









背景
DeepSeek现在流行度正盛,今年的机器学习就用他作为一个开端,开整。
本文是基于百度aistudio的在线课程《DeepSeek从云端模型部署到应用开发》。

AIstudio社区内一键部署DeepSeek
什么是Ollama
Ollama的原理主要涉及模型架构基础、本地化运行机制、多模型管理策略、量化与优化技术等多个方面,以下是具体说明:
基于Transformer的模型架构基础
Ollama所支持的大语言模型大多以Transformer架构为基础。Transformer架构由编码器和解码器组成,核心是自注意力机制(Self-Attention)。以文本生成为例,在处理输入文本时,自注意力机制可以让模型并行计算每个位置与其他位置之间的依赖关系,捕捉文本中的长序列依赖信息,比如在理解一个复杂句子时,能准确把握各个词汇之间的语义关联,从而更好地生成连贯、有逻辑的文本。
本地化运行机制
- 模型下载与存储:Ollama从模型开源仓库或其他来源下载模型权重数据和相关配置文件,存储在本地设备的指定目录。如用户指定下载Llama-2模型,Ollama会按模型结构和权重文件组织方式,将其完整下载并存储,便于后续加载和使用。
- 本地计算资源利用:运行时,Ollama根据本地硬件资源,如CPU的核心数、频率,GPU的显存容量、计算能力等,合理分配计算任务。利用硬件加速库如CUDA(针对NVIDIA GPU)或ROCm(针对AMD GPU),将模型计算任务并行化处理,提高运行效率。比如在进行文本生成时,可利用GPU的并行计算能力快速计算模型的前向传播,生成文本结果。
- 与本地环境交互:能与本地的文件系统、数据库等进行交互。用户可让模型读取本地文本文件内容进行分析处理,或从本地数据库中获取数据作为输入,经过模型处理后将结果输出到本地文件或数据库中。
多模型支持原理
- 模型适配层:Ollama构建了模型适配层,针对不同模型的结构差异和接口特点,进行统一的封装和适配。比如Llama模型和BERT模型结构不同,输入输出格式也有差异,模型适配层会将它们转换为Ollama内部统一的表示形式和处理流程,使Ollama能以统一方式加载和运行不同模型。
- 模型注册表:通过模型注册表记录支持的所有模型信息,包括模型名称、版本、作者、模型架构、权重文件路径、配置参数等。当用户请求使用某个模型时,Ollama可从注册表中快速获取模型相关信息,进行加载和初始化操作。
量化与优化技术原理
- 模型量化:采用量化技术将模型权重数据的精度降低,如从32位浮点数转换为8位整数或4位整数。在保证模型性能损失较小的情况下,大大减少了模型存储所需的空间和计算量。例如,将一个原本以32位浮点数存储的权重矩阵转换为8位整数存储,存储量可减少为原来的四分之一。
- 优化算法:运用各种优化算法对模型进行优化,如随机梯度下降(SGD)及其变种Adagrad、Adadelta、Adam等。这些算法通过调整模型的参数,使模型在训练或推理过程中更快地收敛到最优解,提高模型的运行效率和准确性。比如在模型微调过程中,Adam算法可根据参数的梯度自适应地调整学习率,加快模型收敛速度。
交互接口原理
- 命令行接口(CLI):通过解析用户在命令行输入的指令,将其转换为对Ollama内部函数的调用。比如用户在命令行输入
ollama run llama-2 --prompt "Hello",命令行解析器会识别出要运行Llama-2模型,并传入"Hello"作为输入提示,然后调用相应的模型运行函数,将结果输出到命令行。 - RESTful API接口:基于网络协议,将Ollama的功能封装成不同的API端点。当接收到客户端发送的HTTP请求时,按照请求的URL路径和方法,调用相应的处理函数,对请求数据进行处理,如接收用户通过POST请求发送的文本生成任务,运行模型后将生成的文本以JSON格式作为响应返回给客户端。
Ollama是一个专注于本地运行大语言模型(LLM)的开源项目。以下是对它的具体介绍:
- 核心特点
- 本地化运行:可在个人电脑或服务器等本地设备上直接运行开源大模型,如Llama3、Mistral、Phi-3等,无需依赖云端API,保证了数据隐私,降低延迟,增强可控性。
- 多模型支持:涵盖多种主流模型,包括大规模语言模型如GPT系列、BERT等;计算机视觉模型如ResNet、YOLO等;强化学习模型以及时间序列预测模型如LSTM、ARIMA等。
- 轻量化设计:通过量化技术,如4-bit或8-bit量化,显著降低模型内存占用,保持较高推理性能。
- 易于使用:提供简单的命令行界面和RESTful API,用户能通过几行代码调用模型,还可通过Modelfile整合模型权重、配置文件和数据集,简化部署配置。
- 跨平台兼容:支持Windows、macOS、Linux(包括ARM架构如树莓派),甚至结合Termux工具可在手机上部署。
- RAG集成:可结合本地文档库实现检索增强生成(Retrieval-Augmented Generation)。
- 核心功能
- 本地模型推理:能离线运行Llama3、CodeLlama等模型,进行文本、代码生成及对话。
- 模型微调:基于本地数据调整模型参数,适配垂直领域,不过通常需搭配其他工具。
- API服务暴露:通过REST API或OpenAI兼容接口,供其他应用调用本地模型。
- 多模态扩展:支持Whisper(语音)、BakLLaVA(图像)等多模态插件。
- 应用场景
- 内容创作:帮助生成博客文章、广告文案等内容。
- 编程辅助:辅助开发者生成代码、调试程序、优化代码结构。
- 教育和研究:辅助学生和研究人员学习、写作和研究,生成论文摘要、解答问题。
- 跨语言交流:利用多语言模型提供高质量翻译功能。
- 个人助手:帮助撰写邮件、生成待办事项等。
什么是蒸馏模型
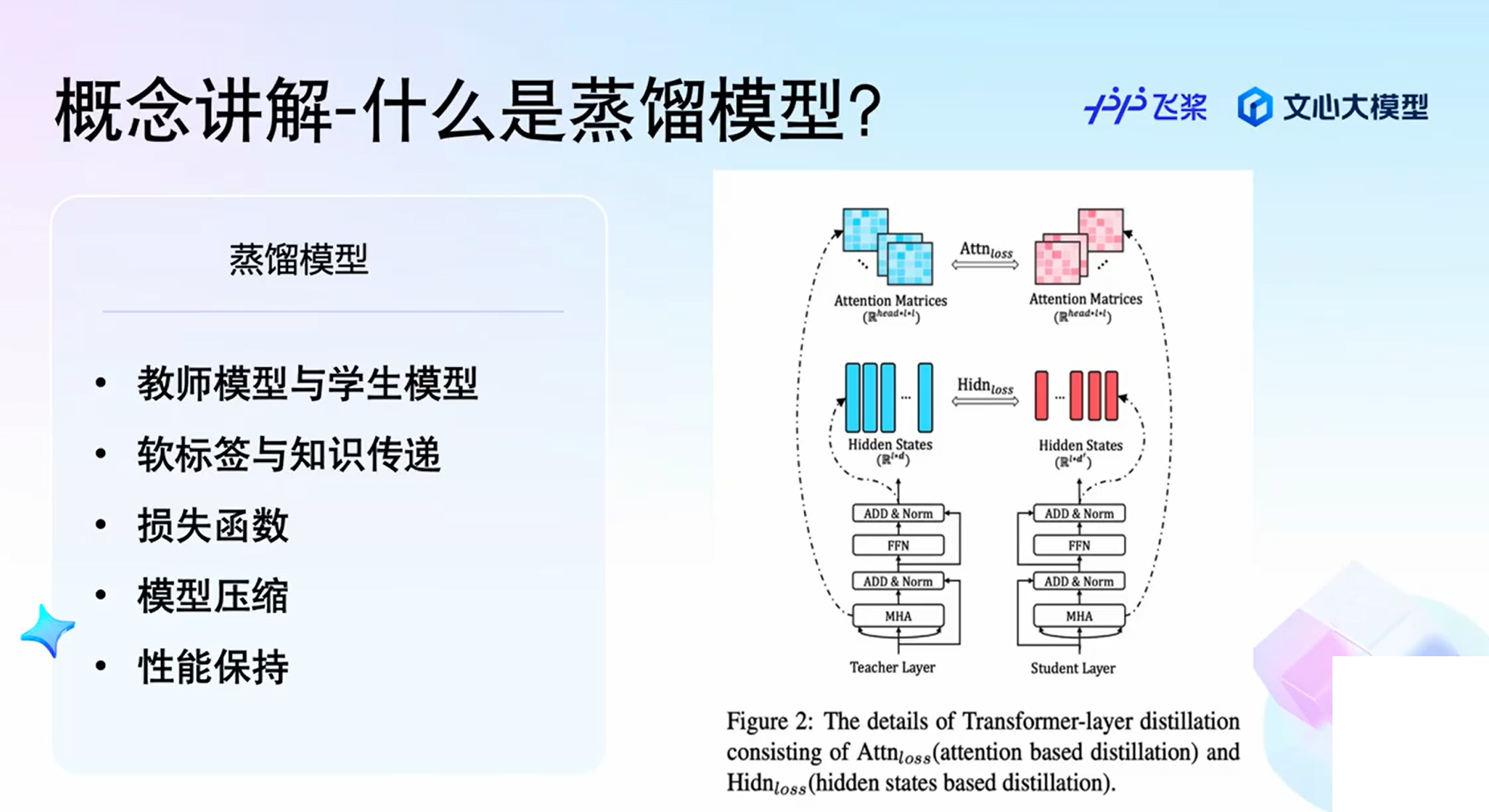
本次是用r1做教师模型,qianwen做学生模型
蒸馏模型是一种基于知识迁移技术的模型,旨在将一个复杂、性能较高的教师模型的知识,迁移至一个相对简单、规模较小的学生模型。以下是对它的具体介绍:
原理
- 训练教师模型:首先训练一个大模型,通常是一个非常复杂的神经网络,如深度学习模型,来完成特定的任务。这些大模型能够在数据上取得很好的结果,但计算开销较大。
- 生成软标签:教师模型用来预测数据的标签,生成的不是简单的硬标签,如分类任务中的“是”或“否”,而是一个软标签,通常是每个类别的概率分布。软标签包含了更多的信息,如类别之间的关系,可以帮助学生模型更好地学习。
- 训练学生模型:学生模型通常是一个较小的模型,结构上简单得多,训练时以教师模型的输出,即软标签,作为目标进行优化。通过这种方式,学生模型可以学习到教师模型中的一些特征和知识,虽然它的容量和复杂度较小,但仍能达到较高的性能。
损失函数计算
蒸馏损失是用来衡量学生模型的输出和教师模型的输出之间的差异,目标是让学生模型尽量模仿教师模型的“思考方式”,从而学到教师模型的知识。在知识蒸馏中,通常会用到两种损失:
- 蒸馏损失(Distillation Loss):让学生模型的输出尽量接近教师模型的软标签。
- 常规损失(Hard Loss):让学生模型的输出尽量接近真实标签,即硬标签。最终的损失函数是这两种损失的加权组合。
优势
- 模型压缩:学生模型比教师模型小得多,适合部署在资源有限的设备上,如移动设备、边缘计算设备等。
- 性能不打折:学生模型的性能可以接近甚至在某些情况下超过教师模型,能在保持较高准确性的同时,具有更低的计算资源需求。
- 泛化能力强:软标签提供了更多的信息,让学生模型在面对新数据时表现更好,能够更好地捕捉数据中的复杂模式和关系。
应用
模型蒸馏的应用场景几乎涵盖了AI的各个领域,如自然语言处理领域的DistilBERT、TinyBERT,可让手机等设备也能运行NLP模型;在计算机视觉领域,可将大型卷积神经网络蒸馏为轻量级模型,用于手机拍照、人脸识别等;在边缘计算中,助力智能家居、自动驾驶等场景中的AI在低功耗设备上运行。
模型参数量
社区内一键部署DeepSeek
首先点击部署
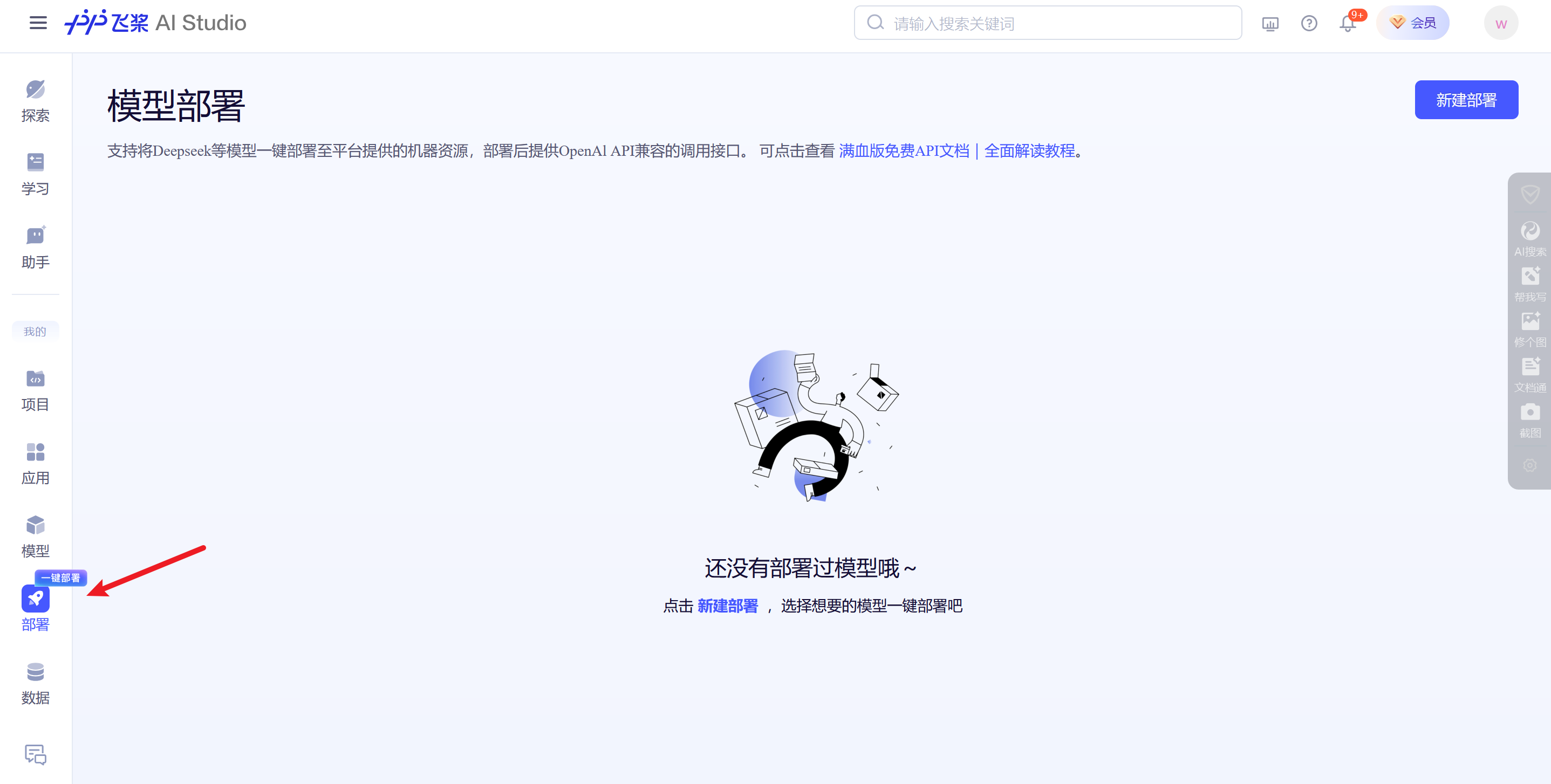
选择新建部署,然后选择llama-70B模型
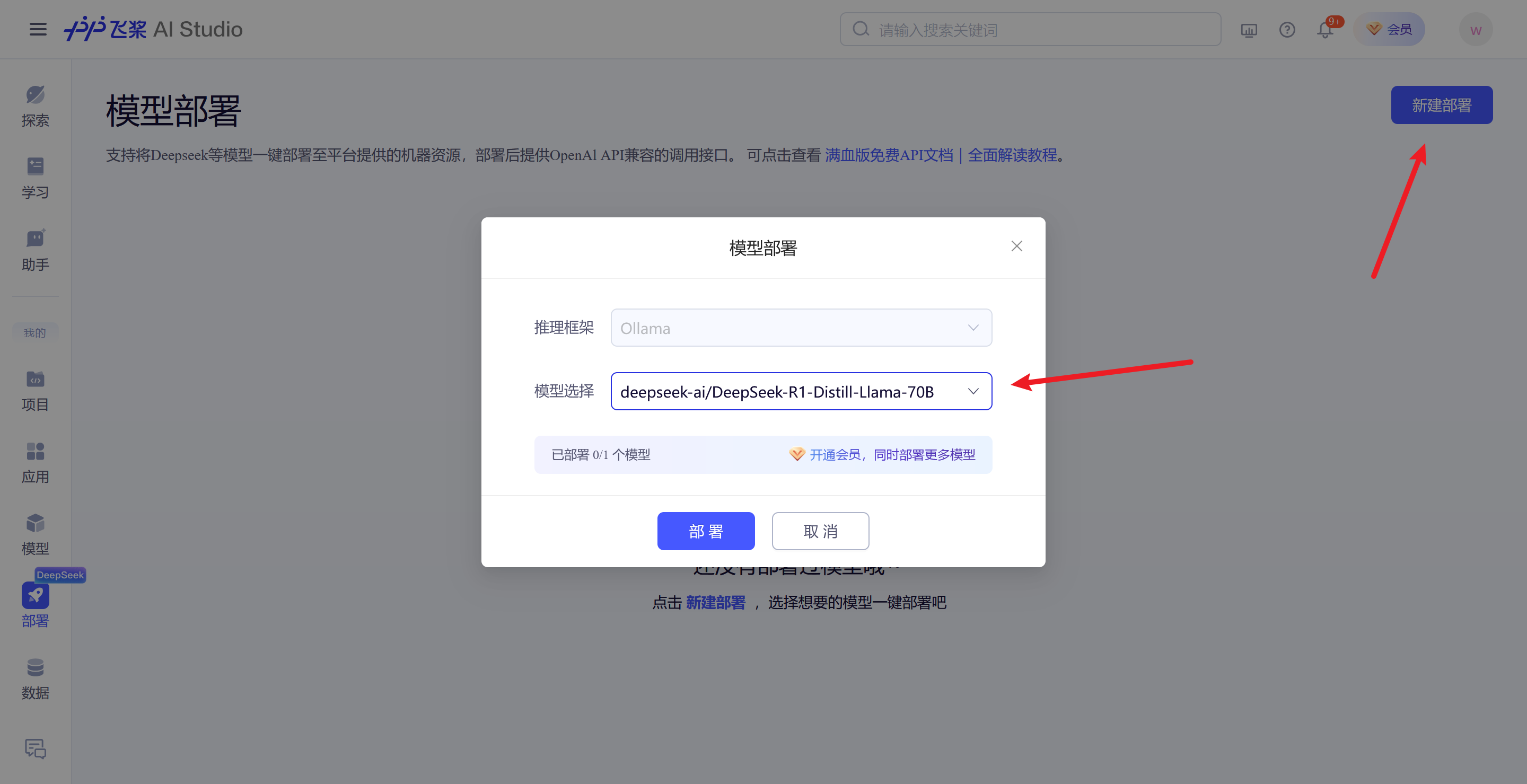
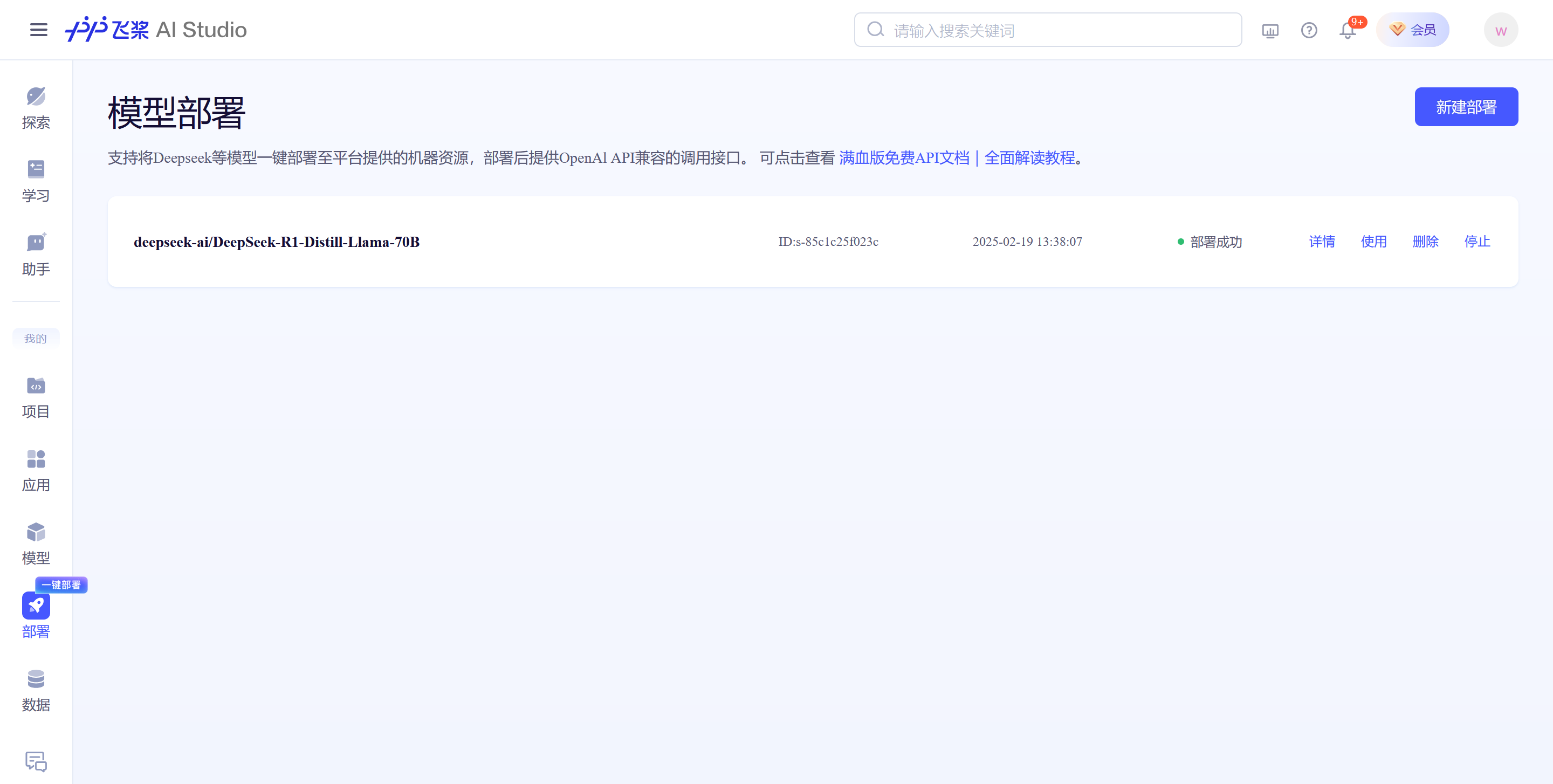
然后就部署成功了
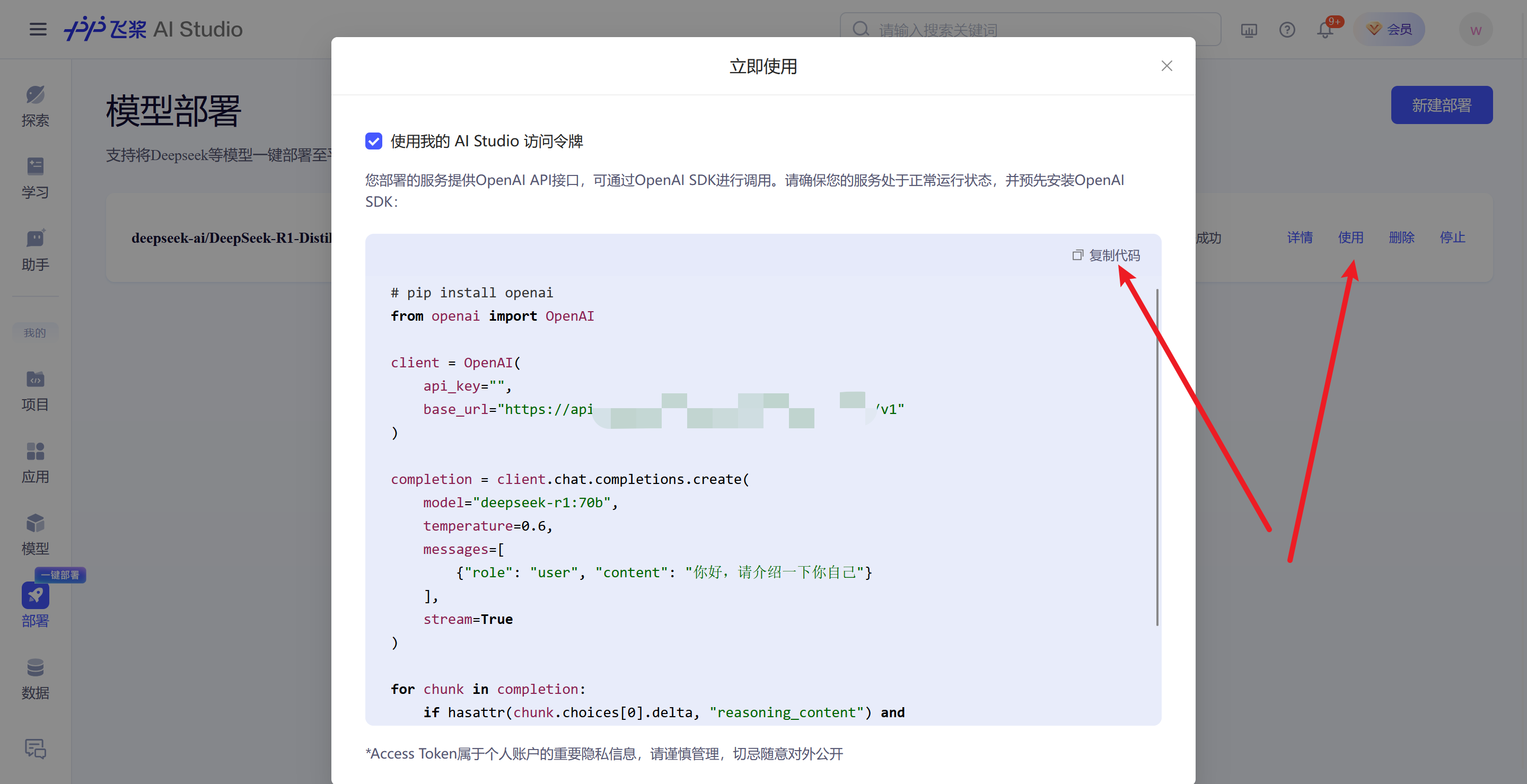
点击使用或详情,可以查看到具体的api-key和地址,需要注意的是,现在api-key已经无法直接看到,需要个人中心中获取。复制这部分的代码。
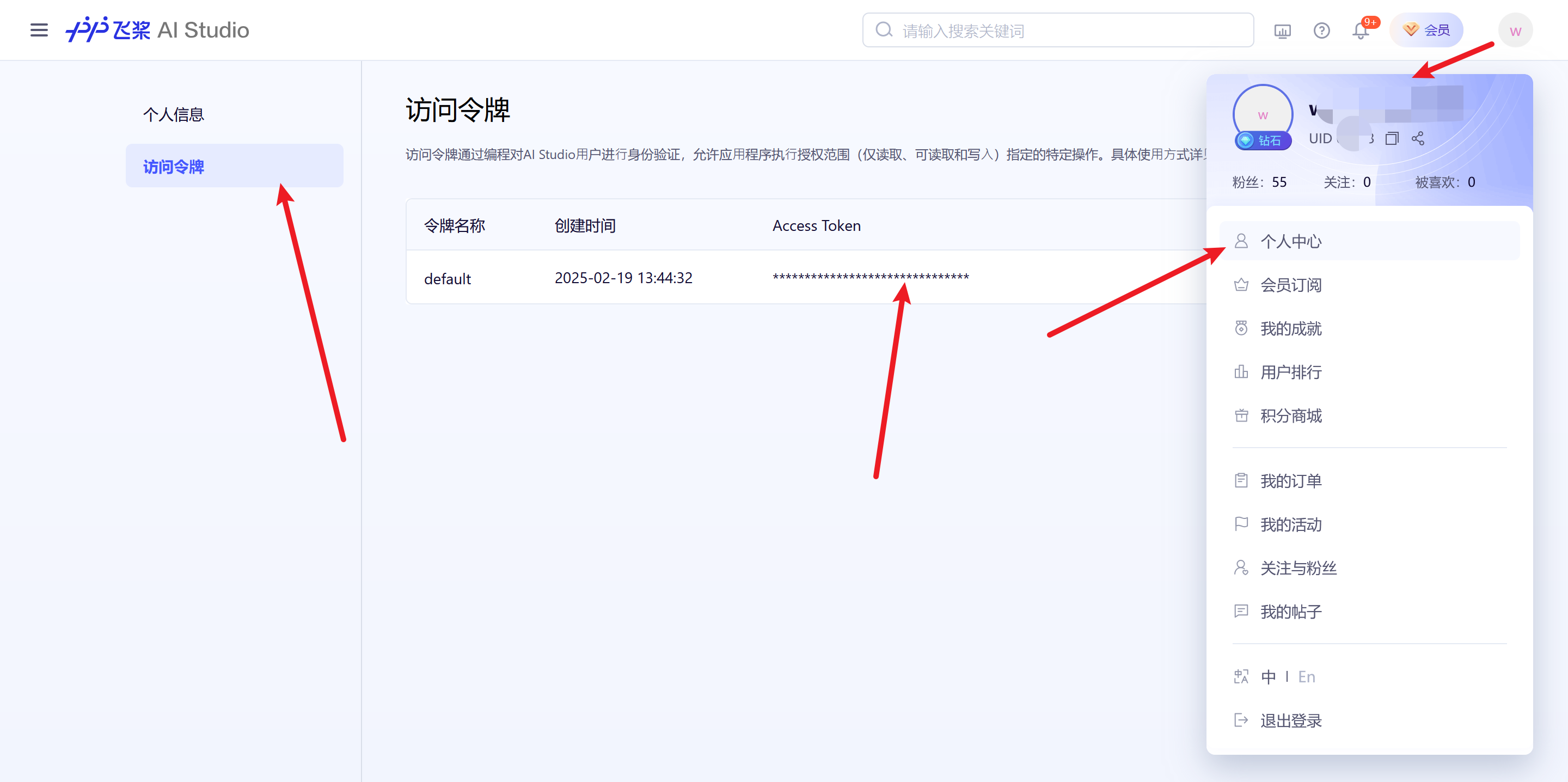
点击头像,弹出个人中心,单击访问令牌,既可以看到aistudio的访问令牌,切记要保存好,不要外泄
新建一个项目,或是本地新建一个项目,然后把复制好的代码和api-key给贴到代码中
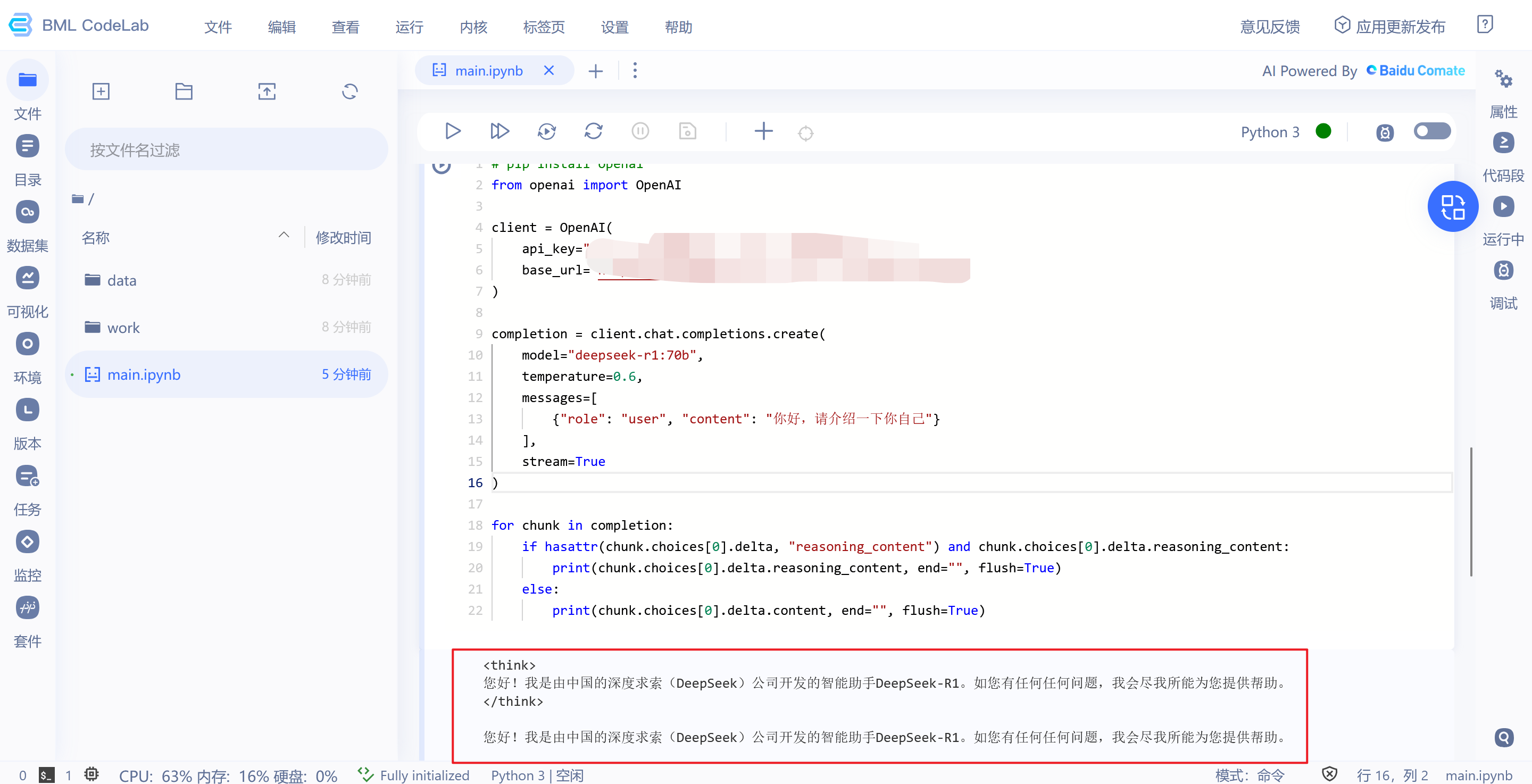
# pip install openai
from openai import OpenAI
import os
os.environ["AI_STUDIO_API_KEY"] = ""
# https://aistudio.baidu.com/account/accessToken
client = OpenAI(
api_key=os.environ.get("AI_STUDIO_API_KEY"),
base_url="https://api-8735kfl5z2eaz3x8.aistudio-app.com/v1"
)
completion = client.chat.completions.create(
model="deepseek-r1:70b",
temperature=0.6,
messages=[
{"role": "user", "content": "你好,请介绍一下你自己"}
],
stream=True
)
for chunk in completion:
if hasattr(chunk.choices[0].delta, "reasoning_content") and chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
else:
print(chunk.choices[0].delta.content, end="", flush=True)
输出如下:
流式对话
import os
os.environ["AI_STUDIO_API_KEY"] = ""
# https://aistudio.baidu.com/account/accessToken
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("AI_STUDIO_API_KEY"), # 含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken,
base_url="https://aistudio.baidu.com/llm/lmapi/v3", # aistudio 大模型 api 服务域名
)
completion = client.chat.completions.create(
model="deepseek-r1",
messages=[
{'role': 'system', 'content': '你是 AI Studio 实训AI开发平台的开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议。'},
{'role': 'user', 'content': '你好,请介绍一下AI Studio'}
],
stream=True,
)
for chunk in completion:
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
else:
print(chunk.choices[0].delta.content, end="", flush=True)
多轮对话
import os
os.environ["AI_STUDIO_API_KEY"] = ""
# https://aistudio.baidu.com/account/accessToken
import os
from openai import OpenAI
def get_response(messages):
client = OpenAI(
api_key=os.environ.get("AI_STUDIO_API_KEY"), # 含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken,
base_url="https://aistudio.baidu.com/llm/lmapi/v3", # aistudio 大模型 api 服务域名
)
completion = client.chat.completions.create(model="ernie-3.5-8k", messages=messages)
return completion
messages = [
{
"role": "system",
"content": "你是 AI Studio 开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议。",
}
]
assistant_output = "您好,我是AI Studio 开发者助理,请问有什么能帮助你的吗?"
print(f"""输入:"结束",结束对话""")
print(f"模型输出:{assistant_output}")
user_input = ""
while "结束" not in user_input:
user_input = input("请输入:")
# 将用户问题信息添加到messages列表中
messages.append({"role": "user", "content": user_input})
print("message: \n ",messages)
assistant_output = get_response(messages).choices[0].message.content
# 将大模型的回复信息添加到messages列表中
messages.append({"role": "assistant", "content": assistant_output})
print(f"模型输出:{assistant_output}")
print("")


















 7842
7842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











