







 超级会员免费看
超级会员免费看
01 为什么会出现 CRAG 技术?
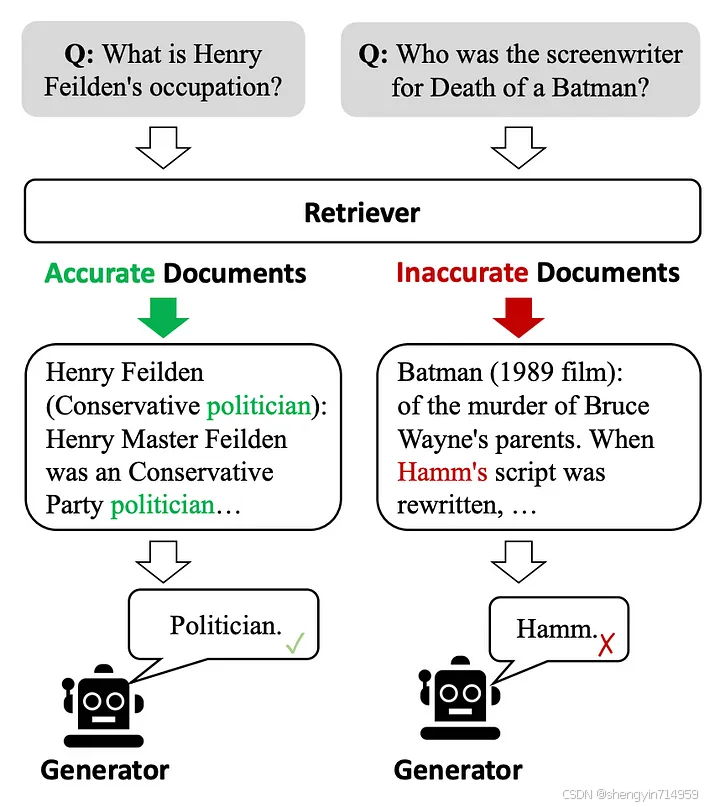
图 1:这些例子表明,低效的检索器(retriever)容易引入大量无关的信息,会阻碍生成器(generators)获取准确的知识,甚至可能将其引入歧途。资料来源:Corrective Retrieval Augmented Generation[1]
图 1 指出了传统 RAG 方法存在的一个问题:大多数传统的 RAG 方法会忽视文档内容与用户问题之间的相关性,只是简单地把检索到的文档拼接在一起。这种做法可能导致无关信息的混入,不仅妨碍模型获取准确的知识,还可能误导模型,从而引发幻觉问题。
此外,大多数传统 RAG 方法都是将检索到的整篇文档传递给大模型。 然而,这些文档中的大部分内容实际上对模型响应的生成过程并没有实质性的帮助,不应该被无差别地传递给大模型。
02 CRAG 的核心理念
CRAG 构思了一种轻量级的检索评估机制,可用于评判针对特定用户请求所获取文档的总体品质,并创造性地运用网络搜索(web search)技术,以此增强检索结果的准确性。
CRAG 具备出色的兼容性,即插即用,能够轻松融入各种基于 RAG 的策略体系,其整体框架如图 2 所示。
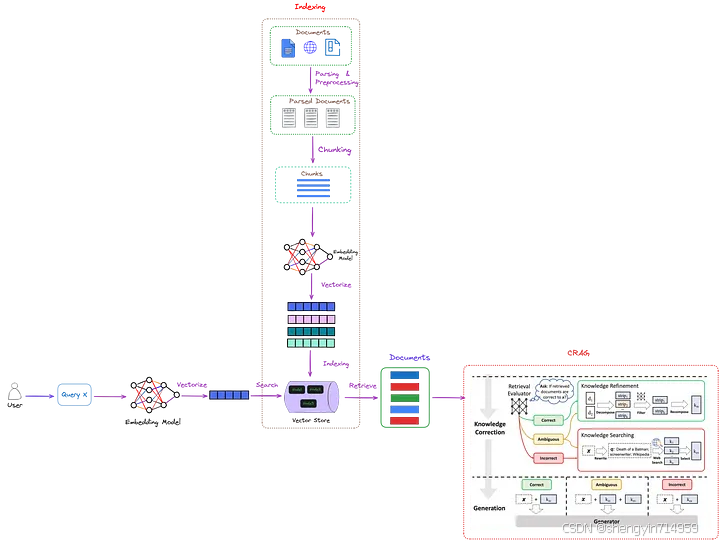
图 2:CRAG(红色虚线框标记)在 RAG 架构中的定位。其巧妙地引入检索评估模块,可用于评估检索文档与用户需求的相关性,并据此估计可信度(confidence level),进而触发三类不同的知识检索策略,即 {正确、错误、不确定} 。其中,“x”代表用户的查询请求。该图由作者原创,CRAG 部分(红色虚线框标记)取自《Corrective Retrieval Augmented Generation》[1]
如图 2 所示,CRAG 通过引入检索评估器(retrieval evaluator) 改进传统 RAG 方法,能够更精准地衡量检索文档与查询指令间的相关度。
存在三种可能的判定结果:
若判定为 “正确” ,表示检索出的文档包含了回答用户查询需要的关键信息,此时可以启用知识精炼算法(knowledge refinement algorithm),对文档内容进行重写优化。
若判定为 “错误” ,则意味着用户查询与检索出的文档完全不相关。因此,我们不能将这类文档发送给大语言模型(LLM)进行处理。在 CRAG 技术方案中,会使用网络搜索引擎来检索更多外部知识。
若判定为 “不确定” ,表明检索出的文档虽与需求相去不远,但尚不足以直接给出答案。这时,就需要通过网络搜索来补充缺失信息。因此,既要运用知识精炼算法,又需要搜索引擎的助力。
最后,经过一系列加工处理的信息会被转发给大语言模型(LLM),以便生成最终的模型响应。图 3 详细描述了这一过程。

图 3:评估与处理步骤,摘选自《Corrective Retrieval Augmented Generation》一文
请注意,网络搜索技术(web search)并非直接使用用户的原始输入进行搜索。相反,该技术会先构建一个引导性提示词(prompt),然后给出少量示例(few-shot),将其发送给GPT-3.5 Turbo,借此获取更精准的搜索查询语句。
在对整个处理流程有了一定的了解后,接下来我们将聚焦于 CRAG 体系中的两大核心模块 —— 检索评估机制(retrieval evaluator)与知识精炼算法(knowledge refinement algorithm),逐一展开深入探讨。
2.1 检索评估机制(retrieval evaluator)
如图 4 所示,检索评估器对后续环节的成效具有深远影响,其对整体系统性能的影响较大。
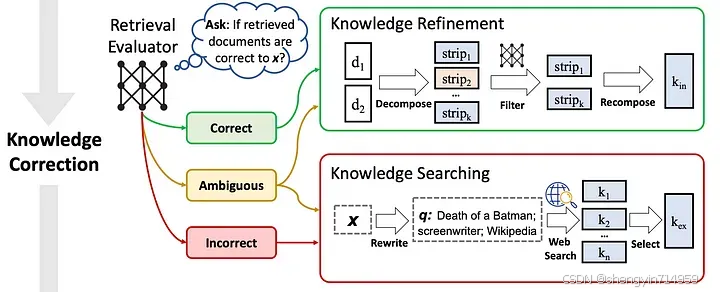
图 4:CRAG 的知识修正(Knowledge correction)流程。Source: Corrective Retrieval Augmented Generation[1]
CRAG 采用一个经过微调的 T5-large 模型作为检索评估器(retrieval evaluator),在如今这个大语言模型时代,T5-large[2] 也被视为轻量级的语言模型。
对于每个特定的用户查询,系统通常会提取约十篇文献资料。紧接着,将用户查询内容与每篇文献逐一结合,形成模型输入,然后评估它们的相关度(relevance)。在模型微调过程中,positive samples 会被打上标签“1”,而 negative samples 的则标注为“-1”。到了模型推理阶段,评估器会为每篇文档计算一个相关性分数,数值区间在 -1 至 1 之间。
这些相关性分数依据特定阈值将被划分为三大类别。划分类别这一操作需要界定两个不同的阈值界限。CRAG 系统中的阈值配置灵活性较高,可根据实验数据的具体情况调整设定:
为了决定这三种判定结果的判定方法,我们根据经验确定了两组可信度阈值(confidence thresholds)。它们在不同数据集中的具体数值如下:PopQA 数据集的阈值为(0.59, -0.99),PubQA 和 ArcChallenge 数据集的阈值是(0.5, -0.91),而在 Biography 数据集中,阈值则被设定为(0.95, -0.91)。
2.2 知识精炼算法(knowledge refinement algorithm)
CRAG 针对检索到的相关文档,创新性地采取了一种 “细分再整合” 的策略来深度挖掘最核心的知识信息,此过程如图 4 所示。
第一步依赖于一套启发式规则,将每篇文档分解为多个细粒度的知识点,以便挖掘更加精确的信息。 如果检索到的文档只有一两句话,则应将其视作一个独立的信息单元;而对于篇幅较长的文档,则依据其总长度,灵活切分为由数个句子组成的多个更小单元,确保每个小单元都封装一条独立完整的信息。
随后,借助检索评估机制,计算每一个细分知识点的相关性得分,滤除相关性得分较低的部分。然后余下的高相关性知识点经过重组,形成内部知识库(internal knowledge)。
03 Code Explanation 代码解读
CRAG 是一种开源技术,Langchain 和 LlamaIndex 这两大平台都支持并实现了这种技术。在此我们将以 LlamaIndex 的实现版本为蓝本进行详细解析。
3.1 环境配置
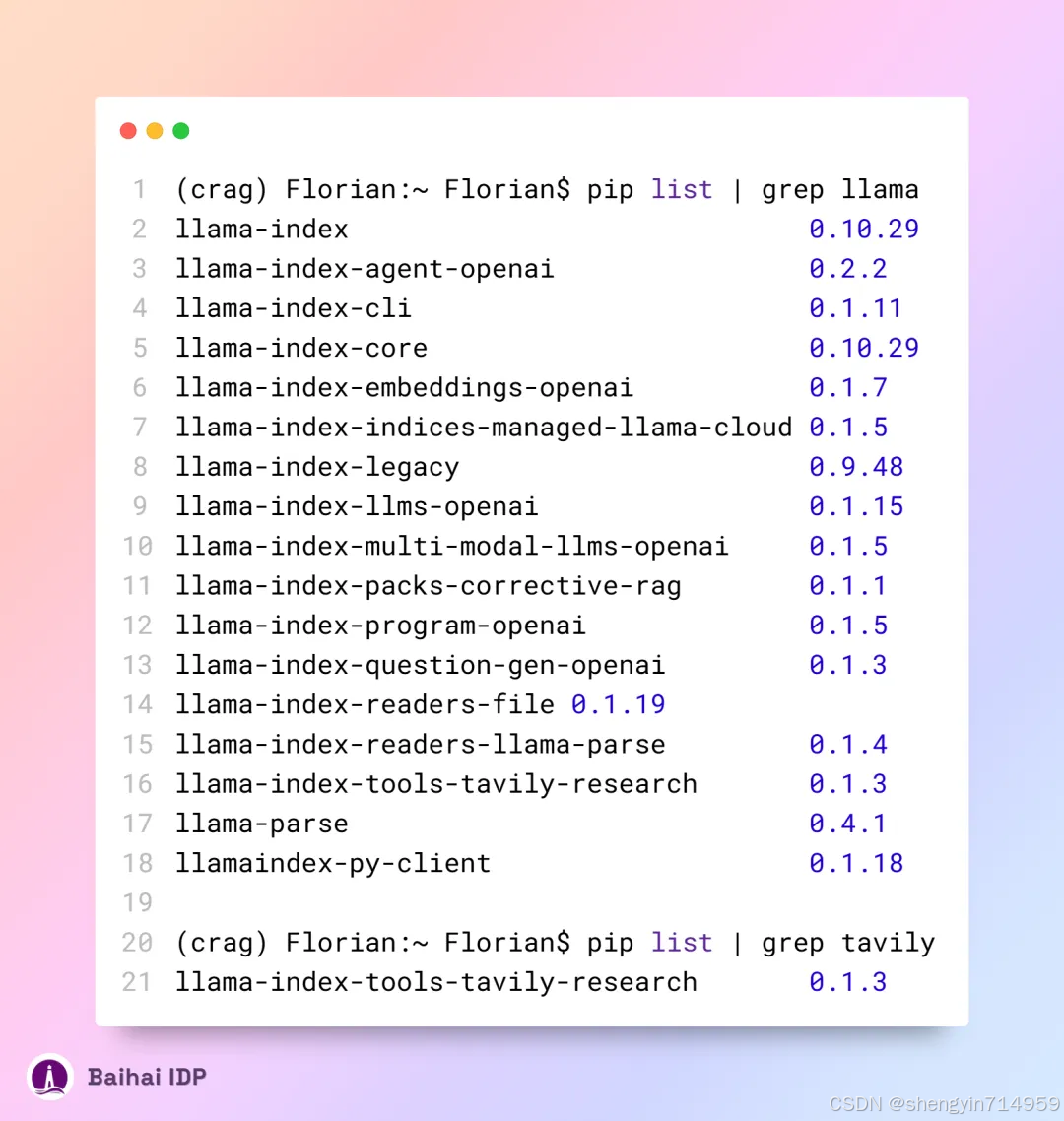
安装完成后,LlamaIndex 和 Tavily 的相应版本如下:
3.2 测试代码
测试代码如下。第一次运行需要下载CorrectiveRAGPack。

其中 YOUR_TAVILYAI_API_KEY 可通过此网站[3]申请。
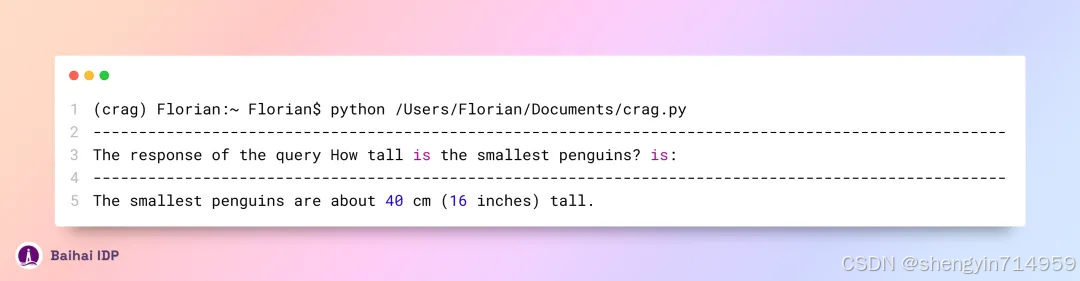
测试代码的运行结果如下(大部分调试信息已被删除):
要了解测试代码,需要深入剖析 corrective_rag.run() 方法的实现细节,接下来让我们一探究竟。
3.3 类 CorrectiveRAGPack 的构造函数
首先我们来看看该构造函数,其源代码[4]如下:
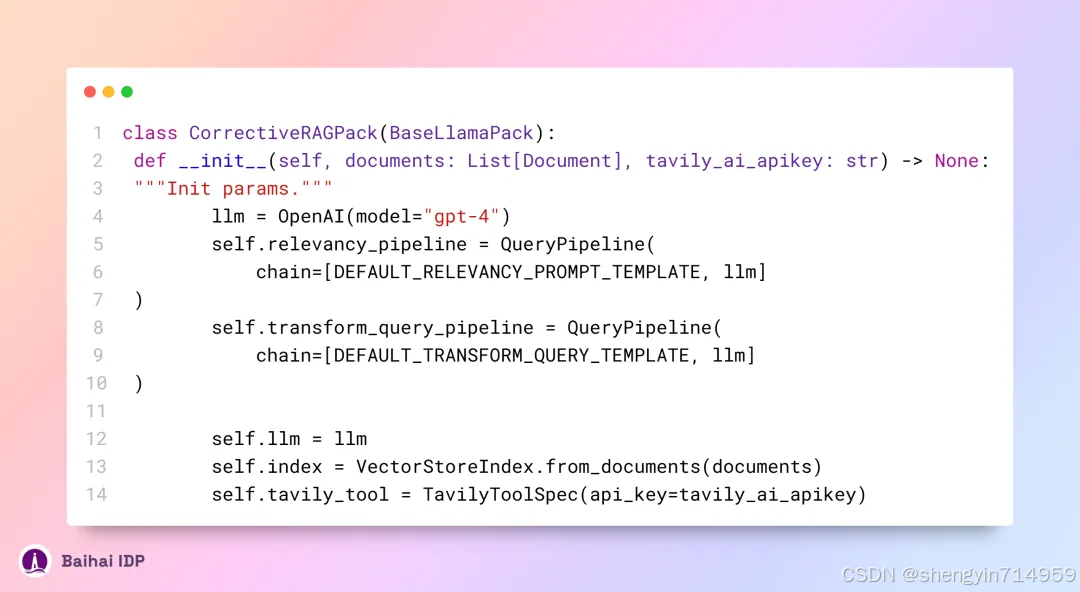
请注意,系统默认配置采用的是 gpt-4 模型。若您不具备使用 gpt-4 的权限,可将其手动调整为 gpt-3.5-turbo 或其他大模型的 API。
3.4 class CorrectiveRAGPack:: run()
函数 run() 的源代码[5]如下所示:
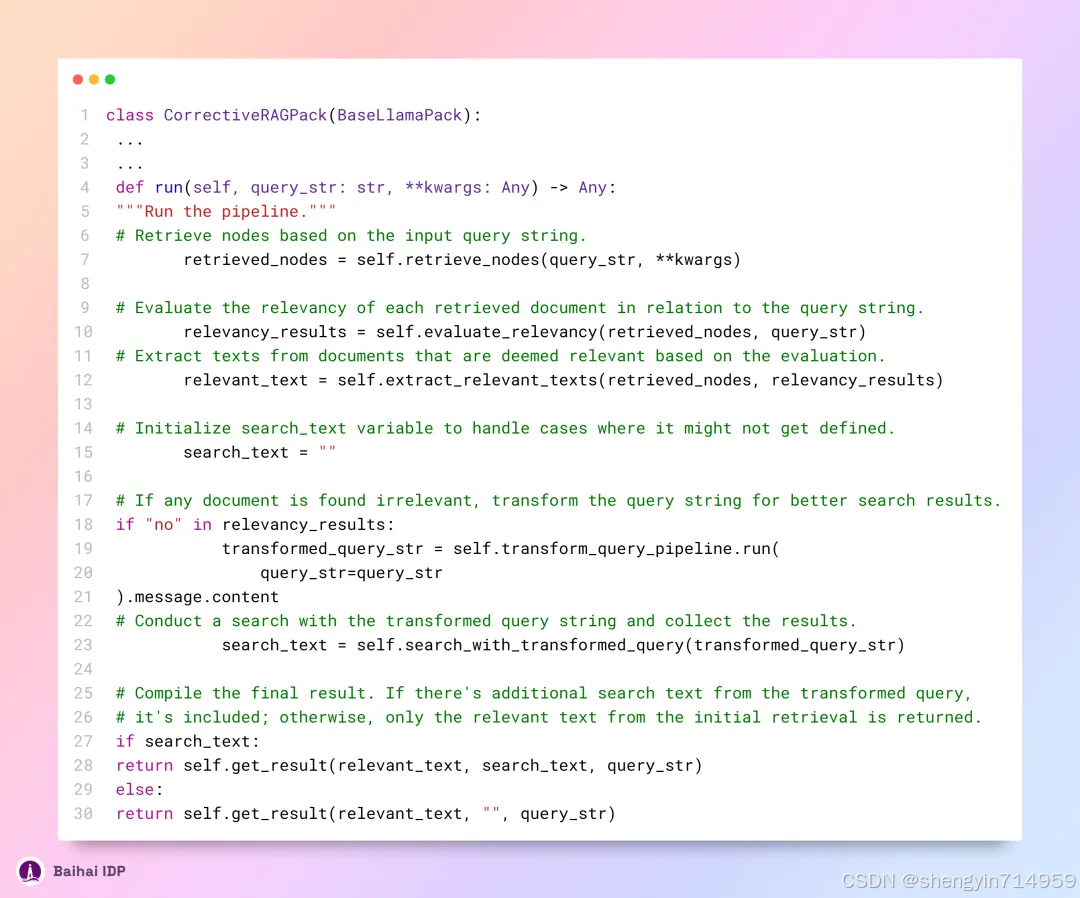
上述代码与 CRAG 的标准流程相比,有三点显著不同之处:
未涉及对模棱两可的“不确定”文档的辨识与特别处理。
在评估检索信息时,并未采用预训练的 T5-large 模型,而是转而利用 LLM(大语言模型)进行评估。
省略了知识精炼(knowledge refinement)这一步骤。
尽管如此,LlamaIndex 还是引入了另一种方法论(langchain 亦有类似实践),为此类任务的处理提供了另外一种思考路径。
3.5 使用 LLM 评估检索到的信息
具体代码[6]如下:
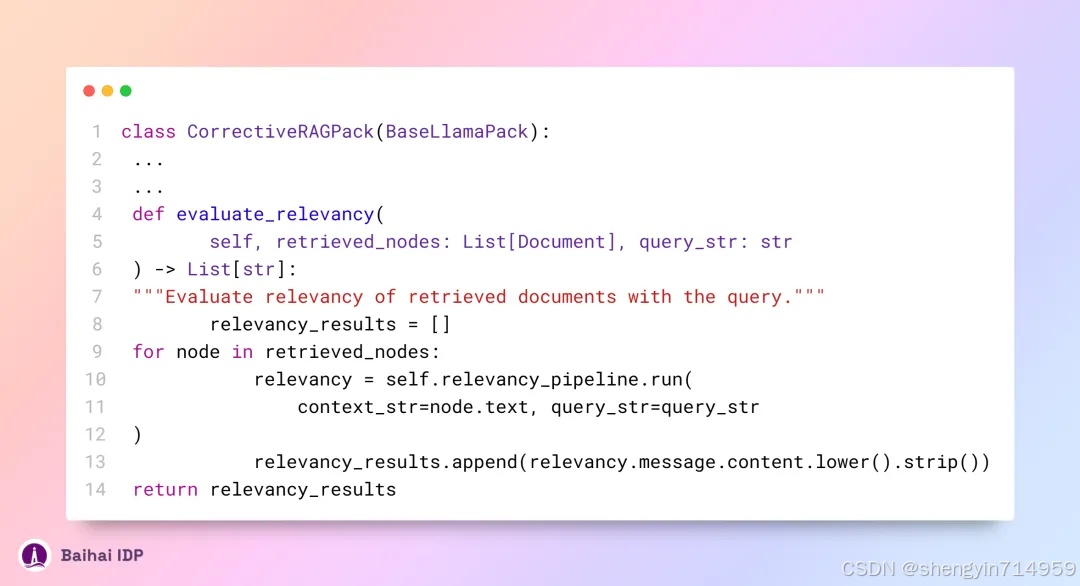
调用 LLM 的提示词[7]如下所示:
根据 CRAG 论文的内容展示,ChatGPT 在评估检索内容相关性上的性能不及 T5-Large 模型。
而在实际项目中,我们完全能够使用初始的知识精练算法(knowledge refinement algorithm)。相应的代码实现,您可以在此链接[8]获取。3.6 重写用于搜索的查询语句 Rewrite query for search
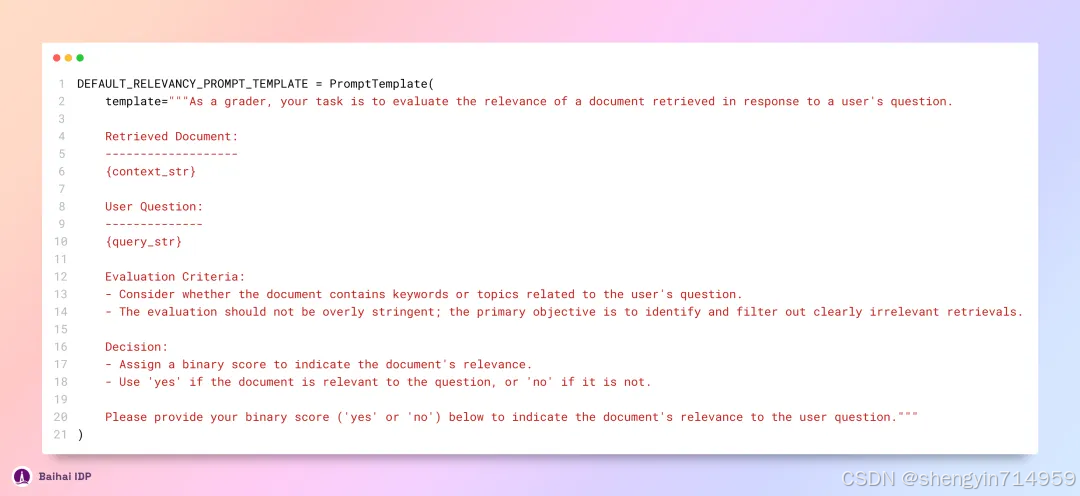
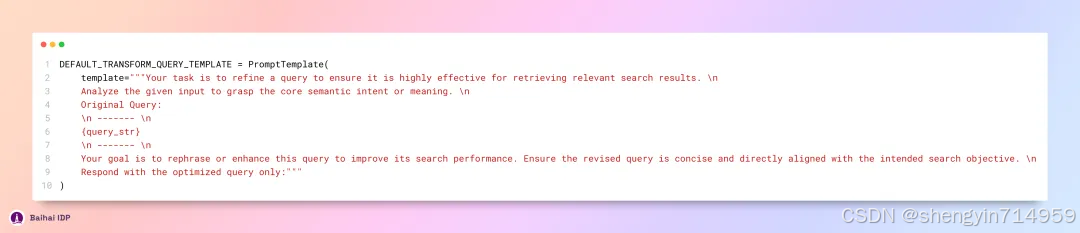
网络搜索功能(web search)并未直接采用用户输入的查询语句。而是通过一种“小样本(few-shot)”策略,精心构造一个引导性提示词,提交给 GPT-3.5 Turbo 模型,借此生成更适配的搜索请求。该引导性提示词的构造方法如下所示:
04 作者对 CRAG 的见解和思考
4.1 CRAG 与 self-RAG 的区别
从操作流程来看,self-RAG 能够跳过检索步骤,直接借助大语言模型(LLM)给出答案,但对比之下, CRAG 在作出回应前,必须先完成信息检索,并加入额外的评估环节。
从系统架构角度分析,self-RAG 的构造更为精细,其背后是更为复杂的训练机制,以及生成阶段中多次迭代的标签生成(label generation)与评估(evaluation)流程,这一特点导致其推理成本相对较高。因此,CRAG 比 selfRAG 更加轻量化。
谈及其性能表现,如图 5 所示,在大多数应用场景中,CRAG 的性能普遍优于 self-RAG。
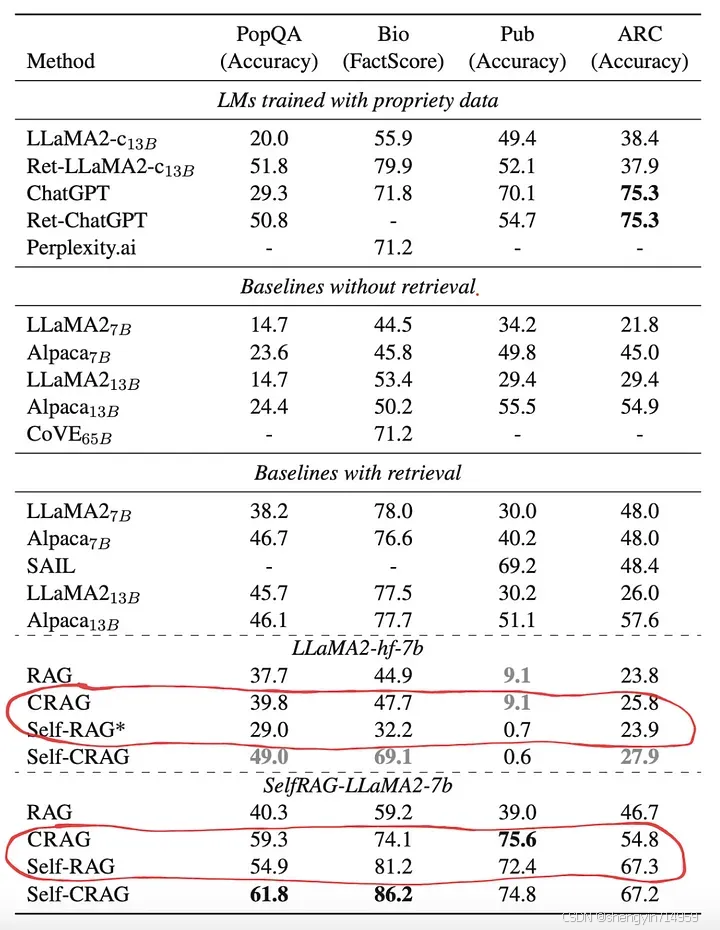
图 5:四大数据集相关测试集上的全面评估结果。这些结果依据不同的 LLM 分类展示。其中,加粗数值表示所有方法和 LLM 中的最优表现;而灰色的加粗数值,则表示特定 LLM 的最佳性能。标注星号(*)的内容是通过 CRAG 重新验证得到的结果,其余结果均直接引述自相关研究文献。Source: 《Corrective Retrieval Augmented Generation》
4.2 对检索评估器的进一步改进
检索评估器可以看作是一个评估分数分类模型,它负责评估查询语句和文档之间的相关性,作用近似于 RAG 系统中的重排模型(re-ranking model)。
为了提升这类相关性判断模型(relevance judgement models)的实用性,可以集成更多贴近实际场景的特性。比如,在科研论文的问答 RAG 场景中,会有大量专业词汇;而在旅游领域的 RAG 场景下,则更多的是日常交流式的用户提问。
通过向检索评估器的训练数据中融入场景特征(scene features),能有效增强其评估文档相关性的能力。此外,还可以引入用户意图(user intentions)、文本差异度(edit distance)等因素作为辅助特征,如图 6 所示:
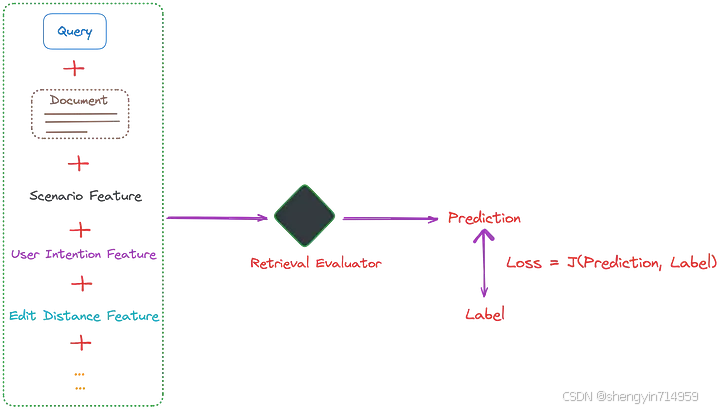
图 6: 通过整合更多额外特征,CRAG系统中检索评估器的训练效能进一步提升。图片由作者提供。
另外,从 T5-Large 模型取得的成效来看,轻量级模型似乎也能取得不错的效果,这无疑为 CRAG 技术在规模较小的团队或公司中的推广与应用带来了希望。
4.3 检索评估器的评分标准与阈值设定
如前文所述,不同类型的数据其阈值各有不同。值得注意的是,“不确定”及“不正确”类别阈值普遍趋近于 -0.9 ,这表明大部分检索到的信息仍与查询语句具有一定相关性。因此,完全摒弃这些检索到的知识,转而纯依赖网页搜索或许并非明智之举。
针对实际应用场景,需紧密贴合具体问题情景与实际需求进行灵活调整。
05 Conclusion
本文从一个生动实例入手,逐步概述 CRAG 的核心流程,并辅以代码解析,其间穿插个人的见解与深度思考。
综上所述,CRAG 作为一个即插即用的插件,可以大幅度提高 RAG 的性能表现,为 RAG 的改进提供了一个轻量级解决方案。若您对 RAG 技术感兴趣,敬请阅读本系列其他文章。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









