



三、后端接口部分
共定义了六个python文件,其中在运行过程中需要启动四个,分别是backdata、countnum、login、chat。config和modules文件是在chat文件中被调用的,因此无需启动。其中前三个启动文件都是和数据库交互的数据,是我在毕设当中自行拓展的内容,chat文件是本次毕设的主要实现功能,实现问答语句的返回,接下来会着重讲解这一部分的逻辑。
与数据库关联接口
以backdata为例,countnum和login写法均与前述一致,可查看源码。
后台管理界面的数据需要连接数据库进行操作,这里使用的是mysql数据库。以下代码展示了详细的配置格式,也是连接mysql数据库的必要格式,注意点已在代码中注释出来。
from flask_cors import CORS
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import text
app=Flask(__name__)
CORS(app)
HOSTNAME = "127.0.0.1"
PORT = 3306
USERNAME = "root"
PASSWORD = "自己的数据库密码"
DATABASE = "backplotform"#和在数据库中要使用的表的表名一致,否则无法正确连接
app.config['SQLALCHEMY_DATABASE_URI'] = f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8"
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
#自定义类名
class bakcdata(db.Model):
#将数据库backplotform表中的变量按照以下格式写到此处
id=db.Column(db.Integer,primary_key=True)
request=db.Column(db.Text)
answer=db.Column(db.Text)
comment=db.Column(db.Text)
satisfication=db.Column(db.Integer)
time = db.Column(db.Text)
username = db.Column(db.Text)
def __repr__(self):
return f"<bakcdata {self.id}>"
@app.route('/getrecord',methods=['GET'])
def getrecord():
with app.app_context():
records = bakcdata.query.all()
records_dict = [{'id': record.id, 'request': record.request, 'answer': record.answer,
'time': record.time, 'comment': record.comment, 'satisfication': record.satisfication,
'username':record.username}
for record in records]
return jsonify(records_dict)
if __name__ == '__main__':
app.run(port=5001)
接下来解释编写一个接口所需要的详细步骤。
@app.route的括号内定义了两个参数,第一个参数是对前端暴露的接口名,前端部分在请求这个接口时就可以使用这个名称进行调用。第二个参数若为post,则需要接收前端传递过来的数据,并对后端的数据进行修改;若为get,则为直接获取后端的数据,无需任何修改。
def后的函数名建议和暴露的方法名一致,with也为固定写法语句。
中间一系列的写法已通过注释表示。
最后若是对数据库的表项进行删除操作,则在commit之前要使用delete,并传入对应要删除的表项;若要对数据库表增加表项,则需要在commit之前使用add,并传入相应表项。若不对数据库表进行相应的操作,则直接return返回数据给前端即可。
#此处接口的方法设置为post,因此前端传送的数据要对后端的数据库表中进行修改
#该接口实现的是删除功能
@app.route('/deleterecord',methods=['POST'])
def deleterecord():
with app.app_context():
# 为什么需要json,因为post请求的数据往往会在request里,
# 若前端是一个json格式,则调用json,然后通过字典的形式获取相应的值
# 如果为整型数据,则直接从data项中获取即可
# 定义一个data,来接收前端传递进行的数据
data = request.json
#data数据中含有id,通过get方法来获取
recordid = data.get('id')
# 通过class名来获取对该表的对象,以此来获取表中的数据
# 使用数据库查询语句对数据库进行查询
record = bakcdata.query.get(recordid)
db.session.delete(record)
db.session.commit()
return jsonify({'message':'删除成功'}),200
实现智能问答语句返回接口
chat为主函数,modules.py和config.py为辅函数
在实现问答语句的返回的过程中,我定义了一个diseasename变量,用来接收实体识别出来的结果,同时用作对用户提问的疾病进行统计,以用作可视化的图标的数据支撑。
首先用msg接收前端传递进来的数据sent(这是在前端定义好的变量名称)。下一步便是拿到msg中的问句,调用classifier对其进行意图分类。
#chat函数
@app.route('/index',methods=['GET'])
def index():
diseasename = []
msg = request.args.get('sent')
user_intent = classifier(msg)
if user_intent in ["greet","goodbye","deny","isbot"]:
reply = gossip_robot(user_intent)
elif user_intent == "accept":
reply = load_user_dialogue_context('wjh')
reply = reply.get("choice_answer")
else:
reply = medical_robot(msg , 'wjh')#reply就是槽位模板,里面有已经填充好的模板信息
# 用作数据库统计疾病提问的数量
diseasename = get_disease_name(msg,'wjh')
if reply["slot_values"]:#如果存在新的疾病实体,那么就需要重新写入日志,用于下一轮对话
dump_user_dialogue_context('wjh',reply)
reply = reply.get("replay_answer")
return jsonify({'reply': reply , 'diseasename':diseasename}),200
#moudles.py
def classifier(text):
"""
判断是否是闲聊意图,以及是什么类型闲聊
"""
"""
这里的clf_model是先前使用bert模型训练好的意图识别模型,
使用predict方法可以获取预测到的置信度
"""
return clf_model.predict(text)
在进行意图识别的过程中,调用模型进行预测时会同步返回一个置信度,当意图置信度达到一定阈值时(>=0.8),可以查询该意图下的答案,也即会直接执行else部分;当意图置信度较低时(0.4~0.8),会进行一次意图增强(accept)的提问,若用户进行了肯定的回答,则置信度会被提升至0.8,按照识别的实体进行恢复,若用户拒绝了回答,则置信度会被修改至小于0.4的某一个值,按照拒绝回答的模板进行回复。
意图的识别会分为两类,一类是闲聊意图,另一类是增强意图。若识别为闲聊意图:问好(greet)、再见(goodbye)、肯定(isbot)、拒绝(deny),则需要触发gossip_robot函数,使其调用config中配置好的回复模板。
若意图识别为闲聊意图,则会调用以下代码按分类进行回复。
#modules.py
def gossip_robot(intent):
return random.choice(
gossip_corpus.get(intent)
)
#config.py
gossip_corpus = {
"greet":[
"你好呀",
"你好,我是智能医疗诊断机器人,有什么可以帮助你吗",
"你好,你可以问我一些关于疾病诊断的问题哦"
],
"goodbye":[
"再见啦,很高兴为您服务,欢迎再次使用,祝您身体健康!"
],
"deny":[
"很抱歉没帮到您",
"那您可以试着问我其他问题哟"
],
"isbot":[
"我是小智,你的智能健康顾问",
"你可以叫我小智哦~",
"我是医疗诊断机器人小智"
],
}
在说明意图增强前,我们需要知道多轮对话是如何实现的。本项目定义了13种问题类型,包括定义、病因、预防措施、临床表现和相关病症等,每种提问类型都会对应一个语义槽,我们需要将识别出来的实体填入相应问题的语义槽当中。下面展示一个语义槽,其余问题类型都是相似的,只需要将识别出来的实体填入Disease中,这就要借助utils文件夹中的json_utils.py文件,其里面的dump_user_dialogue_context函数。
#config.py
semantic_slot = {
"病因":{
"slot_list" : ["Disease"],
"slot_values":None,
"cql_template" : "MATCH(p:疾病) WHERE p.name='{Disease}' RETURN p.cause",
"reply_template" : "'{Disease}' 疾病的原因是:\n",
"ask_template" : "您问的是疾病 '{Disease}' 的原因吗?",
"intent_strategy" : "",
"deny_response":"您说的我有点不明白,您可以换个问法问我哦~"
},
}
以下为utils文件夹中json_utlis.py文件。
第一个函数是对json文件的修改,也即将识别出来的的实体填写在json文件中。修改的json文件往往是当识别出了新的实体后需要调用这个函数。在chat函数中,若为问答意图,则需要调用dump_user_dialogue_context函数,将识别出来的实体的填入到相应问题的模板中。
第二个函数是调用json文件,获取其填充好的语义槽,这往往用于意图增强时需要调用上一轮对话。
#实现多轮对话的关键
#将 Python 数据结构转换为 JSON 格式的字符串
def dump_user_dialogue_context(user,data):
path = os.path.join(LOGS_DIR,'{}.json'.format(str(user)))#则是根据用户标识 user 构建的文件名(以用户标识为名的 JSON 文件)。
with open(path,'w',encoding='utf8') as f:
f.write(json.dumps(data, sort_keys=True, indent=4,
separators=(', ', ': '),ensure_ascii=False))
def load_user_dialogue_context(user):
path = os.path.join(LOGS_DIR,'{}.json'.format(str(user)))
if not os.path.exists(path):
return {"choice_answer":"非常抱歉,我不理解你的意思。","slot_values":None}
else:
with open(path,'r',encoding='utf8') as f:
data = f.read()
return json.loads(data)
以下为wjh.json文件中的内容(存储上一轮对话的json文件),识别的插槽名为:“颅脑损伤”。
{
"ask_template": "您问的是疾病 '{Disease}' 的治疗方法吗?",
"choice_answer": "'颅脑损伤' 的主要治疗药物有:\n甘油氯化钠注射液、胞磷胆碱钠氯化钠注射液",
"cql_template": "MATCH(p:疾病)-[r:recommand_drug]->(q) WHERE p.name='{Disease}' RETURN q.name",
"deny_response": "没有理解您说的意思哦~",
"intent_strategy": "clarify",
"replay_answer": "您问的是疾病 '颅脑损伤' 的治疗方法吗?",
"reply_template": "'{Disease}' 的主要治疗药物有:\n",
"slot_list": [
"Disease"
],
"slot_values": {
"Disease": "颅脑损伤"
}
}
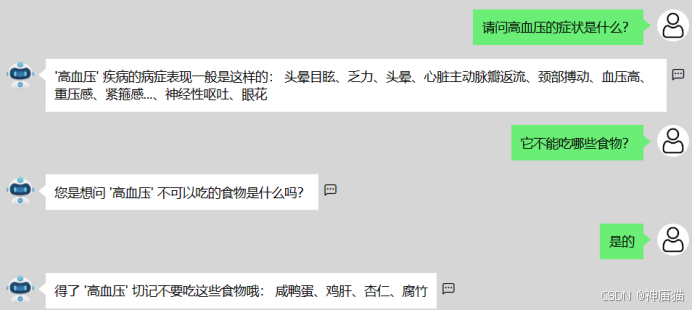
当用户输入的问句省略了疾病主语时,如下图中“它不能吃哪些食物?”,此时不能够直接分析出实体,那么此时意图识别为增强意图,则首先会调用utils文件夹中的json_utils.py 中的load_user_dialogue_context方法,调用上一轮对话中识别出来的语义槽。若无法加载到上一轮存储对话的文件,则返回无法回答的语句,也即上一轮未能识别出正确的实体。若能够找到,则读取data并返回,再获取其中的choice_answer返回最终的结果,也即后端会返回“您是想问‘高血压’不可以吃的食物是什么吗?”。返回问句中使用的“高血压”就是从json文件中调用的上一轮对话存储的结果。
若意图识别为诊断意图,则调用封装好的medical_robot进行文本解析,并利用填充好的语义槽对问句进行组装然后返回最终回复答案。其中semantic_parser为文本的实体解析,根据其中的置信度返回相应的回复策略。而get_answer根据相应的意图,组装不同的cypher语句来查询返回最终的回复语句。
def medical_robot(text,user):
"""
如果确定是诊断意图则使用该方法进行诊断问答
"""
semantic_slot = semantic_parser(text,user)
answer = get_answer(semantic_slot)
return answer
def intent_classifier(text):
#该方法内部会调用训练好的模型来解析文本的意图,获取相应的概率和名称
result = bert_intent_recognize(text)
if result != -1:
return result['data']
else:
return -1
def slot_recognizer(text):
#该方法可以获取识别出来的实体
result = medical_ner(text)
if result != -1:
return result['data']
else:
return -1
def semantic_parser(text,user):
"""
对文本进行解析
intent = {"name":str,"confidence":float}
"""
intent_rst = intent_classifier(text)#会获取相应的名称和概率
slot_rst = slot_recognizer(text)
if intent_rst==-1 or slot_rst==-1 or intent_rst.get("name")=="其他":
return semantic_slot.get("unrecognized")
slot_info = semantic_slot.get(intent_rst.get("name"))
# 填槽:实际上就是要去调用模型的一个过程,将从用户输入文本中提取的实体或信息填入预定义的槽位中
slots = slot_info.get("slot_list")#从槽信息中获取槽列表,获取识别的实体疾病。
slot_values = {}#创建一个空字典,用于存储槽的值
for slot in slots:
slot_values[slot] = None
for ent_info in slot_rst:
for e in ent_info["entities"]:
if slot.lower() == e['type']:
slot_values[slot] = entity_link(e['word'],e['type'])
last_slot_values = load_user_dialogue_context(user)["slot_values"]#将填充完的槽值存入槽信息中。
for k in slot_values.keys():
if slot_values[k] is None:
slot_values[k] = last_slot_values.get(k,None)
slot_info["slot_values"] = slot_values
# 根据意图强度来确认回复策略,这里会选择相应的直接进行回复
conf = intent_rst.get("confidence")
if conf >= intent_threshold_config["accept"]:
slot_info["intent_strategy"] = "accept"
elif conf >= intent_threshold_config["deny"]:
slot_info["intent_strategy"] = "clarify"
else:
slot_info["intent_strategy"] = "deny"
return slot_info
def get_answer(slot_info):
"""
根据语义槽获取答案回复
"""
#获取相应的语义槽变量,具体的内容可以查看config中的语义槽
cql_template = slot_info.get("cql_template")
reply_template = slot_info.get("reply_template")
ask_template = slot_info.get("ask_template")
slot_values = slot_info.get("slot_values")
strategy = slot_info.get("intent_strategy")
if not slot_values:
return slot_info
#根据回复策略来组装cypher语句
if strategy == "accept":
cql = []
if isinstance(cql_template,list):
for cqlt in cql_template:
cql.append(cqlt.format(**slot_values))
else:
cql = cql_template.format(**slot_values)
answer = neo4j_searcher(cql)
if not answer:
slot_info["replay_answer"] = "抱歉,未找到相关结果,请重新提问!"
else:
pattern = reply_template.format(**slot_values)
slot_info["replay_answer"] = pattern + answer
elif strategy == "clarify":
# 澄清用户是否问该问题
pattern = ask_template.format(**slot_values)
slot_info["replay_answer"] = pattern
# 得到肯定意图之后需要给用户回复的答案
cql = []
if isinstance(cql_template,list):
for cqlt in cql_template:
cql.append(cqlt.format(**slot_values))
else:
cql = cql_template.format(**slot_values)
answer = neo4j_searcher(cql)
if not answer:
slot_info["replay_answer"] = "抱歉,未找到相关结果,请重新提问!"
else:
pattern = reply_template.format(**slot_values)
slot_info["choice_answer"] = pattern + answer
elif strategy == "deny":
slot_info["replay_answer"] = slot_info.get("deny_response")
return slot_info


















 3633
3633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









