







目录
数据结构
基本数据结构
栈与队列
栈:后进先出
STACK-EMPTY(S)
输入:一个栈S
输出:判断栈是否为空,若为空则返回TRUE,否则返回FALSE
if S.top == 0 // 栈顶指针为0表示栈为空
return TRUE // 返回TRUE表示栈为空
else
return FALSE // 返回FALSE表示栈不为空
PUSH(S, x)
输入:一个栈S和要入栈的元素x
功能:将元素x入栈
S.top = S.top + 1 // 将栈顶指针加1,表示栈的大小增加一个位置
S[S.top] = x // 将元素x存放在栈顶指针所指向的位置
POP(S)
输入:一个栈S
输出:从栈顶弹出一个元素并返回该元素的值
功能:将栈顶元素出栈
if STACK-EMPTY(S) // 先判断栈是否为空
error "underflow" // 若栈为空,则出现栈下溢错误
else
S.top = S.top - 1 // 将栈顶指针减1,表示将栈顶元素出栈
return S[S.top + 1] // 返回栈顶元素的值
队列:先进先出
ENQUEUE(Q, x)
输入:一个循环队列Q和要入队的元素x
功能:将元素x入队
Q[Q.tail] = x // 将元素x存放在队列的尾部,即tail指向的位置
if Q.tail == Q.length // 如果tail指向最后一个位置
Q.tail = 1 // 则将tail置为1,形成循环
else
Q.tail = Q.tail + 1 // 否则将tail指针后移一位,指向下一个位置
DEQUEUE(Q)
输入:一个循环队列Q
输出:从队头出队一个元素并返回该元素的值
功能:将队头元素出队
x = Q[Q.head] // 将队头元素赋值给x,表示要出队的元素
if Q.head == Q.length // 如果head指向最后一个位置
Q.head = 1 // 则将head置为1,形成循环
else
Q.head = Q.head + 1 // 否则将head指针后移一位,指向下一个位置
return x // 返回出队的元素的值
链表
链表搜索
单链表(Singly Linked List)数据结构中的查找操作
LIST-SEARCH(L, k)
输入:一个单链表L和要查找的关键字k
输出:查找到关键字k对应的节点,若未找到则返回NIL
x = L.head // 从链表的头节点开始查找,将头节点赋值给x
while x != NIL and x.key != k // 当x不为空且节点的关键字不等于k时,继续查找
x = x.next // 将x指向下一个节点,继续查找
return x // 返回查找到的节点,若未找到则返回NIL
链表插入
单链表(Singly Linked List)数据结构中的插入操作
LIST-INSERT(L, x)
输入:一个单链表L和要插入的节点x
功能:将节点x插入到单链表L的头部
x.next = L.head // 将节点x的next指针指向当前链表的头节点,将x插入到头部
if L.head != NIL // 如果当前链表不为空
L.head.prev = x // 将原头节点的prev指针指向新插入的节点x
L.head = x // 将链表的头指针指向新插入的节点x
x.prev = NIL // 将节点x的prev指针置为NIL,因为x是头节点,没有前驱节点
链表删除
单链表(Singly Linked List)数据结构中的删除操作
LIST-DELETE(L, x)
输入:一个单链表L和要删除的节点x
功能:从单链表L中删除节点x
if x.prev != NIL // 如果x的前驱节点不为空
x.prev.next = x.next // 将x的前驱节点的next指针指向x的后继节点,跳过x
else
L.head = x.next // 否则,将x的后继节点作为新的头节点,即删除头节点
if x.next != NIL // 如果x的后继节点不为空
x.next.prev = x.prev // 将x的后继节点的prev指针指向x的前驱节点,跳过x
LIST-SEARCH(L, k)
输入:一个单链表L和要查找的关键字k
输出:查找到关键字k对应的节点,若未找到则返回NIL
x = L.head // 从链表的头节点开始查找,将头节点赋值给x
while x != NIL and x.key != k // 当x不为空且节点的关键字不等于k时,继续查找
x = x.next // 将x指向下一个节点,继续查找
return x // 返回查找到的节点,若未找到则返回NIL
LIST-INSERT(L, x)
输入:一个单链表L和要插入的节点x
功能:将节点x插入到单链表L的头部
x.next = L.head // 将节点x的next指针指向当前链表的头节点,将x插入到头部
if L.head != NIL // 如果当前链表不为空
L.head.prev = x // 将原头节点的prev指针指向新插入的节点x
L.head = x // 将链表的头指针指向新插入的节点x
x.prev = NIL // 将节点x的prev指针置为NIL,因为x是头节点,没有前驱节点
LIST-DELETE(L, x)
输入:一个单链表L和要删除的节点x
功能:从单链表L中删除节点x
if x.prev != NIL // 如果x的前驱节点不为空
x.prev.next = x.next // 将x的前驱节点的next指针指向x的后继节点,跳过x
else
L.head = x.next // 否则,将x的后继节点作为新的头节点,即删除头节点
if x.next != NIL // 如果x的后继节点不为空
x.next.prev = x.prev // 将x的后继节点的prev指针指向x的前驱节点,跳过x
哨兵
在单链表中使用哨兵(Sentinel)节点进行删除操作可以简化代码并避免一些特殊情况的处理。哨兵节点是一个额外的虚拟节点,位于链表的头部或尾部,不包含实际数据,只作为辅助节点,使链表操作更加方便。
LIST-DELETE'(L, x)
输入:一个使用哨兵节点的单链表L和要删除的节点x
功能:从单链表L中删除节点x
x.prev.next = x.next // 将x的前驱节点的next指针指向x的后继节点,跳过x
x.next.prev = x.prev // 将x的后继节点的prev指针指向x的前驱节点,跳过x
带有哨兵节点的单链表(Singly Linked List)数据结构中的查找操作
LIST-SEARCH'(L, k)
输入:一个带有哨兵节点的单链表L和要查找的关键字k
输出:查找到关键字k对应的节点,若未找到则返回L.nil
x = L.nil.next // 从链表的第一个实际节点开始查找,跳过哨兵节点
while x != L.nil and x.key != k // 当x不是哨兵节点且节点的关键字不等于k时,继续查找
x = x.next // 将x指向下一个节点,继续查找
return x // 返回查找到的节点,若未找到则返回L.nil
LIST-INSERT'(L, x)
输入:一个带有哨兵节点的单链表L和要插入的节点x
功能:将节点x插入到带有哨兵节点的单链表L的头部
x.next = L.nil.next // 将节点x的next指针指向原链表的第一个实际节点
L.nil.next.prev = x // 将原链表的第一个实际节点的prev指针指向新插入的节点x
L.nil.next = x // 将哨兵节点的next指针指向新插入的节点x,将x插入到链表头部
x.prev = L.nil // 将节点x的prev指针置为哨兵节点,因为x是头节点的前驱节点
指针与对象的实现
简单的内存分配与释放操作
ALLOCATE-OBJECT()
功能:分配一个新的对象
输出:返回分配的对象
if free == NIL // 如果空闲列表为空
error "out of space" // 报错,表示内存空间已用完,无法分配新的对象
else
x = free // 从空闲列表中取出一个空闲对象
free = x.next // 将空闲列表的头指针指向下一个空闲对象,从空闲列表中移除x
return x // 返回分配的对象x
FREE-OBJECT(x)
输入:一个要释放的对象x
功能:将对象x释放,使其成为空闲对象
x.next = free // 将对象x插入到空闲列表的头部
free = x // 更新空闲列表的头指针,使其指向新的空闲对象x
列表(链表)查找
COMPACT-LIST-SEARCH(L, n, k)
输入:一个包含n个元素的列表L,其中每个元素都有一个key属性表示关键字,以及要查找的关键字k
输出:如果找到关键字k对应的节点,则返回该节点的位置;否则返回NIL
i = L // 初始化i为列表L的头节点
while i != NIL and key[i] < k // 当i不为空且当前节点的关键字小于k时,继续查找
j = RANDOM(1, n) // 随机选择一个范围在[1, n]的整数j
if key[i] < key[j] and key[j] <= k // 如果当前节点的关键字小于j节点的关键字且j节点的关键字小于等于k
i = j // 则将i指向j节点
if key[i] == k // 如果当前节点的关键字等于k
return i // 则返回当前节点的位置
i = next[i] // 将i指向下一个节点,继续查找
if i == NIL or key[i] > k // 如果i为空或当前节点的关键字大于k
return NIL // 则返回NIL,表示未找到关键字k对应的节点
else
return i // 否则返回当前节点的位置,表示找到了关键字k对应的节点
改进后的列表(链表)查找算法
COMPACT-LIST-SEARCH'(L, n, k, t)
输入:一个包含n个元素的列表L,其中每个元素都有一个key属性表示关键字,以及要查找的关键字k和随机选择节点的次数t
输出:如果找到关键字k对应的节点,则返回该节点的位置;否则返回NIL
i = L // 初始化i为列表L的头节点
for q = 1 to t // 进行t次随机选择节点的操作
j = RANDOM(1, n) // 随机选择一个范围在[1, n]的整数j
if key[i] < key[j] and key[j] <= k // 如果当前节点的关键字小于j节点的关键字且j节点的关键字小于等于k
i = j // 则将i指向j节点
if key[i] == k // 如果当前节点的关键字等于k
return i // 则返回当前节点的位置
while i != NIL and key[i] < k // 当i不为空且当前节点的关键字小于k时,继续查找
i = next[i] // 将i指向下一个节点,继续查找
if i == NIL or key[i] > k // 如果i为空或当前节点的关键字大于k
return NIL // 则返回NIL,表示未找到关键字k对应的节点
else
return i // 否则返回当前节点的位置,表示找到了关键字k对应的节点
散列表
直接寻址表
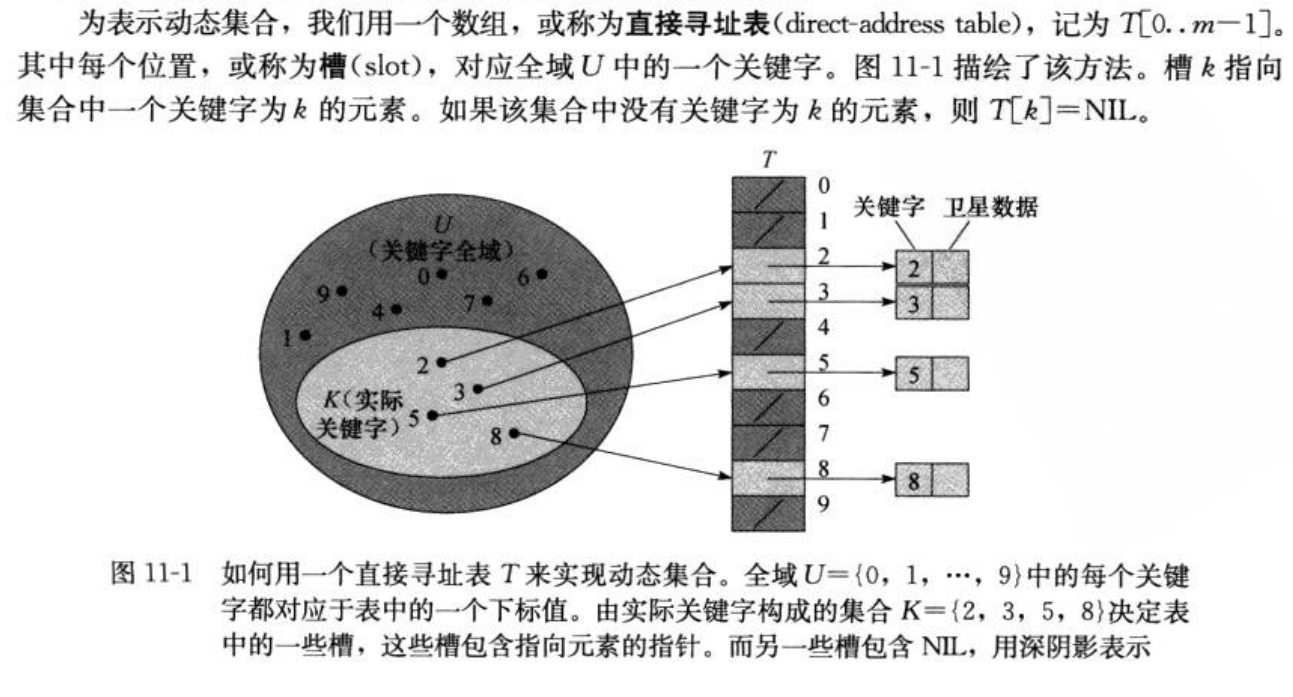
这是一个基于直接寻址表(Direct-Address Table)的数据结构的伪代码,包括查找(DIRECT-ADDRESS-SEARCH)、插入(DIRECT-ADDRESS-INSERT)和删除(DIRECT-ADDRESS-DELETE)操作。
直接寻址表是一种用于动态集合操作的简单数据结构,适用于关键字取值范围有限且已知的情况。它的主要特点是使用一个数组来存储元素,数组的下标就是关键字的值。
DIRECT-ADDRESS-SEARCH(T, k)
输入:一个直接寻址表T和要查找的关键字k
输出:查找到关键字k对应的元素,若未找到则返回NIL
return T[k] // 直接返回数组T中下标为k的元素,即关键字k对应的元素
DIRECT-ADDRESS-INSERT(T, x)
输入:一个直接寻址表T和要插入的元素x
功能:将元素x插入到直接寻址表T中
T[x.key] = x // 将元素x存放在数组T中下标为x.key的位置,x.key是元素x的关键字
DIRECT-ADDRESS-DELETE(T, x)
输入:一个直接寻址表T和要删除的元素x
功能:从直接寻址表T中删除元素x
T[x.key] = NIL // 将数组T中下标为x.key的位置置为NIL,表示删除元素x
散列表
这是一个基于链式哈希表(Chained Hash Table)的数据结构的伪代码,包括插入(CHAINED-HASH-INSERT)、查找(CHAINED-HASH-SEARCH)和删除(CHAINED-HASH-DELETE)操作。
链式哈希表是一种用于解决散列冲突的方法,它将具有相同散列值的元素存储在同一个链表中。在链式哈希表中,每个位置对应一个散列桶,每个散列桶存储一个链表,链表中存放散列值相同的元素。
CHAINED-HASH-INSERT(T, x)
输入:一个链式哈希表T和要插入的元素x
功能:将元素x插入到链式哈希表T中
insert x at the head of list T[h(x.key)] // 将元素x插入到链表T[h(x.key)]的头部
CHAINED-HASH-SEARCH(T, k)
输入:一个链式哈希表T和要查找的关键字k
输出:查找到关键字k对应的元素,若未找到则返回NIL
功能:在链式哈希表T中查找关键字k对应的元素
search for an element with key k in list T[h(k)] // 在链表T[h(k)]中查找关键字k对应的元素
CHAINED-HASH-DELETE(T, x)
输入:一个链式哈希表T和要删除的元素x
功能:从链式哈希表T中删除元素x
delete x from the list T[h(x.key)] // 从链表T[h(x.key)]中删除元素x
散列函数
除法散列法
取 k k k除以 m m m的余数
h ( k ) = k m o d m h(k)=k\mathrm{~mod~}m h(k)=k mod m
乘法散列法
构造散列函数的乘法散列法包含两个步骤。第一步,用关键字 k k k乘上常数 A A A ( 0 < A < 1 0<A<1 0<A<1),并提取 k A kA kA的小数部分。第二步,用 m m m乘以这个值,再向下取整。
h ( k ) = ⌊ m ( k A mod 1 ) ⌋ h(k)=\lfloor m(k\text{A mod}1)\rfloor h(k)=⌊m(kA mod1)⌋
全域散列法
开放寻址法
基于开放寻址法(Open Addressing)的哈希表的插入操作
HASH-INSERT(T, k)
输入:一个哈希表T和要插入的关键字k
功能:将关键字k插入到哈希表T中
i = 0 // 初始化i为0,用于迭代寻找哈希槽位
repeat
j = h(k, i) // 使用哈希函数h计算关键字k在哈希表中的位置,计算方法为h(k, i) = (h(k) + i) mod m,其中m是哈希表大小
if T[j] == NIL // 如果哈希槽位T[j]为空,表示找到了可用的槽位
T[j] = k // 将关键字k存储在槽位T[j]中
return j // 返回关键字k在哈希表中的位置j
else
i = i + 1 // 否则,继续寻找下一个槽位,i增加1
until i == m // 直到遍历整个哈希表,仍未找到可用的槽位
error "hash table overflow" // 如果遍历整个哈希表仍未找到可用的槽位,则表示哈希表已满,抛出哈希表溢出错误
基于开放寻址法(Open Addressing)的哈希表的查找操作
HASH-SEARCH(T, k)
输入:一个哈希表T和要查找的关键字k
输出:查找到关键字k对应的槽位,若未找到则返回NIL
功能:在哈希表T中查找关键字k对应的槽位
i = 0 // 初始化i为0,用于迭代寻找哈希槽位
repeat
j = h(k, j) // 使用哈希函数h计算关键字k在哈希表中的位置,计算方法为h(k, j) = (h(k) + j) mod m,其中m是哈希表大小
if T[j] == k // 如果哈希槽位T[j]中的元素等于目标关键字k,表示找到了目标元素
return j // 返回目标元素k在哈希表中的位置j
i = i + 1 // 否则,继续向后寻找下一个槽位,i增加1
until T[j] == NIL or i == m // 直到找到目标元素k或者遍历整个哈希表
return NIL // 若遍历整个哈希表仍未找到目标元素k,则返回NIL,表示未找到
完全散列
二叉搜索树
二叉搜索树定义
这是一个二叉搜索树(Binary Search Tree,BST)的中序遍历操作的伪代码。
二叉搜索树是一种二叉树的特殊形式,它满足以下性质:
- 左子树上所有节点的关键字小于根节点的关键字。
- 右子树上所有节点的关键字大于根节点的关键字。
- 左子树和右子树也都是二叉搜索树。
中序遍历是一种二叉树遍历的方法,它的遍历顺序是先遍历左子树,然后访问根节点,最后遍历右子树。对于二叉搜索树来说,中序遍历的结果是一个有序序列。
INORDER-TREE-WALK(x)
输入:一棵二叉搜索树的根节点x
功能:对二叉搜索树进行中序遍历,输出有序的关键字序列
if x != NIL // 如果当前节点x不为空
INORDER-TREE-WALK(x.left) // 递归遍历左子树,对左子树进行中序遍历
print(x.key) // 输出当前节点的关键字,即访问根节点
INORDER-TREE-WALK(x.right) // 递归遍历右子树,对右子树进行中序遍历
先序遍历
PREORDER-TREE-WALK(x)
输入:一棵二叉搜索树的根节点x
功能:对二叉搜索树进行先序遍历,输出先序遍历的结果
if x != NIL // 如果当前节点x不为空
print(x.key) // 输出当前节点的关键字,即访问根节点
PREORDER-TREE-WALK(x.left) // 递归遍历左子树,对左子树进行先序遍历
PREORDER-TREE-WALK(x.right) // 递归遍历右子树,对右子树进行先序遍历
后序遍历
POSTORDER-TREE-WALK(x)
输入:一棵二叉搜索树的根节点x
功能:对二叉搜索树进行后序遍历,输出后序遍历的结果
if x != NIL // 如果当前节点x不为空
POSTORDER-TREE-WALK(x.left) // 递归遍历左子树,对左子树进行后序遍历
POSTORDER-TREE-WALK(x.right) // 递归遍历右子树,对右子树进行后序遍历
print(x.key) // 输出当前节点的关键字,即访问根节点
查询二叉搜索树
查找
二叉搜索树(BST)的查找操作
二叉搜索树是一种特殊的二叉树,它满足以下性质:
- 左子树上所有节点的关键字小于根节点的关键字。
- 右子树上所有节点的关键字大于根节点的关键字。
- 左子树和右子树也都是二叉搜索树。
TREE-SEARCH(x, k)
输入:一棵二叉搜索树的根节点x和目标关键字k
输出:查找到与目标关键字k相等的节点,若未找到则返回NIL
功能:在二叉搜索树中查找与目标关键字k相等的节点
if x == NIL or k == x.key // 如果当前节点x为空或者目标关键字k与当前节点的关键字相等
return x // 返回当前节点x,可能是找到与目标关键字k相等的节点,也可能是未找到
if k < x.key // 如果目标关键字k小于当前节点的关键字
return TREE-SEARCH(x.left, k) // 递归查找左子树,对左子树进行查找操作
else
return TREE-SEARCH(x.right, k) // 否则,递归查找右子树,对右子树进行查找操作
迭代版本的二叉搜索树(BST)的查找操作
ITERATIVE-TREE-SEARCH(x, k)
输入:一棵二叉搜索树的根节点x和目标关键字k
输出:查找到与目标关键字k相等的节点,若未找到则返回NIL
功能:在二叉搜索树中迭代查找与目标关键字k相等的节点
while x != NIL and k != x.key // 当当前节点x不为空且目标关键字k与当前节点的关键字不相等时
if k < x.key // 如果目标关键字k小于当前节点的关键字
x = x.left // 向左子树移动,继续查找
else
x = x.right // 否则,向右子树移动,继续查找
return x // 返回找到的节点,可能是与目标关键字k相等的节点,也可能是NIL表示未找到
最大关键字元素和最小关键字元素
二叉搜索树(BST)的查找最小值
TREE-MINIMUM(x)
输入:一棵二叉搜索树的根节点x
输出:二叉搜索树中的最小关键字节点
功能:在二叉搜索树中查找最小关键字节点
while x.left != NIL // 当左子节点不为空时,说明还未到达最左边的叶子节点
x = x.left // 继续向左子树移动,查找最小关键字节点
return x // 返回最小关键字节点,即为二叉搜索树中的最小值节点
TREE-MAXIMUM(x)
输入:一棵二叉搜索树的根节点x
输出:二叉搜索树中的最大关键字节点
功能:在二叉搜索树中查找最大关键字节点
while x.right != NIL // 当右子节点不为空时,说明还未到达最右边的叶子节点
x = x.right // 继续向右子树移动,查找最大关键字节点
return x // 返回最大关键字节点,即为二叉搜索树中的最大值节点
前驱后继
二叉搜索树(BST)中查找某节点的后继节点
TREE-SUCCESSOR(x)
输入:一个二叉搜索树中的节点x
输出:二叉搜索树中节点x的后继节点
功能:查找给定节点x在中序遍历中的后继节点
if x.right != NIL // 如果节点x的右子树不为空
return TREE-MINIMUM(x.right) // 返回节点x右子树的最小节点,即节点x的后继节点
y = x.p // 否则,找到节点x的父节点y
while y != NIL and x == y.right // 在向上遍历父节点y的过程中,直到找到一个父节点y满足y不为空且x是y的左子节点为止
x = y // 将当前节点x移动到父节点y
y = y.p // 将父节点y移动到它的父节点,继续向上遍历
return y // 返回最终找到的父节点y,即为节点x的后继节点
插入删除
插入
二叉搜索树(BST)中插入节点
TREE-INSERT(T, z)
输入:一个二叉搜索树T和待插入的节点z
输出:在二叉搜索树T中插入新节点z后的树
功能:将新节点z插入到二叉搜索树T中
y = NIL // 初始化y为NIL,用于记录x的父节点
x = T.root // 初始化x为根节点,从根节点开始查找插入位置
while x != NIL // 当x不为空时,说明还未到达插入位置
y = x // 将当前节点x作为父节点y
if z.key < x.key // 如果新节点z的关键字小于当前节点x的关键字
x = x.left // 向左子树移动,继续查找插入位置
else
x = x.right // 否则,向右子树移动,继续查找插入位置
z.p = y // 设置新节点z的父节点为y
if y == NIL // 如果y为NIL,说明二叉搜索树T为空
T.root = z // 将新节点z作为根节点,插入空树T
elseif z.key < y.key // 否则,如果新节点z的关键字小于父节点y的关键字
y.left = z // 将新节点z作为y的左子节点插入
else
y.right = z // 否则,将新节点z作为y的右子节点插入
删除
二叉搜索树(BST)中执行节点替换(Transplant)操作
TRANSPLANT(T, u, v)
输入:一棵二叉搜索树T,两个节点u和v,用节点v替换节点u
输出:执行节点替换后的二叉搜索树T
功能:将节点v替换节点u,并维护二叉搜索树的性质
if u.p == NIL // 如果节点u没有父节点,即节点u为根节点
T.root = v // 将根节点设置为节点v
elseif u == u.p.left // 否则,如果节点u是其父节点u.p的左子节点
u.p.left = v // 将节点v设置为u.p的左子节点
else // 否则,节点u是其父节点u.p的右子节点
u.p.right = v // 将节点v设置为u.p的右子节点
if v != NIL // 如果节点v不为空,即v不为NIL
v.p = u.p // 将节点v的父节点指针设置为u的父节点,即完成节点替换
二叉搜索树(BST)中执行节点删除(TREE-DELETE)操作
TREE-DELETE(T, z)
输入:一棵二叉搜索树T,待删除的节点z
输出:执行节点删除后的二叉搜索树T
功能:从二叉搜索树T中删除给定节点z,并维护二叉搜索树的性质
if z.left == NIL // 如果节点z没有左子节点
TRANSPLANT(T, z, z.right) // 使用z的右子节点替换z
elseif z.right == NIL // 如果节点z没有右子节点
TRANSPLANT(T, z, z.left) // 使用z的左子节点替换z
else // 否则,节点z既有左子节点也有右子节点
y = TREE-MINIMUM(z.right) // 找到z的右子树中最小的节点y
if y.p != z // 如果y不是z的直接右子节点
TRANSPLANT(T, y, y.right) // 使用y的右子节点替换y
y.right = z.right // 将z的右子树连接到y的右子节点上
y.right.p = y // 更新y的右子节点的父节点指针
TRANSPLANT(T, z, y) // 使用y替换z
y.left = z.left // 将z的左子树连接到y的左子节点上
y.left.p = y // 更新y的左子节点的父节点指针
随机构建二叉搜索树
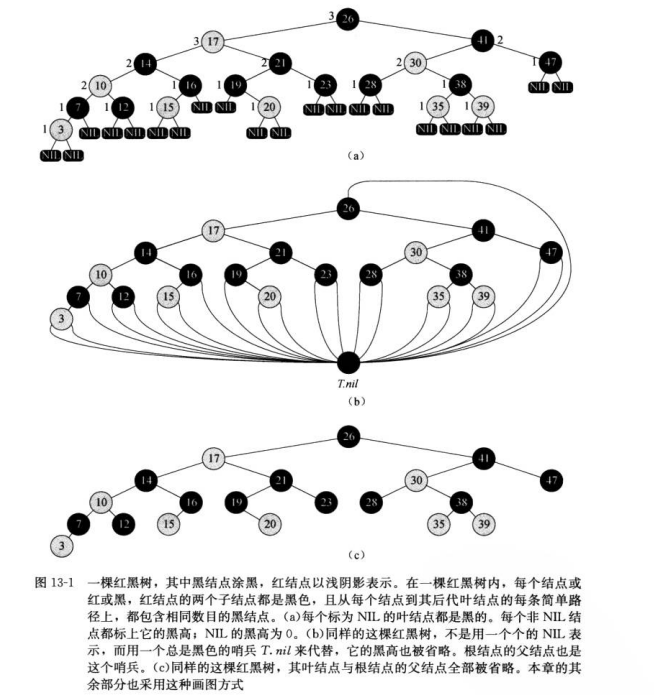
红黑树
性质

旋转
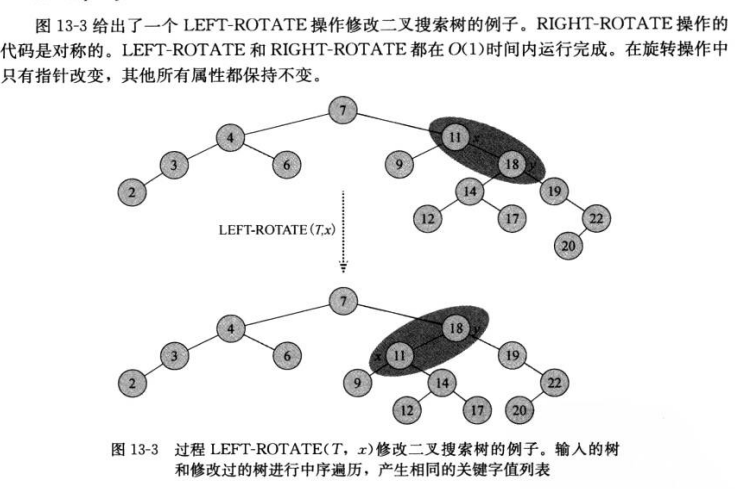
红黑树中执行左旋转(LEFT-ROTATE)操作
LEFT-ROTATE(T, x)
输入:一棵红黑树T,待旋转的节点x
输出:执行左旋转后的红黑树T
功能:对红黑树T中的节点x进行左旋转操作
y = x.right // 将节点y设置为节点x的右子节点,用于进行左旋转
x.right = y.left // 将y的左子树变为x的右子树
if y.left != T.nil // 如果y的左子树不为空
y.left.p = x // 将y的左子树的父节点指针指向x
y.p = x.p // 将y的父节点指针指向x的父节点
if x.p == T.nil // 如果x是根节点
T.root = y // 将y设置为根节点
elseif x == x.p.left // 如果x是其父节点的左子节点
x.p.left = y // 将y设置为x的父节点的左子节点
else
x.p.right = y // 否则,将y设置为x的父节点的右子节点
y.left = x // 将x放在y的左子节点上
x.p = y // 更新x的父节点指针,完成左旋转
红黑树中执行右旋转(RIGHT-ROTATE)操作
RIGHT-ROTATE(T, y)
输入:一棵红黑树T,待旋转的节点y
输出:执行右旋转后的红黑树T
功能:对红黑树T中的节点y进行右旋转操作
x = y.left // 将节点x设置为节点y的左子节点,用于进行右旋转
y.left = x.right // 将x的右子树变为y的左子树
if x.right != T.nil // 如果x的右子树不为空
x.right.p = y // 将x的右子树的父节点指针指向y
x.p = y.p // 将x的父节点指针指向y的父节点
if y.p == T.nil // 如果y是根节点
T.root = x // 将x设置为根节点
elseif y == y.p.left // 如果y是其父节点的左子节点
y.p.left = x // 将x设置为y的父节点的左子节点
else
y.p.right = x // 否则,将x设置为y的父节点的右子节点
x.right = y // 将y放在x的右子节点上
y.p = x // 更新y的父节点指针,完成右旋转
插入
红黑树中执行插入操作(RB-INSERT)
红黑树是一种自平衡的二叉搜索树,它在每个节点上增加一个额外的存储位表示节点的颜色(红色或黑色),并通过一些约束条件来保持树的平衡。
RB-INSERT(T, z)
输入:一棵红黑树T,待插入的节点z
输出:执行插入操作后的红黑树T
功能:向红黑树T中插入节点z,并维护红黑树的性质
y = T.nil // 将节点y设置为NIL节点,用于记录节点z的父节点
x = T.root // 将节点x设置为根节点,用于在红黑树中搜索节点z的位置
while x != T.nil // 在红黑树中查找节点z的插入位置
y = x // 更新节点y为节点x,用于记录节点z的父节点
if z.key < x.key
x = x.left // 如果z的关键字小于节点x的关键字,则在x的左子树中继续查找
else
x = x.right // 否则,在x的右子树中继续查找
z.p = y // 将节点z的父节点指针指向节点y
if y == T.nil // 如果节点y为NIL节点,即红黑树为空树
T.root = z // 将z设置为根节点
elseif z.key < y.key // 否则,如果z的关键字小于节点y的关键字
y.left = z // 将z作为节点y的左子节点
else
y.right = z // 否则,将z作为节点y的右子节点
z.left = T.nil // 将z的左子节点设置为NIL节点
z.right = T.nil // 将z的右子节点设置为NIL节点
z.color = RED // 将z的颜色设置为红色,插入操作总是插入红色节点
RB-INSERT-FIXUP(T, z) // 调用RB-INSERT-FIXUP修复红黑树的性质
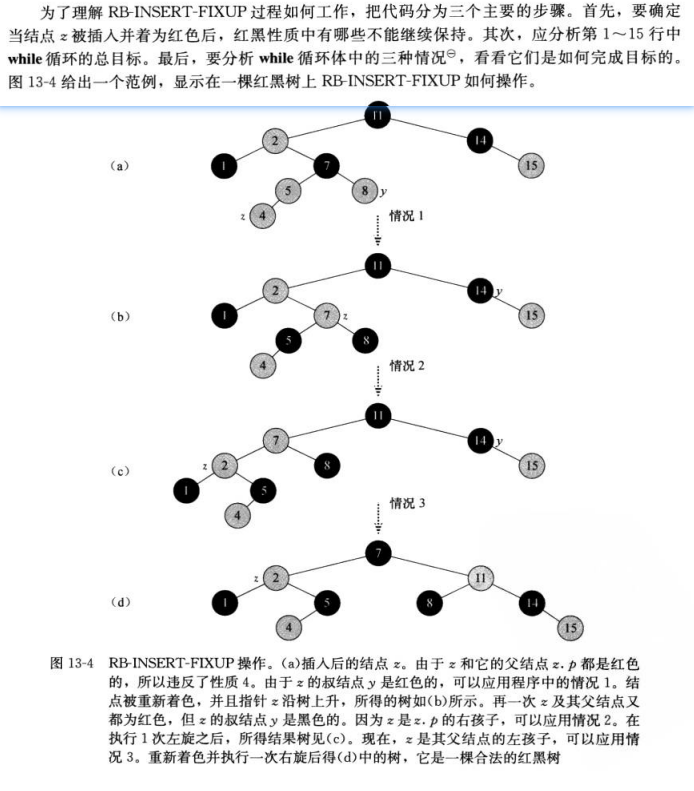
红黑树中执行插入操作后修复性质
RB-INSERT-FIXUP(T, z)
输入:一棵红黑树T,新插入的节点z
输出:修复后满足红黑树性质的红黑树T
功能:修复红黑树在插入节点z后可能破坏的性质,并恢复红黑树的平衡
while z.p.color == RED // 如果节点z的父节点是红色,表示可能破坏红黑树性质
if z.p == z.p.p.left // 如果z的父节点是其祖父节点的左子节点
y = z.p.p.right // 将y设置为z的叔节点(z的祖父节点的右子节点)
if y.color == RED // case 1: 叔节点y是红色
z.p.color = BLACK // 将父节点的颜色设为黑色
y.color = BLACK // 将叔节点的颜色设为黑色
z.p.p.color = RED // 将祖父节点的颜色设为红色
z = z.p.p // 将节点z上移两层,以继续修复性质
else if z == z.p.right // case 2: 叔节点y是黑色,且z是其父节点的右子节点
z = z.p // 将节点z上移一层
LEFT-ROTATE(T, z) // 对节点z进行左旋转,转化为case 3
// case 3: 叔节点y是黑色,且z是其父节点的左子节点
z.p.color = BLACK // 将父节点的颜色设为黑色
z.p.p.color = RED // 将祖父节点的颜色设为红色
RIGHT-ROTATE(T, z.p.p) // 对祖父节点进行右旋转
// 如果z的父节点是其祖父节点的右子节点,与上述情况对称
else (same as then clause with "right" and "left" exchanged)
T.root.color = BLACK // 将根节点的颜色设为黑色,确保红黑树性质5得到满足
删除
红黑树中执行替换节点(RB-TRANSPLANT)操作
RB-TRANSPLANT(T, u, v)
输入:一棵红黑树T,待替换的节点u,替换节点v
输出:执行替换操作后的红黑树T
功能:用节点v替换节点u,并保持红黑树性质不变
if u.p == T.nil // 如果节点u的父节点为NIL节点,即u为根节点
T.root = v // 将v设置为新的根节点
elseif u == u.p.left // 如果节点u是其父节点的左子节点
u.p.left = v // 将v设置为u的父节点的左子节点
else
u.p.right = v // 否则,将v设置为u的父节点的右子节点
v.p = u.p // 将v的父节点指针指向u的父节点
红黑树中执行删除节点(RB-DELETE)操作
RB-DELETE(T, z)
输入:一棵红黑树T,待删除的节点z
输出:执行删除操作后的红黑树T
功能:删除红黑树中的节点z,并保持红黑树性质不变
y = z // 将节点z保存在变量y中,用于后续操作
y-original-color = y.color // 保存y的颜色,用于后续操作
if z.left == T.nil // 如果节点z没有左子节点
x = z.right // 将z的右子节点设置为后继节点x
RB-TRANSPLANT(T, z, z.right) // 删除节点z,并用其右子节点x替换它
elseif z.right == T.nil // 如果节点z没有右子节点,与上述情况对称
x = z.left
RB-TRANSPLANT(T, z, z.left)
else // 如果节点z既有左子节点又有右子节点
y = TREE-MINIMUM(z.right) // 找到z的后继节点y
y-original-color = y.color // 保存y的颜色,用于后续操作
x = y.right // 将y的右子节点设置为后继节点x
if y.p == z // 如果y是z的直接后继
x.p = y // 直接将x的父节点指向y
else // 否则,通过RB-TRANSPLANT操作将y从树中删除,并用其右子节点x替换它
RB-TRANSPLANT(T, y, y.right)
y.right = z.right
y.right.p = y
RB-TRANSPLANT(T, z, y) // 用后继节点y替换z,并将z从树中删除
y.left = z.left // 将z的左子节点作为y的左子节点
y.left.p = y // 更新y的左子节点的父节点指针
y.color = z.color // 将y的颜色设置为z的颜色
if y-original-color == BLACK // 如果删除的节点y原来是黑色
RB-DELETE-FIXUP(T, x) // 对x进行修复操作,以保持红黑树性质
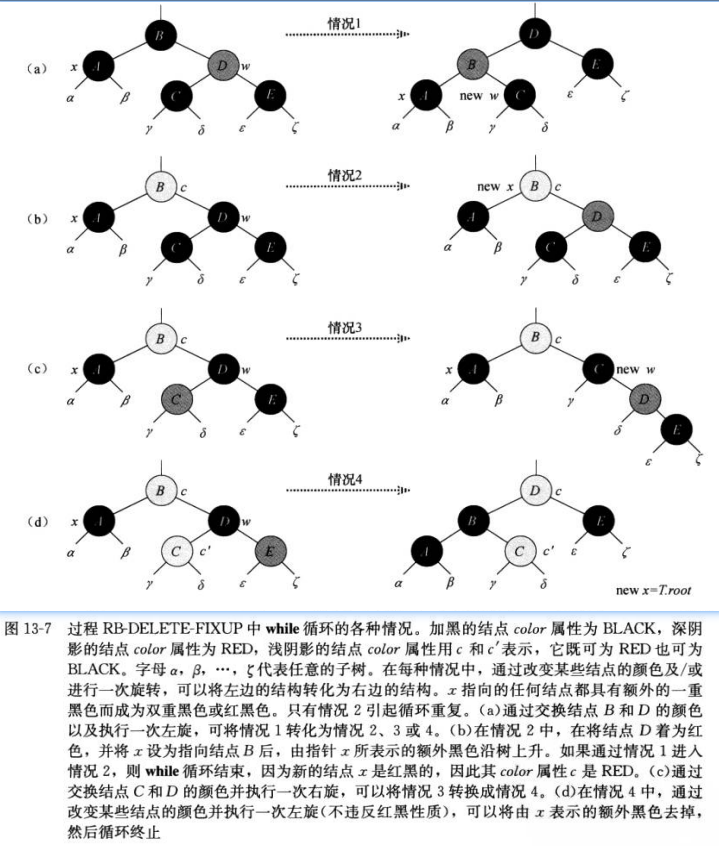
红黑树中执行删除后修复操作(RB-DELETE-FIXUP)
RB-DELETE-FIXUP(T, x)
输入:一棵红黑树T,删除节点后需要修复的节点x
输出:执行修复操作后的红黑树T
功能:对红黑树进行修复操作,以保持红黑树性质
while x != T.root and x.color == BLACK // 当节点x不是根节点且颜色为黑色时,需要进行修复操作
if x == x.p.left // 如果x是其父节点的左子节点
w = x.p.right // 将w设置为x的兄弟节点
if w.color == RED // case 1:兄弟节点w为红色
w.color = BLACK // 将兄弟节点w的颜色设置为黑色
x.p.color = RED // 将x的父节点颜色设置为红色
LEFT-ROTATE(T, x.p) // 对x的父节点进行左旋转
w = x.p.right // 将w设置为x的新兄弟节点
if w.left.color == BLACK and w.right.color == BLACK // case 2:兄弟节点w的两个子节点都为黑色
w.color = RED // 将兄弟节点w的颜色设置为红色
x = x.p // 将x指向其父节点,继续向上修复
else if w.right.color == BLACK // case 3:兄弟节点w的左子节点为红色,右子节点为黑色
w.left.color = BLACK // 将兄弟节点w的左子节点颜色设置为黑色
w.color = RED // 将兄弟节点w的颜色设置为红色
RIGHT-ROTATE(T, w) // 对兄弟节点w进行右旋转
w = x.p.right // 将w设置为x的新兄弟节点
w.color = x.p.color // case 4:兄弟节点w的右子节点为红色
x.p.color = BLACK // 将x的父节点颜色设置为黑色
w.right.color = BLACK // 将兄弟节点w的右子节点颜色设置为黑色
LEFT-ROTATE(T, x.p) // 对x的父节点进行左旋转
x = T.root // 将x指向根节点,结束循环
else (same as then clause with "right" and "left" exchanged) // 与上述代码类似,处理x是其父节点的右子节点的情况
x.color = BLACK // 将节点x的颜色设置为黑色,修复结束
数据结构扩张
动态顺序统计
查找具有给定秩的元素
基于顺序统计树的选择算法(OS-SELECT)
顺序统计树是一种二叉搜索树的扩展,它在每个节点上维护一个额外的属性size,表示以该节点为根的子树中的节点数目。这样,顺序统计树可以在O(log n)时间内找到元素的排名。
OS-SELECT(x, i)
输入:顺序统计树的根节点x,以及要查找的第i小的元素的排名i
输出:第i小的元素对应的节点
功能:在顺序统计树中找到第i小的元素,并返回对应的节点
r = x.left.size + 1 // r表示x的左子树中的节点数目加上x本身,即x的排名(1表示最小,2表示第二小,以此类推)
if i == r // 如果i正好等于x的排名,说明x就是要找的第i小的元素
return x
elseif i < r // 如果i小于x的排名,说明要找的第i小的元素在x的左子树中
return OS-SELECT(x.left, i)
else // 如果i大于x的排名,说明要找的第i小的元素在x的右子树中
return OS-SELECT(x.right, i - r)
确定一个元素的秩
顺序统计树中的排名操作(OS-RANK)
OS-RANK(T, x)
输入:顺序统计树T的根节点,以及要查找其排名的节点x
输出:节点x的排名
功能:在顺序统计树中找到节点x的排名
r = x.left.size + 1 // r表示x的左子树中的节点数目加上x本身,即x的排名(1表示最小,2表示第二小,以此类推)
y = x
while y != T.root // 从节点x开始向上遍历,计算x的排名
if y == y.p.right // 如果y是其父节点的右子节点
r = r + y.p.left.size + 1 // 将y的父节点的左子树节点数目加上1,累计到r中
y = y.p // 将y指向其父节点,继续向上遍历
return r // 返回节点x的排名
对子树规模的保护
顺序统计树中左旋转操作(LEFT-ROTATE)
LEFT-ROTATE(T, x)
输入:顺序统计树T,以及要进行左旋转的节点x
功能:对顺序统计树T进行左旋转操作,以节点x为支点
y = x.right // 将y指向节点x的右子节点
x.right = y.left // 将y的左子树(如果存在)作为x的右子树
if y.left != T.nil // 如果y的左子树不为空,更新y的左子树的父节点指针
y.left.p = x
y.p = x.p // 更新y的父节点指针为x的父节点
if x.p == T.nil // 如果x没有父节点,说明x是根节点
T.root = y // 更新根节点为y
elseif x == x.p.left // 如果x是其父节点的左子节点
x.p.left = y // 更新x的父节点的左子节点为y
else
x.p.right = y // 更新x的父节点的右子节点为y
y.left = x // 将x作为y的左子节点
x.p = y // 将y作为x的父节点
y.size = x.size // 更新y的size为原先x的size
x.size = x.left.size + x.right.size + 1 // 更新x的size为左子树和右子树节点数目之和加上1(包括x本身)
扩张数据结构

区间树
区间树是一种用于有效地存储和搜索具有区间属性的数据结构。每个节点都表示一个区间,其中包含了左端点low和右端点high。区间树能够高效地搜索与给定区间有重叠的所有区间。
在区间树(Interval Tree)中搜索与给定区间i有重叠的区间
INTERVAL-SEARCH(T, i)
输入:区间树T的根节点,以及要搜索的区间i
输出:与给定区间i有重叠的区间对应的节点,如果没有则返回NIL
功能:在区间树中搜索与给定区间i有重叠的区间
x = T.root // 将x指向区间树的根节点
while x != T.nil and i does not overlap x.int // 如果x不为空节点且给定区间i与x的区间x.int不重叠
if x.left != T.nil and x.left.max > i.low // 如果x的左子节点不为空,并且左子节点的max属性大于i的low端点
x = x.left // 向左子树继续搜索
else
x = x.right // 向右子树继续搜索
return x // 返回与给定区间i有重叠的区间对应的节点,如果没有则返回NIL



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











