



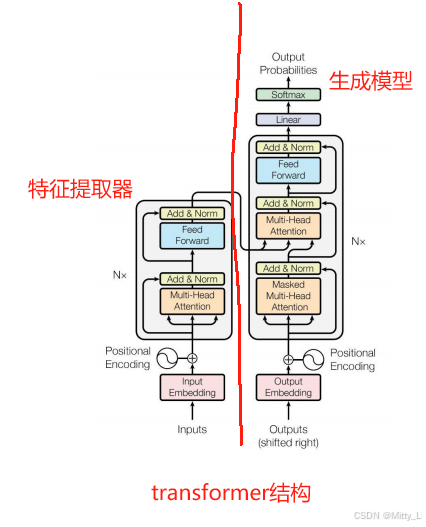
RNN模型: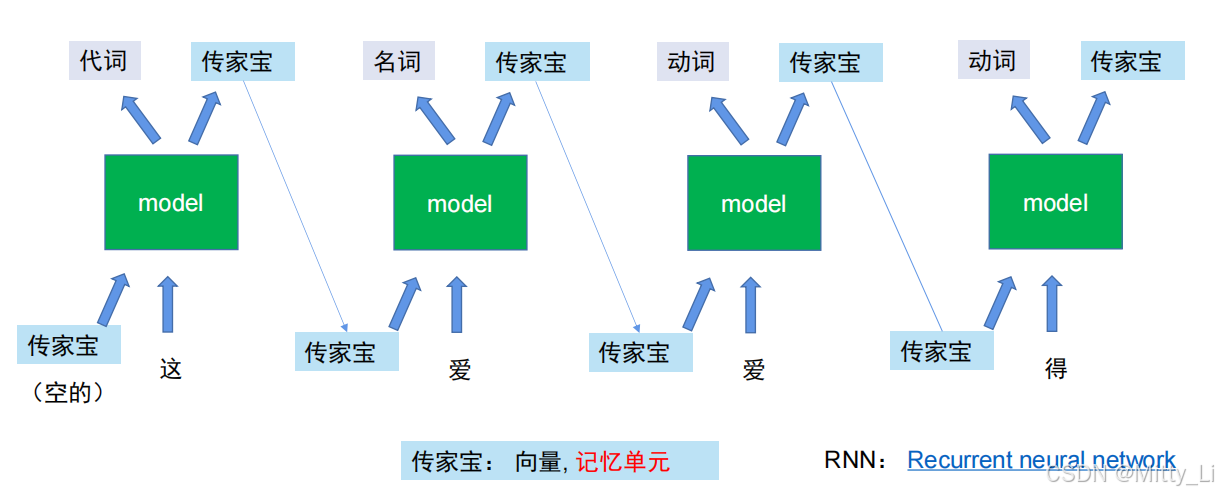
通过记忆单元(可理解为传家宝)去改变模型的输入 ,这样模型的输出也会改变,每次模型输入一个字的时候,会一起输入由上一个字传下来的记忆单元(可理解为传家宝),这样一直迭代下去。
这里会体现出一个问题:即若一段话你需要的词距离太远,那每个字都需要传家宝的话,极容易出现不肖子孙(即记忆单元里面存储了错误的信息)
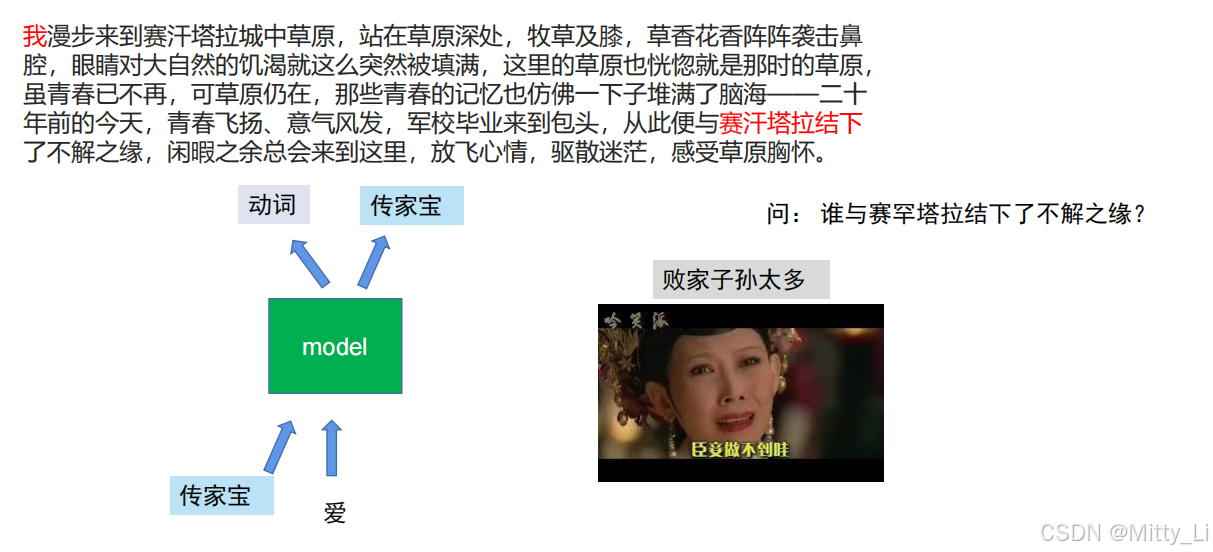
那对于那些不肖子孙,我们可以采用LSTM方法,对其进行上锁,不让你进入模型,对于上图的例子,我们就可以在我和赛罕塔拉中间所有的内容都进行上锁
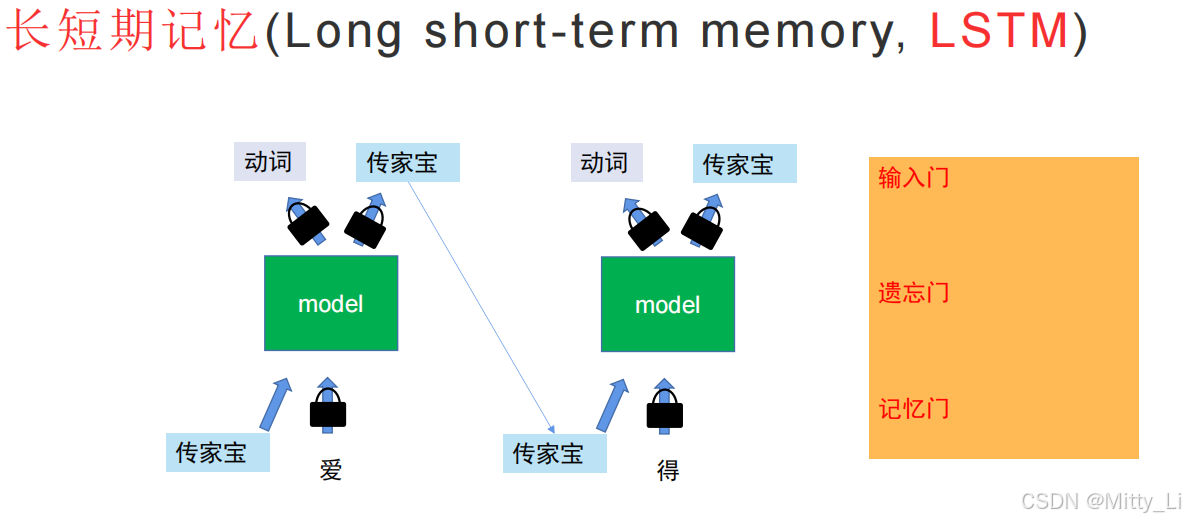
但这样又出现了一个问题,速度太慢了! 只能一个一个字去输入和输出,所以为了解决这个问题,引入了自注意力机制。
自注意力机制是一个特征转换器,我们假设每个字都是768维的向量
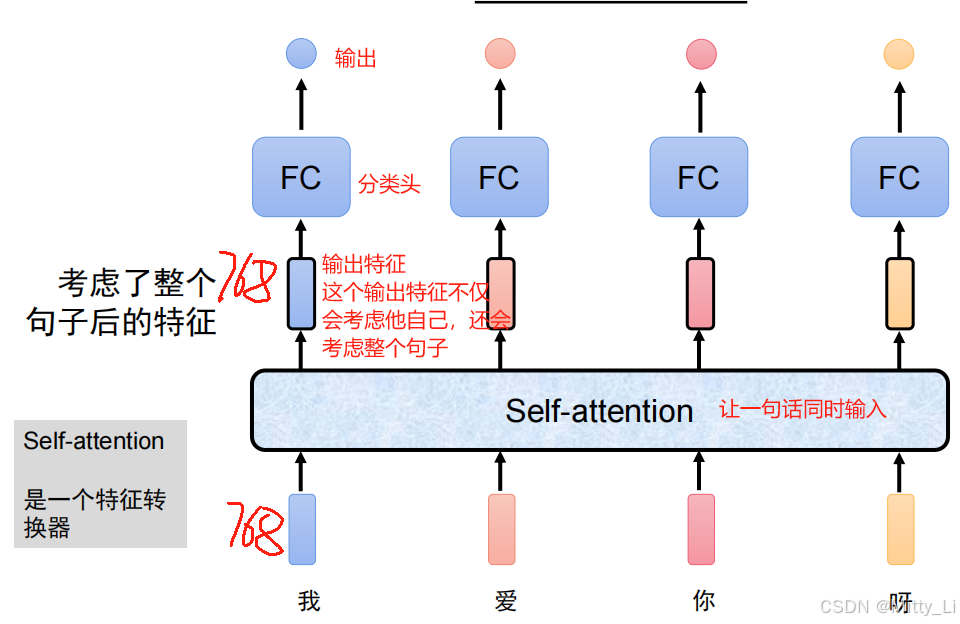
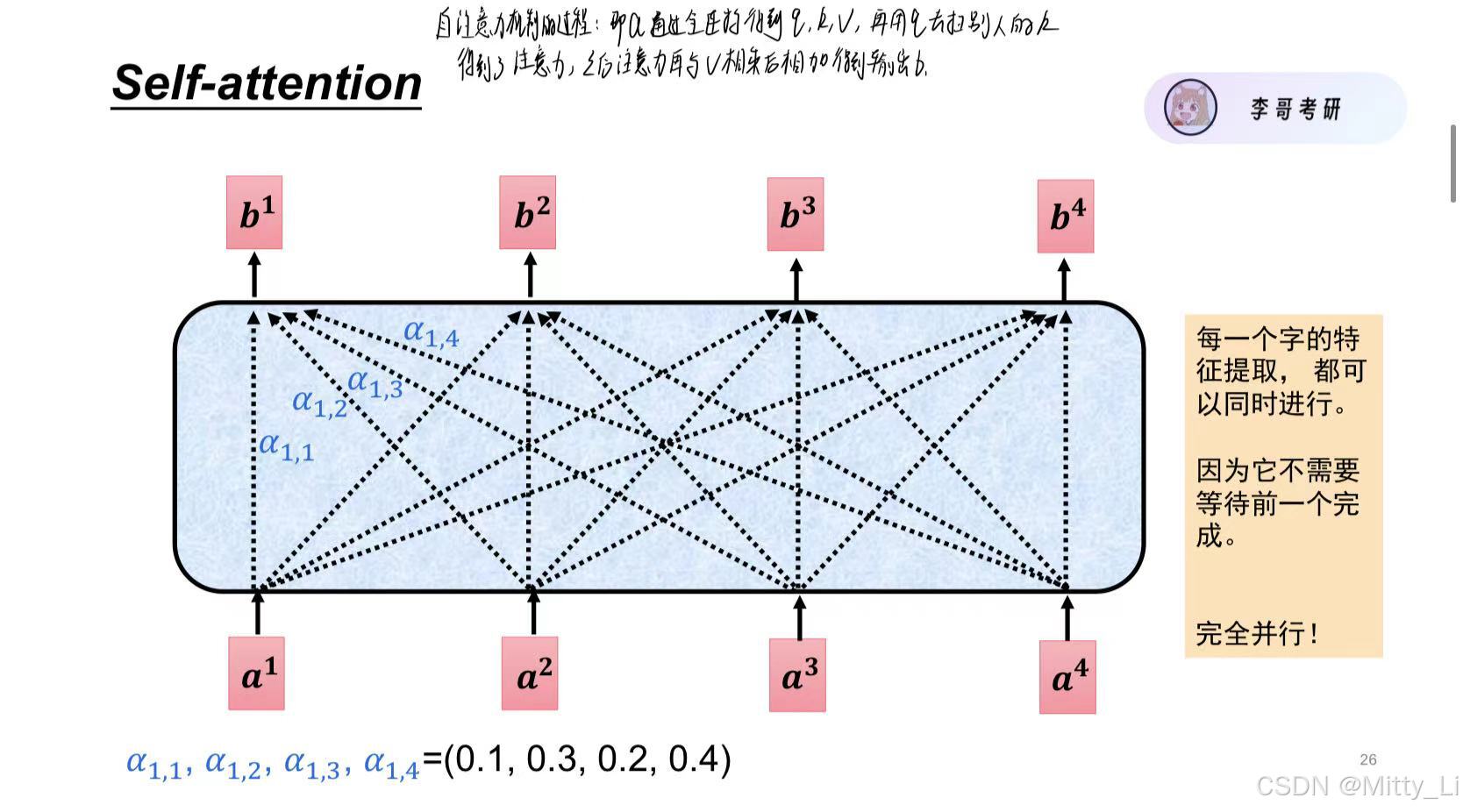
什么是注意力?--即给某件事分配多大的精力,需要注意,注意力要为1
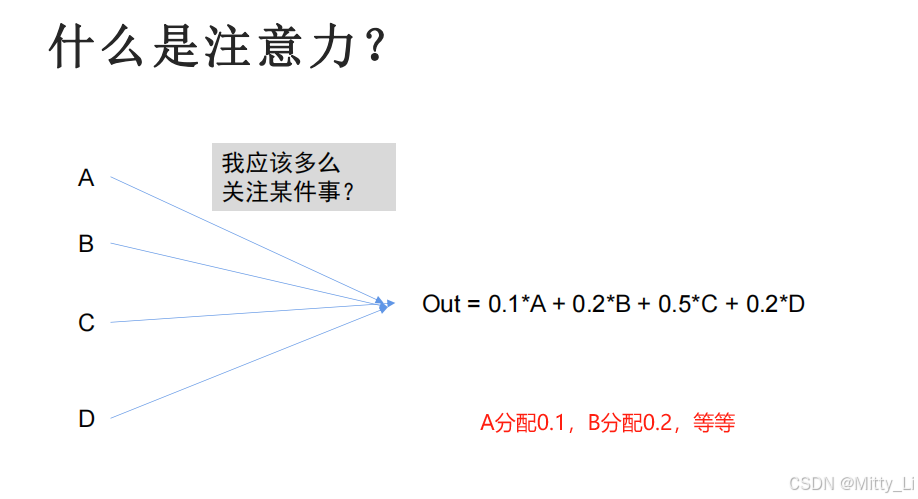
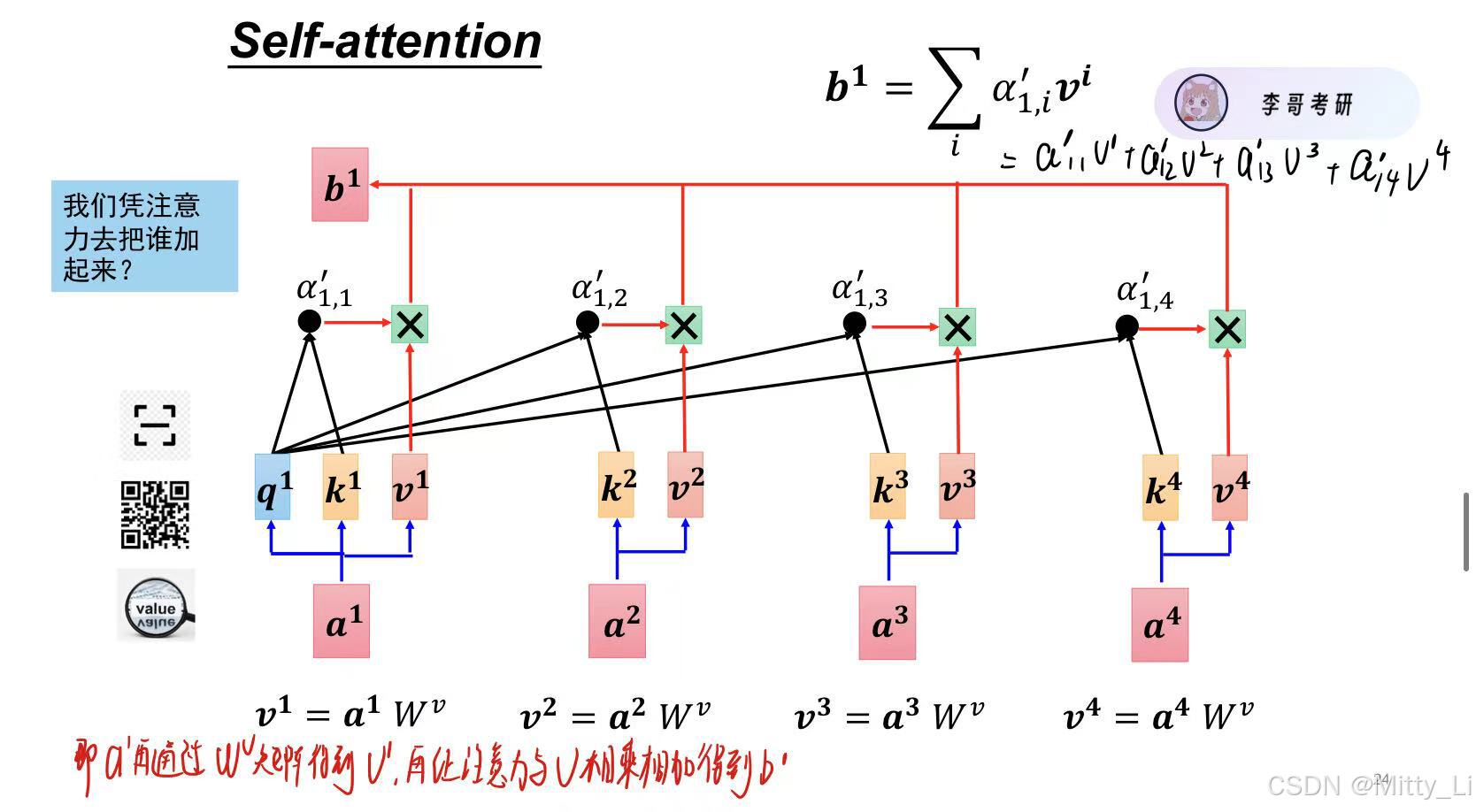
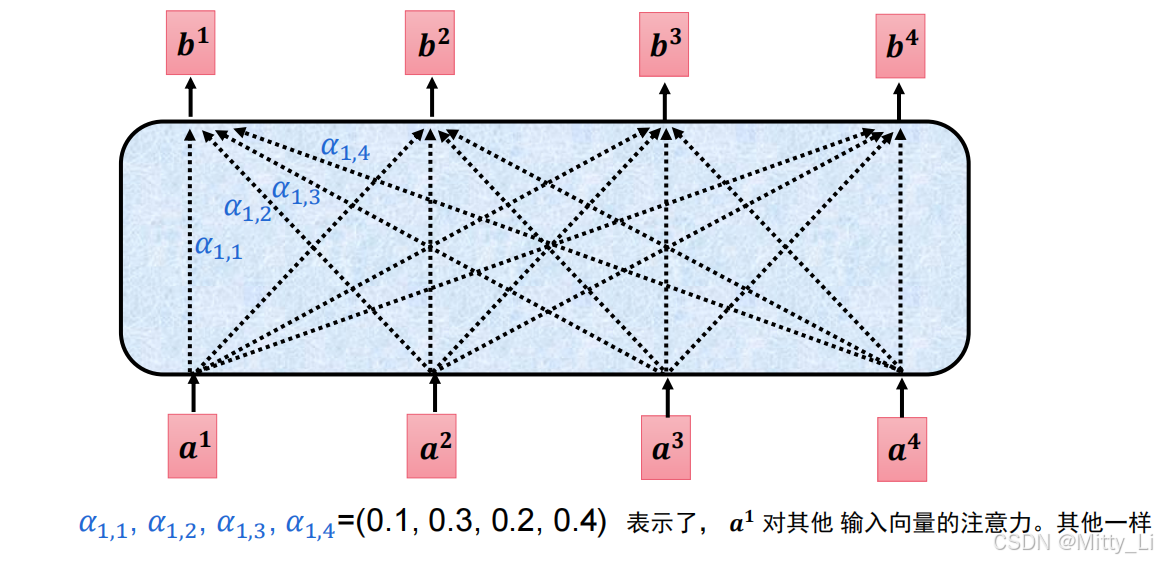 b1是由a1--a4由他们和各自的注意力相乘和相加得到的,b2,b3同理。
b1是由a1--a4由他们和各自的注意力相乘和相加得到的,b2,b3同理。
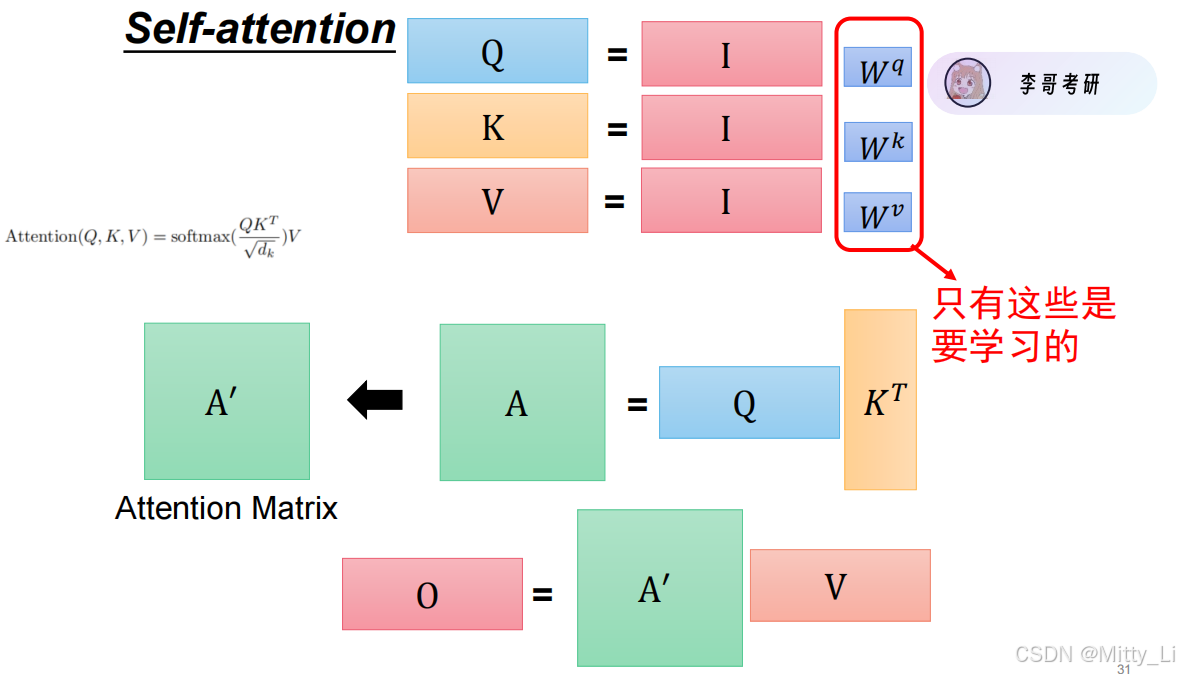
如何计算注意力?
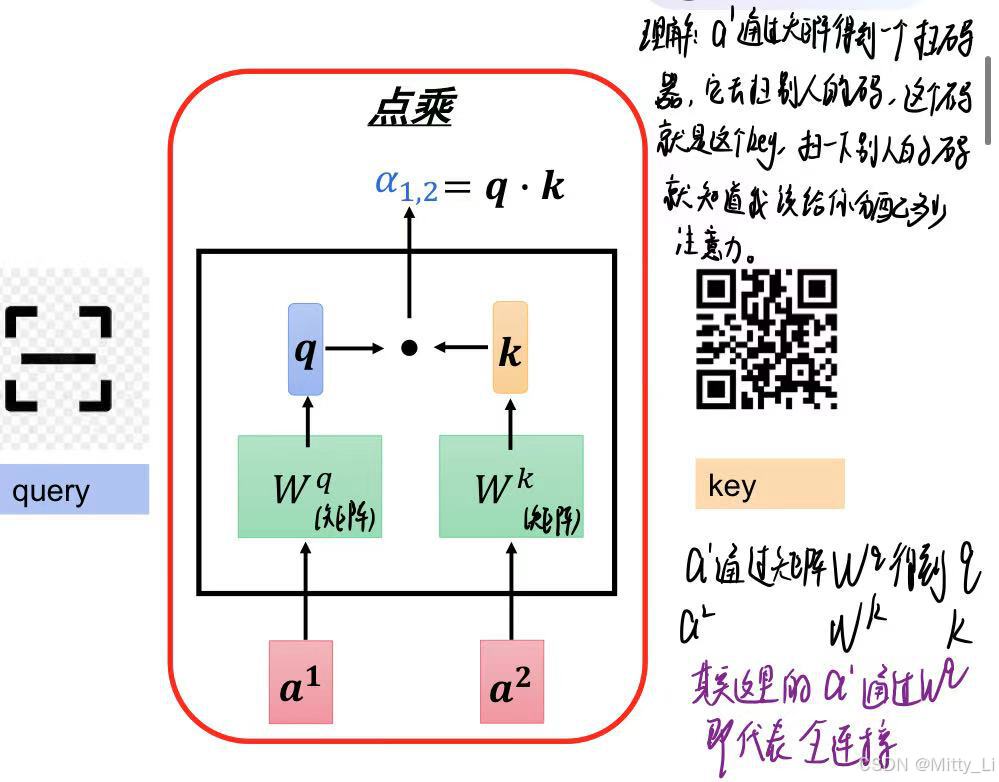
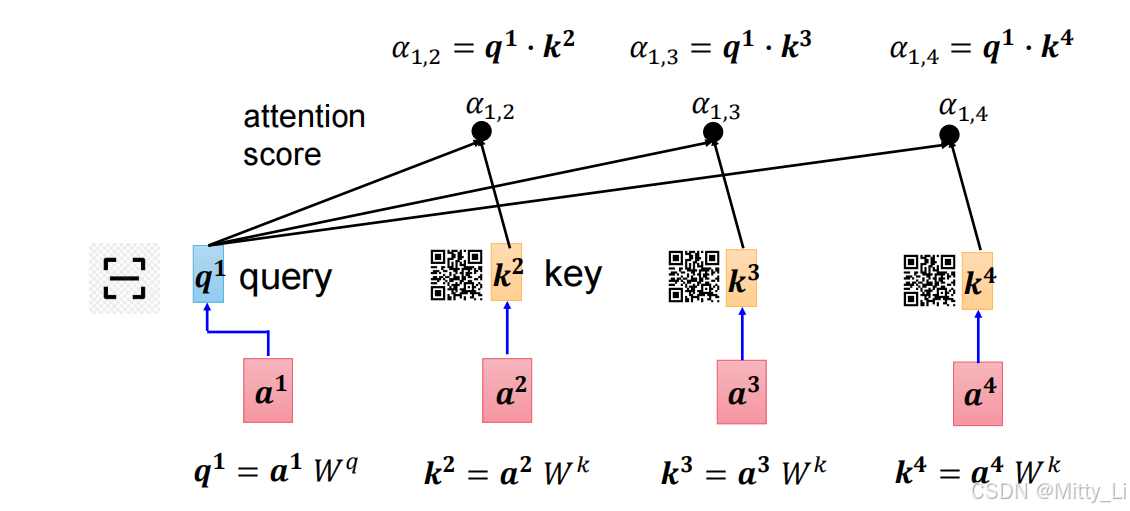
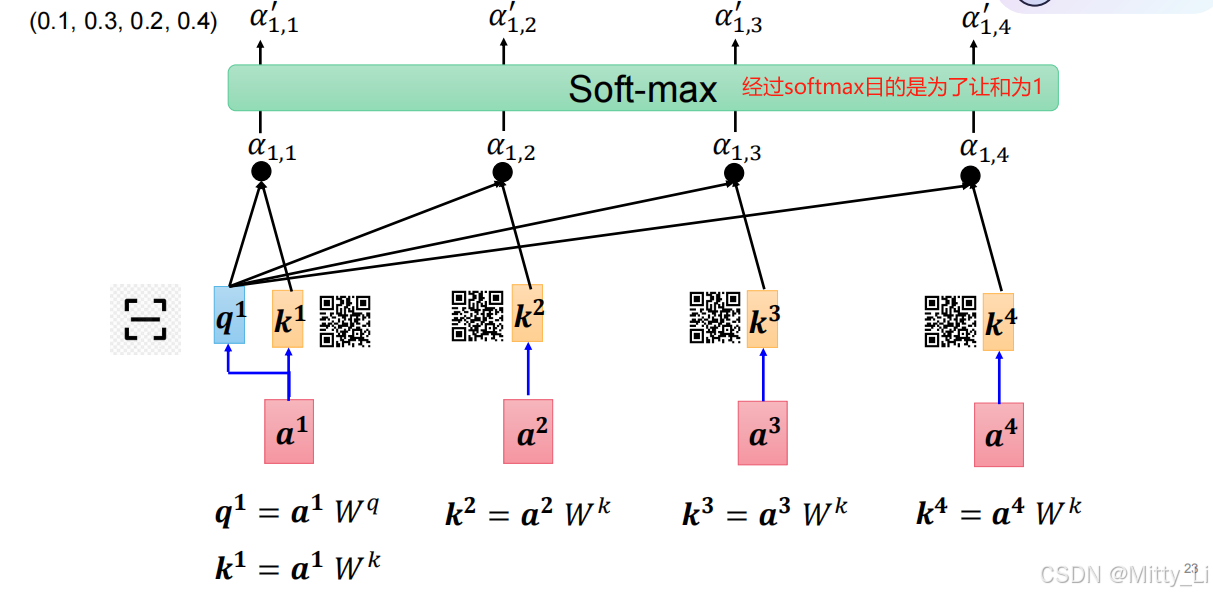
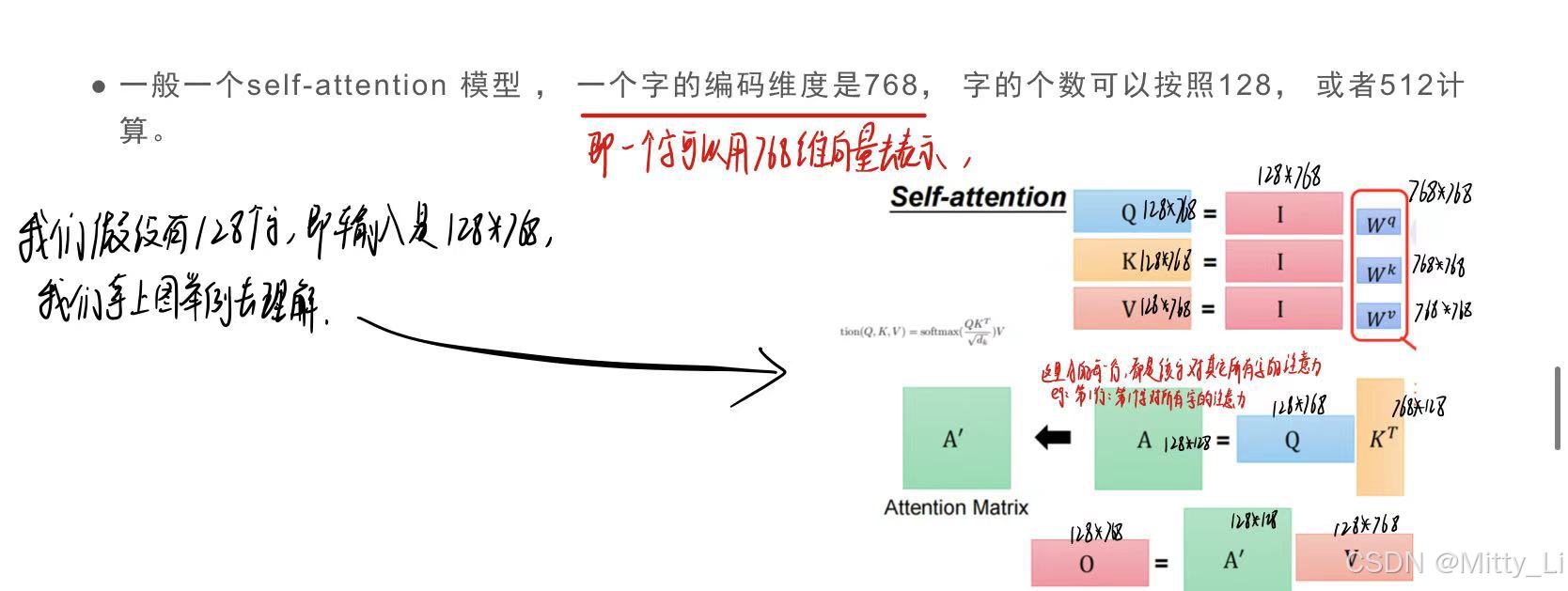 可以看到输入为128*768,输出的时候还是128*768,即它的维度没有改变
可以看到输入为128*768,输出的时候还是128*768,即它的维度没有改变
自此自注意力机制流程走完。
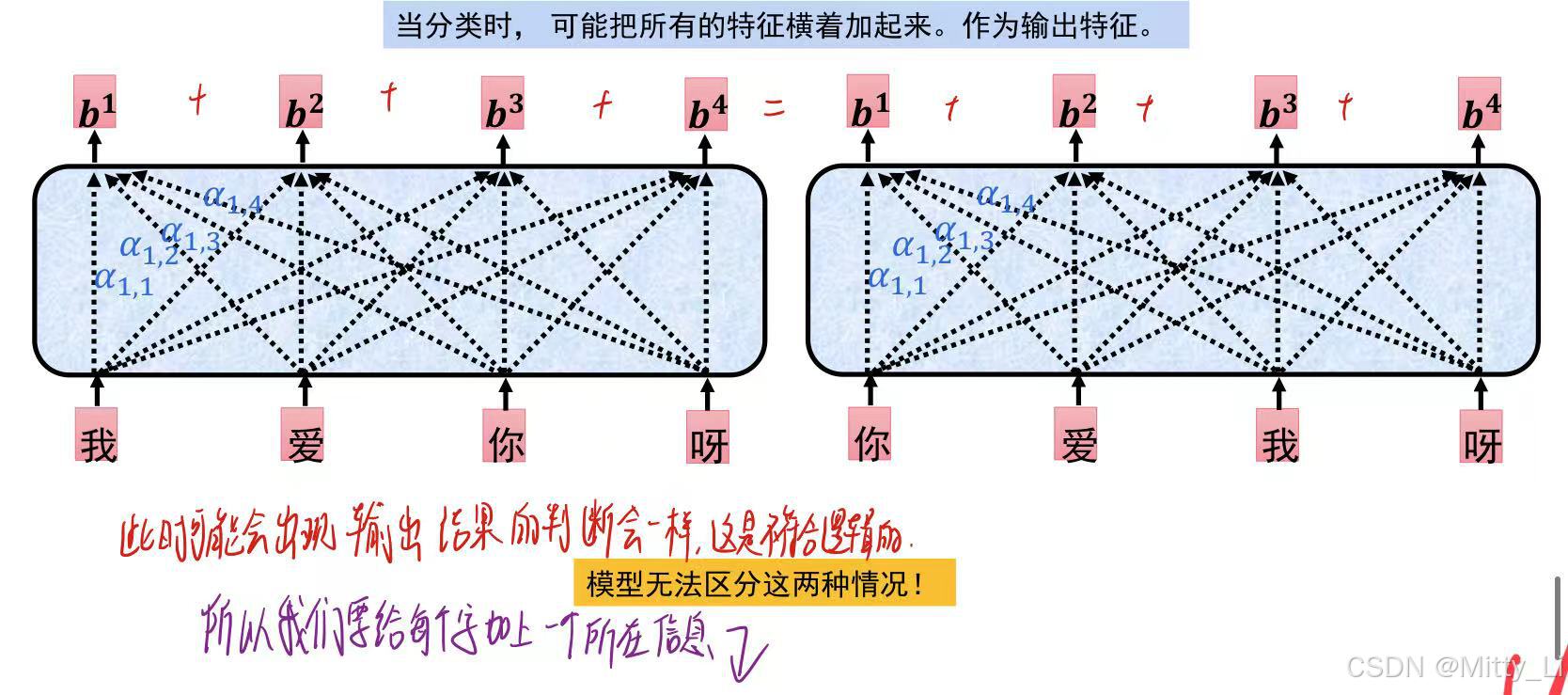
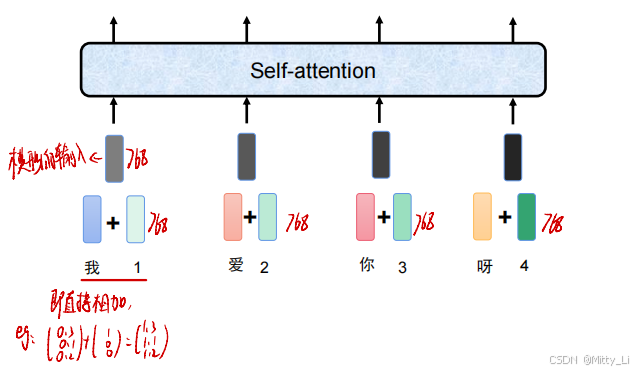
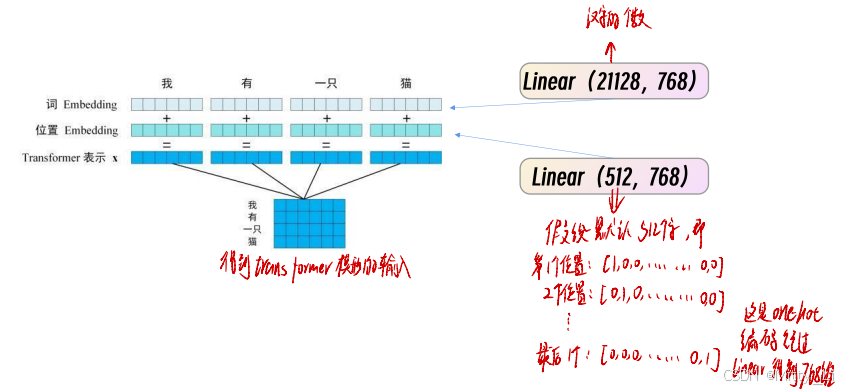
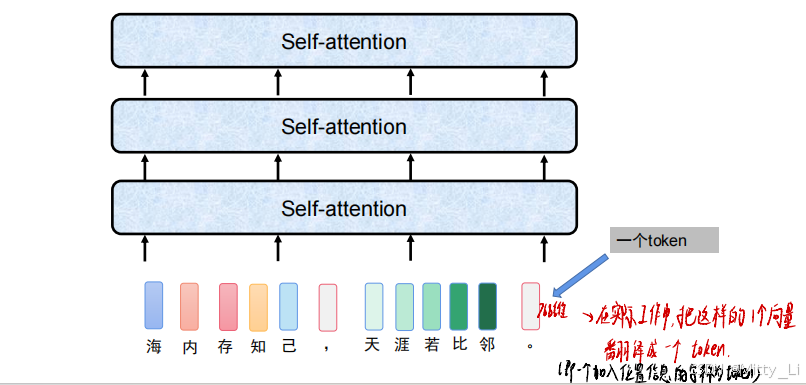
引入位置信息:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









