







KNN 简介
k近邻法(k-nearest neighbor,k-NN)是一种基本的分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。
k近邻算法用一句通俗的古语来说就是:“物以类聚,人以群分”。你要看一个实例的类别,你就可以看它附近是什么类别。如下图1.1所示,当要判断绿色实例的类别的时候,我们可以看看它的附近有哪些类,然后采取多数表决的决策规则(红色2个多于蓝色1个),于是把绿色实例也分类为红色那一类。

k近邻法三要素:距离度量、k 值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的pL距离。k 值小时,k 近邻模型更复杂,容易发生过拟合;k值大时,k 近邻模型更简单,又容易欠拟合。因此k值得选择会对分类结果产生重大影响。k 值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。分类决策规则往往是多数表决,即由输入实例的k个邻近输入实例中的多数类决定输入实例的类。( 近似误差与训练集有关,估计误差与测试集有关 )
距离度量
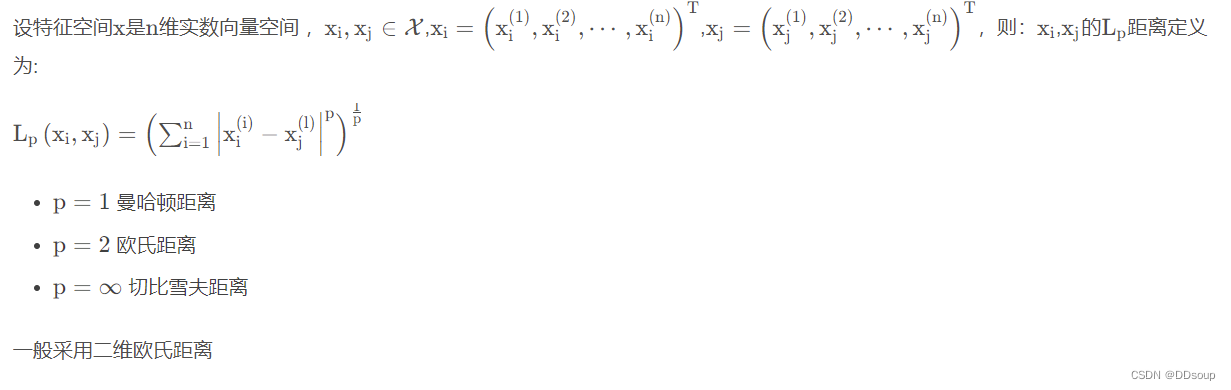
交叉验证选取 K 值
在许多实际应用中数据是不充足的。为了选择好的模型,可以采用交叉验证方法。交叉验证的基本想法是重复地使用数据,把给定的数据进行切分,将切分的数据组合为训练集与测试集,在此基础上反复进行训练测试以及模型的选择。在实现过程中将采用sklearn.model_selection.cross_val_score()实现交叉验证选取k值。
KNN实现
实现K近邻算法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。k近邻法最简单的实现方法是线性扫描,也就是暴力法计算输入实例到每一个训练实例的距离,然后取前k个距离最短的采取多数表决规则进行分类。但是如果训练集的数据量很大时,这种方法就不可行了。为了提高k近邻的搜索效率,可以考虑使用特殊的结构存储训练数据,以减少距离计算的次数,常用的有 k d kdkd(k d kdkd tree)树方法。
KNN算法实现
sklearn.neighborssklearn.neighbors.KNeighborsClassifier(n_neighbors = 5,
weights='uniform',
algorithm = '',
leaf_size = '30',
p = 2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)参数如下:
n_neighbors:这个值就是指 KNN 中的 “K”了。前面说到过,通过调整 K 值,算法会有不同的效果。
weights(权重):最普遍的 KNN 算法无论距离如何,权重都一样,但有时候我们想搞点特殊化,比如距离更近的点让它更加重要。这时候就需要 weight 这个参数了,这个参数有三个可选参数的值,决定了如何分配权重。参数选项如下:
• ‘uniform’:不管远近权重都一样,就是最普通的 KNN 算法的形式。
• ‘distance’:权重和距离成反比,距离预测目标越近具有越高的权重。
• 自定义函数:自定义一个函数,根据输入的坐标值返回对应的权重,达到自定义权重的目的。
algorithm:在 sklearn 中,要构建 KNN 模型有三种构建方式,1. 暴力法,就是直接计算距离存储比较的那种放松。2. 使用 kd 树构建 KNN 模型 3. 使用球树构建。 其中暴力法适合数据较小的方式,否则效率会比较低。如果数据量比较大一般会选择用 KD 树构建 KNN 模型,而当 KD 树也比较慢的时候,则可以试试球树来构建 KNN。参数选项如下:
• ‘brute’ :蛮力实现
• ‘kd_tree’:KD 树实现 KNN
• ‘ball_tree’:球树实现 KNN
• ‘auto’: 默认参数,自动选择合适的方法构建模型
不过当数据较小或比较稀疏时,无论选择哪个最后都会使用 ‘brute’
leaf_size:如果是选择蛮力实现,那么这个值是可以忽略的,当使用KD树或球树,它就是是停止建子树的叶子节点数量的阈值。默认30,但如果数据量增多这个参数需要增大,否则速度过慢不说,还容易过拟合。
p:和metric结合使用的,当metric参数是"minkowski"的时候,p=1为曼哈顿距离, p=2为欧式距离。默认为p=2。
metric:指定距离度量方法,一般都是使用欧式距离。
• ‘euclidean’ :欧式距离
• ‘manhattan’:曼哈顿距离
• ‘chebyshev’:切比雪夫距离
• ‘minkowski’: 闵可夫斯基距离,默认参数
n_jobs:指定多少个CPU进行运算,默认是-1,也就是全部都算。
属性如下:
classes_ : 分类器已知的类别标签,返回ndarray标签数组。
effective_metric_ :距离度量,和上述参数中metric参数设定的距离度量一致。
effective_metric_params_:指标函数附加的关键字参数,对于大多数距离指标,将会和metric参数相同,但如果effective_metric_params_属性设置为‘minkowski’,那么也可能包含p参数的值。返回的形式是字典。
outputs_2d_:训练时当y的形状为(n,)或(n,1),则返回False,否则返回True。
方法如下:
fit(X, y):使用X作为训练数据,y作为标签目标数据进行数据拟合训练。
get_params([deep]):获取参数组成的字典。
kneighbors([X, n_neighbors, return_distance]):找寻一个点的k个邻居。
predict(X):根据提供的数据去预测它的类别标签。
predict_proba(X):返回测试数据X的概率估计值。
score(X, y[, sample_weight]):返回给定数据和标签的平均准确度。
set_params(params):设置估值器的参数。
KNN算法相关API
neighbors.NearestNeighbors([n_neighbors,...]) 用于实现邻居搜索的无监督学习者。
neighbors.KNeighborsClassifier([...]) 实现k近邻投票的分类器。
neighbors.RadiusNeighborsClassifier([...]) 在给定半径内的邻居之间实施投票的分类器
neighbors.KNeighborsRegressor([n_neighbors,...]) 基于k-最近邻居的回归。
neighbors.RadiusNeighborsRegressor([radius,...]) 基于固定半径内的邻居的回归。
neighbors.NearestCentroid([公制,......]) 最近的质心分类器。
neighbors.BallTree BallTree用于快速广义的N点问题
neighbors.KDTree KDTree用于快速广义N点问题
neighbors.LSHForest([n_estimators,radius,...]) 使用LSH林执行近似最近邻搜索。
neighbors.DistanceMetric DistanceMetric类
neighbors.KernelDensity([带宽,......]) 核密度估计
neighbors.kneighbors_graph(X,n_neighbors [,...]) 计算X中点的k-邻居的(加权)图
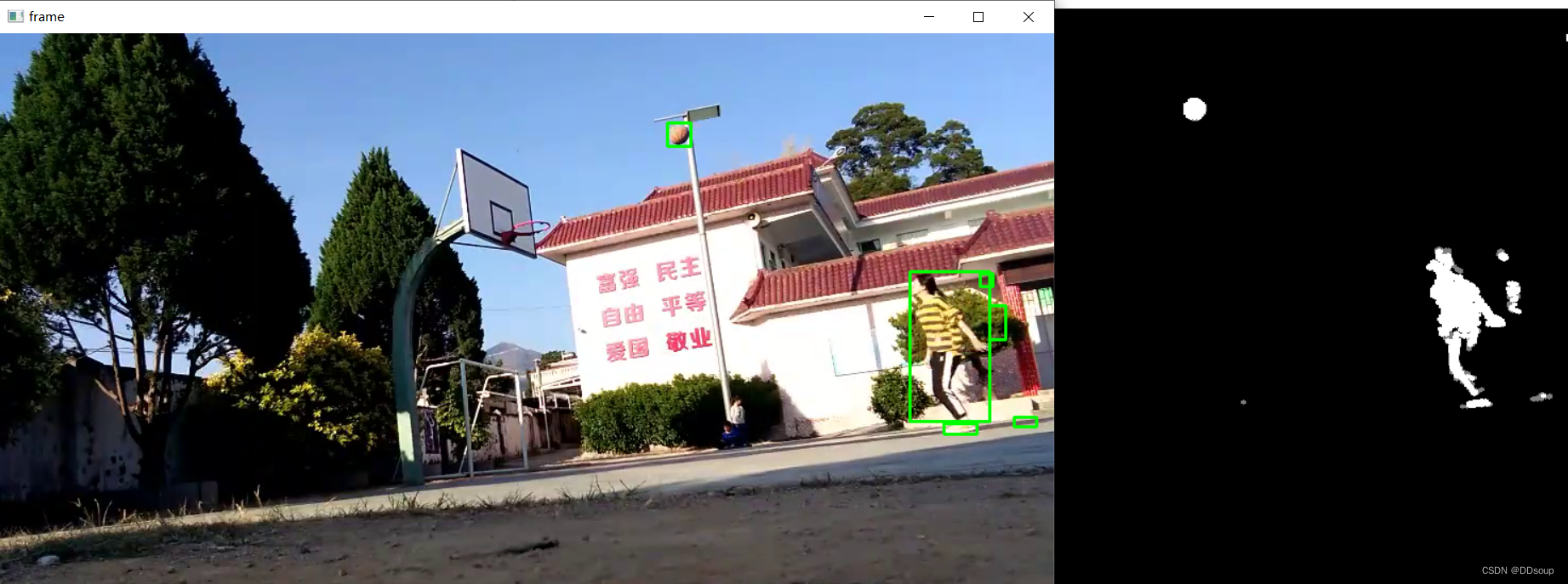
neighbors.radius_neighbors_graph(X,半径) 计算X中点的邻居(加权)图使用OpenCV 用KNN算法训练好的模型进行前景与背景的分割
import cv2 as cv
import numpy as np
import sys
import math
import operator
import torch
import argparse
cap = cv.VideoCapture('C:/Users/86158/Desktop/Meng/Love/99.mp4')
# 卷积核
kernel = cv.getStructuringElement(cv.MORPH_ELLIPSE,(5, 5))
# 高斯混合
fgbg = cv.createBackgroundSubtractorMOG2()
# K-近邻聚类
knn = cv.createBackgroundSubtractorKNN()
while(1):
ret, frame = cap.read()
fgmask = knn.apply(frame)
# 开运算去除小型噪音点
fgmask = cv.morphologyEx(fgmask, cv.MORPH_OPEN, kernel)
contour,hiearachy = cv.findContours(fgmask,cv.RETR_TREE,cv.CHAIN_APPROX_NONE)
for c in contour:
perimeter = cv.arcLength(c, True)
if perimeter > 30:
x, y, w, h = cv.boundingRect(c)
cv.rectangle(frame, (x, y), (x + w, y + h), (0,255,0), 2)
cv.imshow('frame', frame)
cv.imshow('fgmask', fgmask)
k = cv.waitKey(40) & 0xff
if k ==27:
break
cap.release()
cv.destroyAllWindows()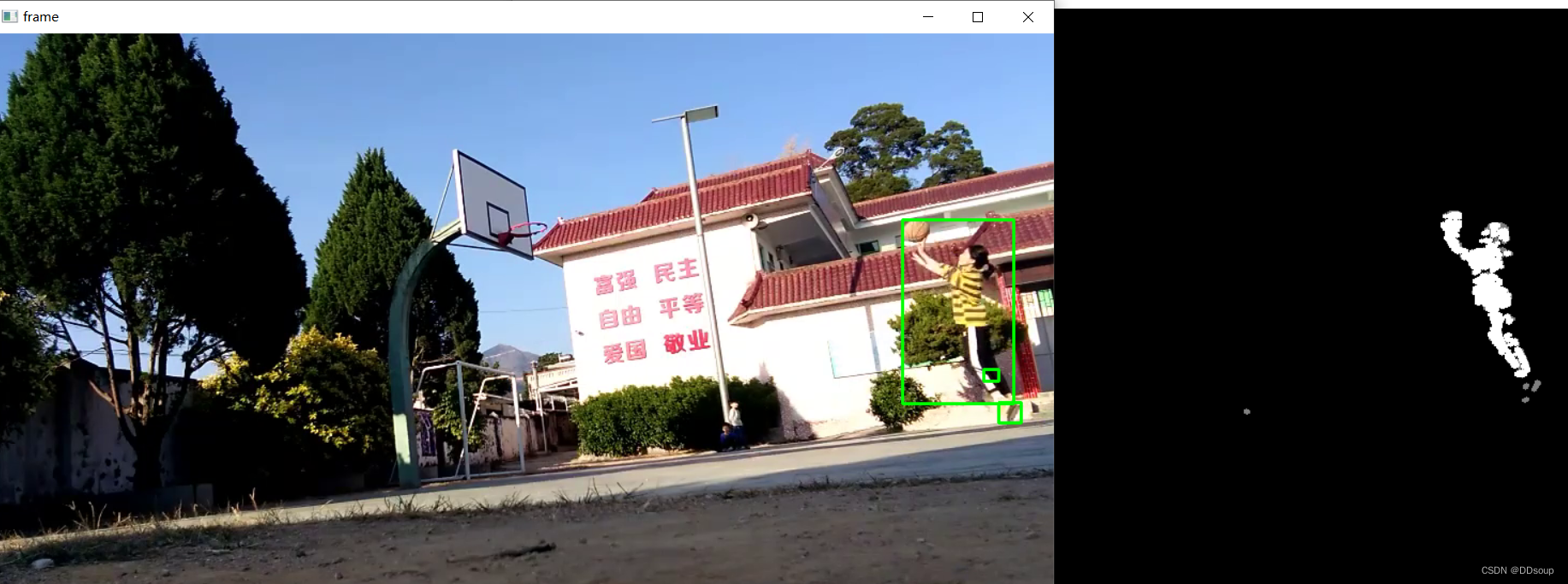


















 3895
3895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











