
第一阶段:加载文件-读取文件-文本分割,也就是图中的1.2.3.4箭头。
- 加载文件:这是读取存储在本地的知识库文件的步骤;
- 读取文件:读取加载的文件内容,通常是将其转化为文本格式;
- 文本分割:按照一定的规则(例如段落、句子、词语等)将文本分割。
第二阶段:文本向量化(embedding)-存储到向量数据库。
- 文本向量化:这通常涉及到NLP的特征抽取,可以通过诸如TF-IDF、word2vec、BERT等方法将分割好的文本转化为数值向量;
- 存储到向量数据库:文本向量化之后存储到数据库vectorstore。在图中第5.6步完成。
第三阶段:问句向量化
- 这是将用户的查询或问题转化为向量,应使用与文本向量化相同的方法,以便在相同的空间中进行比较,在图中也就是第8.9.10步。
第四阶段:在文本向量中匹配出与问句向量最相似的top k个
- 这一步是信息检索的核心,通过计算余弦相似度、欧氏距离等方式,找出与问句向量最接近的文本向量。
第五阶段:匹配出的文本作为上下文和问题一起添加到prompt中
- 这是利用匹配出的文本来形成与问题相关的上下文,用于输入给语言模型。
第六阶段:提交给LLM生成回答
- 将这个问句问题和上下文一起提交给语言模型(大模型),让它生成回答,比如知识查询。
简单代码
以下是一个简单的代码实现:(使用openai的api)
import os
import dotenv
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
from langchain.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
dotenv.load_dotenv() #加载配置文件信息
OPEN_AI_KEY = os.getenv('OPEN_AI_KEY')
file_path = "/add.txt"
file_path = file_path.encode('utf-8').decode('gbk')
loader = TextLoader(file_path)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1024, chunk_overlap=128) #数据分块
chunks = text_splitter.split_documents(documents)
client = weaviate.Client( #数据块存储
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
retriever = vectorstore.as_retriever() #数据检索
template = """你是一个问答机器人助手,请使用以下检索到的上下文来回答问题,如果你不知道答案,就说你不知道。问题是:{question},上下文: {context},答案是:
"""
prompt = ChatPromptTemplate.from_template(template) #提示增强
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) #答案生成
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = input()
res = rag_chain.invoke(query)
print(f'答案:{res}')
我们也可以在这段代码中看到文本分割、文本向量化、和输入提示的部分。
实际应用
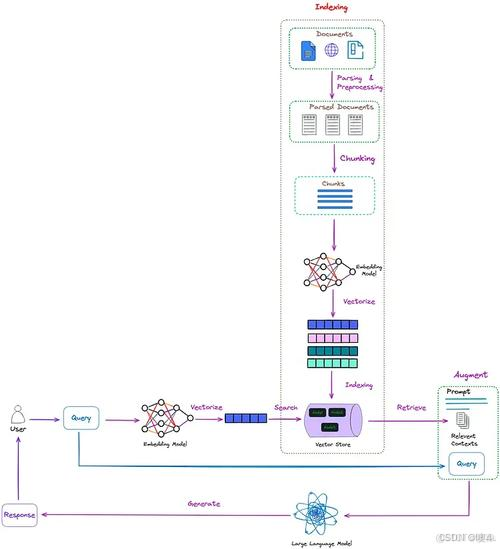
在实际的的具体应用中,数据的形式多种多样,向大模型传入一个pdf文件并解析再输出就是一种高级的rag应用的模式。上图中竖直的部分就是对外挂文件进行解析的过程,同样是寻找躯干并进行词向量化处理。
指令微调
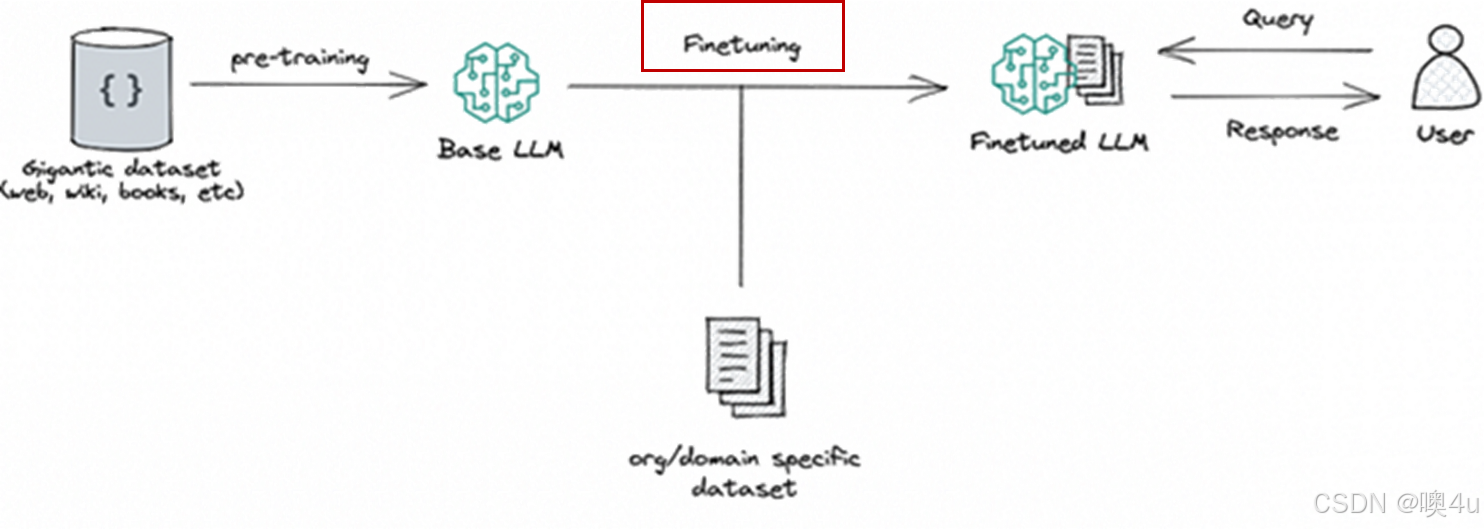
另一大类对大模型进行微调的方式就是微调。这是采用预先训练的 LLM 并通过少量特定用例的增量数据对基础模型进行进一步训练的过程,改变其神经网络中的参数权重,以使其适应特定任务或提高其性能或独特需求。微调适用于任务或域定义明确,且有足够的标记数据的场景,比如风格微调,但是微调对GPU算力还是有相对比较高的要求的,我们就主要介绍一下概念。
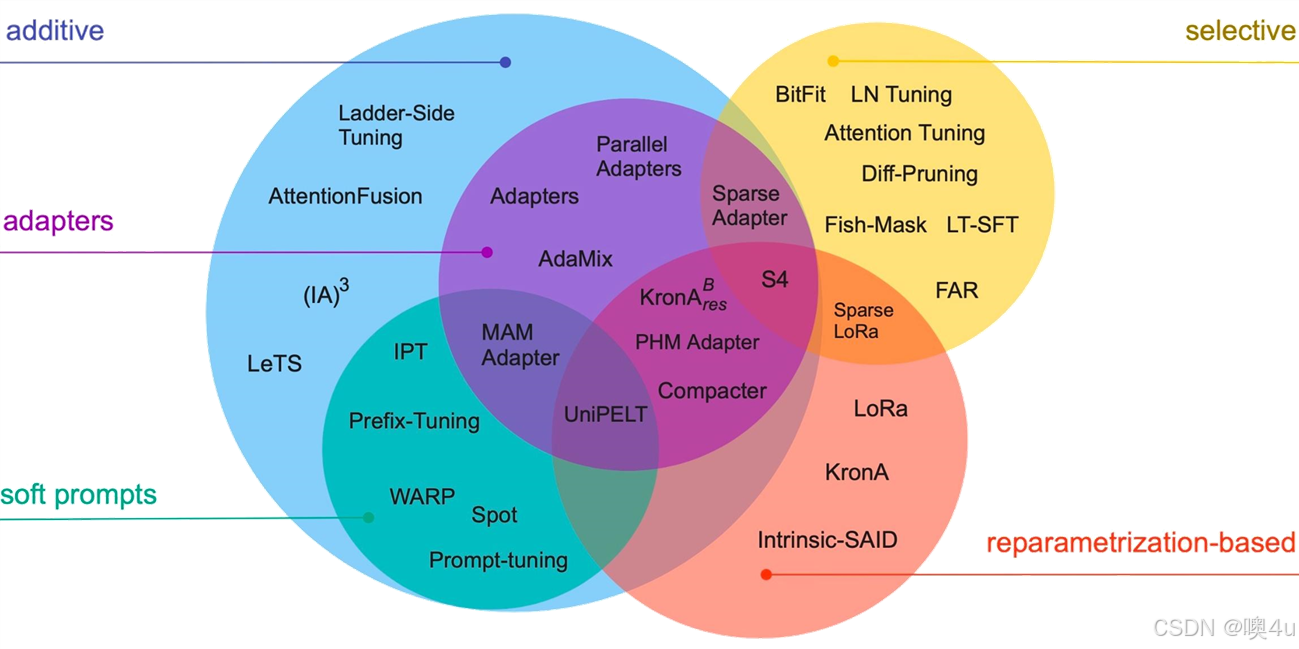
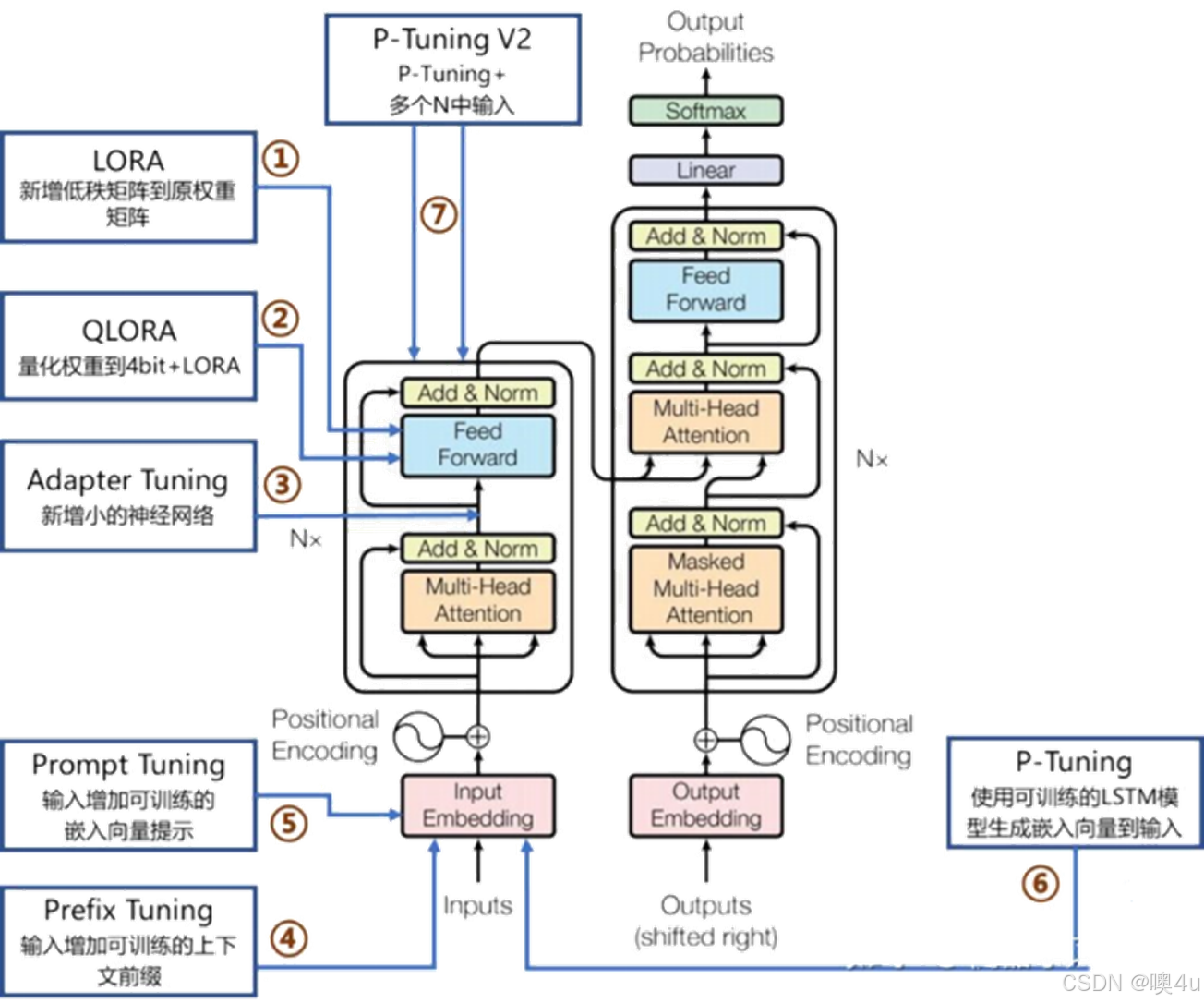
从参数规模来说,可以简单分为全参数微调和高效参数微调。前者一般是用预训练模型作为初始化权重,在特定数据集上继续训练,全部参数都更新的方法。而后者则是期望用更少的资源完成模型参数的更新,包括只更新一部分参数或者说通过对参数进行某种结构化约束,例如稀疏化或低秩近似来降低微调的参数数量。主要的微调方法有:
- 增加额外参数(蓝绿圈),如:Prefix Tuning、Prompt Tuning、Adapter Tuning及变体
- 选取一部分参数更新(黄圈),如:BitFit
- 引入重参数化(橙圈),如:LoRA
- 混合高效微调(最中间多重重合的部分),如:MAM Adapter、UniPELT
- 目前常见的微调技术有Instruction Tuning、BitFit、Prefix Tuning、Prompt Tuning、P-Tuning、Adapter Tuning、LoRA、RLHF等。
我们着重介绍两种比较常见的方法:pt和lora。
前缀微调(prefix tuning)
技术概念
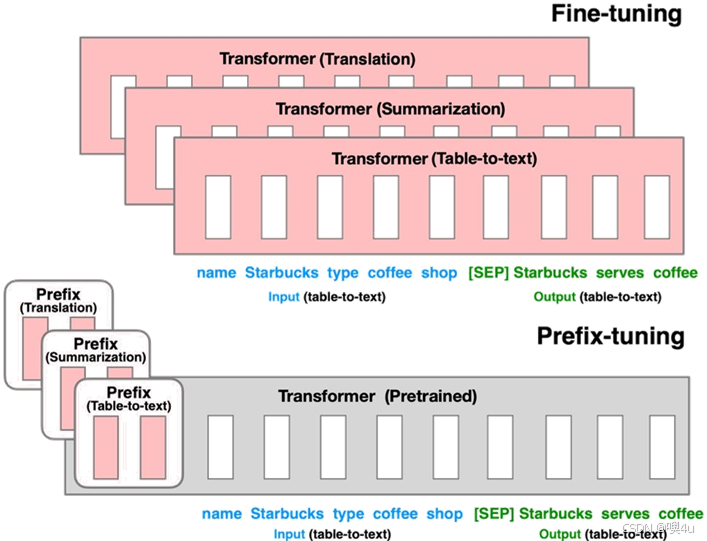
这其实是一种特殊形式的微调。它通过在输入序列的开始添加一个前缀(prefix)来改变模型的行为。这个前缀是一组可学习的参数,它在训练过程中被更新,以便模型可以生成与特定任务相关的输出。它通过在模型的输入端添加一个固定的前缀向量来实现。这种方法只需要训练少量的参数,大约是模型总参数的0.1%,这显著减少了计算成本和过拟合的风险。前缀调优在某些情况下甚至能够达到比全参数微调更好的性能,这可能是因为较少的参数调整有助于模型更好地泛化到不同的任务上。
在下图中,展示了两个不同的模型(自回归模型(上)和编码器-解码器模型(下))如何使用前缀调优(Prefix Tuning)来执行特定任务。


在这篇论文中,作者使用Prefix-tuning做生成任务,它根据不同的模型结构定义了不同的Prompt拼接方式。
- 对于自回归模型,例如GPT2模型,加入前缀后的模型输入表示:z = [PREFIX; x; y],这是因为合适的上文能够在语言参数固定不变的情况下去引导生成下文。
- 对于编解码器结构的模型,加入前缀后的模型输入表示:z = [PREFIX; x; PREFIX; y],这是因为Encoder端增加前缀是为了引导输入部分的编码 ,Decoder 端增加前缀是为了引导后续token的生成。
在这两种情况下,前缀是可训练的参数,它们在模型的训练过程中被优化,以便模型可以更好地完成摘要生成或文本到文本的任务。通过调整前缀,模型可以在不改变其内部权重的情况下适应不同的任务或数据集。这种方法的优点是可以提高模型的适应性,同时保持预训练模型的一般性能力。
技术效果
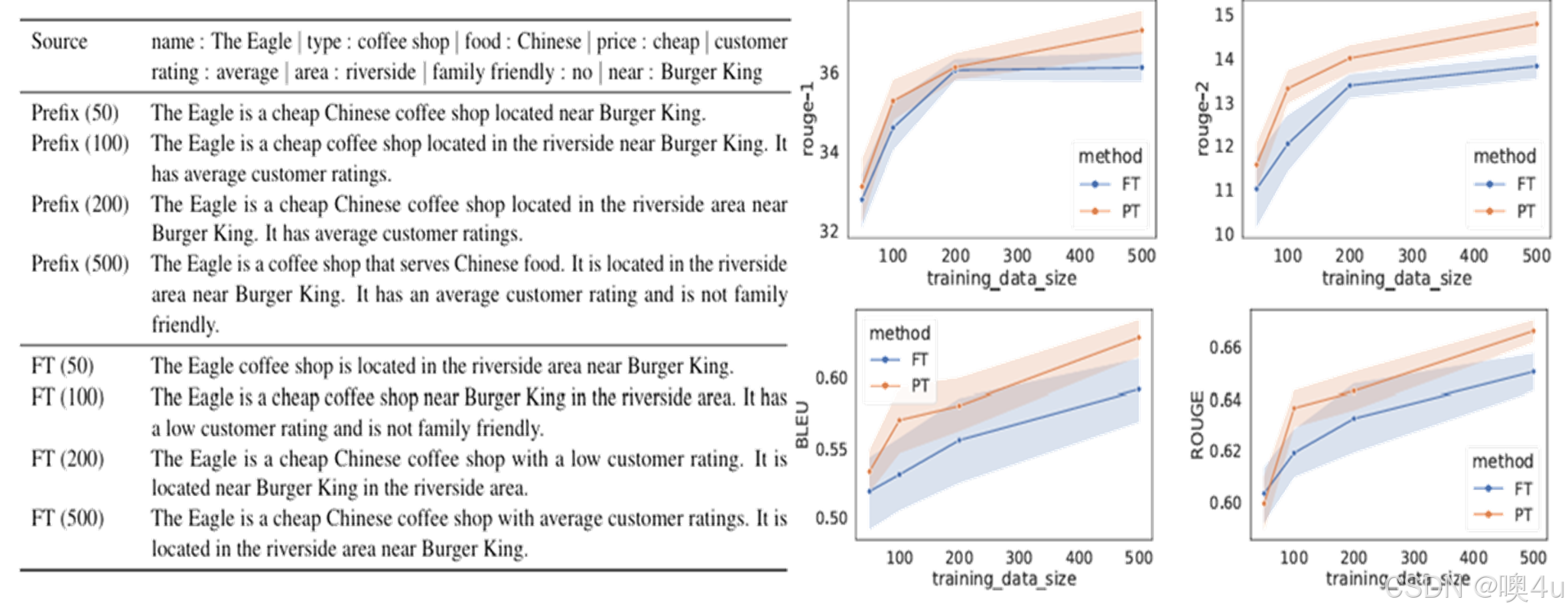
再来看一下prefix-tuning的效果。上下两个表格分别是对前缀微调和全参数微调的结果。我们可以看到在数据量相同的情况下,prefix-tuning做文本生成的效果是要好于fine-tuning的,ft的在200和500的数据环境中生成的效果和pt的100-200的数据环境差不多。对于右边的四个评价指标我们会在本篇最后的评估指标中讲到。
这组结果也表明了在低数据环境中,前缀调优相对于全参微调表现出更好的性能。
低秩适应方法(Low-Rank Adaptation of Large Language Models, Lora)
这是一个Transformer整体架构图,通过刚刚的介绍我们可以知道prefix-tuning还是在输入层对大模型进行调整,那我们接下来再来介绍一下lora这种方法。
技术概念

大型模型难以顾及单一领域特别是传统文化的深度。庞大的训练集使大型模型无法灵活应用于垂直领域内容,微软的研究人员提出了大语言模型的低秩适应方法(Low-Rank Adaptation of Large Language Models, Lora)的概念,旨在通过少量素材为生成内容添加特征。它通过对原始预训练模型进行降维和升维,减少微调时的计算复杂度。降维可以使得模型参数更少,计算资源需求更低,从而提高训练速度。升维则有助于提高模型在特定任务上的表现。LoRA 的精妙之处在于,它相当于在原有大模型的基础上增加了一个可拆卸的插件,模型主体保持不变。LoRA 随插随用,轻巧方便。
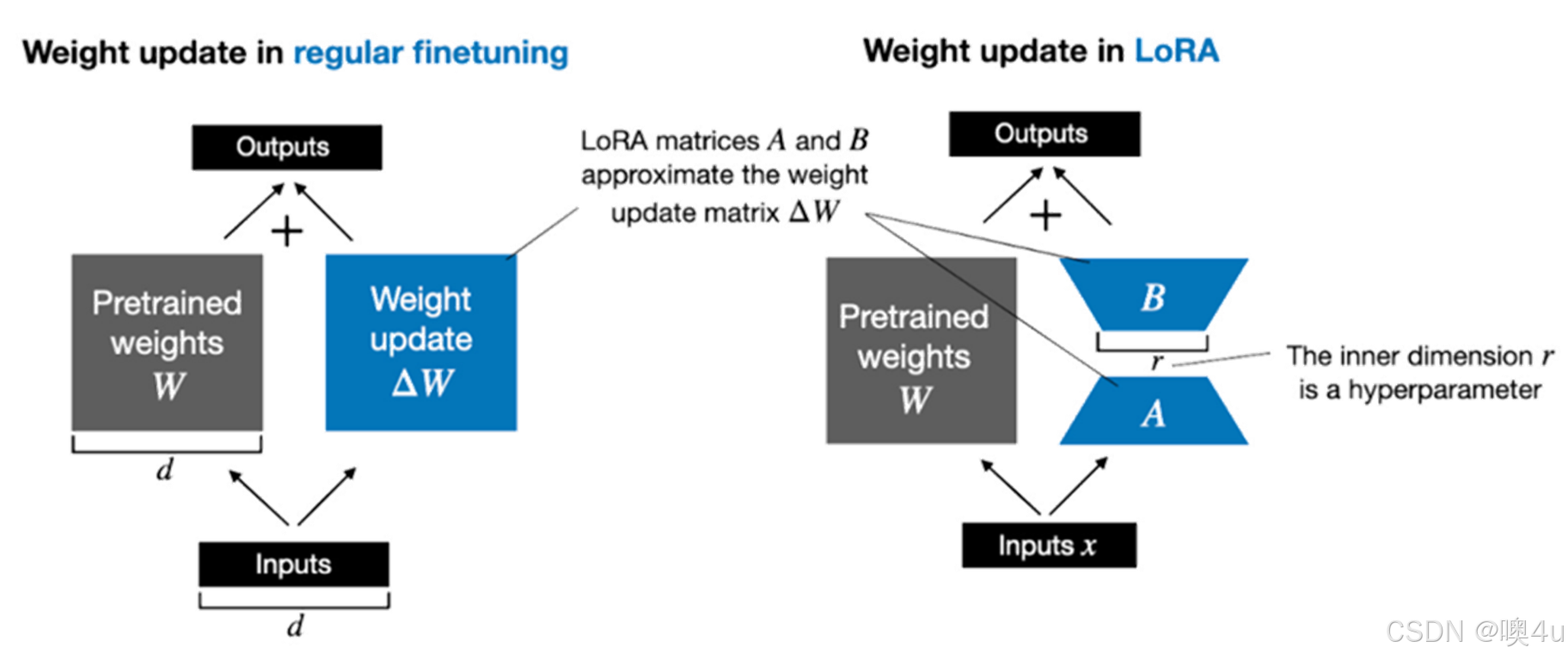
例如,假设我们有一个 7B 参数的语言模型,用一个权重矩阵 W 表示。权重矩阵W用于表示模型中的可学习参数,用于将输入数据映射到模型的隐藏层或输出层。在神经网络中,权重矩阵连接了神经元(具体可见本专栏《6.神经网络模型》)之间的输入和输出,决定了信号在网络中的传递和转换。在反向传播期间(《6.神经网络模型》),模型需要学习一个 ΔW 矩阵,旨在更新原始权重,让损失函数(《6.神经网络模型》)值最小。如果权重矩阵 W 包含 7B 个参数,则权重更新矩阵 ΔW 也包含 7B 个参数,计算矩阵 ΔW 非常耗费计算和内存。LoRA的优势就在这里。如上图所示,这就是 LoRA 节省计算资源的奥秘。ΔW 的分解意味着我们需要用两个较小的 LoRA 矩阵 A 和 B 来表示较大的矩阵 ΔW。如果 A 的行数与 ΔW 相同,B 的列数与 ΔW 相同,我们可以用矩阵乘法表示以上的分解,记为 ΔW = AB。这种方法节省了多少内存呢?
例如,如果 ΔW 有 10,000 行和 20,000 列,则需存储 200,000,000 个参数。秩 r 是一个超参数。如果我们选择 r=8 的 A 和 B,则 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 + 8×20,000 = 240,000 个参数,比 200,000,000 个参数少约 830 倍。
那么这个权重矩阵是怎么得到的呢?
LoRA(Layer-wise Relevance Adjustment)的工作原理类似于给不同层级的神经网络“打分”,然后根据这些分数调整每个层级的重要性,以便更好地适应特定任务。
- 1. 给不同层级打分:首先,LoRA 分析模型在某个任务中各个层级的贡献。它会考虑每个层级在任务中的重要性,比如某些层级可能对任务更关键,而其他层级可能对任务影响较小。
- 2. 调整层级的重要性:接下来,LoRA 根据这些分析结果,模型在任务中的表现,调整每个层级的重要性。它会给模型的每个部分“分配更多注意力”,使得对任务影响较大的层级得到更多的权重,而对任务影响较小的层级则降低其权重。
- 3. 监控和调整:最后,在微调的过程中,你可以监控 LoRA 的效果,并根据需要对其参数进行调整,以获得更好的微调效果。
技术升级

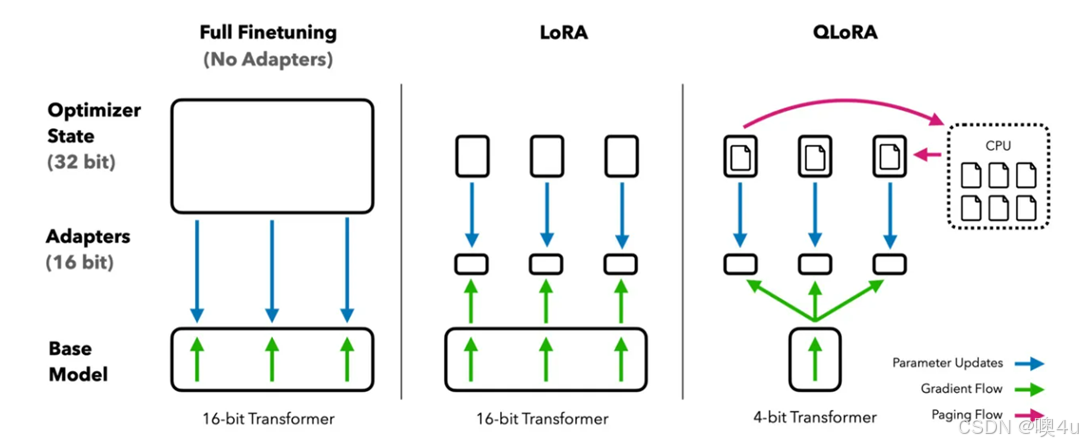
在刚刚这个过程中,层级重要性完全是根据模型判断当前层级对任务印象的大小来判断的,有一定的可能会造成错误
AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。主要就是通过调整增量矩分配、以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量、在训练损失中添加了额外的惩罚项。然而,微调非常大的模型代价非常昂贵;尽管lora已经极大的缩小了所需学习的权重矩阵的参数的数量,但以 LLaMA 65B 参数模型为例,常规的 16 bit微调需要超过 780 GB 的 GPU 内存。
QLoRA使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。QLORA 有一种低精度存储数据类型(4 bit),还有一种计算数据类型(BFloat16)。实际上,这意味着无论何时使用 QLoRA 权重张量,我们都会将张量反量化为 BFloat16,然后执行 16 位矩阵乘法。QLoRA通过这种技术技术实现高保真 4 bit微调。此外,还引入了分页优化器,以防止梯度检查点期间的内存峰值,从而导致内存不足的错误。
技术应用


以下是本草大模型的github主页,这是一个开源的基于LLaMA-7B的使用LoRa微调后的精通于中医药领域的大模型。这是它多轮对话的数据内容,蓝色部分就是融入到多轮对话中的文献信息,绿色部分是chatgpt自身补充的外部知识。大家感兴趣的话可以课后自己去探究。

技术对比

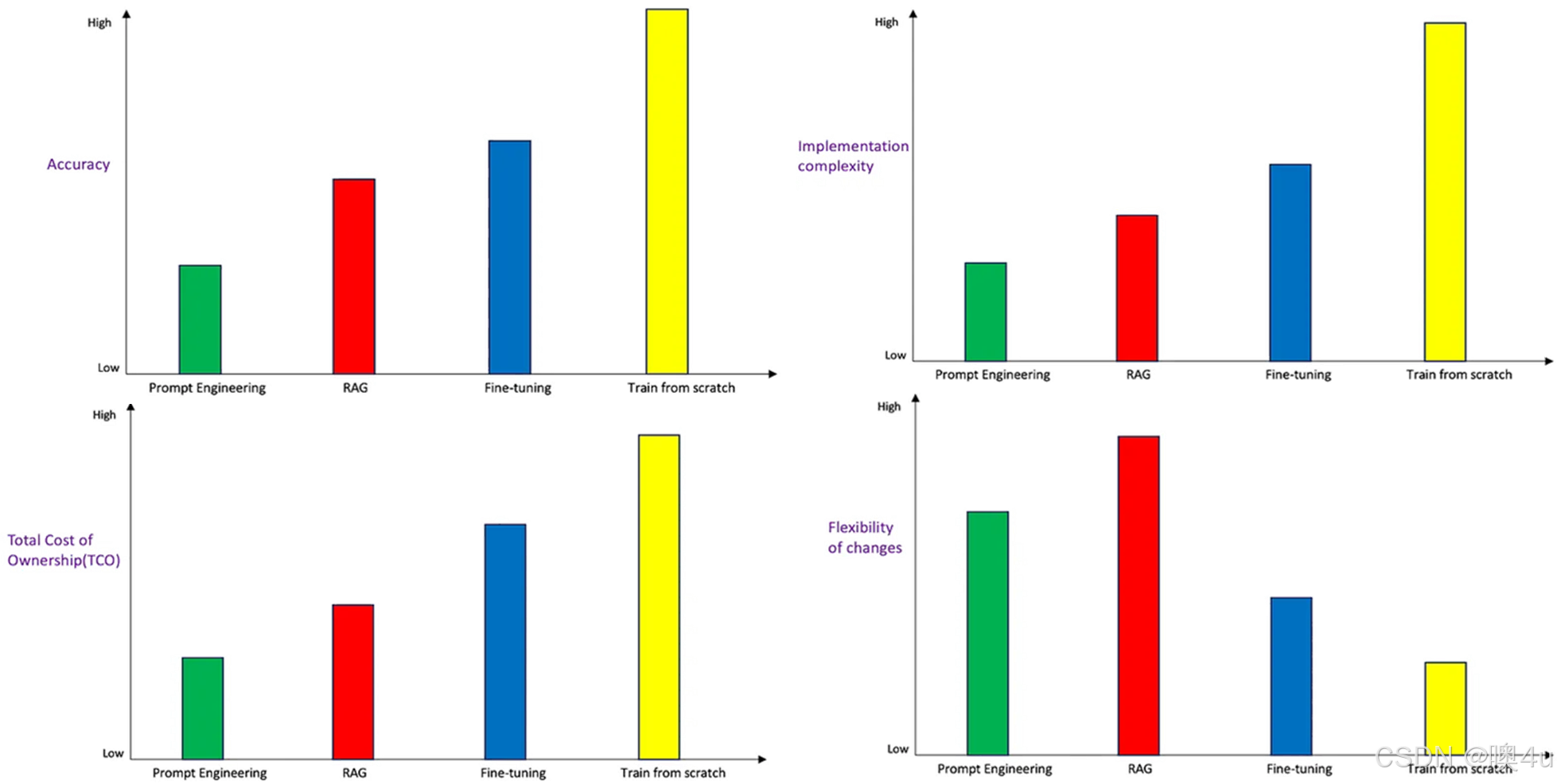
在此图中,复杂性、成本和质量等各种因素沿单个维度表示。但是我认为,将 RAG 和微调视为实现相同结果的两种技术过于简单化,只是其中一种技术比另一种更便宜、更简单。它们从根本上是不同的。
- RAG 虽然在整合外部知识方面功能强大,但主要侧重于信息检索,并且本身并不根据检索到的信息来调整其语言风格或领域特异性。它将从外部数据源提取相关内容,但可能不会展现微调模型可以提供的定制细微差别或领域专业知识。
- 微调的优势在于能够使LLM的行为适应特定的细微差别、语气或术语。如果我们希望模型听起来更像医学专业人士,以诗意的风格写作,或者使用特定行业的术语,那么对特定领域的数据进行微调可以让我们实现这些定制。这种影响模型行为的能力对于与特定风格或领域专业知识保持一致至关重要的应用程序至关重要。
我们当然也可以使用两者混合的模式来进行调整。

因此,我们可以通过一些指标来选择微调的方式。减少幻觉是不是至关重要?就像图一,RAG的高质量结果是由于直接来自向量化信息存储的增强用例特定上下文。与提示工程相比,它产生了大幅改善的结果,并且极低几率出现幻觉。这里ft准确率更高的原因我个人认为他是因为我们正在使用特定领域的数据更新模型权重。最后一幅图考虑数据的动态程度如何?如果先前摘要的数据库是静态的或很少更新,则微调模型的知识可能会在较长时间内保持相关性。然而,如果摘要更新频繁,并且模型需要不断地与最新的风格变化保持一致,那么 RAG 可能会因其动态数据检索功能而具有优势。
迁移学习(Transfer Learning)
我们了解了几种模型微调技术后,再来引入一个新的概念,迁移学习。
技术概念
什么是迁移学习?迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学习社区持续关注的话题。
迁移学习对人类来说很常见,例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。
简单来说,迁移学习的核心就是相似性,是一种以不变应万变的手段。通过刚刚的介绍,我们不难想到fine-tuning,也就是指令微调,就是一种迁移学习的方法。finetune就是利用别人己经训练好的网络,针对自己的任务再进行调整。
技术背景-为什么需要迁移学习
讲到这里应该清楚我们为什么需要迁移学习了:
- 1.大数据与少标注的矛盾:虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型。人工进行数据标定太耗时。
- 2.大数据与弱计算的矛盾:普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移。
- 3.普适化模型与个性化需求的矛盾:即使是在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在不同人之间做模型的适配。有可能还会有一些特定应用有一些特定的需求。下图就是对迁移学习的分类。我们分别举个例子了解一下。
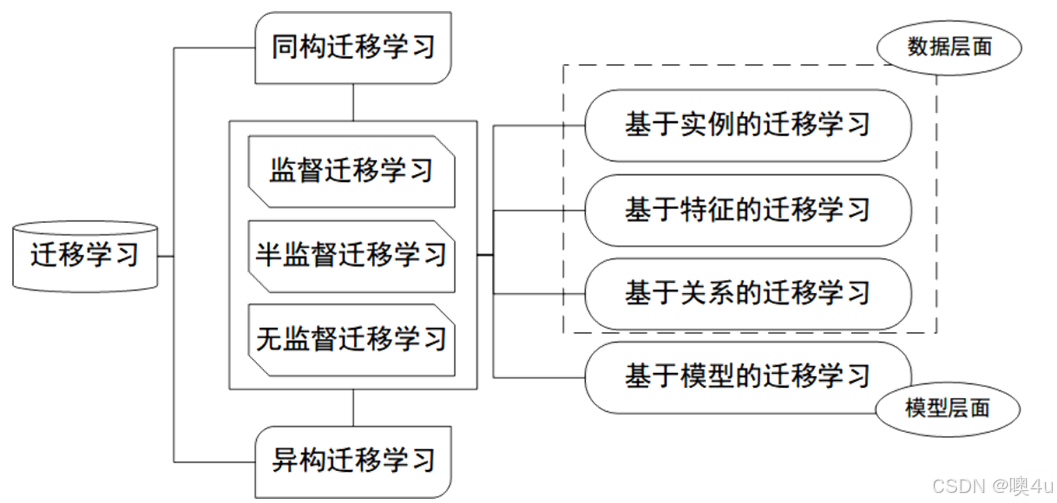
基于实例的迁移学习(Instance based Transfer Learning)
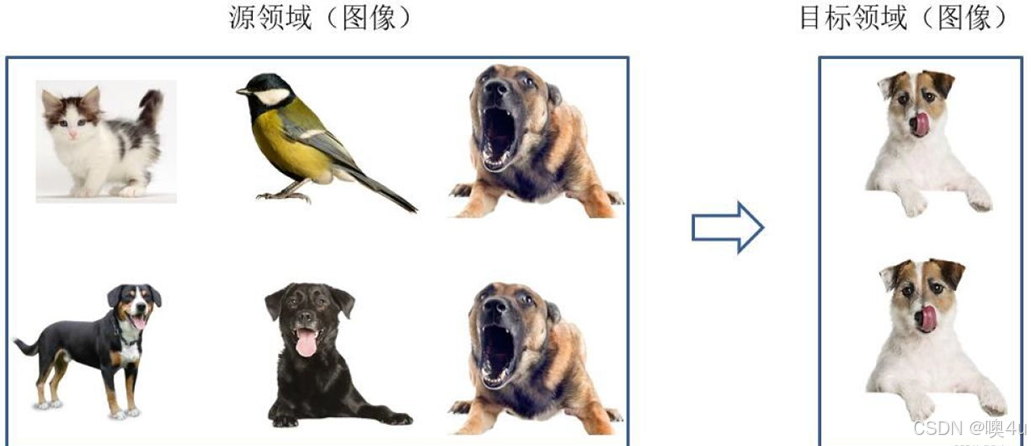
基于样本的迁移学习方法 根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。这张图形象地表示了基于样本迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重。
基于特征的迁移方法 (Feature based Transfer Learning)

基于特征的迁移方法是指将通过特征变换的方式互相迁移,来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法(详细可见本专栏的《4.4 分类》)进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。图片很形象地表示了两种基于特征的迁移学习方法。
基于模型的迁移方法 (Parameter/Model based Transfer Learning)
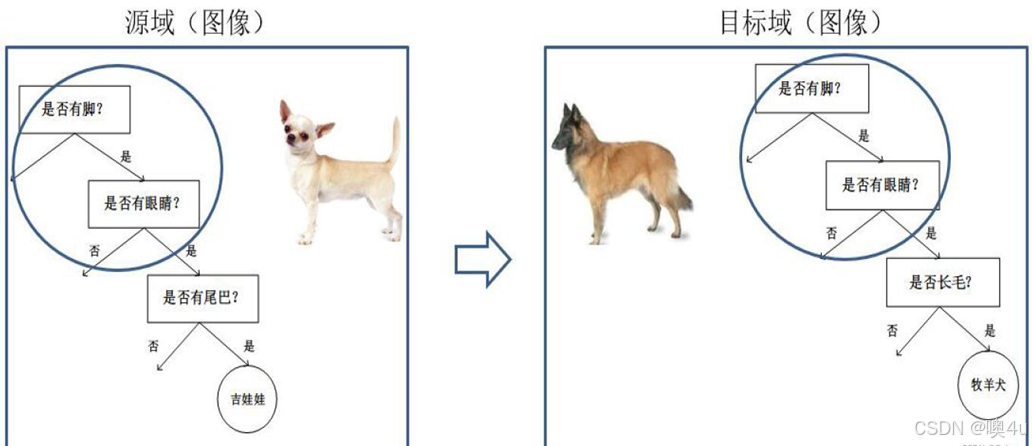
基于模型的迁移方法是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是: 源域中的数据与目标域中的数据可以共享一些模型的参数。图片形象地表示了基于模型的迁移学习方法的基本思想。
基于关系的迁移学习方法 (Relation Based Transfer Learning)

与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。图片形象地表示了不同领域之间相似的关系。
迁移学习相比开发一个机器学习项目,主要的区别就在于重用并调整模型。
领域适应技术
领域适应就是在特定场景下的迁移学习应用。领域自适应技术是在迁移学习的基础上进一步发展,它的核心思想是根据新领域的数据动态调整模型参数,以便更好地适应新领域的特点。领域自适应技术的主要特点是可以在不同领域之间实现更高的泛化能力,从而更好地适应不同的应用场景。
大模型文本生成的评估方法
我们在微调技术最后的对比中提到了几种模型的评估方法,这都是基于“准确性”指标的。
BLEU(Biligual Evaluation understudy)
BLEU是一种用来评估机器翻译的评价指标,广泛出现在文本生成的论文当中。

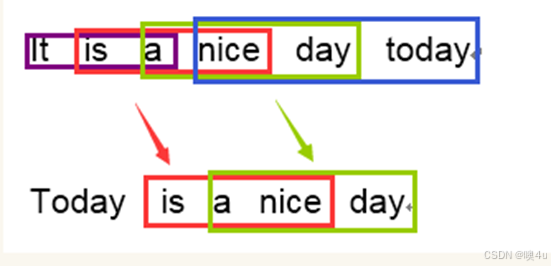

BLEU采用一种N-Gram的匹配规则,具体来说就是比较译文和参考文献之间的N组词的相似度。上面这幅图采用的是1-Gram匹配,在不考虑语序的前提下,Candidate中五个词命中了参考译文,于是Score(1-gram)=5/6。下面这幅图是3-Gram。Candidate中有两个三元词汇命中了Reference中的四个三元词汇,于是Score(3-gram)=2/4。
N-gram匹配法则可以理解为,1-gram匹配时,代表Candidate中有多少个单词是正确翻译的,而2-gram~4-gram匹配就代表了Candidate的流畅程度。但是他的优缺点也显而易见。在最下面这个例子中,candidate中的the与reference中的the全部命中,但这显然是不合理的。
BLEU的好处:
- (1)速度快、成本低廉;
- (2)容易理解;
- (3)不受语种限制;
- (4)运用广泛。
BLEU的缺点:
- (1)忽略同义词;
- (2)N-gram的机制会导致某项分数特别低;
- (3)BLEU不考虑意义;
- (4)BLEU不考虑句子的结构,很多时候,只要单词相同BLEU就会给出很高的分数;
- (5)BLEU不能够很好地处理形态丰富的语言;
- (6)BLEU与人类的判断并不相符合。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
它是评估自动文摘以及机器翻译的一组指标。它通过将自动生成的摘要或翻译与一组通常由人工生成的参考摘要进行比较计算,得出相应的分值,以衡量自动生成的摘要或翻译与参考摘要之间的“相似度”。

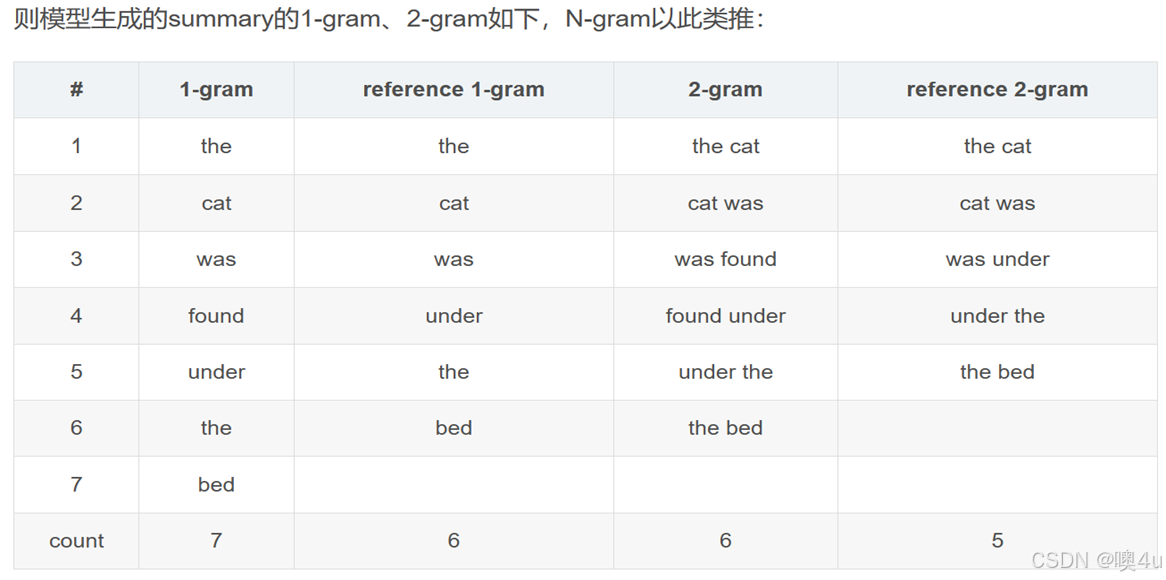
例如:Rouge-1(X,Y)= 6/6=1.0:分子是待评测摘要和参考摘要都出现的1-gram的个数,分母是参考摘要的1-gram个数。Rouge-2(X,Y)= 5/4=0.8。
Rouge-L
L是longest common subsequence首字母,因Rouge-L使用了最长公共子序列。

优点:使用LCS的一个优点是它不需要连续匹配,而且反映了句子级词序的顺序匹配。由于它自动包含最长的顺序通用n-gram,因此您不需要预定义的n-gram长度。
缺点:只计算一个最长子序列,最终的值忽略了其他备选的最长子序列及较短子序列的影响。
Rouge-S
即使用了skip-grams,在参考摘要和待评测摘要进行匹配时,不要求gram之间必须是连续的,可以“跳过”几个单词,比如skip-bigram,在产生grams时,允许最多跳过两个词。比如“cat in the hat”的 skip-bigrams 就是 “cat in, cat the, cat hat, in the, in hat, the hat”。
优点:考虑了所有按词序排列的词对,比n-gram模型更深入反映句子级词序。
缺点:若不设定最大跳跃词数会出现很多无意义词对。若设定最大跳跃词数,需要指定最大跳跃词数的值。

总结
大模型在自然语言处理中的优化和评估主要围绕微调和领域适应技术展开。微调包括知识注入和指令微调,使模型在特定任务或领域的表现更为精准。知识注入通过外部检索增强生成(RAG)帮助模型获取信息,而指令微调则通过对模型参数的优化(例如Prefix Tuning和LoRA)来调整输出。LoRA通过低秩适配减少微调的计算需求,提高特定领域内容的生成效果。此外,迁移学习在优化过程中起到重要作用,通过重用已训练模型在新任务中的知识,减轻标注和计算资源的压力。在评估方面,主要采用BLEU和ROUGE等指标衡量生成文本的准确性和流畅度。未来的优化重点将是提升模型的高效性、可解释性和领域适应性。
参考资料
https://zhuanlan.zhihu.com/p/680692103
https://yetingyun.blog.youkuaiyun.com/
《Prompting or Fine-tuning? A Comparative Study of Large Language Models for Taxonomy Construction》
大模型微调-知乎

















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









