




Brijen Thananjeyan等
摘要
(1)在策略学习之前利用离线数据来学习违反约束的区域
(2)在两个策略中分离提高任务性能和约束满意度的目标:一个任务策略只优化任务奖励,一个恢复策略在可能违反约束时引导代理安全。
(3)我们在6个模拟领域中评估了Recovery RL,包括两个富接触操作任务和一个基于图像的导航任务,以及一个基于图像的物理机器人避障任务。我们将恢复RL与5种先前的安全RL方法进行比较,这些方法通过约束优化或奖励塑造共同优化任务性能和安全性,并发现恢复RL在所有领域都优于次优先验方法。结果表明,恢复强化学习在模拟领域的效率是2-20倍,在物理实验领域的效率是3倍。
目标
增大强化学习训练过程中的安全性
即在确保安全的前提下让智能体尽量提高完成任务的效率。
算法创新点
1.将重置策略改为恢复策略(在可能违反约束时重置到附近的安全状态而无需reset)
2.训练两个策略:
任务策略侧重于优化无约束任务目标;
恢复策略在任务策略近期有违反约束的危险时进行控制
问题设定
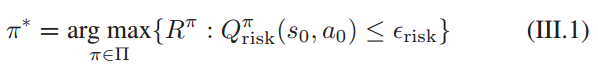
在满足约束的条件下,找到最优的策略
算法介绍
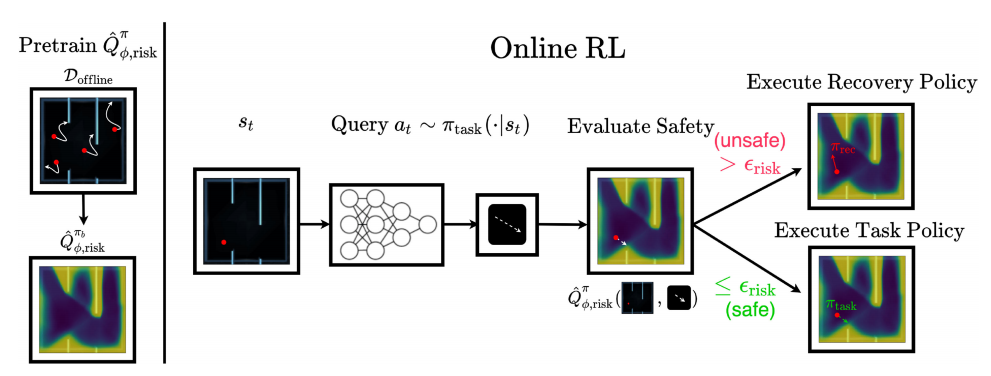
以迷宫任务为例,约束是不能撞上墙,算法训练过程如下:
1.使用离线数据集预
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1848
1848




 到【灌水乐园】发言
到【灌水乐园】发言







