




🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
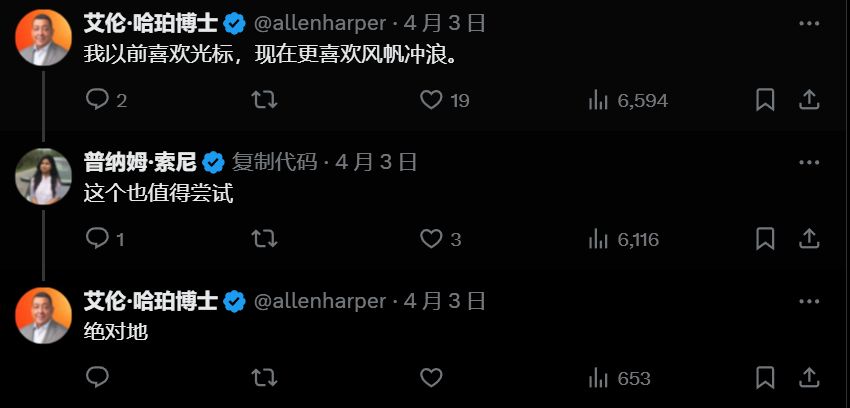 Tips:本文介绍产品功能、技术理念、实战体验、AI编码实践,信息量有点大。
Tips:本文介绍产品功能、技术理念、实战体验、AI编码实践,信息量有点大。Augment Code 自称是第一个能深度理解大型复杂项目、专为团队协作打造的 AI 编码平台, 今天正式亮相,号称能适应你的代码上下文,给团队生产力上 Buff。
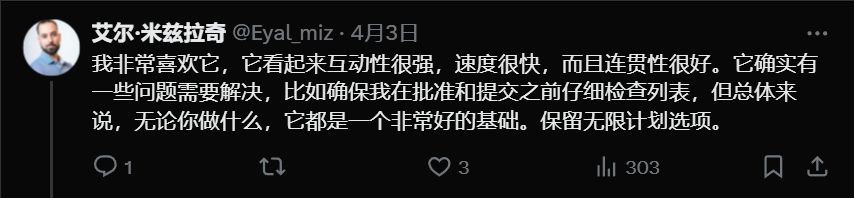
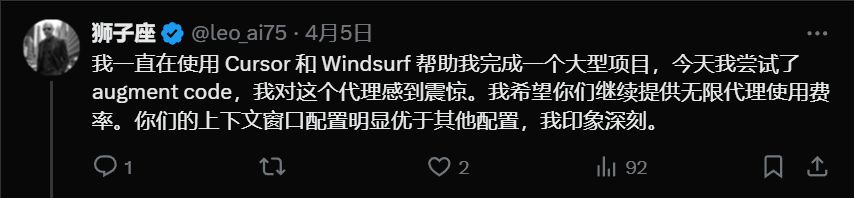
官方喊话了:“ 免费来试试,把你最大最复杂的代码库丢过来,看我们搞不搞得定。(augmentcode.com)。”
创始人 Scott Dietzen 表示,Webflow、Kong、Pigment 这些公司已经在用了。
 Augment 官方在博客中写到:AI正在改变我们编写代码的方式,而且变化很快。AI现在可以创建简单的应用程序、解释代码块并发现程序中的错误。但专业开发人员不会从事小型项目或代码片段的工作。现实世界中的软件开发涉及:接手没文档的屎山、用别人写的奇葩 API、搞不清依赖就得硬着头皮迁移、重构牵一发动全身的代码包…… 到目前为止,还没有 AI 编码平台专门针对软件工程团队在处理大型复杂代码库上解决这些痛点。
Augment 官方在博客中写到:AI正在改变我们编写代码的方式,而且变化很快。AI现在可以创建简单的应用程序、解释代码块并发现程序中的错误。但专业开发人员不会从事小型项目或代码片段的工作。现实世界中的软件开发涉及:接手没文档的屎山、用别人写的奇葩 API、搞不清依赖就得硬着头皮迁移、重构牵一发动全身的代码包…… 到目前为止,还没有 AI 编码平台专门针对软件工程团队在处理大型复杂代码库上解决这些痛点。这 Agent 要干啥?不只是写代码,而是帮你搞定整个开发流程。
专为在实际系统中工作的工程师打造: - 多文件编辑 - 完整 PR 创建 - 终端命令和代码执行 - 上下文感知文档和测试代理不只是建议代码。它编写码、运行代码并记录每一步。
终端/执行权限 get:直接指挥终端、运行代码,能力边界大扩展。
智能文档/测试:结合项目背景,生成靠谱的文档和测试用例。
全程 Live Show:写、跑、记,每一步操作都透明可见。
集成开发工作流 (Integrated Dev Workflows)从接活 (ticket) 到交差 (PR),一条龙服务,不用换工具:
- 连 GitHub 做分支、提交、发 PR。
- 连 Linear 发现和解决 issue。
- 连 Notion、JIRA、Confluence 把文档需求变成代码。AI 真正融入了你的日常工作流。
Agent 的几大亮点:
Augment 的核心武器:吃透你的代码库。每个功能都自带 上下文感知。给你的建议、补全、互动,全都贴着你的代码库来——组件、API、编码风格,它门儿清。能扛住大项目, 连 Unreal Engine、Chromium 这种级别的代码库都能搞定。“团队最大的痛点就是搞懂代码库的每个部分怎么运作、怎么组合。Augment Code 无缝集成,建议直观,团队效率和幸福感飙升。跟试过的其他编程助手比,这玩意儿是团队上手最快的。”— Chintan Shah, Collective 工程副总裁初创、大厂都在用。Collective 工程 VP 现身说法:搞懂全局代码库痛点被解决,团队效率、幸福感双提升,是上手最快的 AI 助手。持久记忆 (Persistent Memory) 这 Agent 越用越懂你:
- 它会学你的代码风格。
- 你上次怎么重构的,它记得。
- 你公司的基建和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3589
3589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











