









写在前面
网络爬虫常用于从互联网中获取数据,在如今的人工智能和大数据驱动时代极其适用。由于余胜军老师的爬虫课爆笑,我就学习并整理了一些基础爬虫入门的内容,具体的工程项目、js等暂不涉及。
目录
一、基础知识
1. 什么是爬虫
网络爬虫(Web Crawler 或 Spider)通常从一个或若干起始链接开始,自动访问网页并通过解析网页中的超链接,不断“爬取”新的页面并获取相应数据。
核心流程:
- 获取待爬URL:从初始种子URL或其他数据源获取URL。
- 发送请求并获取响应:向目标URL发送HTTP请求,获取网页HTML等资源。
- 解析内容:提取网页中的链接、文本、图片等信息。
- 存储和处理数据:将爬取到的数据按照需要的格式进行存储,以备后续分析或使用。
- 链接去重并继续爬取:对提取到的新的链接去重后,加入待爬队列,重复上述过程。
网络爬虫的用途:
- 搜索引擎索引:例如百度、谷歌的爬虫会爬取互联网上的网页信息,构建搜索引擎索引。
- 数据采集与分析:爬虫可帮助企业或研究者批量采集数据,用于市场调研、舆情分析、学术研究等。
- 商业情报与竞品监控:企业可以使用爬虫监控竞争对手价格、活动等信息,辅助商业决策。
- 信息聚合与个性化推荐:例如资讯聚合平台,通过爬虫抓取各大网站的新闻内容,进行筛选与整合。
常见的合法合规问题:
-
robots 协议(robots.txt):网站通常会在根目录放置
robots.txt文件,通过规定哪些路径允许或禁止爬取,为爬虫提供抓取指令。虽然robots协议并非法律强制,但它是一种行业规范,守规的爬虫应当遵守。 -
隐私保护与个人信息收集:爬虫过程中若涉及采集个人信息,需要注意各国或地区的隐私保护法律法规(如GDPR等)。不要在未授权的情况下收集、储存或传播用户的敏感信息。
-
数据授权与网站条款:某些网站的用户协议或使用条款可能明确禁止自动爬虫或大规模数据抓取,爬取前应仔细阅读并遵守。如果涉及非公开或付费内容或版权保护范围,需要获得相应授权或遵守网站的访问限制。
如何判断一个网站是否允许爬虫:
-
检查 robots.txt 文件:在浏览器地址栏输入
https://目标网站域名/robots.txt,通常可以查看网站对爬虫的爬取规则,但是不一定所有网站都有robots.txt注明,就像b站就没有。Disallow字段表示禁止爬取的路径;没有在Disallow列表中的页面,一般可视为可爬取,但依旧需要结合网站条款判断。 如:https://www.youkuaiyun.com/robots.txt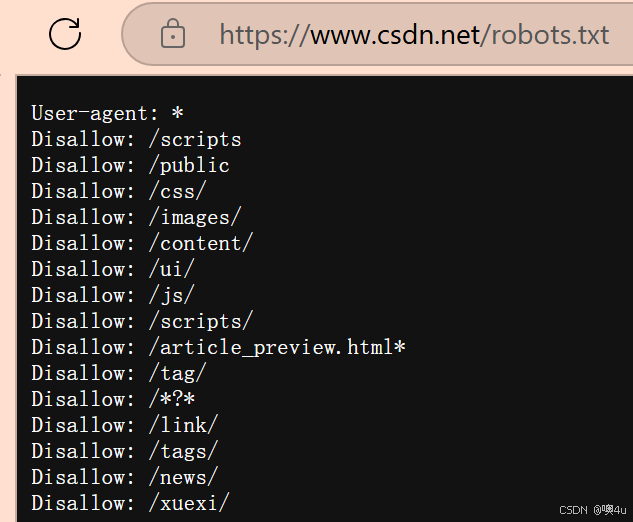
-
查看网站的使用条款或法律声明:部分网站会在服务条款中直接声明禁止任何形式自动化爬取
-
联系网站方或获取API授权:如果数据采集量较大,或目标数据为敏感/付费内容,建议联系网站管理员或平台方,进行数据授权或通过开放API的方式获取。
-
技术层面的封禁信号:有些网站会通过反爬机制(如验证码、人机验证、IP封禁等)来阻止爬虫访问,这在一定程度上也反映了网站对爬虫的态度。
2. HTML 和 CSS
HTML标签
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>示例页面</title>
</head>
<body>
<h1>这是一个标题</h1>
<p>这是一个段落。</p>
<a href="https://example.com">这是一个链接</a>
</body>
</html>

<!DOCTYPE html>:指定文档类型为 HTML5。<html>:HTML文档的根元素。<head>:存放页面的元信息(如<meta>(文档的字符编码)、<title>、样式、脚本等)。<body>:页面主体,包含可见的内容(文本、图片、链接、表单等)。
常见 HTML 标签
- 标题标签(
<h1>~<h6>):表示从大到小的标题层级。 - 段落标签(
<p>):表示文本段落。 - 链接标签(
<a href="...">):超链接,用于跳转到其他页面或资源。 - 列表标签(
<ul>、<ol>、<li>):无序列表、有序列表,以及列表项。 - 表格标签(
<table>、<tr>、<td>、<th>):用于显示结构化表格数据。 - 图像标签(
<img src="..." alt="..." />):在页面中插入图片。 - 表单相关标签(
<form>、<input>、<select>等):用于提交数据。
DOM 结构
DOM(Document Object Model)是把 HTML 文档表示为一棵树形结构。在这棵树中,每一个标签(如 <body>、<div>、<p> 等)都被视为一个DOM节点,各个节点之间存在父子关系、兄弟关系。
- div 是 HTML(超文本标记语言)中的一个常用块级元素,全称通常被理解为 "division"(区块或分区)的缩写。它最主要的用途是 将网页内容进行分块,从而便于在 CSS 中针对不同块进行样式、布局或脚本操作。与
p(段落)、header(页眉)、nav(导航)等带有特定语义的标签不同,div并不包含具体含义,仅用于作为 容器 来组织页面结构。这意味着div可以用来包装任何内容,比如文本、图片、表格、表单等。由于div没有语义本身,我们往往给它加上class或id属性,以便在 CSS 或 JavaScript 中进行样式、脚本操作。适用于页面大块结构布局或组合多个元素。
以上面这段简单的html代码为例,DOM结构可抽象为:
html (DocumentElement)
├── head
│ ├── meta (charset="UTF-8")
│ └── title
└── body
├── h1
├── p
└── a (href="https://example.com")
利用浏览器 F12 获取 JSON 数据
在开发或采集数据时,我们不一定需要“爬取”HTML中的 DOM 来提取信息。有些网站或前端页面是通过 Ajax 或 API 调用获取 JSON 数据,然后再在页面上渲染展示。此时,我们可以 直接调用这些接口 来获取结构化的 JSON 数据,减少 DOM 解析的复杂度。
以下是一个简要操作步骤示例(以 Edge 浏览器为例):
-
打开开发者工具: 在浏览器中打开目标网页,按下
F12或在菜单选择“检查”进入开发者工具。
-
切换到“Network”面板: 确保勾选
Preserve log(以免刷新页面时清空日志)。可以在页面加载或点击某个按钮时观察有哪些网络请求发生。 -
过滤或查找 JSON 请求: 在
Network面板中,会看到许多请求:HTML、CSS、JS、图片、接口请求等。通常可以通过“过滤”关键字或选择“XHR”/“Fetch” 来只看 Ajax(或 Fetch)请求。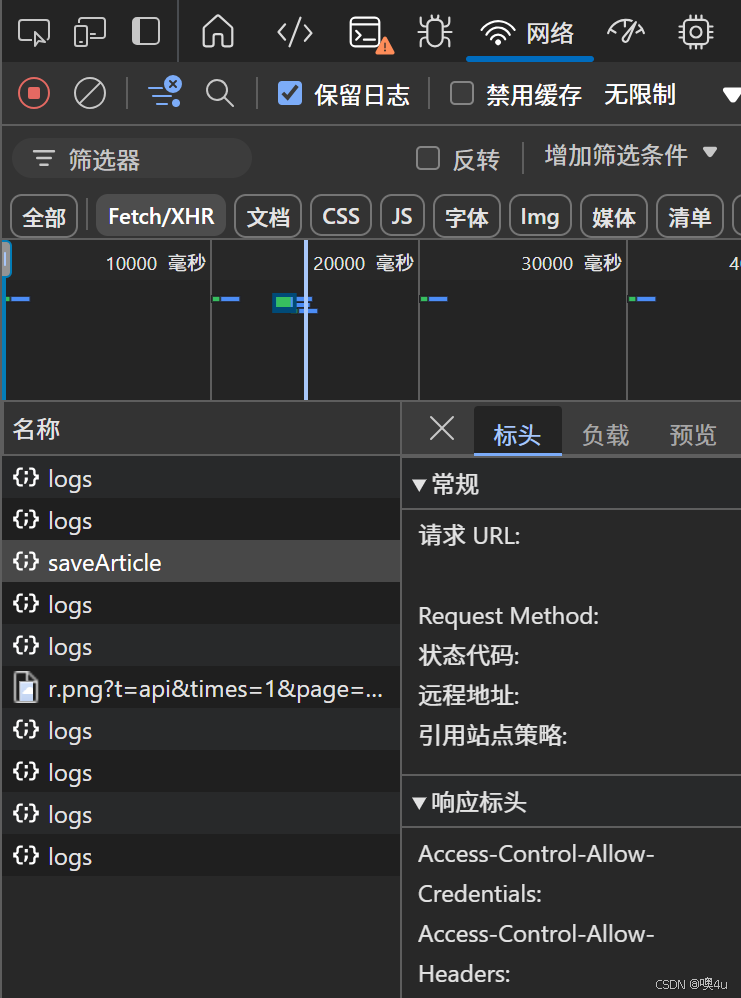
-
查看请求和响应: 选中某个可疑的接口请求,在 Headers 中查看请求 URL、请求方法(GET、POST 等)、请求参数等。在 Preview 或 Response 中查看服务器返回的数据,如果看到类似 JSON 结构,那么恭喜,你找到了可以直接获取数据的接口。,以我现在编辑这篇文章的草稿点击“保存草稿”为例:

具体的request库等会在后续篇幅中分享。
import requests
# 示例请求地址(以实际接口为准)
url = "https://example.com/api/saveArticle"
# 发起 GET 或 POST 请求,具体视接口而定
response = requests.get(url)
# 将响应内容解析为 JSON
json_data = response.json()
# json_data 就是一个字典类型 (dict), 与上面的结构对应
# 例如可以获取 code、traceId、data、msg
code = json_data["code"]
trace_id = json_data["traceId"]
data = json_data["data"]
article_id = data["article_id"]
article_url = data["url"]
message = json_data["msg"]
print("code =", code)
print("traceId =", trace_id)
print("article_id =", article_id)
print("article_url =", article_url)
print("msg =", message)
CSS 基础
CSS(Cascading Style Sheets,层叠样式表)用于控制网页的外观和布局,与 HTML 一起构成 Web 前端的核心技术。HTML 负责 结构(内容和语义),CSS 负责 样式(视觉呈现),JavaScript 负责 交互(动态功能)。
常见的 CSS 选择器
选择器的作用就是告诉浏览器:要对哪些元素应用样式。掌握各种类型的选择器,有助于更精准地控制页面元素的样式。在.css文件中:
1. 元素(标签)选择器:语法:直接使用元素名
/* 所有 p 元素文字颜色为红色 */
p {
color: red;
}
2. 类选择器(class):语法:以 . 开头,后面跟类名
.highlight {
color: blue;
font-weight: bold;
}
在html中:(一个 class 可以被多个元素使用,也可以在一个元素上加多个 class。)
<p class="highlight">这是高亮段落</p>
<span class="highlight">这是高亮文本</span>
3. ID 选择器(id):语法:以 # 开头,后面跟 id 名
#header {
background-color: #f0f0f0;
padding: 20px;
}
HTML 中:(id 在同一个页面里应该是唯一的,不宜重复使用。)
<div id="header">
<h1>网站标题</h1>
</div>
4. 层级选择器:
- 后代(descendant)选择器:用空格表示,匹配某元素内部(任意层级)包含的目标元素
div p { color: green; }表示选择所有位于
div内部的p元素(可能是子元素、孙元素、曾孙元素...)。 -
子(child)选择器:用
>表示,只匹配直接子元素ul > li { list-style: none; }表示选择
ul的直接子元素li,跳过更深层的嵌套。 -
相邻兄弟选择器(
+):匹配紧挨着某元素后面的兄弟元素h2 + p { margin-top: 0; }表示选择紧跟在
h2后面的那个p元素。 -
通用兄弟选择器(
~):匹配后续的所有兄弟元素h2 ~ p { color: gray; }
5. 属性选择器: 根据元素的属性或属性值进行筛选
/* 匹配含有 src 属性的 img 标签 */
img[src] {
border: 1px solid #ccc;
}
/* 匹配 href 的值以 https 开头的所有 a 元素 */
a[href^="https"] {
color: green;
}
/* 匹配 href 的值以 .pdf 结尾的所有 a 元素 */
a[href$=".pdf"] {
color: red;
}
/* 匹配 href 的值包含 'blog' 的所有 a 元素 */
a[href*="blog"] {
text-decoration: underline;
}
6. 伪类选择器(pseudo-classes)例如 :hover, :active, :focus, :nth-child(), etc.
a:hover {
color: orange;
}
/* 鼠标悬停时,链接变为橙色 */
7. 伪元素选择器(pseudo-elements)例如 ::before, ::after, ::first-line, etc.
p::before {
content: "提示:";
font-weight: bold;
}
/* 在每个 p 的内容前插入“提示:”文字 */
布局基础
盒模型(Box Model)
所有的 HTML 元素都可以看成一个矩形框,包含:
- content(内容区域)
- padding(内边距)
- border(边框)
- margin(外边距)
一个元素的最终所占空间 = content + padding + border + margin
常见布局方式
1. 传统布局:
- 基于
display属性:block,inline,inline-block等 - 基于浮动(
float)实现左右布局,需要清除浮动等技巧(旧式方法,现在用得少一些)。
2. 弹性盒布局(Flexbox):非常常用,能方便地控制元素在一维空间(行或列)上的对齐、分布和排序。
.container {
display: flex; /* 设置为弹性容器 */
justify-content: space-between; /* 主轴对齐方式 */
align-items: center; /* 交叉轴对齐方式 */
}
.container > div {
flex: 1; /* 子元素均分可用空间 */
}
以下示例展示了一个简单的头部导航栏,用 弹性盒 布局方式实现等宽分布:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Flexbox 示例</title>
<style>
/* 全局样式 */
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: sans-serif;
}
/* 容器设置为 Flex 布局 */
.navbar {
display: flex;
background-color: #f0f0f0;
padding: 10px;
justify-content: space-around; /* 每个项目在主轴上均匀分布 */
align-items: center; /* 垂直方向居中对齐 */
}
/* 导航项 */
.nav-item {
text-decoration: none;
color: #333;
font-weight: bold;
padding: 5px 10px;
}
.nav-item:hover {
background-color: #ddd;
}
</style>
</head>
<body>
<div class="navbar">
<a class="nav-item" href="#">首页</a>
<a class="nav-item" href="#">文章</a>
<a class="nav-item" href="#">关于</a>
<a class="nav-item" href="#">联系</a>
</div>
</body>
</html>

3. 网格布局(CSS Grid) 在二维空间(行、列)上进行布局,可构建更复杂的页面结构。
.grid-container {
display: grid;
grid-template-columns: 1fr 1fr 1fr; /* 3 列均分 */
gap: 10px; /* 网格间距 */
}
.grid-item {
background-color: #ccc;
border: 1px solid #333;
text-align: center;
}
4. 绝对定位 / 固定定位:position: absolute; / position: fixed; 让元素脱离正常文档流,可以用来做浮动按钮、悬浮栏等特殊布局。
3. HTTP 协议
HTTP(HyperText Transfer Protocol) 是浏览器和服务器进行通信的主要协议,也是网络爬虫在爬取网页时所使用的核心协议。简单来说,当爬虫发送一个 HTTP 请求 到服务器后,服务器会返回一个 HTTP 响应,其中包含了网页内容(HTML、JSON、图片等)。在大多数爬虫场景下,最常见就是发送 GET 请求去获取网页内容;有时也需要模拟POST 请求。
常见的 HTTP 方法(动词)
- GET:获取资源(如访问网页、下载文件等),在爬虫中最常见。特点:
- 请求参数通常跟在 URL 后面
- 请求通常被缓存,查询操作多用 GET。
url = "https://example.com/search" params = {"q": "python 爬虫", "page": 1} # 将自动拼接 ?q=python+爬虫&page=1 response = requests.get(url, params=params) print(response.text) # 响应的 HTML 或 JSON
- POST:用于向服务器提交数据(如表单提交、登录操作等)。特点:
- 请求参数放在请求体中(body),而不是 URL 后面。
- 更适合发送敏感或较大数据,服务器会在某些情况下要求必须用 POST。
url = "https://example.com/login" data = {"username": "test", "password": "123456"} response = requests.post(url, data=data) print(response.json()) # 可能返回 JSON,例如登录成功信息
- 其他方法(PUT、DELETE、HEAD、OPTIONS 等)在大多数爬虫场景中较少用到。
常见的 HTTP 请求头
当爬虫向服务器发送 HTTP 请求时,会包含一些 请求头(Headers)。这些头信息在一定程度上可以告诉服务器客户端的特征或请求意图,也可能会影响到服务器对请求的响应方式。
- User-Agent:表示客户端(浏览器或爬虫程序)的身份字符串。有以下作用:
- 伪装成真实浏览器:很多网站会通过检查
User-Agent来识别爬虫,如果使用默认的爬虫 UA(如python-requests或Scrapy默认 UA),可能会触发反爬措施。 - 应对不同终端响应:有些网站针对不同 UA 可能返回移动端/PC端不同页面。
- 基本礼仪:在工业标准中,也可以在 UA 中带上自己的联系信息或项目名称,以示尊重(但很多时候爬虫往往会伪装成常见浏览器 UA)。
import requests headers = { "User-Agent": "..." } response = requests.get("https://example.com", headers=headers)
- 伪装成真实浏览器:很多网站会通过检查
- Cookies:是服务器在客户端(浏览器/爬虫)上存储的小块数据,用于记录用户状态或偏好。
- 保持会话状态:如登录后会在 Cookies 中存储 session id,后续请求需要携带该 Cookies 才能保持登录状态。
- 反爬或限速:部分网站会用 Cookies + JavaScript 结合,判断是否为异常访问(重复刷新、自动访问等)。
- 模拟用户行为:在爬虫中,如果需要访问需要登录的页面或带有个性化信息的页面,就需要携带对应 Cookies。
- Referer(也写作 Referrer):告诉服务器当前请求来自哪个页面(即上一个访问页面的网址)。浏览器在访问一个链接时,通常会将所跳转页面的 URL 作为
Referer发送给服务器,以便服务器做统计或防盗链等。- 防盗链绕过:某些网站会验证
Referer,如果不是来自其正规页面,可能返回错误或拒绝请求。 - 模拟正常用户访问路径:爬虫可以在请求头中设置一个合适的
Referer,伪装成从上一页点击进来,而不是直接访问,减少被识别为爬虫的风险。headers = { "User-Agent": "...", "Referer": "https://example.com/search?page=1" } response = requests.get("https://example.com/detail?id=100", headers=headers)
- 防盗链绕过:某些网站会验证
- Accept、Accept-Encoding、Accept-Language
- Accept:表示客户端能够处理的数据类型(如
text/html,application/json等)。 - Accept-Encoding:表示客户端能够处理的内容编码方式(如
gzip,deflate)。 - Accept-Language:表示客户端偏好的语言(如
en-US,zh-CN)。- 模拟真实浏览器:与
User-Agent搭配使用,填上常见浏览器的Accept等字段,显得更“真实”。 - 获取最佳格式:告知服务器自己可处理哪些格式(HTML / JSON / XML 等)。有时只返回 JSON 即可,能节省流量,也更方便解析。
- 模拟真实浏览器:与
- Accept:表示客户端能够处理的数据类型(如
- Content-Type:在 POST 请求 或其他发送数据的场景中,需要用
Content-Type告诉服务器本次发送的数据格式,如application/json、application/x-www-form-urlencoded、multipart/form-data等。- 提交表单时,需要
application/x-www-form-urlencoded或multipart/form-data。 - 提交 JSON 数据时,需要设置为
application/json。
- 提交表单时,需要
- 避免使用默认的爬虫头:适当设置
User-Agent,Referer,Cookies等,模仿普通浏览器访问,减少被反爬封禁的可能。 - 如果需要持续访问或保持登录态(如爬取私人数据),需要在爬虫中管理好
Cookies或Session,以免每次请求都被视为新的会话。 - 不要以过快的频率爬取,以免给服务器造成负担或触发 IP 封锁。
- 对于需要频繁访问的站点,可以使用 随机休眠 或 限速 手段。
- 处理好状态码(如 403 Forbidden, 404 Not Found, 500 Server Error),不要一直重试,以免造成不必要的流量浪费或被服务器拉黑。
4. python并发编程以及常见的网络库
并发编程概念
并发编程是指在同一时间段内让程序“同时”执行多个任务。狭义的“同时”可能只是逻辑上同时,实际底层可能在不同时间片中轮换执行。
在 Python 中,常见的并发模型包括 多线程(threading)、多进程(multiprocessing)、以及 异步 I/O(asyncio)。具体如何选择,取决于程序的性能瓶颈(CPU 计算密集 vs. I/O 密集)以及对并行/并发的需求。
Threading(多线程)
- 线程(Thread) 是在同一进程内执行的多个控制流,可以共享进程中的全局变量、内存空间、打开的文件句柄等资源。
- 由于 GIL(全局解释器锁) 的限制,在 CPython 中,多个线程无法在同一时刻同时执行 纯 Python 代码。但对于网络 I/O、文件 I/O、等待操作等场景,多线程仍然能带来效率提升。
-
常见应用场景:I/O 密集型任务,如爬虫爬取多个网页、同时处理多个网络请求等。
import threading import time def worker(name): print(f"Worker {name} started") time.sleep(2) print(f"Worker {name} finished") threads = [] for i in range(3): t = threading.Thread(target=worker, args=(i,)) threads.append(t) t.start() for t in threads: t.join() print("All threads done.")Worker 0 started Worker 1 started Worker 2 started Worker 2 finished Worker 0 finished Worker 1 finished All threads done.
Multiprocessing(多进程)
- 进程(Process) 拥有独立的内存空间、系统资源,能够真正利用多核 CPU 实现并行。
- 在 Python 中使用
multiprocessing模块,可以绕过 GIL 的限制,对 CPU 密集型 任务(比如大规模数值计算、图像处理等)更有效。 - 常见应用场景:CPU 密集型任务,如大规模数据分析、图像/视频处理等。
from multiprocessing import Process import os def worker(name): print(f"Worker {name} in process: {os.getpid()}") processes = [] for i in range(3): p = Process(target=worker, args=(i,)) processes.append(p) p.start() for p in processes: p.join() print("All processes done.")Worker 0 in process: 33156 Worker 1 in process: 8848 Worker 2 in process: 33968 All processes done.
Asyncio(异步 I/O)
- 异步 I/O 是指在等待 I/O 时,可以让程序去执行其他任务,而不必被 I/O 阻塞。
- Python 内置的
asyncio库允许使用 协程(coroutine) 的方式编写异步代码,通过event loop来调度协程执行。 - 适合大量网络 I/O、等待操作的场景(比如高并发网络服务器、爬虫等),能够极大地提升吞吐量。
- 常见于:网络服务器,高并发 HTTP/Sockect 服务;异步爬虫(例如结合
aiohttp库);import asyncio import time async def worker(name): print(f"Worker {name} started") await asyncio.sleep(2) print(f"Worker {name} finished") async def main(): tasks = [worker(i) for i in range(3)] await asyncio.gather(*tasks) asyncio.run(main())
常见网络编程库
1. socket 库:Python 标准库自带的 socket 模块是最基础的网络编程接口,允许手动创建TCP/UDP连接,进行底层通信。一般步骤:
- 创建
socket对象(指定AF_INET/AF_INET6与SOCK_STREAM/SOCK_DGRAM等) - 服务器端
bind()+listen()(TCP) +accept();客户端connect() - 发送(
send/sendall)和接收(recv)数据。 - 关闭连接(
close())。import socket host = '127.0.0.1' port = 12345 server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server_socket.bind((host, port)) server_socket.listen(5) print(f"Server listening on {host}:{port}") while True: client_socket, addr = server_socket.accept() print("Connected by", addr) data = client_socket.recv(1024) if not data: break print("Received:", data.decode()) client_socket.sendall(b"Hello from server!") client_socket.close()
更高级的网络库/框架
requests:基于 HTTP 协议的爬虫常用库,用于发起 GET/POST 请求、处理响应等,包装方便。aiohttp:基于asyncio的异步 HTTP 客户端/服务器库,适合高并发异步爬虫。socketserver:Python 标准库里的一个简单框架,用来快速实现服务器端。
5. 可练习爬虫的网站
- Quotes to Scrape http://quotes.toscrape.com/
- 这是一个经典的练习网站,提供一些名人名言,可用于练习爬取文本、翻页、标签等。页面结构简单清晰,非常适合初学者。
- 这是一个经典的练习网站,提供一些名人名言,可用于练习爬取文本、翻页、标签等。页面结构简单清晰,非常适合初学者。
- Books to Scrape http://books.toscrape.com/
- 和 “Quotes to Scrape” 属于同一系列,主要是一本本书的封面、价格、库存状态等信息。可以练习商品信息抓取、分页爬取、图片下载等。
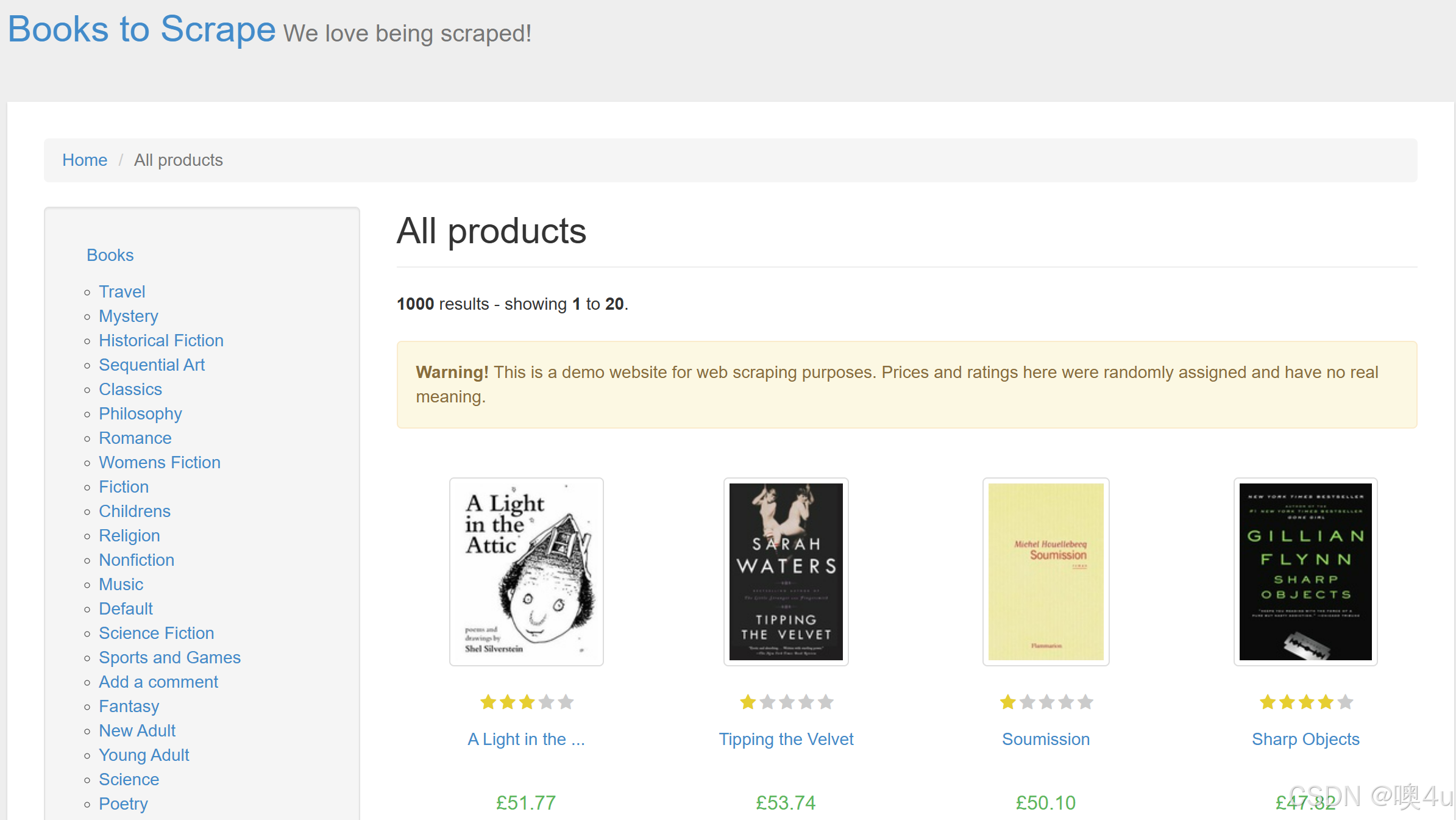
- 和 “Quotes to Scrape” 属于同一系列,主要是一本本书的封面、价格、库存状态等信息。可以练习商品信息抓取、分页爬取、图片下载等。
- JSONPlaceholder https://jsonplaceholder.typicode.com/
- 虽然不属于传统“网页爬取”,但它提供了免费的 REST API,返回 JSON 格式的模拟数据(如用户信息、帖子、评论等)。适合新手练习请求与响应的处理(尤其是
GET/POST等方法)。
- 虽然不属于传统“网页爬取”,但它提供了免费的 REST API,返回 JSON 格式的模拟数据(如用户信息、帖子、评论等)。适合新手练习请求与响应的处理(尤其是
- httpbin https://httpbin.org/
- 一个用来测试 HTTP 请求与响应的网站,可以返回各种响应头、状态码、JSON、带延迟的请求等。适合练习爬虫发送请求、测试重定向、模拟表单提交等。
- 除此之外,还有一些公开数据集如Wikipedia(维基百科)、Archive.org(互联网档案馆)、GitHub 的公共仓库数据、一些 新闻网站(如 BBC、CNN、The Guardian 等) 或者 博客平台(如 Medium)等,但这些都要注意“合法合规性”。
二、初级爬虫
下面通过示例代码的方式,介绍如何使用 requests 库来发送 GET / POST 请求、设置 Headers、Cookies,以及如何使用 requests.Session 进行会话管理。随后,再介绍 BeautifulSoup 库的用法,包括如何利用标签名、属性、CSS 选择器查找节点,以及 find() / find_all() 方法来解析 HTML。为方便演示,我们使用两个经典练习网站,即1.5中提到的前两个网址。
1. Requests 库
基础用法
- 发送 GET 请求
import requests # 示例:获取 Quotes to Scrape 的首页 HTML url_quotes = "http://quotes.toscrape.com/" response = requests.get(url_quotes) print("状态码:", response.status_code) print("部分响应文本:", response.text[:200]) # 仅打印前200字符 # 状态码: 200 # 部分响应文本: <!DOCTYPE html> # <html lang="en"> # <head> # <meta charset="UTF-8"> # <title>Quotes to Scrape</title> # <link rel="stylesheet" href="/static/bootstrap.min.css"> # <link rel="stylesheet" href="/static/mresponse.status_code:查看 HTTP 响应状态码(如 200 表示成功)。response.text:获取返回的页面 HTML(字符串形式)。response.content:获取二进制内容(如下载图片等时使用)。
- 送 POST 请求
import requests url_quotes = "http://quotes.toscrape.com/login" payload = { "username": "test_user", "password": "123456" } response_post = requests.post(url_quotes, data=payload) print("POST状态码:", response_post.status_code) print("POST响应文本:", response_post.text[:200]) # POST状态码: 200 # POST响应文本: <!DOCTYPE html> # <html lang="en"> # <head> # <meta charset="UTF-8"> # <title>Quotes to Scrape</title> # <link rel="stylesheet" href="/static/bootstrap.min.css"> # <link rel="stylesheet" href="/static/m使用代码模拟的是以下过程:
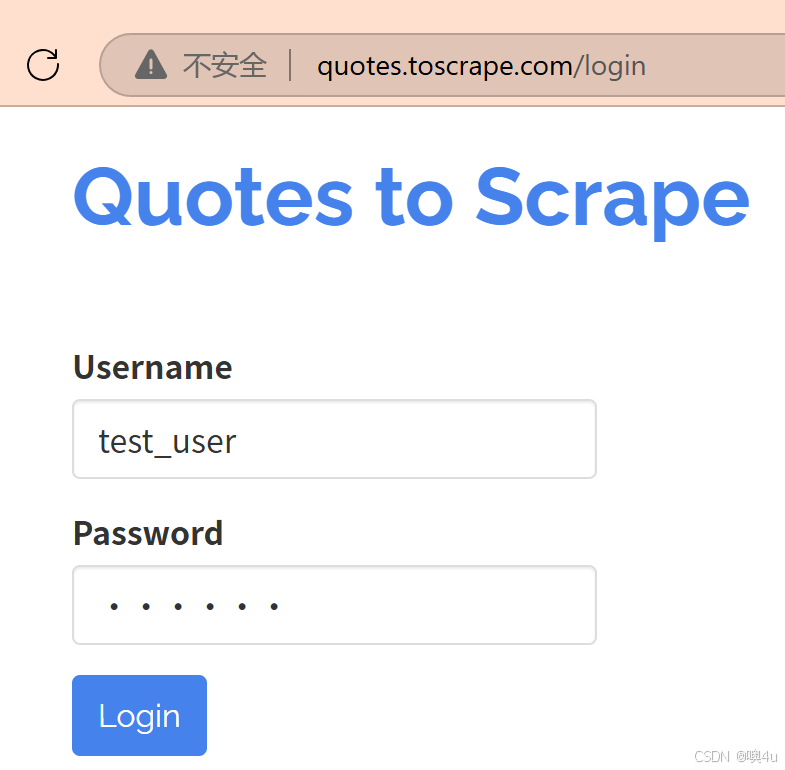
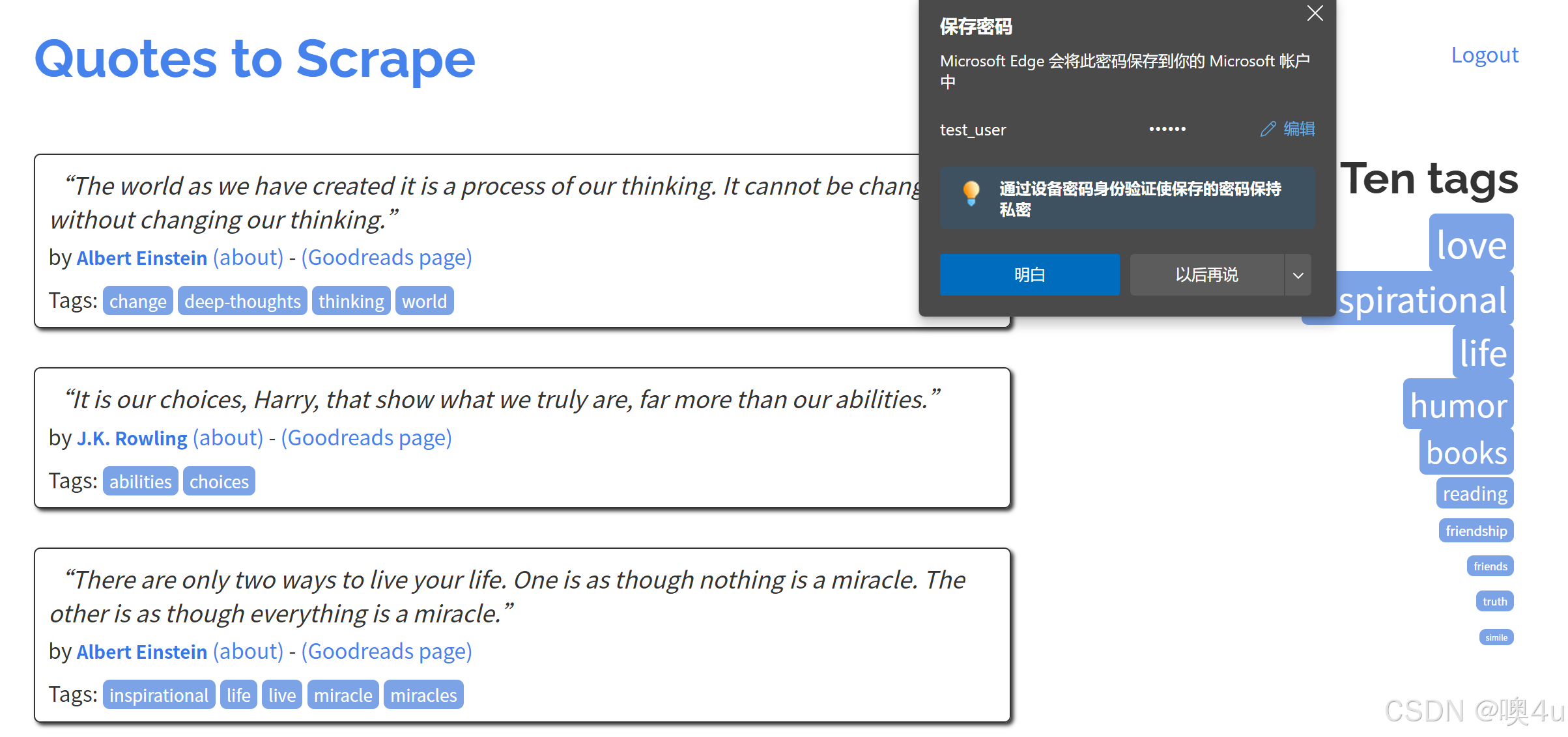
data参数:字典形式,表示要提交的表单字段和对应的值。- 如果某些网站需要 JSON 格式提交,可以用
json=payload而不是data=payload,同时要记得在 Headers 中设置Content-Type: application/json。
- 以上过程也可以用cookies实现
import requests url_quotes = "http://quotes.toscrape.com/login" cookies = { "username": "test_user", "password": "123456" } response_with_cookies = requests.post(url_quotes, cookies=cookies) print("带cookies的状态码:", response_with_cookies.status_code) # 带cookies的状态码: 200 -
使用 Session 对象:
requests.Session()可以在多次请求之间保持会话状态,包括 Cookies、Headers 等信息,实现模拟“登录后操作”、减少重复设置的目的。import requests # 创建一个session session = requests.Session() # 设置通用Headers session.headers.update({ "User-Agent": "Mozilla/5.0" }) # 先访问首页 resp1 = session.get("http://quotes.toscrape.com/") print("访问首页:", resp1.status_code) # 假设登录接口 login_url = "http://quotes.toscrape.com/login" payload = {"username": "test_user", "password": "123456"} resp2 = session.post(login_url, data=payload) print("登录:", resp2.status_code) # 现在的session已经保存了Cookies,再次请求需要登录的页面时就不需要重新登录 profile_url = "http://quotes.toscrape.com/login" resp3 = session.get(profile_url) print("session登录:", resp3.status_code, resp3.text[:200]) # 访问首页: 200 # 登录: 200 # session登录: 200 <!DOCTYPE html> # <html lang="en"> # <head> # <meta charset="UTF-8"> # <title>Quotes to Scrape</title> # <link rel="stylesheet" href="/static/bootstrap.min.css"> # <link rel="stylesheet" href="/static/m
基础异常处理
- 常见异常处理:使用
requests发起 HTTP 请求时,可能会遇到多种异常情况,例如连接超时、地址不可达、服务器错误等。常见的异常类型包括:requests.exceptions.Timeout:超时异常(连接超时或读取超时)requests.exceptions.ConnectionError:网络连接错误(如域名解析失败、目标端口拒绝等)requests.exceptions.HTTPError:HTTP 状态码错误(4xx 或 5xx)requests.exceptions.RequestException:所有 requests 异常的基类,捕获任何未知或通用错误import requests from requests.exceptions import RequestException, Timeout, ConnectionError, HTTPError url = "http://example.com" try: # 设置 5 秒超时 response = requests.get(url, timeout=5) # 如果收到 4xx 或 5xx 状态码,raise_for_status() 会抛出 HTTPError response.raise_for_status() # 请求成功则执行以下逻辑 print("状态码:", response.status_code) print("部分响应:", response.text[:200]) except Timeout: print("请求超时,请检查网络或服务器是否响应缓慢。") except ConnectionError: print("网络连接异常,请检查网络或目标地址是否正确。") except HTTPError as e: print(f"HTTP 错误,状态码: {e.response.status_code},错误信息: {e}") except RequestException as e: print("发生未知错误:", e)timeout=5表示连接和读取的总超时时间为 5 秒,若超过此限制,抛出Timeout异常。- 如果不指定
timeout,默认requests会一直等待服务器响应,可能造成 程序卡死 或 无响应。 - 在网络状况不佳时,超时设置可以让程序尽快报错,从而进行重试或其他处理。
requests的timeout参数既可以是一个数值,也可以是一个元组,分别表示 连接(connect) 和 读取(read) 超时时间:# 同时设置 连接超时 和 读取超时 response = requests.get("http://example.com", timeout=(3, 5))- 第一个值 (3) 表示连接超时,若 3 秒内无法与服务器建立连接则报错。
- 第二个值 (5) 表示读取超时,若已连接但 5 秒内没有收到任何数据则报错。
- 如果不指定
response.raise_for_status():若状态码为 4xx(客户端错误)或 5xx(服务器错误),抛出HTTPError。- 常用异常按从具体到通用的顺序捕获,避免漏掉可能的错误。
- 重试机制:有时由于网络波动、临时服务器故障等导致请求失败,如果简单地报错退出并不理想。可以给请求添加 重试 机制,提升成功率。
- 手动实现重试:最简单的方式是自己写一个循环,进行若干次请求尝试:
import requests import time from requests.exceptions import RequestException def fetch_with_retry(url, max_retries=3, delay=2): for i in range(max_retries): try: response = requests.get(url, timeout=5) response.raise_for_status() return response # 成功则返回 except RequestException as e: print(f"第 {i+1} 次请求失败:{e}") if i < max_retries - 1: print(f"等待 {delay} 秒后重试...") time.sleep(delay) else: print("已达到最大重试次数,放弃。") return None resp = fetch_with_retry("http://example.com/nonexistent", max_retries=3, delay=1) if resp is None: print("请求最终失败。") else: print("请求成功,响应内容:", resp.text[:200]) # 第 1 次请求失败:404 Client Error: Not Found for url: http://example.com/nonexistent # 等待 1 秒后重试... # 第 2 次请求失败:404 Client Error: Not Found for url: http://example.com/nonexistent # 等待 1 秒后重试... # 第 3 次请求失败:404 Client Error: Not Found for url: http://example.com/nonexistent # 已达到最大重试次数,放弃。 # 请求最终失败。- 设置
max_retries尝试次数,每次捕获RequestException。 - 如果当前次数还没到达上限,等待一段时间
delay后再次尝试。 - 如果超过
max_retries,则返回None表示失败。
- 设置
- 使用 requests.adapters.Retry:
requests本身提供了一个 HTTPAdapter + Retry 机制(需要urllib3),可以更优雅地配置重试策略:import requests from requests.adapters import HTTPAdapter from urllib3.util.retry import Retry session = requests.Session() # 配置重试策略 retry_strategy = Retry( total=3, # 总共重试次数 backoff_factor=1, # 失败后延迟策略 (指数型 backoff) status_forcelist=[429, 500, 502, 503, 504], # 遇到这些状态码触发重试 allowed_methods=["HEAD", "GET", "OPTIONS"] # 针对哪些请求方法启用重试 ) adapter = HTTPAdapter(max_retries=retry_strategy) session.mount("http://", adapter) session.mount("https://", adapter) # 之后的请求都带有上面配置的重试 try: response = session.get("http://example.com/nonexist", timeout=5) response.raise_for_status() print("成功响应:", response.text[:200]) except requests.exceptions.RequestException as e: print("最终失败:", e) # 最终失败: 404 Client Error: Not Found for url: http://example.com/nonexistRetry(total=3):最多尝试 3 次(包括第一次)。backoff_factor=1:如果连续请求失败,则会等待 1s、2s、4s…(指数递增)。status_forcelist=[429, 500, ...]:当服务器返回这些状态码时会触发重试。session.mount():将该重试策略应用到所有http://与https://请求上。- 这种方式比较灵活,适合对特定状态码自动重试,并有良好的退避 (backoff) 策略,避免过度频繁地请求服务器。
- 手动实现重试:最简单的方式是自己写一个循环,进行若干次请求尝试:
2. BeautifulSoup 库
- 基本用法
import requests from bs4 import BeautifulSoup url_quotes = "http://quotes.toscrape.com/" response = requests.get(url_quotes) # 创建 BeautifulSoup 对象 soup = BeautifulSoup(response.text, "html.parser") # 查看标题 title = soup.find("title").get_text() print("页面标题:", title) # 页面标题: Quotes to ScrapeBeautifulSoup(response.text, "html.parser"):将获取到的 HTML 字符串解析为可搜索的DOM树。find("title"):查找文档中的第一个<title>标签,返回一个 标签对象(Tag)。get_text():获取标签内的文本内容。
使用 find() & find_all()
soup.find("tag_name", **conditions):返回符合条件的第一个标签。import requests from bs4 import BeautifulSoup url_quotes = "http://quotes.toscrape.com/" response = requests.get(url_quotes) # 创建 BeautifulSoup 对象 soup = BeautifulSoup(response.text, "html.parser") quote_div = soup.find("div", class_="quote") print("第一个 quote div:", quote_div) # 获取作者姓名 author_tag = quote_div.find("small", class_="author") author_name = author_tag.get_text() print("作者:", author_name) # 若还想获取名言文本: quote_text = quote_div.find("span", class_="text").get_text() print("名言内容:", quote_text) # 也可以获取标签信息 tag_elements = quote_div.find_all("a", class_="tag") tags = [tag.get_text() for tag in tag_elements] print("标签:", tags) # 第一个 quote div: <div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork"> # <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span> # <span>by <small class="author" itemprop="author">Albert Einstein</small> # <a href="/author/Albert-Einstein">(about)</a> # </span> # <div class="tags"> # Tags: # <meta class="keywords" content="change,deep-thoughts,thinking,world" itemprop="keywords"/> # <a class="tag" href="/tag/change/page/1/">change</a> # <a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a> # <a class="tag" href="/tag/thinking/page/1/">thinking</a> # <a class="tag" href="/tag/world/page/1/">world</a> # </div> # </div> # 作者: Albert Einstein # 名言内容: “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” # 标签: ['change', 'deep-thoughts', 'thinking', 'world']- 上面将返回页面中第一个
div,且class="quote"的标签。 - 之后可以进一步操作
quote_div获取作者、内容等信息(具体内容储存在哪里,要根据原网页页面的具体HTML 结构,在quote_div中,作者的信息通常放在一个small标签内,并带有class="author")。author_tag = quote_div.find("small", class_="author"):找到<small class="author">这个标签,返回一个标签对象(Tag)。author_name = author_tag.get_text():拿到标签内的文字内容,比如"Albert Einstein"。- 同样方式,可以获取名言的文本(在
<span class="text">内)或标签列表(在<a class="tag">内)。
- 上面将返回页面中第一个
soup.find_all("tag_name", **conditions):返回所有符合条件的标签列表。import requests from bs4 import BeautifulSoup url_quotes = "http://quotes.toscrape.com/" response = requests.get(url_quotes) # 创建 BeautifulSoup 对象 soup = BeautifulSoup(response.text, "html.parser") quotes_divs = soup.find_all("div", class_="quote") print(f"找到了 {len(quotes_divs)} 条名言") for i, div in enumerate(quotes_divs, 1): text = div.find("span", class_="text").get_text() author = div.find("small", class_="author").get_text() print(f"{i}. \"{text}\" —— {author}") # 找到了 10 条名言 # 1. "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”" —— Albert Einstein # 2. "“It is our choices, Harry, that show what we truly are, far more than our abilities.”" —— J.K. Rowling # 3. "“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”" —— Albert Einstein # 4. "“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”" —— Jane Austen # 5. "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”" —— Marilyn Monroe # 6. "“Try not to become a man of success. Rather become a man of value.”" —— Albert Einstein # 7. "“It is better to be hated for what you are than to be loved for what you are not.”" —— André Gide # 8. "“I have not failed. I've just found 10,000 ways that won't work.”" —— Thomas A. Edison # 9. "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”" —— Eleanor Roosevelt # 10. "“A day without sunshine is like, you know, night.”" —— Steve Martin- 如果要找第n个,可在确认第n个确实存在的情况下使用find_all()返回的列表,再取索引[n-1]
- 按属性查找:
import requests from bs4 import BeautifulSoup base_url = "http://quotes.toscrape.com" page_url = "/page/1/" all_love_quotes = [] while True: full_url = base_url + page_url resp = requests.get(full_url) soup = BeautifulSoup(resp.text, "html.parser") # 查找本页所有 "love" 标签锚点 love_anchors = soup.find_all("a", attrs={"class":"tag", "href":"/tag/love/page/1/"}) for anchor in love_anchors: quote_div = anchor.find_parent("div", class_="quote") quote_text = quote_div.find("span", class_="text").get_text(strip=True) author_name = quote_div.find("small", class_="author").get_text(strip=True) all_love_quotes.append((quote_text, author_name)) # 寻找下一页 next_li = soup.find("li", class_="next") if next_li: page_url = next_li.find("a")["href"] else: print("没有下一页了,结束。") break print(f"共找到含 love 标签的名言 {len(all_love_quotes)} 条。") for i, (text, author) in enumerate(all_love_quotes, 1): print(f"{i}. \"{text}\" —— {author}") # 没有下一页了,结束。 # 共找到含 love 标签的名言 14 条。 # 1. "“It is better to be hated for what you are than to be loved for what you are not.”" —— André Gide # 2. "“This life is what you make it. No matter what, you're going to mess up sometimes, it's a universal truth. But the good part is you get to decide how you're going to mess it up. Girls will be your friends - they'll act like it anyway. But just remember, some come, some go. The ones that stay with you through everything - they're your true best friends. Don't let go of them. Also remember, sisters make the best friends in the world. As for lovers, well, they'll come and go too. And baby, I hate to say it, most of them - actually pretty much all of them are going to break your heart, but you can't give up because if you give up, you'll never find your soulmate. You'll never find that half who makes you whole and that goes for everything. Just because you fail once, doesn't mean you're gonna fail at everything. Keep trying, hold on, and always, always, always believe in yourself, because if you don't, then who will, sweetie? So keep your head high, keep your chin up, and most importantly, keep smiling, because life's a beautiful thing and there's so much to smile about.”" —— Marilyn Monroe # 3. "“You may not be her first, her last, or her only. She loved before she may love again. But if she loves you now, what else matters? She's not perfect—you aren't either, and the two of you may never be perfect together but if she can make you laugh, cause you to think twice, and admit to being human and making mistakes, hold onto her and give her the most you can. She may not be thinking about you every second of the day, but she will give you a part of her that she knows you can break—her heart. So don't hurt her, don't change her, don't analyze and don't expect more than she can give. Smile when she makes you happy, let her know when she makes you mad, and miss her when she's not there.”" —— Bob Marley # 4. "“The opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.”" —— Elie Wiesel # 5. "“It is not a lack of love, but a lack of friendship that makes unhappy marriages.”" —— Friedrich Nietzsche # 6. "“I love you without knowing how, or when, or from where. I love you simply, without problems or pride: I love you in this way because I do not know any other way of loving but this, in which there is no I or you, so intimate that your hand upon my chest is my hand, so intimate that when I fall asleep your eyes close.”" —— Pablo Neruda # 7. "“If you can make a woman laugh, you can make her do anything.”" —— Marilyn Monroe # 8. "“The real lover is the man who can thrill you by kissing your forehead or smiling into your eyes or just staring into space.”" —— Marilyn Monroe # 9. "“Love does not begin and end the way we seem to think it does. Love is a battle, love is a war; love is a growing up.”" —— James Baldwin # 10. "“There is nothing I would not do for those who are really my friends. I have no notion of loving people by halves, it is not my nature.”" —— Jane Austen # 11. "“To love at all is to be vulnerable. Love anything and your heart will be wrung and possibly broken. If you want to make sure of keeping it intact you must give it to no one, not even an animal. Wrap it carefully round with hobbies and little luxuries; avoid all entanglements. Lock it up safe in the casket or coffin of your selfishness. But in that casket, safe, dark, motionless, airless, it will change. It will not be broken; it will become unbreakable, impenetrable, irredeemable. To love is to be vulnerable.”" —— C.S. Lewis # 12. "“If I had a flower for every time I thought of you...I could walk through my garden forever.”" —— Alfred Tennyson # 13. "“A lady's imagination is very rapid; it jumps from admiration to love, from love to matrimony in a moment.”" —— Jane Austen # 14. "“To die will be an awfully big adventure.”" —— J.M. Barrie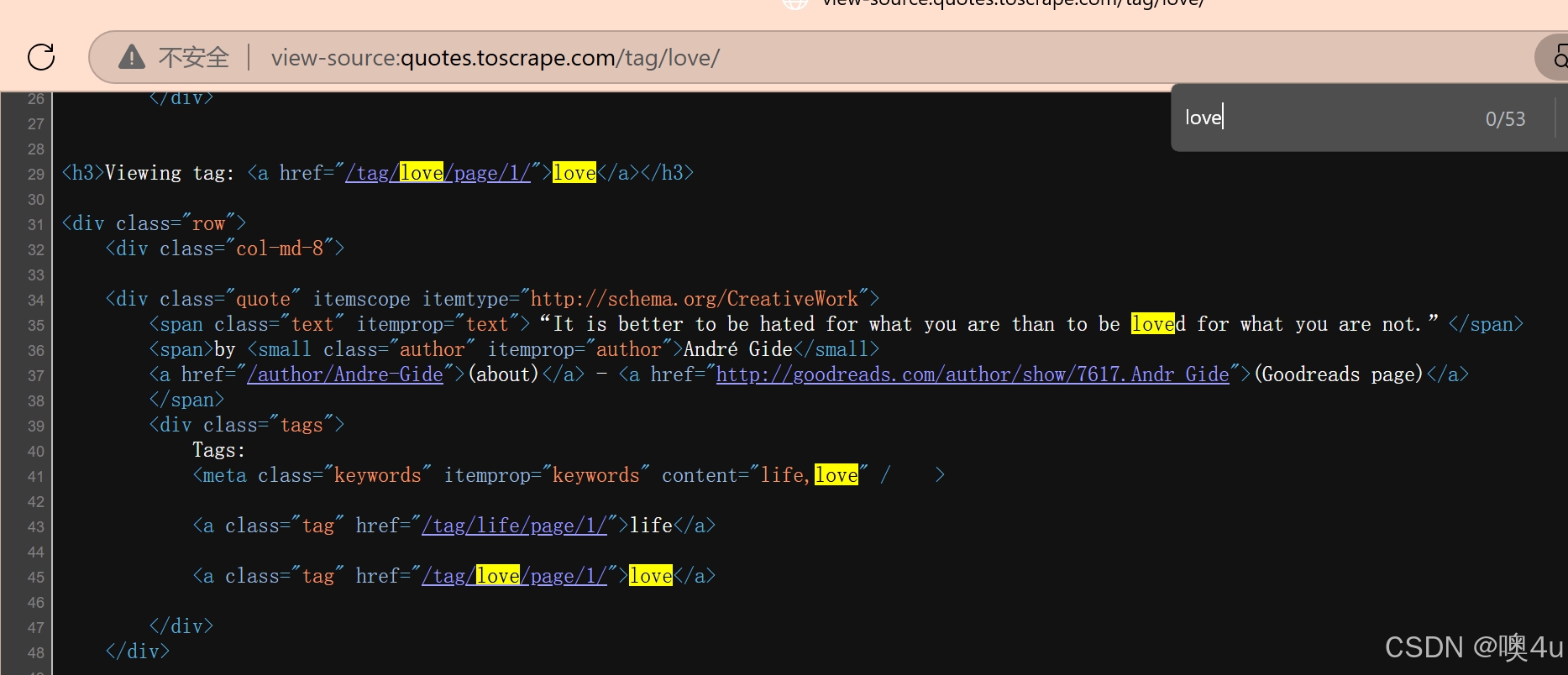
- 通过
soup.find_all("a", attrs={"class": "tag", "href": "/tag/love/page/1/"})来找到所有“love”链接。 - 然后使用
.find_parent("div", class_="quote")追溯到所属的名言块。 - 最后,再从这个名言块里提取名言文本、作者等信息。
- 通过
- 一种思路是:每个
<div class="quote">都有若干<a class="tag">。我们先拿到本页所有quote_div,再在内部查找<a class="tag">是否包含 “love”。示例:import requests from bs4 import BeautifulSoup url = "http://quotes.toscrape.com/page/1/" resp = requests.get(url) soup = BeautifulSoup(resp.text, "html.parser") quotes_divs = soup.find_all("div", class_="quote") for div in quotes_divs: tag_list = [a.get_text(strip=True) for a in div.find_all("a", class_="tag")] if "love" in tag_list: # 若这个名言块包含 love 标签,则获取名言与作者 quote_text = div.find("span", class_="text").get_text(strip=True) author_name = div.find("small", class_="author").get_text(strip=True) print(f"名言: {quote_text}") print(f"作者: {author_name}") print("-" * 30)-
这种方式比指定
href="/tag/love/page/1/"更灵活,因为在不同页面上,“love” 标签的href可能也会变化,比如/tag/love/page/2/。
-
翻页
在这两个示例网站上,页面结构较为简单,通常在页面底部或某个位置有一个 “Next” 按钮,它对应的 HTML 结构一般是这样(略简化):
<li class="next">
<a href="/page/2/">Next <span aria-hidden="true">→</span></a>
</li>
# 找下一页链接
next_li = soup.find("li", class_="next")
if next_li:
next_page = next_li.find("a")["href"]
page_url = next_page
else:
print("没有下一页了,结束。")
break- 先访问第一页并解析其中的内容;
- 在页面中查找
li.next(class="next") 标签,里面通常有一个<a>,它的href可能是/page/2/; - 如果找到了这个链接,就更新要爬取的 URL,再进行下一次请求;
- 如果没有
li.next,说明已经到达最后一页,可以停止爬取。
CSS 选择器
BeautifulSoup 提供 select() 方法,可以按照类似 CSS 的选择器语法来查找,适合前端背景。
# 例:查找所有 class=quote 的 div
quotes_divs = soup.select("div.quote")
# 例:查找 class=quote 下的 span.text
quote_texts = soup.select("div.quote span.text")
# 例:查找带有 class=author 的 small 元素
authors = soup.select("small.author")
select()返回的是一个列表,一次性获取所有匹配元素。
示例:获取 “Books to Scrape” 的商品信息
import requests
from bs4 import BeautifulSoup
base_url = "http://books.toscrape.com/catalogue/"
page_url = "page-1.html"
all_books = []
while True:
full_url = base_url + page_url
print(f"正在抓取: {full_url}")
resp = requests.get(full_url)
soup = BeautifulSoup(resp.text, "html.parser")
# 找到所有的商品项
books = soup.find_all("article", class_="product_pod")
if not books:
break
for b in books:
# 书名在 h3 > a 的 title 属性中
title_tag = b.find("h3").find("a")
title = title_tag["title"]
# 价格在 .product_price > .price_color 中
price = b.find("p", class_="price_color").get_text(strip=True)
# 评级在 p 中的 class,如 "star-rating Four"
star_rating = b.find("p", class_="star-rating")["class"][1]
all_books.append((title, price, star_rating))
# 找下一页链接
next_li = soup.find("li", class_="next")
if next_li:
next_page = next_li.find("a")["href"]
page_url = next_page
else:
print("没有下一页了,结束。")
break
print(f"共抓到 {len(all_books)} 本书。")
for i, (title, price, rating) in enumerate(all_books[:5], 1):
print(f"{i}.《{title}》 价格: {price} 评分: {rating}")
# 正在抓取: http://books.toscrape.com/catalogue/page-1.html
# 正在抓取: http://books.toscrape.com/catalogue/page-2.html
# 正在抓取: http://books.toscrape.com/catalogue/page-3.html
# 正在抓取: http://books.toscrape.com/catalogue/page-4.html
# 正在抓取: http://books.toscrape.com/catalogue/page-5.html
# 正在抓取: http://books.toscrape.com/catalogue/page-6.html
# 正在抓取: http://books.toscrape.com/catalogue/page-7.html
# 正在抓取: http://books.toscrape.com/catalogue/page-8.html
# 正在抓取: http://books.toscrape.com/catalogue/page-9.html
# 正在抓取: http://books.toscrape.com/catalogue/page-10.html
# 正在抓取: http://books.toscrape.com/catalogue/page-11.html
# 正在抓取: http://books.toscrape.com/catalogue/page-12.html
# 正在抓取: http://books.toscrape.com/catalogue/page-13.html
# 正在抓取: http://books.toscrape.com/catalogue/page-14.html
# 正在抓取: http://books.toscrape.com/catalogue/page-15.html
# 正在抓取: http://books.toscrape.com/catalogue/page-16.html
# 正在抓取: http://books.toscrape.com/catalogue/page-17.html
# 正在抓取: http://books.toscrape.com/catalogue/page-18.html
# 正在抓取: http://books.toscrape.com/catalogue/page-19.html
# 正在抓取: http://books.toscrape.com/catalogue/page-20.html
# 正在抓取: http://books.toscrape.com/catalogue/page-21.html
# 正在抓取: http://books.toscrape.com/catalogue/page-22.html
# 正在抓取: http://books.toscrape.com/catalogue/page-23.html
# 正在抓取: http://books.toscrape.com/catalogue/page-24.html
# 正在抓取: http://books.toscrape.com/catalogue/page-25.html
# 正在抓取: http://books.toscrape.com/catalogue/page-26.html
# 正在抓取: http://books.toscrape.com/catalogue/page-27.html
# 正在抓取: http://books.toscrape.com/catalogue/page-28.html
# 正在抓取: http://books.toscrape.com/catalogue/page-29.html
# 正在抓取: http://books.toscrape.com/catalogue/page-30.html
# 正在抓取: http://books.toscrape.com/catalogue/page-31.html
# 正在抓取: http://books.toscrape.com/catalogue/page-32.html
# 正在抓取: http://books.toscrape.com/catalogue/page-33.html
# 正在抓取: http://books.toscrape.com/catalogue/page-34.html
# 正在抓取: http://books.toscrape.com/catalogue/page-35.html
# 正在抓取: http://books.toscrape.com/catalogue/page-36.html
# 正在抓取: http://books.toscrape.com/catalogue/page-37.html
# 正在抓取: http://books.toscrape.com/catalogue/page-38.html
# 正在抓取: http://books.toscrape.com/catalogue/page-39.html
# 正在抓取: http://books.toscrape.com/catalogue/page-40.html
# 正在抓取: http://books.toscrape.com/catalogue/page-41.html
# 正在抓取: http://books.toscrape.com/catalogue/page-42.html
# 正在抓取: http://books.toscrape.com/catalogue/page-43.html
# 正在抓取: http://books.toscrape.com/catalogue/page-44.html
# 正在抓取: http://books.toscrape.com/catalogue/page-45.html
# 正在抓取: http://books.toscrape.com/catalogue/page-46.html
# 正在抓取: http://books.toscrape.com/catalogue/page-47.html
# 正在抓取: http://books.toscrape.com/catalogue/page-48.html
# 正在抓取: http://books.toscrape.com/catalogue/page-49.html
# 正在抓取: http://books.toscrape.com/catalogue/page-50.html
# 没有下一页了,结束。
# 共抓到 1000 本书。
# 1.《A Light in the Attic》 价格: £51.77 评分: Three
# 2.《Tipping the Velvet》 价格: £53.74 评分: One
# 3.《Soumission》 价格: £50.10 评分: One
# 4.《Sharp Objects》 价格: £47.82 评分: Four
# 5.《Sapiens: A Brief History of Humankind》 价格: £54.23 评分: Five解析技巧
一些常用的字符串处理技巧(正则、Python 字符串操作等)也会经常用到。具体可见我的“机器学习专栏”《1.python基础》
三、中级爬虫
1. Scrapy 框架
Scrapy框架并不使用requests库和BeautifulSoup库。相反,Scrapy拥有自己独立的请求处理系统和响应解析机制。它基于异步网络框架Twisted,高效地处理大量并发请求。对于HTML解析,Scrapy默认使用lxml库,而不是BeautifulSoup。不过,如果需要,开发者仍可以在Scrapy项目中集成BeautifulSoup进行自定义解析。Scrapy通过其内置的Spider、Item、Pipeline和Middleware等组件,提供了从发送请求、解析响应到数据存储的全流程解决方案,使得爬虫开发更加结构化和高效。因此,Scrapy不仅仅是对requests和BeautifulSoup功能的封装,而是一个功能更全面、性能更强大的专业爬虫框架。
Scrapy 是一个 Python 爬虫框架,提供了从 爬取 到 数据清洗 再到 存储 的完整解决方案,是一个工程化的专业框架。其核心组件包括:
-
Spider(爬虫)
- 用于定义 要爬取的网页 和 如何提取数据。
- Spider 中通常会编写
start_requests()或start_urls,以及parse()方法,在parse()中使用选择器(如 XPath、CSS Selector)提取目标信息,生成 Item 或后续请求。
-
Item(数据结构)
- 用于定义 要存储或处理的结构化数据。
- 在
items.py中定义类,例如:import scrapy class MyItem(scrapy.Item): title = scrapy.Field() price = scrapy.Field() stock = scrapy.Field() -
在 Spider 中提取数据后,创建
item = MyItem(title=..., price=..., stock=...),再yield item到 Pipeline 进一步处理。
-
Pipeline(管道)
- 当 Spider
yield出Item后,会依照在settings.py中配置的顺序经过各个 Pipeline。 - 常见用途:数据清洗、去重、存储 到数据库(MySQL、MongoDB、Redis 等)或文件(CSV、JSON 等)。
- 在
pipelines.py中实现process_item(self, item, spider)方法来编写处理逻辑。
- 当 Spider
-
Middleware(中间件)
- 分为 下载器中间件(Downloader Middleware) 与 爬虫中间件(Spider Middleware)。
- 可以拦截或修改 请求/响应 数据:
- 下载器中间件常用于 请求头处理、代理、限速、Cookies 等。
- 爬虫中间件常用于修改 Spider 输出 或 即将送入 Spider 的响应。
Scrapy 的大致工作流程是:Spider 生成请求 → 下载器中间件处理请求 → 调度器 → 下载器发送请求给目标网站并获取响应 → 下载器中间件处理响应 → Spider 解析响应生成 Item 或新的请求 → Pipeline 处理 Item 并存储。
如果爬虫需求并不复杂、只是一次性或者规模较小,可以用 requests + BeautifulSoup 编写脚本,即可快速实现数据采集。当爬虫需求不断增加、或需要处理并发与反爬,组织多站点甚至分布式,再转向 Scrapy 等专业框架是合适的选择。
2. Scrapy 进阶
Cookie 处理
- Scrapy 默认会自动管理 Cookie(
COOKIES_ENABLED = True),会将服务器返回的Set-Cookie存储到内存并在后续请求中带上。 - 如果需要手动设置或修改 Cookie,可以在
request.headers或request.cookies里指定;或者在 下载器中间件 中注入或修改 Cookie。
表单/登录
- 通常需要先分析登录请求(如查看表单字段、POST 参数),然后在 Spider 中手动发起
FormRequest,或者在Request中带method="POST"和formdata/body:import scrapy class LoginSpider(scrapy.Spider): name = "login_spider" start_urls = ["http://example.com/login"] def parse(self, response): return scrapy.FormRequest.from_response( response, formxpath='//form[@id="login-form"]', formdata={"username": "user", "password": "pass"}, callback=self.after_login ) def after_login(self, response): # 检查登录是否成功 ...
Token 处理
- 一些网站在表单或请求头中需要带特定 Token(CSRF Token、JWT Token等),可以在 parse 或回调函数中从页面/响应中提取 Token,再放到下一个请求的 Header 或 formdata 中。
- 也可借助下载器中间件,在所有请求发出前,统一注入或更新 Token。
其他定制
- 比如 自定义请求头(User-Agent、Referer 等)或 重写 start_requests() 来执行带参数的请求。
- 抓包分析(借助浏览器 F12 / Charles / Fiddler) 对复杂登录、鉴权流程特别重要。
3. 配套处理
数据存储
当 Spider yield item 后,Item 会流经 Pipeline 进行存储或清洗。最常见做法:
-
存储到 CSV/JSON
- 开启 内置的 Feed Export 功能(在
settings.py中设置FEED_FORMAT,FEED_URI等),可自动将爬取结果导出到 CSV/JSON/XML 等格式文件。 - 或自行在
pipelines.py中使用 Pythoncsv/json标准库写文件。
- 开启 内置的 Feed Export 功能(在
-
MySQL
- 在
pipelines.py中连接数据库、执行INSERT或UPDATE。示例:import pymysql class MySQLPipeline: def open_spider(self, spider): self.conn = pymysql.connect( host='localhost', user='root', password='123456', db='mydb' ) self.cursor = self.conn.cursor() def process_item(self, item, spider): sql = "INSERT INTO books(title, price) VALUES (%s, %s)" self.cursor.execute(sql, (item['title'], item['price'])) self.conn.commit() return item def close_spider(self, spider): self.cursor.close() self.conn.close()-
open_spider()和close_spider()分别在爬虫开启/结束时执行,可建立和关闭连接。
-
-
MongoDB
- 安装
pymongo,在 Pipeline 中使用self.db["collection_name"].insert_one(dict(item))或批量写入。 - 注意
MongoClient的连接方式与数据库、集合的选择。
- 安装
-
Redis
- Scrapy 常与 Redis 配合做分布式爬虫,如 scrapy-redis。
- 基本思路是将 request / items 存储或排队在 Redis 中,实现分布式去重、并行处理。
- 在
Middleware:下载中间件与爬虫中间件
- 下载器中间件(Downloader Middleware)
- 用于处理 Request 和 Response 在到达 Spider 或离开 Spider 之前的过程。
- 可以实现:自定义 User-Agent、代理池(轮换 IP)、限速(AutoThrottle 也算一种形式)、Cookies 注入等。
- 例如要修改请求头:
def process_request(self, request, spider): request.headers['User-Agent'] = 'MyCustomAgent' return None
-
爬虫中间件(Spider Middleware)
- 处于 Spider 和 Engine 之间,影响 Spider 输入/输出 的数据。
- 例如在 Spider 解析完响应要返回 items 或新的 request 之前,进行某些过滤或修改操作。
-
AutoThrottle
- Scrapy 内置的 自动限速 扩展,可以根据爬取速度、网站延迟来自动调节并发请求数与下载延迟。
- 在
settings.py中启用:AUTOTHROTTLE_ENABLED = True AUTOTHROTTLE_START_DELAY = 1.0 AUTOTHROTTLE_MAX_DELAY = 10.0-
这样可以在高峰时段自动减速,避免给服务器造成过大压力;在空闲时段加速爬取。
-
日志与调试
- 日志机制
- Scrapy 默认会在控制台输出日志,等级如
DEBUG,INFO,WARNING,ERROR,CRITICAL等。 - 可在
settings.py中修改日志级别和输出文件:LOG_LEVEL = 'INFO' LOG_FILE = 'scrapy.log'-
在代码中可以使用
self.logger.info("message")或import logging; logging.info("message")。
-
- Scrapy 默认会在控制台输出日志,等级如
-
调试技巧
- scrapy shell:在终端运行
scrapy shell <URL>,可以交互式获取 response,用response.xpath()或response.css()进行选择器测试。 - 断点调试:可在代码里使用
import pdb; pdb.set_trace()或者 IDE 的断点,查看 Spider 运行时的状态。 - 抓包分析:若要调试复杂登录流程、Headers、Cookies,可借助浏览器的 Developer Tools 或第三方抓包工具(Fiddler、Charles 等)。
- scrapy shell:在终端运行
综合示例:Scrapy 工程小结
一个简单的 Scrapy 工程结构可能如下:
myproject/
scrapy.cfg
myproject/
__init__.py
items.py
pipelines.py
middlewares.py
settings.py
spiders/
myspider.py
myspider.py:
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
for quote_div in response.css("div.quote"):
item = MyItem()
item['text'] = quote_div.css("span.text::text").get()
item['author'] = quote_div.css("small.author::text").get()
yield item
# 翻页示例
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield response.follow(next_page, callback=self.parse)
items.py:
import scrapy
class MyItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
pipelines.py:
class MyprojectPipeline:
def process_item(self, item, spider):
# 这里可写入数据库或打印等
print(item)
return item
settings.py (关键部分):
BOT_NAME = 'myproject'
SPIDER_MODULES = ['myproject.spiders']
NEWSPIDER_MODULE = 'myproject.spiders'
# 启用 Pipeline
ITEM_PIPELINES = {
'myproject.pipelines.MyprojectPipeline': 300,
}
# 代理、中间件、AutoThrottle 等配置
# DOWNLOADER_MIDDLEWARES = { ... }
# AUTOTHROTTLE_ENABLED = True
# ...
LOG_LEVEL = 'INFO'
运行: 进入工程目录,命令行执行:
scrapy crawl myspider
四、高级爬虫
1. 动态页面抓取
为什么需要抓取动态页面
- 传统爬虫(requests + BeautifulSoup)只能解析 静态 HTML。
- 现在很多网站使用 JavaScript 和 Ajax 技术(如 SPA)来动态加载内容,导致初次请求获取的 HTML 中并没有最终数据。
- 为了获取在浏览器渲染后才出现的内容,需要 模拟浏览器环境 或 分析并直接调用后台接口。
Selenium
- Selenium 是一个 自动化测试框架,能通过 WebDriver 控制真实浏览器(Chrome、Firefox 等)执行操作。
- 优点:
- 可以渲染 JavaScript,获取最终呈现的页面内容;
- 能处理按钮点击、下拉滚动、表单提交、拖拽等复杂交互。
- 对付动态加载、某些反爬虫(如简单检测 JS 环境)时效果好。
- 缺点:
- 性能较低,启动浏览器开销大;
- 编程逻辑相对复杂,尤其在大量并发时负载较高。
示例(Python + Selenium + Chrome):
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 创建浏览器驱动(需提前安装对应的 ChromeDriver)
driver = webdriver.Chrome()
# 访问目标页面
driver.get("https://example.com/spa-page")
# 等待页面加载(粗暴用 time.sleep,也可使用显式/隐式等待)
time.sleep(2)
# 查找元素并获取文本
element = driver.find_element(By.CSS_SELECTOR, "div.some-class")
print("抓取到的文本:", element.text)
# 关闭浏览器
driver.quit()
- 可以同时了解一下 Playwright 或 puppeteer-python 之类的新工具,有时比 Selenium 更简洁。
- Playwright(Python/Node.js)和 Puppeteer(Node.js)是新一代的 浏览器自动化工具,底层使用 Chromium DevTools 协议,性能和稳定性方面在许多场景更优于传统 Selenium。
- Playwright 也有 Python 版本 (
pip install playwright),特点:- 自带浏览器驱动安装,使用更方便;
- 内置等待机制、支持多浏览器(Chromium、Firefox、WebKit)。
- 提供 headless(无界面)模式,适合服务器端部署。
- 简短示例(Python + Playwright):
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch(headless=True) page = browser.new_page() page.goto("https://example.com/spa-page") # 等待某元素出现 page.wait_for_selector("div.some-class") text = page.query_selector("div.some-class").inner_text() print("抓取到的文本:", text) browser.close()
- 重点掌握如何抓取 SPA(Single Page Application),如何等待页面加载,如何处理 AJAX 数据。
- SPA 通常通过 Ajax 或 fetch 向后端接口请求数据,然后由 JavaScript 渲染到页面。
- 抓取 SPA 有两种主要思路:
- 模拟浏览器(Selenium/Playwright),等待页面渲染完成后再提取元素;
- 直接分析接口,若能在 Network 面板中看到返回 JSON,直接调用该接口,省去浏览器渲染过程(效率更高)。
- 关键点:要 等待页面或数据加载 完成,否则拿到的 HTML 还没更新;使用 等待(
time.sleep()/wait_for_selector/ WebDriverWait) 或 分析接口 实际返回时间。
2. 并发爬虫
- 多线程、多进程、协程(asyncio):
- 可以对比不同并发模式在爬虫中的应用场景。
- Scrapy 本身基于 Twisted 异步框架,掌握了 Scrapy,实际上已经在使用异步并发编程了。
- 如果需要自己写简单的并发爬虫,可以尝试 Python 原生的
asyncio+aiohttp。
3. Scrapy-Redis
- 基于 Redis 实现的分布式爬虫框架,适合需要大规模爬取或在多台机器上进行协同爬取的时候学习。
4. 反爬虫与破解
常见反爬手段
-
封 IP
- 服务器检测到某 IP 频繁请求,可能会返回 403、302 或直接超时;
- 或者服务端只给一定速率以内的请求返回正常数据。
-
登录验证:用户需要先登录(带 Cookie、Session),且可能有多重验证(短信、邮箱、动态密码等)。
-
验证码:用图形验证码、人机验证(reCAPTCHA)等来区分自动脚本和真人访问。
-
JavaScript 混淆或加密:请求参数或关键逻辑在前端JS里做加密,爬虫需要逆向该加密过程或直接模拟浏览器执行JS。
-
动态加载:前文提到的 SPA、Ajax,如果爬虫只抓静态 HTML,则抓不到真实数据。
应对策略
-
IP 封禁:
- 代理池:轮换大量 IP,减少单一 IP 的频繁访问痕迹;
- 或购买付费代理,尤其针对海外站点更稳定。
-
验证码:
- 对于字符类验证码,可以使用 第三方打码平台 或 图像识别模型;
- 对于高级人机验证(如 reCAPTCHA v3),则需更复杂的模拟或使用第三方打码,但要谨慎合法合规。
-
请求参数加密:
- 逆向分析:通过浏览器 F12 抓包、调试 JS 源码,找出加密逻辑或加密参数,然后在爬虫中重现;
- 或者Hook 浏览器执行,让浏览器生成正确参数后拦截。
-
模拟浏览器:
- 利用 Selenium / Playwright 等真正执行 JS、带完整浏览器指纹,很多站点无法轻易识别。
- 同时可以添加 自定义请求头、动态鼠标移动或键盘输入等方式,让行为更像真人。
-
限速/AutoThrottle:
- 不要过于频繁访问,一般要设置延时或自动限速,避免触发服务器的风控。
五、实践步骤
1. 实战项目
- 数据采集项目:电商数据、新闻数据、房产数据等都可作为综合练习。
- 数据清洗与分析:可以用 Pandas 进行数据清洗,用 Matplotlib 或 Seaborn 做可视化。
- 前后端联动:如果有余力,可以做个简单的可视化网站或者使用 Streamlit + ECharts 展示采集结果。
2. 代码优化
- 异步编程:Scrapy 自身异步 + Pipeline 优化。
- 代码规范:PEP8、模块化、函数化、拆分大文件等。
- 性能调优:常见爬虫性能参数(下载延迟、并发数、重试机制等)。
六、部署与维护
- 部署爬虫:如在服务器上运行爬虫.可以了解 Docker、Linux 服务器部署以及定时调度(crontab 等)。
- 定时任务:使用如Cron、Airflow等工具定时执行爬虫.
总结
网络爬虫是一项集网络通信、数据解析、并发处理与反爬策略于一体的综合技术。初学者通常从使用Python的requests库发送GET和POST请求、设置Headers和Cookies,以及管理Session开始,结合BeautifulSoup库解析HTML,通过标签名、属性或CSS选择器查找节点并使用find()和find_all()方法提取所需数据。在面对动态页面时,Selenium等工具能够模拟真实浏览器执行JavaScript,从而抓取由前端渲染的内容,而Playwright和Puppeteer-python等新兴工具则提供了更简洁高效的替代方案,特别适用于处理单页应用(SPA)和等待页面加载或处理AJAX数据。此外,Scrapy框架通过其Spider、Item、Pipeline和Middleware等核心组件,提供了从请求发送、数据提取到存储的全流程管理,适用于中大型爬虫项目,并支持复杂请求如登录、处理Cookie、表单提交和Token验证。面对常见的反爬手段如IP封禁、验证码、请求参数加密和动态加载,爬虫开发者可以采用代理池、第三方打码平台、逆向分析加密逻辑或通过模拟浏览器行为等策略进行应对。数据存储方面,爬取的数据可以灵活地存入MySQL、MongoDB、Redis等数据库,或导出为CSV、JSON文件。下载中间件与爬虫中间件在Scrapy中尤为重要,它们能够处理请求头、代理、限速(如AutoThrottle)等,确保爬虫运行的效率与稳定性。Scrapy自带的日志机制和调试工具如scrapy shell以及断点调试功能,帮助开发者监控爬虫运行状态、排查问题并优化代码。总之,网络爬虫技术不仅要求掌握基本的HTTP协议和数据解析方法,还需具备应对复杂动态内容和反爬机制的能力,合理选择和组合工具与框架,并始终遵循合法合规的原则,以实现高效、稳定和可维护的数据采集。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









