



基于 COVID-19 数据集的回归任务模型,目标是预测 tested_positive(阳性检测结果值)
整体流程:数据预处理--》模型定义--》训练与验证--》测试与结果生成
优化点:
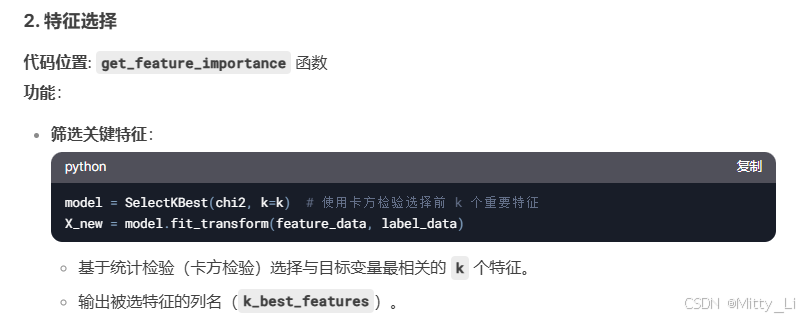
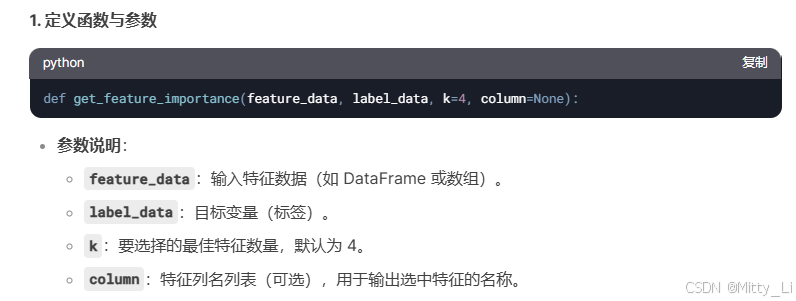
- 特征选择:通过
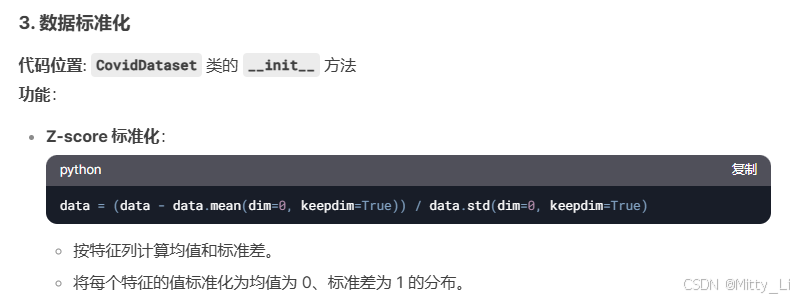
SelectKBest筛选高相关性特征,提升模型效率 - 正则化:在损失函数中加入 L2 正则项(参数平方和),抑制过拟合
训练流程:
-
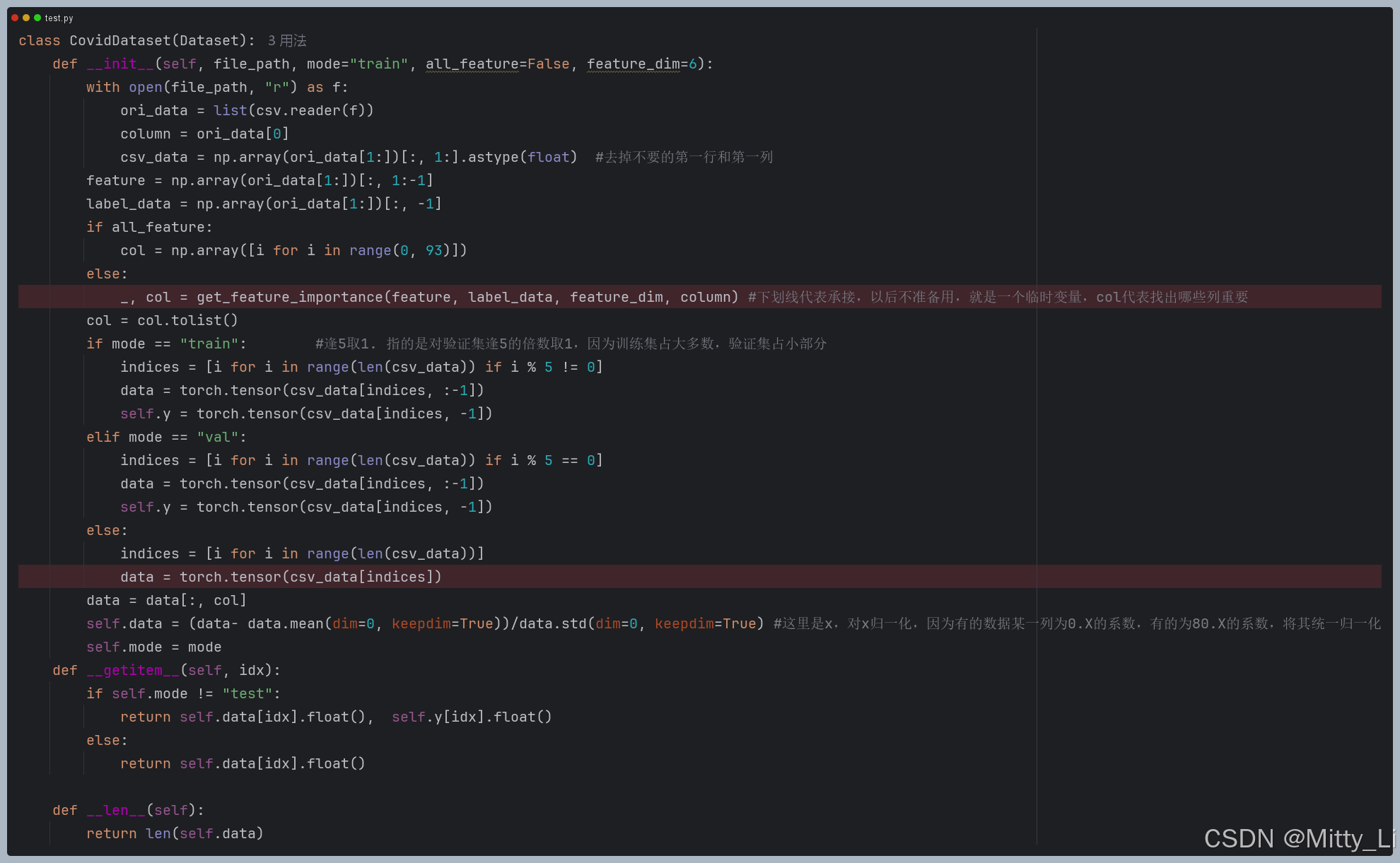
数据加载
-
从
covid.train.csv和covid.test.csv加载数据。 -
根据
all_feature标志选择是否使用全部特征。
-
-
模型训练
-
训练 20 个 epoch,批量大小设为 16。
-
监控训练和验证损失,保存最佳模型至
model_save/best_model.pth。
-
-
测试预测
-
加载最佳模型,生成测试结果文件
pred.csv
-
一.数据预处理
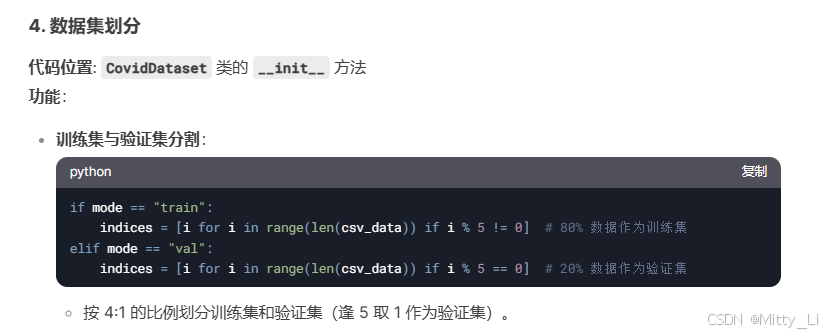
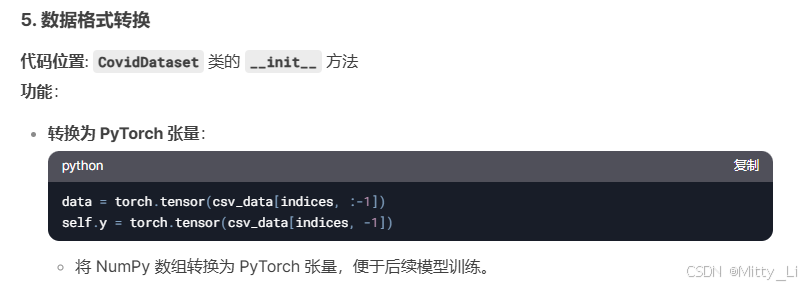


二.模型定义


其中在这里有对super的思考:
#super()显式调用父类初始化方法 → 父子类属性均存在时,调用同一个方法会自动先去调用子类,当你想调用父类的时候,就用super简而言之,super()不是用来“继承”属性和方法的,而是用来调用父类逻辑,确保子类能正确使用已继承的属性和方法。 #super()的理解:在黑马https://www.bilibili.com/video/BV1qW4y1a7fU?spm_id_from=333.788.videopod.episodes&vd_source=8b9e260d6730271baf18c841410561f0&p=119

三.训练与验证



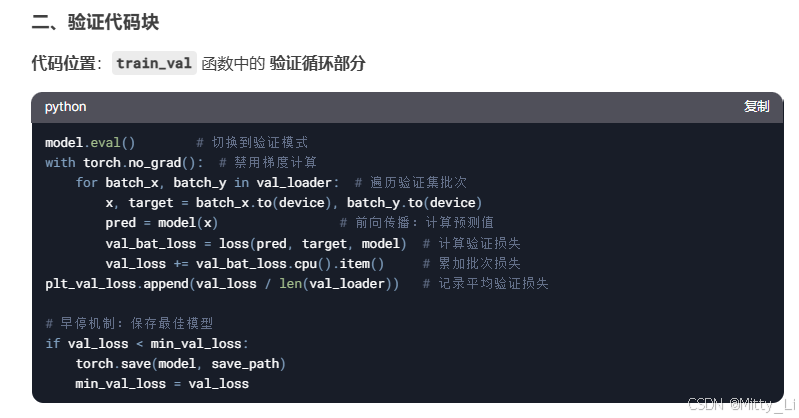


动量的概念:
动量,就相当于惯性,继续冲一下,目的是为了防止陷入以为自己是最小值而不动弹的情况
四.测试与结果生成
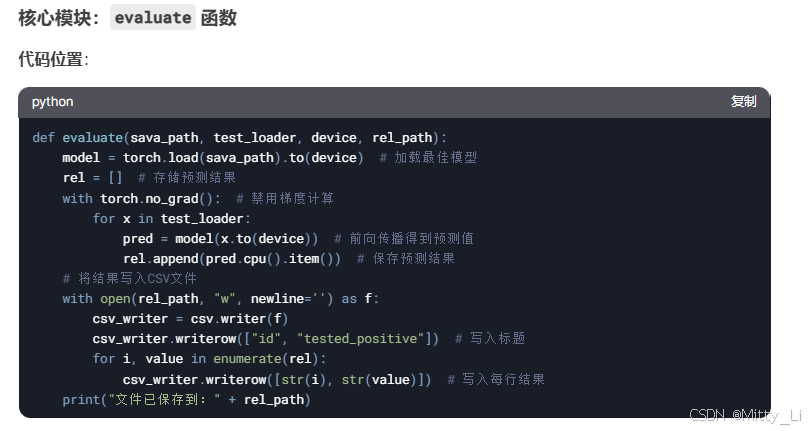
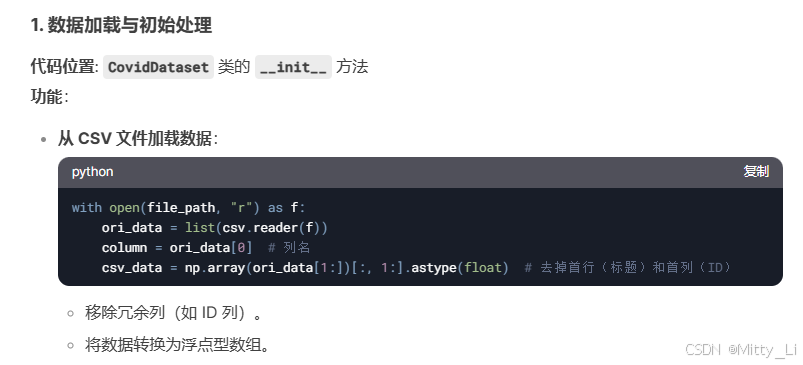
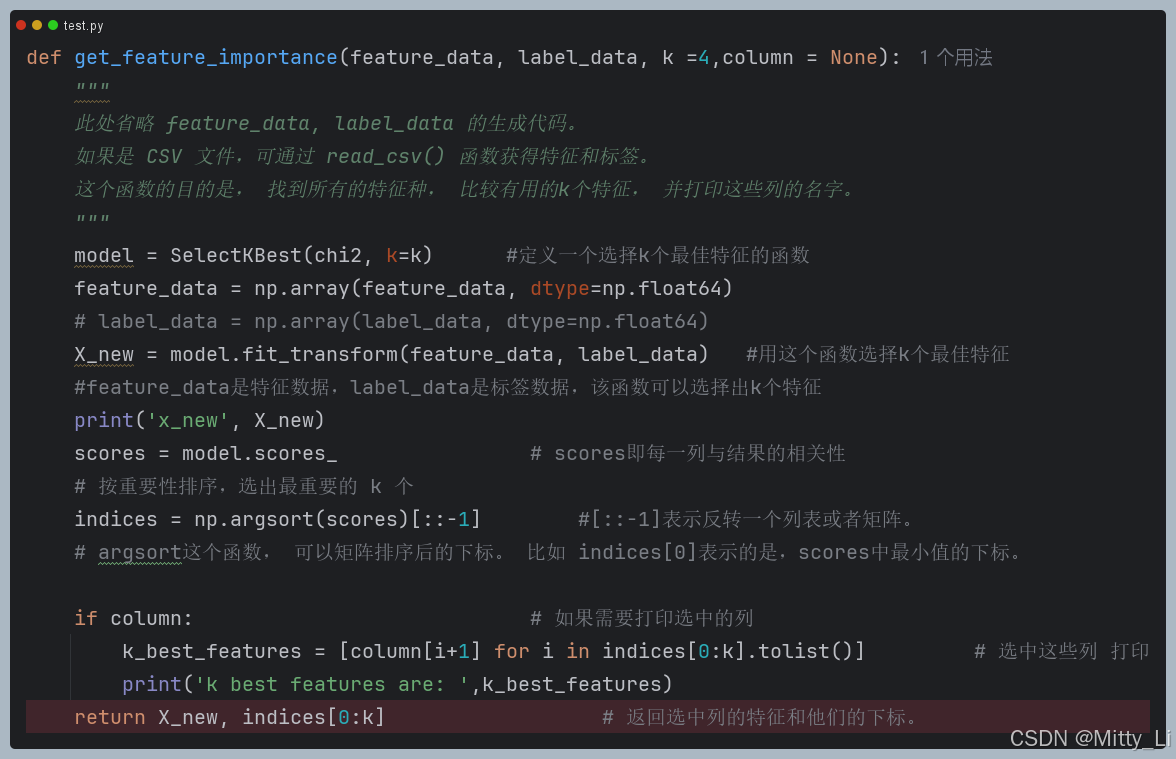
优化点:SelectKBest
1. 核心功能
-
特征降维:从原始特征中选择最重要的 K 个,减少冗余或无关特征,提升模型效率和准确性。
-
适用场景:分类、回归任务中,需快速筛选高相关性特征。


















 2720
2720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









