






 文章介绍了如何手动构建BERT模型,包括BertEmbeddings、Transformer和BertPooler等子模块的实现,以及如何基于HuggingFace的预训练模型加载参数。此外,还详细阐述了在IMDB数据集上进行文本情感分类的微调过程。
文章介绍了如何手动构建BERT模型,包括BertEmbeddings、Transformer和BertPooler等子模块的实现,以及如何基于HuggingFace的预训练模型加载参数。此外,还详细阐述了在IMDB数据集上进行文本情感分类的微调过程。
前段时间学习了NLP相关的一些内容,这一篇主要记录NLP中的一个重要模型——Bert模型的手动实现、如何通过自定义接口实现预训练参数的加载以及在IMDB数据集上微调模型实现文本情感分类任务。
参考《动手学深度学习》搭建BERT语言模型,并加载huggingface上的预训练参数。主要包括如下内容:
- 编写BertEmbeddings、Transformer、BerPooler等Bert模型所需子模块代码。
- 在子模块基础上定义Bert模型结构。
- 定义Bert模型的参数配置接口。
- 定义自己搭建的Bert模型和huggingface上预训练的Bert模型的参数映射关系。
- 定义加载huggingface上预训练的Bert模型的参数到本地Bert模型的方法。
相关源代码链接:
https://download.youkuaiyun.com/download/m0_61142248/87360575
https://download.youkuaiyun.com/download/m0_61142248/87360585
https://download.youkuaiyun.com/download/m0_61142248/87364714
https://download.youkuaiyun.com/download/m0_61142248/87360565
1.编写子模块
Bert模型所需子模块主要包括BertEmbeddings、Transformer、BerPooler,其中Transformer由多头自注意力模块MultiHeadSelfAttention()和前馈模块FeedForward(),FeedForward()中的激活函数为GELU()。
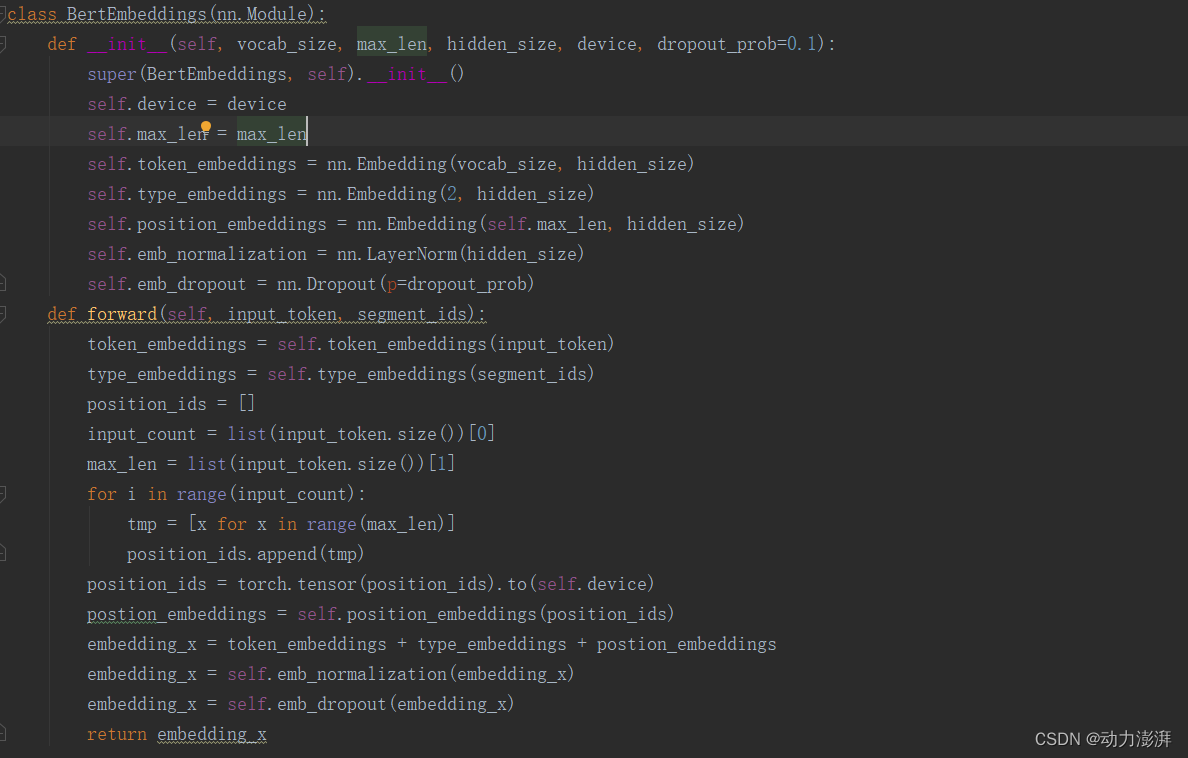
定义BerEmbeddings模块
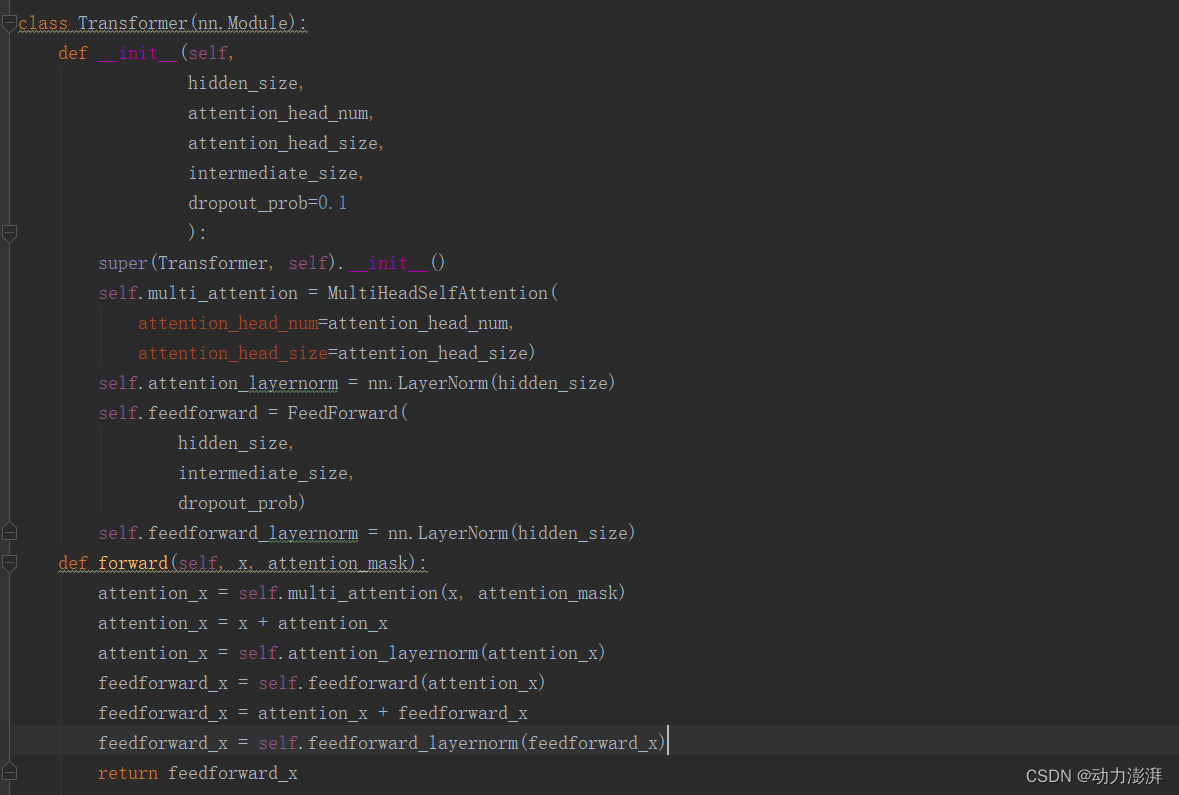
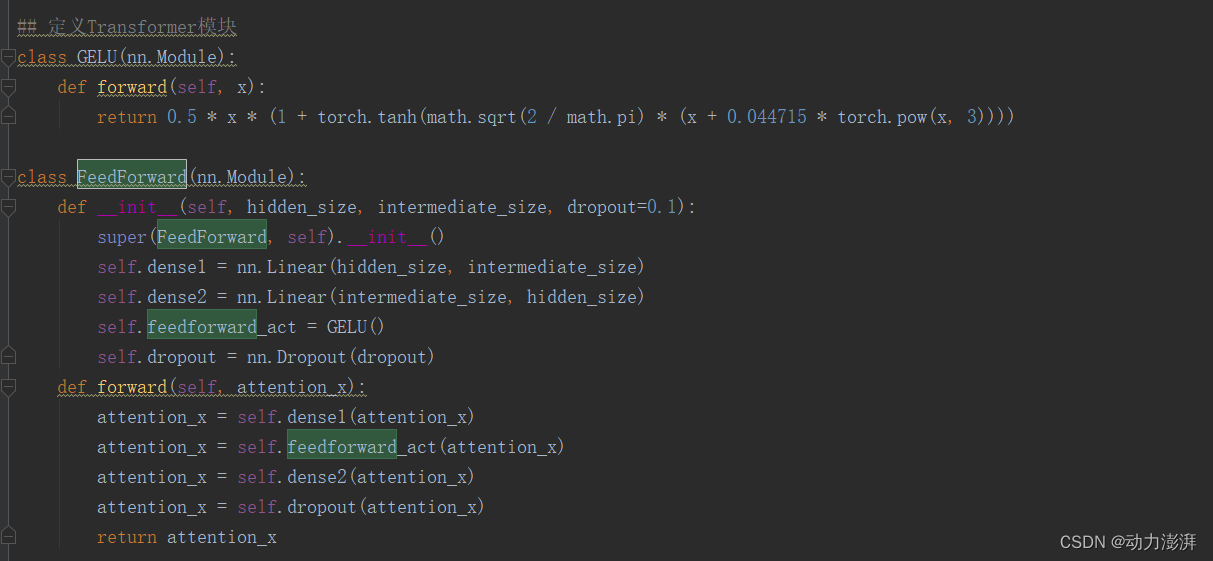
定义Transformer模块
Transformer模块包含多头自注意力模块MultiHeadSelfAttention()和前馈模块FeedForward(),其中FeedForward()中的激活函数为GELU()。
Transformer模块实现:
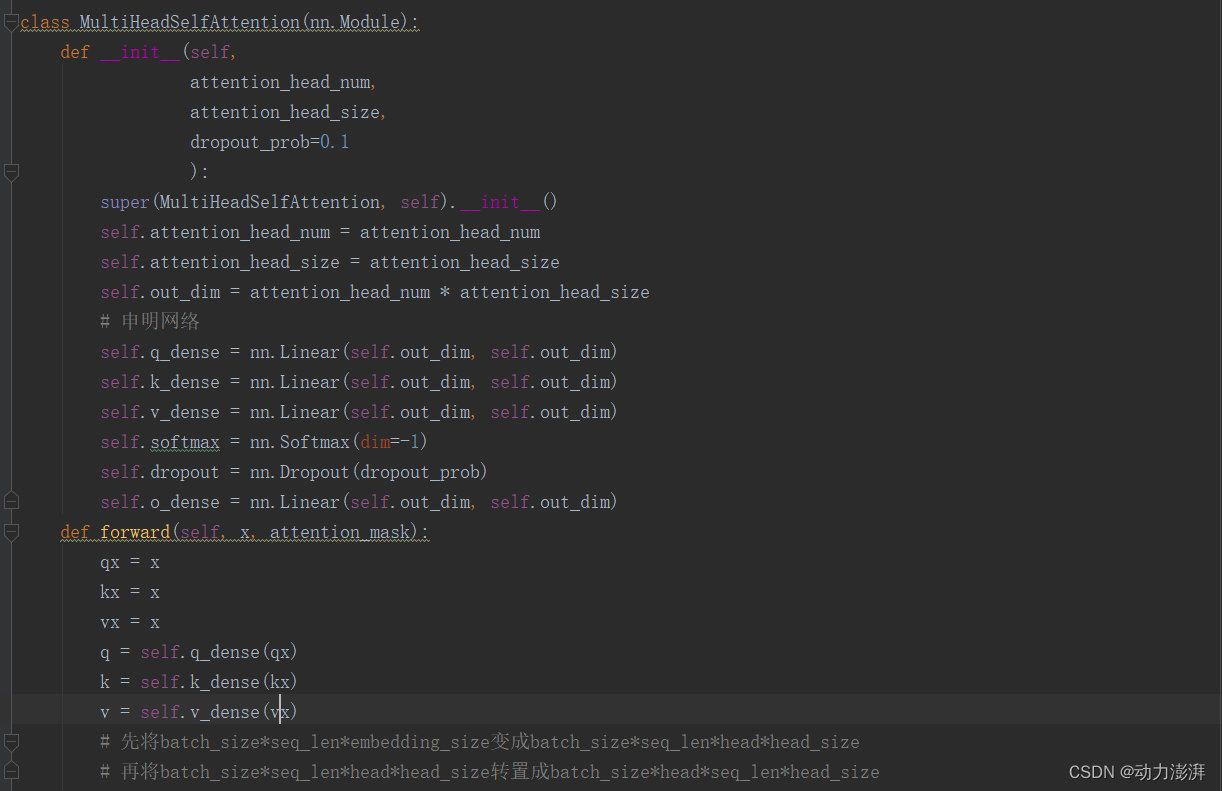
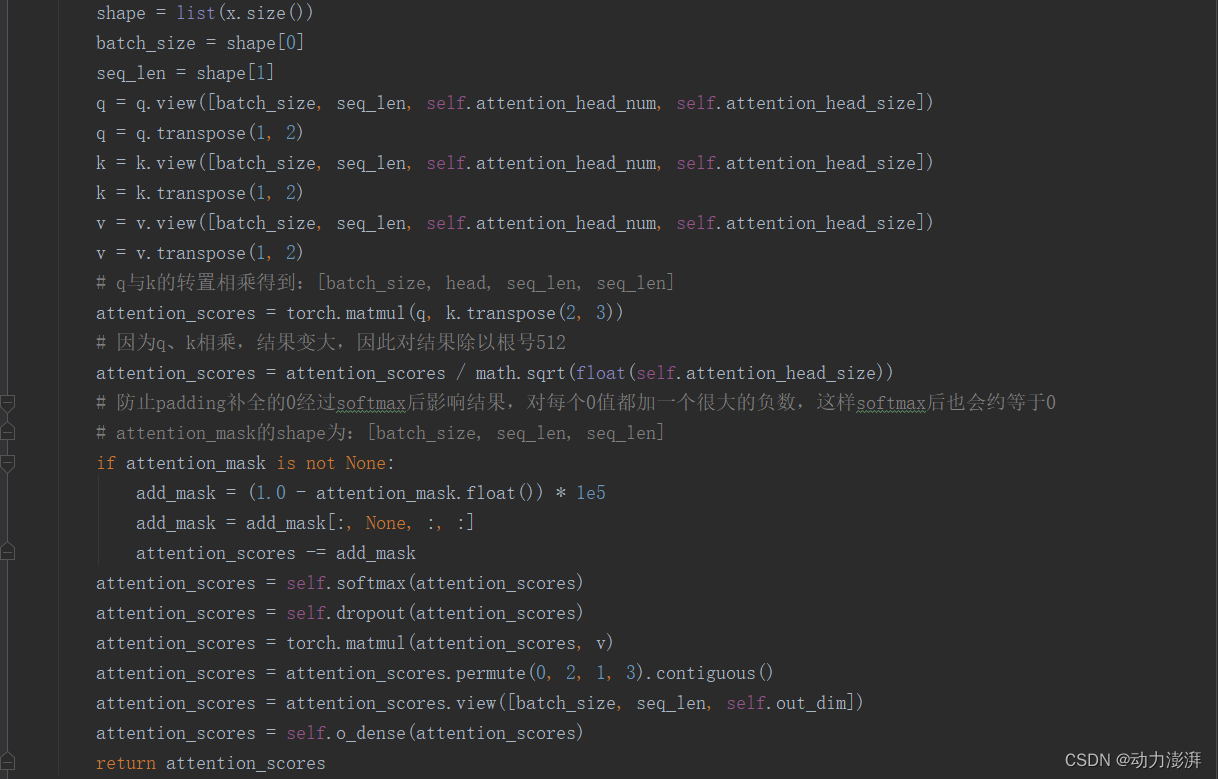
自注意力模块MultiHeadSelfAttention()实现:
FeedForward()模块实现:
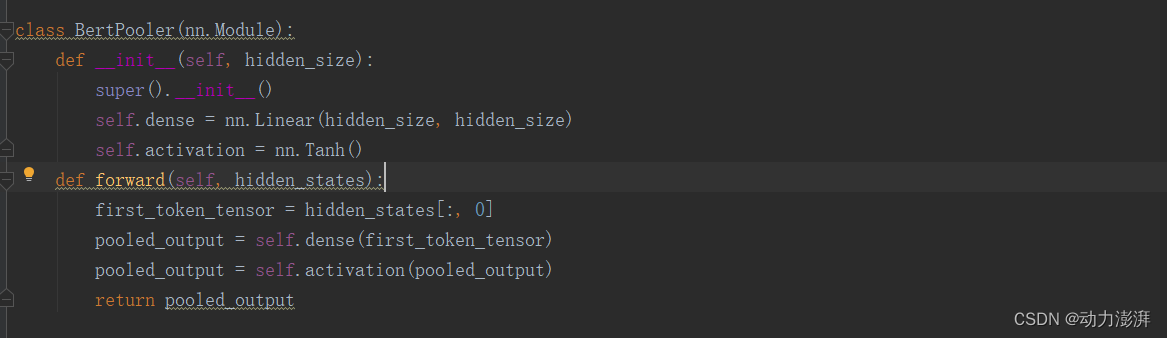
定义BertPooler模块
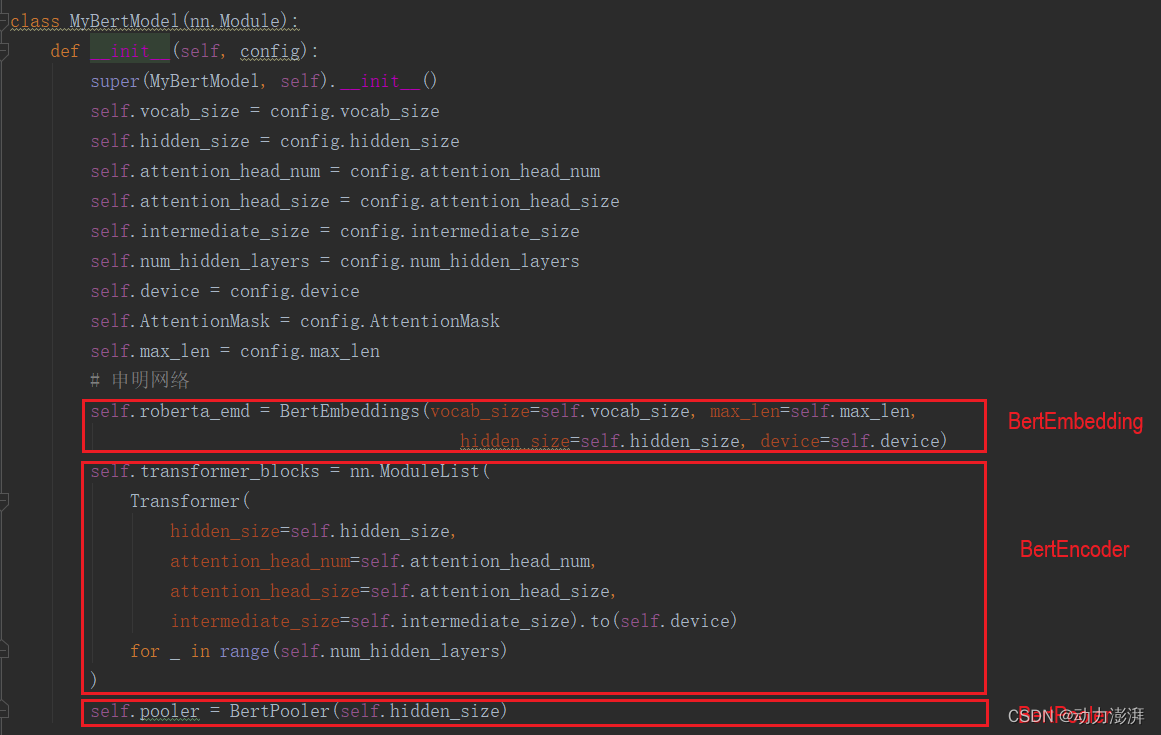
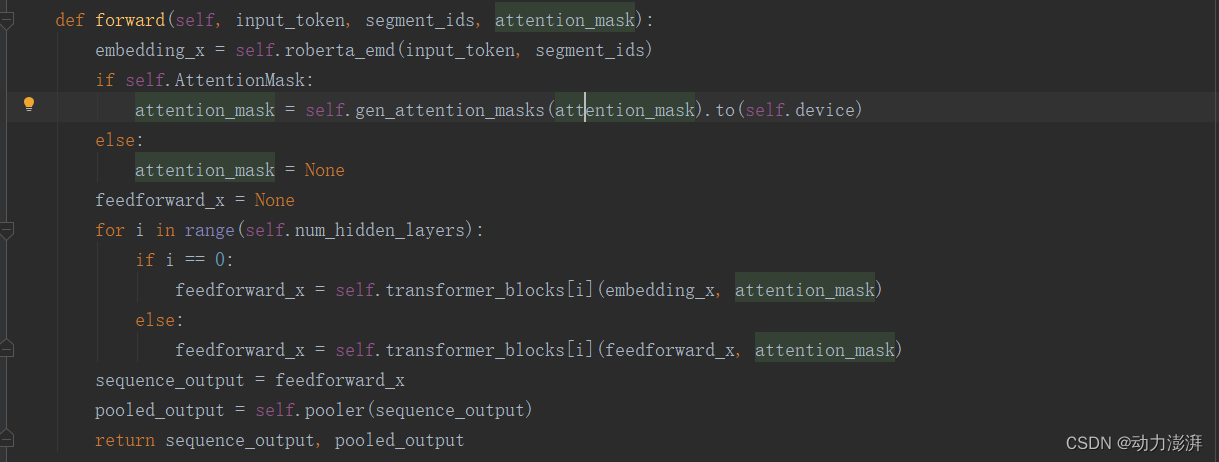
2.搭建Bert模型
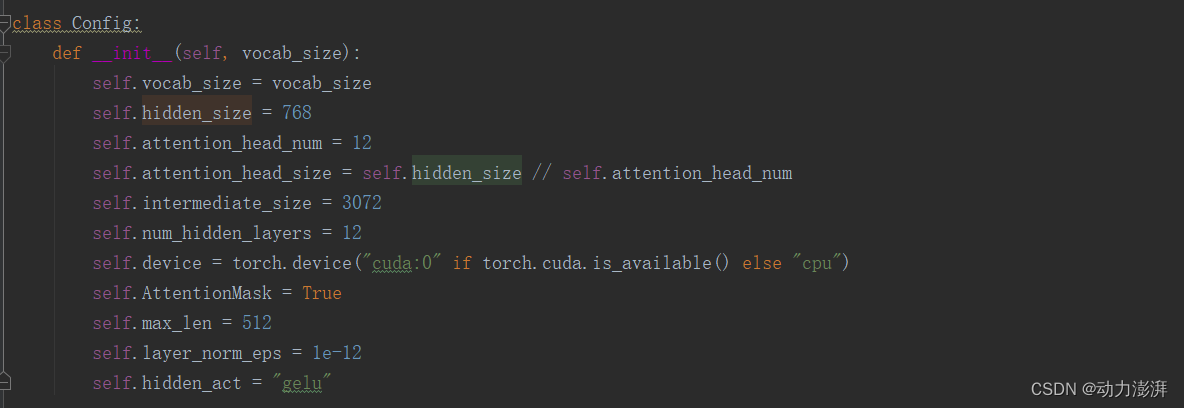
在各子模块的基础上搭建Bert模型,Bert模型的结构参考HuggingFace的BERT结构。主要包括BertEmbedding、BertEncoder和BertPooler三部分。其中BertEncoder是由多个Transformer层堆叠而成,实验中参考了HuggingFace的bert_base_uncased预训练模型的结构参数,总共包含了12层Transformer。模型的其他参数也参考了HuggingFace的bert_base_uncased预训练模型的结构参数。vocab_size为bert_base_uncased预训练模型的字典大小,hidden_size为768,attention_head_num为12,intermediate_size为3072,hidden_act与论文中保持一致使用gelu。
3.Bert模型参数配置接口
Bert模型的参数配置接口和初始化参数
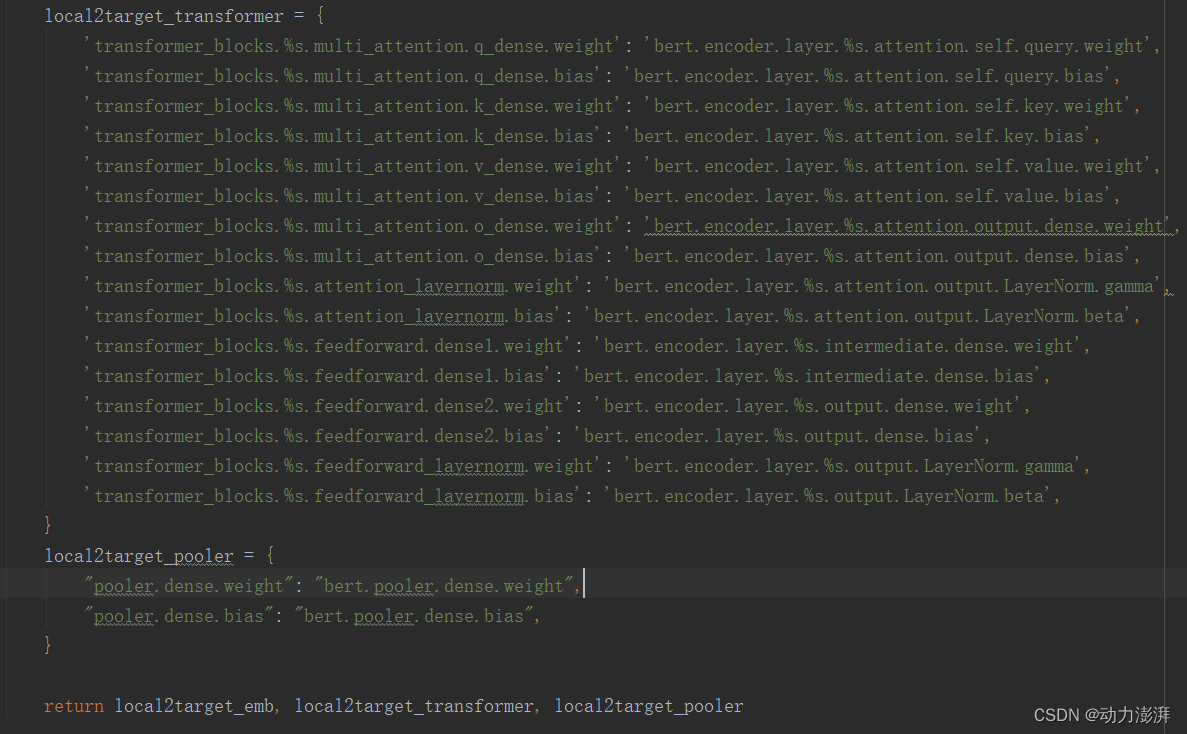
4.定义参数映射关系
由于自己搭建的Bert模型和huggingface上预训练的Bert模型的参数名字不一致,因此需要定义两者间的映射关系,从而实现从预训练模型自动加载对应参数。定义自己搭建的Bert模型和huggingface上预训练的Bert模型的参数映射关系如下:

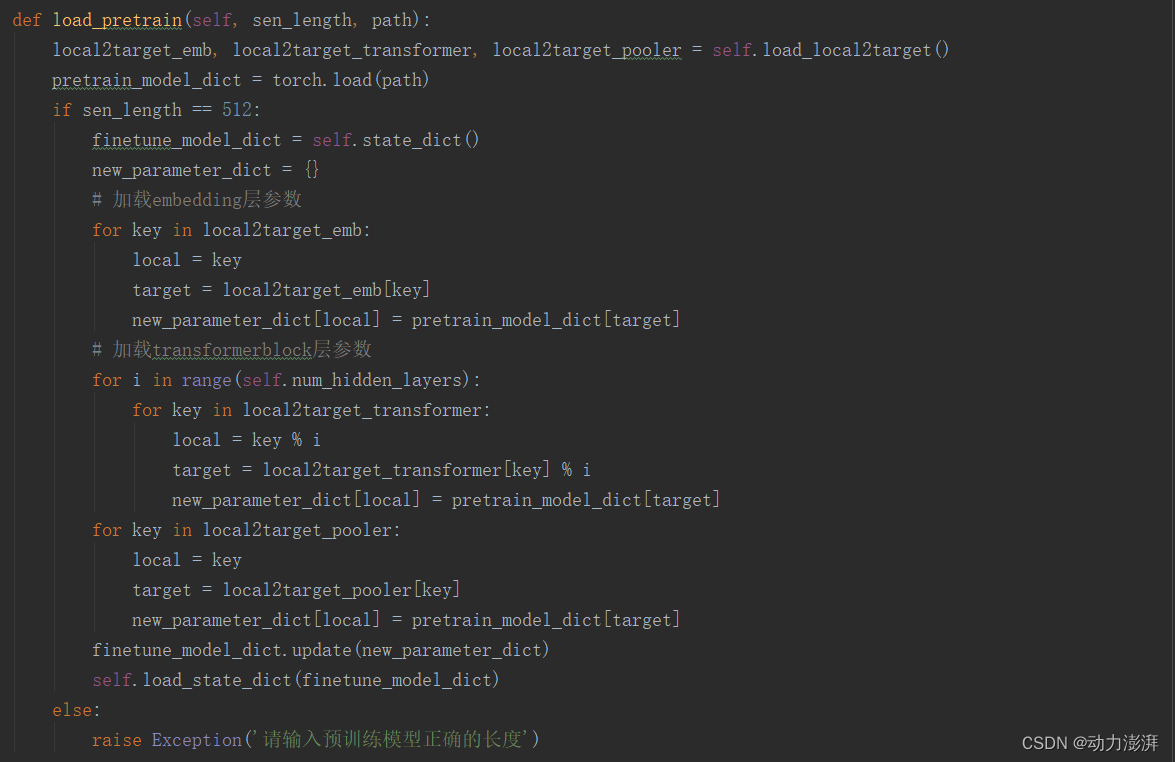
5.定义加载huggingface上预训练的Bert模型参数的方法
定义加载huggingface上预训练的Bert模型的参数到本地Bert模型的方法。
至此,完成了Bert模型的手动实现、通过自定义接口实现预训练参数的加载,至于如何在IMDB数据集上实现模型的微调训练可以参考本博客的另一篇文章——文本情感分类模型之BERT。


















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











