






1.对于深度学习训练过程的概括:
[数据] → [预处理] → [模型] → [前向传播] → [损失计算]
↑ ↓
← [反向传播 ← 参数更新] ←
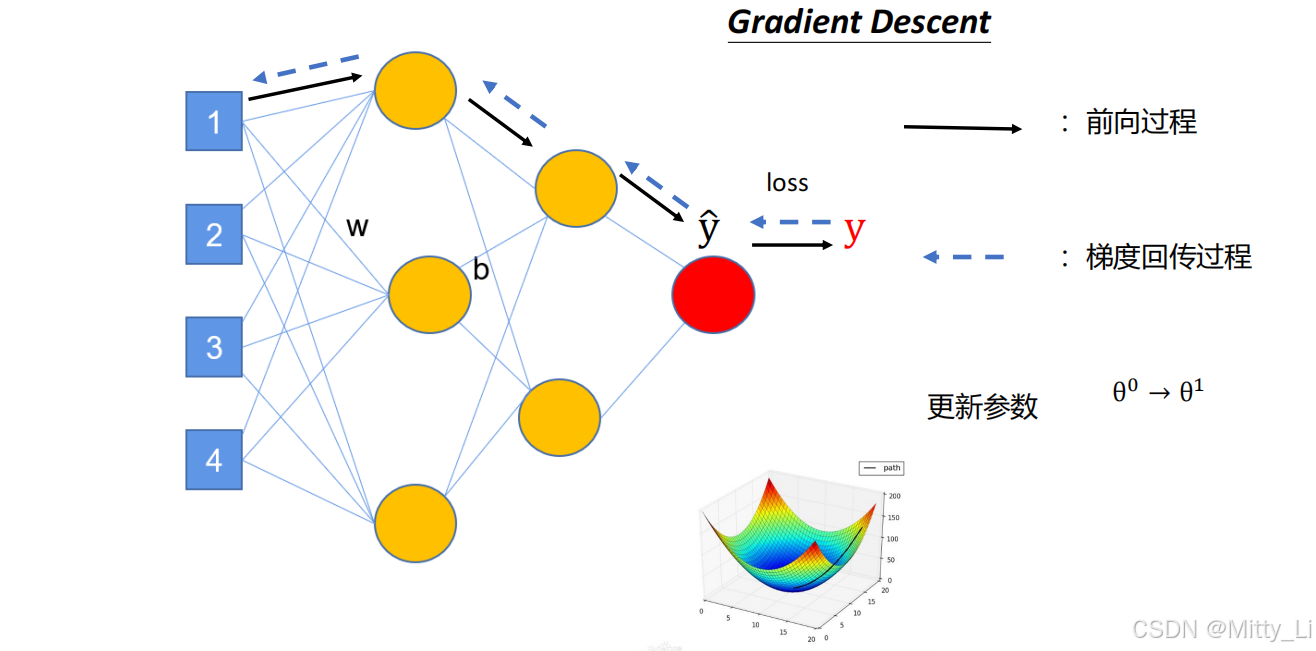
首先对于数据进行简单的预处理,选择模型(也就是函数f()),通过一次前向传播得到了预测值,在通过损失函数去计算预测值和我们真实值的差距,即计算误差,进行反向传播(中间会使用到梯度下降进行调整)修改,更新参数,反复去执行最后得到结果,直到损失值逐渐接近0。
以下是代码实现(参考来源于四川大学李哥教程):
1.创建数据,并预处理
import torch
import matplotlib.pyplot as plt # 画图的
import random #随机
def create_data(w, b, data_num): #生成数据
x = torch.normal(0, 1, (data_num, len(w))) #生成一个服从正态分布的随机张量,用于模拟输入特征数据
# 均值0:数据围绕什么值分布(钟形顶点的位置)
# 方差1:数据分散还是集中(钟形的宽窄程度)
# 靶心是均值(这里是0)
# 方差为1表示:你扔的大多数飞镖会落在距离靶心1米内(约68 % 的数据在 - 1到 + 1之间)
# 少数飞镖会落在 1 ~2 米内(约95 % 的数据在 - 2 到 + 2之间)
# 几乎不会超出 3 米外(99.7 % 的数据在 - 3 到 + 3之间)
# 形状:data_num, len(w)
y = torch.matmul(x, w) + b #matmul表示矩阵相乘 (线性表示)
noise = torch.normal(0, 0.01, y.shape) #噪声要加到y上,所以维度要和y一样(进行预处理)
y += noise #噪声加到y上面
#目的:模拟现实数据的不完美性+防止模型过拟合
return x, y
num = 500
true_w = torch.tensor([8.1,2,2,4]) #真实权重
true_b = torch.tensor(1.1) #真实偏置
#相当于老师出卷子,这两个是标准答案,我们要用这两个东西去生成考题(数据)
X, Y = create_data(true_w, true_b, num) #X为500*4的矩阵,Y为500*1的一维向量
plt.scatter(X[:, 0], Y, 1) # 可视化:绘制第 1个特征(X[:,3])与 Y 的关系,观察线性趋势
#plt.scatter :Matplottlib 中绘制散点图的函数
X[:, 0]:表示提取所有样本的第1个特征(Python 索引从 0 开始)
Y:目标值向量,在这里是线性变化后的值,在这里Y是y+=noise
1:图片中点的大小,100就会显示特别大
plt.show() #弹出一个窗口显示绘制好的图表。如果不调用此函数,图表不会自动展示
def data_provider(data, label, batchsize): #定义一个生成器函数,用于按批次提供随机打乱的数据。
# data:输入特征数据(如形状为(500, 4)的矩阵)。
# label:目标值数据(如形状为(500,)的向量)
# batchsize:每个批次包含的样本数量(如16)
length = len(label) #通过标签数量确定数据集的总样本数。若label有 500 个元素,则length = 500
indices = list(range(length)) #创建一个从0到length-1的索引列表
random.shuffle(indices) #我不能按顺序取 把索引随机打乱
for each in range(0, length, batchsize): #作用:以 batchsize 为步长,遍历所有样本。
#示例:若 length=500,batchsize=16,则循环次数为 500/16 ≈ 31 次(最后一次可能不足 16 个样本)。
get_indices = indices[each: each+batchsize]
# 截取当前批次的索引范围,他是一个列表。 就是X这个矩阵每一行的序号,每一行有四个数据
# 若 batchsize=16,则 get_indices 可能为 [35, 12, 478, ..., 123](共16个随机打乱的索引值)。
# 根据索引提取对应批次的数据和标签。
get_data = data[get_indices] #data是形状为(500, 4)的矩阵,比如说取[35, 12, 478, ..., 123](共16个随机打乱的索引值)对应的样本特征
 get_label = label[get_indices] #label形状为(500,)的向量,即取tensor([5.0, -3.2, 6.1, ...]) # 索引35、12等对应样本的目标值
get_label = label[get_indices] #label形状为(500,)的向量,即取tensor([5.0, -3.2, 6.1, ...]) # 索引35、12等对应样本的目标值

 yield get_data,get_label #有存档点的return,返回当前批次的数据和标签,并暂停函数执行,下次调用时继续从当前位置运行。
#对比 return:普通 return 会终止函数,而 yield 保留函数状态。
batchsize = 16 # 定义每个批次包含 16 个样本
yield get_data,get_label #有存档点的return,返回当前批次的数据和标签,并暂停函数执行,下次调用时继续从当前位置运行。
#对比 return:普通 return 会终止函数,而 yield 保留函数状态。
batchsize = 16 # 定义每个批次包含 16 个样本
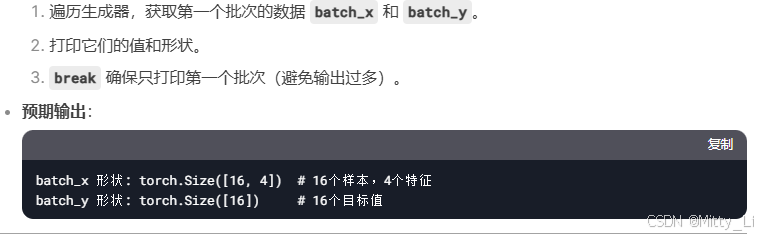
#下面for的作用:测试生成器是否能正确输出第一个批次的数据。
for batch_x, batch_y in data_provider(X, Y, batchsize):
# X和Y是特征矩阵和Y,一个是(500, 4),表示 500 个样本,每个样本有 4 个特征。
# 一个是(500,),表示 500 个样本的目标值。
print(batch_x, batch_y)
break
前向传播+后向传播更新参数
def fun(x, w, b): #前向传播函数,最简单的线性回归公式
pred_y = torch.matmul(x, w) + b #线性回归公式算出来的预测值,付给pred_y
#若 x 的形状为 (batch_size, num_features),w 为 (num_features,),
# 则 pred_y 的形状为 (batch_size,)(每个样本对应一个预测值)。
return pred_y
def maeLoss(pre_y, y): #损失函数
return torch.sum(abs(pre_y-y))/len(y)
def sgd(paras, lr): # 优化器 sgd(随机梯度下降)
#paras 是包含所有待优化参数的 列表(如 [w_0, b_0])等等,是全部参数
with torch.no_grad(): #属于这句代码的部分,不计算梯度,禁止梯度计算,避免更新操作被记录到计算图中
for para in paras: #在 sgd 函数中,para 是 paras 列表中的单个参数(如 w_0 或 b_0),即从paras中每次取一次
para -= para.grad * lr #不能写成 para = para - para.grad*lr,参数沿负梯度方向更新
para.grad.zero_() #使用过的梯度,归0
#参数初始化,初始化模型参数,为训练做准备。
#:权重,从均值为 0、标准差为 0.01 的正态分布中随机采样,形状与 true_w 一致(如 (4,))。
#b_0:偏置,固定初始化为 0.01。
#requires_grad=True:允许自动计算梯度(反向传播时更新参数)
lr = 0.03#学习率
w_0 = torch.normal(0, 0.01, true_w.shape, requires_grad=True)
#这个w需要计算梯度,requires_grad=True:标记该参数需要计算梯度,后续可通过反向传播更新。
#为模型提供初始权重(接近0的小随机值),打破对称性,避免所有参数初始化为相同值导致训练失败,
#w_0 是一个四维张量,其具体数值每次运行都会随机生成,但数值范围大致在 [-0.03, +0.03] 之间。
b_0 = torch.tensor(0.01, requires_grad=True)
#初始化模型的偏置参数 b_0。
#即随机给个值,去得到正确的值
print(w_0, b_0) #打印随机生成的初始值
#----------------------------------------------------------------------------------------------------------------------
# 小批量梯度下降优化线性回归模型
#这段代码实现了线性回归模型的训练过程,通过多次迭代(epoch)优化模型参数(w_0 和 b_0),使其逼近真实值(true_w 和 true_b)
epochs = 50 #作用:定义训练的总轮次(整个数据集遍历50次)。
for epoch in range(epochs): #训练循环(外层循环)
data_loss = 0 #每轮训练开始时,重置累计损失为 0。
for batch_x, batch_y in data_provider(X, Y, batchsize): # 小批量训练(内层循环);从数据生成器 data_provider 中逐批获取数据和标签。
#内层循环遍历数据集的小批量(每批16个样本)。
pred_y = fun(batch_x,w_0, b_0) # 计算预测值,即前向传播,用当前参数 w_0 和 b_0 计算预测值。 81和83行代码
loss = maeLoss(pred_y, batch_y) # 计算平均绝对误差损失
loss.backward() # 计算梯度(反向传播) 自动计算 loss 对 w_0 和 b_0 的梯度,填充 w_0.grad 和 b_0.grad。
sgd([w_0, b_0], lr) # 更新参数并清零梯度
data_loss += loss #将当前批次的损失值累加到 data_loss
# 前向传播:用当前参数w_0和b_0计算预测值pred_y(公式:pred_y = X @ w_0 + b_0)。
# 损失计算:计算预测值与真实值的平均绝对误差(MAE)。
# 反向传播:自动计算loss对w_0和b_0的梯度(即w_0.grad和b_0.grad)。
# 参数更新:通过sgd函数沿负梯度方向更新参数,并清零梯度。
# 损失累计:将当前批次的损失累加到data_loss,用于监控训练进度。
print("epoch:%03d loss: %.6f"%(epoch, data_loss)) #%03d:用 3 位数字显示轮数(如 049)。 %.6f:用 6 位小数显示损失值。
print("真实的函数值是", true_w, true_b)
print("训练得到的参数值是", w_0, b_0)
#----------------------------------------------------------------------------------------------------------------------
#这段代码的功能是可视化线性回归模型在特定特征上的拟合效果
idx = 3 #若 idx=3,表示选择第 4 个特征(即 X 的第 4 列),因为单独得打印X得话,他有4列,在二维图上显示不了,只能选择某一列来
plt.plot(X[:, idx].detach().numpy(), X[:, idx].detach().numpy()*w_0[idx].detach().numpy()+b_0.detach().numpy())
#获取所有样本的第 idx 个特征值,转换为 NumPy 数组,
# .detach().numpy() 因为张量不能画图,将PyTorch张量从计算图中分离,并转换为NumPy数组,以便Matplotlib绘图。
# 必须操作,因为张量包含梯度信息,直接绘图会报错。
#根据训练后的权重 w_0 和偏置 b_0,绘制该特征与预测值的线性关系(直线)。
plt.scatter(X[:, idx], Y, 1)
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









