




🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
OpenAI 正式官宣 o3 & o4-mini:迄今最强模型,AI 终于学会“十八般武艺”全家桶了。
之前传闻的 OpenAI 新“推理模型”正式落地,o3 和 o4-mini 来了,官方自称“迄今为止最聪明、最强大”。直接拉高了 ChatGPT 的能力上限。
这次最大的杀手锏:首次实现 Agent 主动调用并组合 ChatGPT 内部所有工具 —— 网页搜索、Python 数据分析、深度视觉理解、甚至图像生成,全都能串起来用。
关键是,这些模型被训练得懂得何时、如何使用工具,能在通常一分钟内,针对复杂问题给出细致、周到的答案,格式还很对路。
这是向更自主的 Agentic ChatGPT 迈出的一大步,能独立帮你干活了。

有啥不一样?
o3 (全能打手): OpenAI 最强的推理模型,在编码、数学、科学、视觉感知等领域全面突破,刷新了 Codeforces, SWE-bench (还不用专门定制脚手架), MMMU 等多个榜单的 SOTA。
特别擅长处理需要多方面分析、答案不明显的复杂查询,视觉分析能力尤其突出 (图像、图表)。
外部专家评估显示,在困难的真实世界任务中,o3 比 o1 少犯 20% 的严重错误,尤其在编程、商业咨询、创意构思方面表现出色。
早期测试者称赞它作为“思考伙伴”的分析严谨性,以及生成和批判性评估新假设的能力 (尤其在生物、数学、工程领域)。
o4-mini (性价比之王): 更小巧的模型,专为速度和成本优化。性能远超其规模和成本应有的水平,特别是在数学、编码和视觉任务上。
在 AIME 2024 和 2025 数学竞赛基准上表现最佳。专家评估也显示,它在非 STEM 任务和数据科学等领域也优于前代 o3-mini。因为效率高,o4-mini 的调用额度比 o3 高得多,适合需要大量推理的高并发场景。
外部专家还评价说,这两款模型指令遵循能力更强,回答更有用、更可验证 (部分归功于网页搜索的引入)。而且,它们对话起来感觉更自然,会参考记忆和之前的对话,让回复更个性化、更贴切。
AIME 竞赛数学: o4-mini (92.7%) > o3 (91.6%) > o3-mini (87.3%) > o1 (74.3%) (不使用工具)
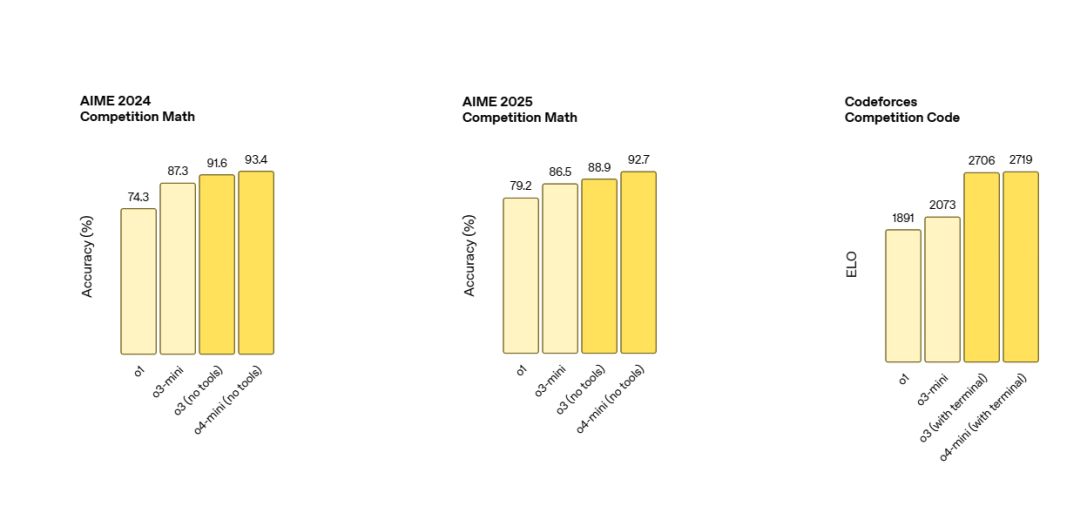
Codeforces 竞赛编程: o4-mini (ELO 2719) ≈ o3 (ELO 2706) >> o3-mini (2073) > o1 (1891) (带终端)
GPQA Diamond (博士级科学问题): o3 (83.3%) > o4-mini (81.4%) > o1 (78.0%) > o3-mini (77.0%) (不使用工具)
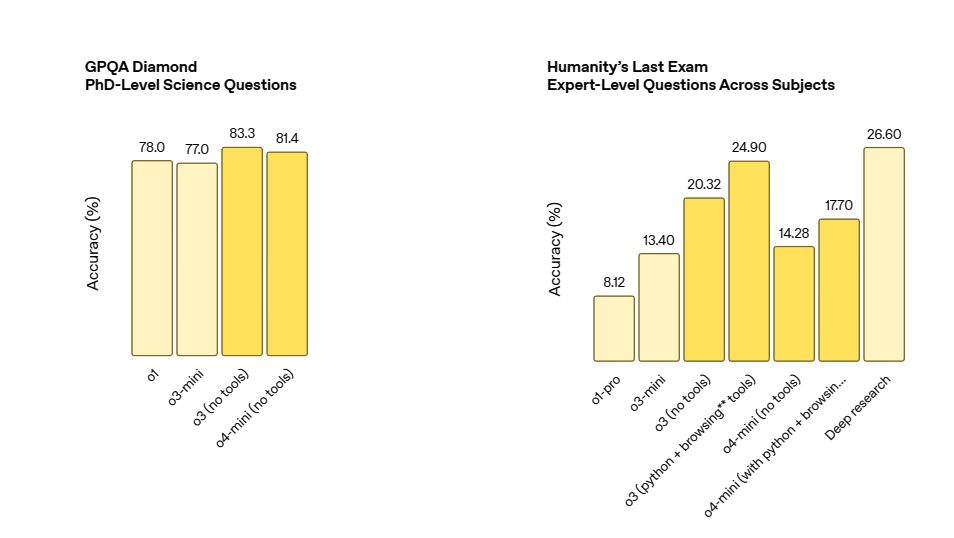
Humanity’s Last Exam (跨学科专家级问题): o3 (带工具 24.9%) > o3 (无工具 20.3%) > o4-mini (带工具 17.7%) > o4-mini (无工具 14.28%)
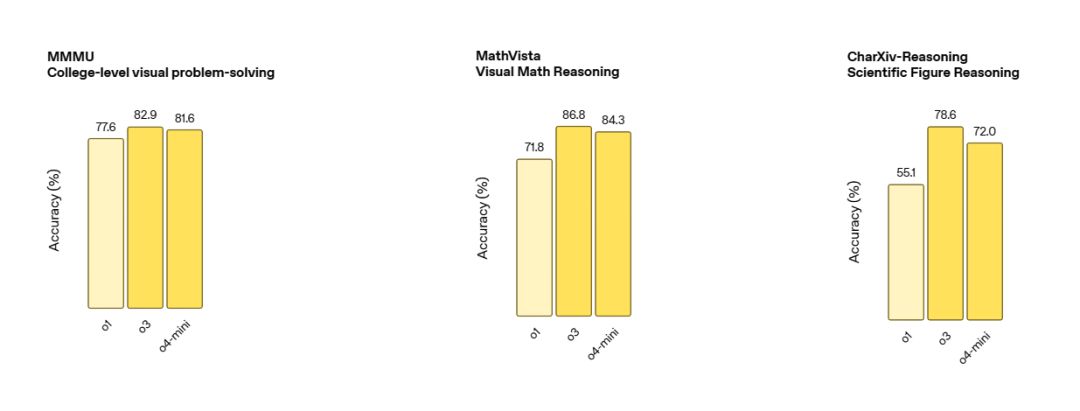
MMMU (大学级视觉解题): o3 (82.9%) > o4-mini (81.6%) > o1 (77.6%)
MathVista (视觉数学推理): o3 (86.8%) > o4-mini (84.3%) > o1 (71.8%)
SWE-Bench Verified (软件工程):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











