



DDP 的工作原理——数据并行
当一张GPU可以存储一个model时,可以通过每张GPU都复制一份模型,在不同的GPU上运行不同的数据,即将一个批次的数据送入各个模型进行并行训练,通过对并行的GPUs上的数据和模型结果进行运算(求平均梯度...)来实现增大batch、提高速度的效果。
训练过程是多进程的,每一块GPU都对应一个进程,除非我们手动实现相应代码,不然各个进程的数据都是不互通的。
如果要用DDP来进行训练,我们通常需要修改三个地方的代码:数据读取器dataloader,日志输出print,指标评估evaluate。
1. DDP的训练过程
DDP的训练过程可以总结为如下步骤:
1)在训练开始时,整个数据集被均等分配到每个GPU上。每个GPU独立地对其分配到的数据进行前向传播(计算预测输出)和反向传播(计算梯度)。
2)通过Ring-All-Reduce算法同步各个GPU上的梯度,以确保模型更新的一致性。
3)一旦所有的GPU上的梯度都同步完成,每个GPU使用这些聚合后的梯度来更新他的模型副本参数,也就是step的过程。因为每个GPU都使用相同的更新梯度,所以所有的模型副本在任何时间点上都是相同的。
2.DDP的名词定义
rank:一个分布式训练的进程号,一个序号表示一个进程,一个分布式训练由多个rank进程组成。
node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
rank与local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。
nnodes、node_rank与nproc_per_node: nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
word size : 全局(一个分布式任务)中,rank的数量。
master_addr与master_port:主节点的地址以及端口,供init_method 的tcp方式使用。 因为pytorch中网络通信建立是从机去连接主机,运行ddp只需要指定主节点的IP与端口,其它节点的IP不需要填写。 这个两个参数可以通过环境变量或者init_method传入。
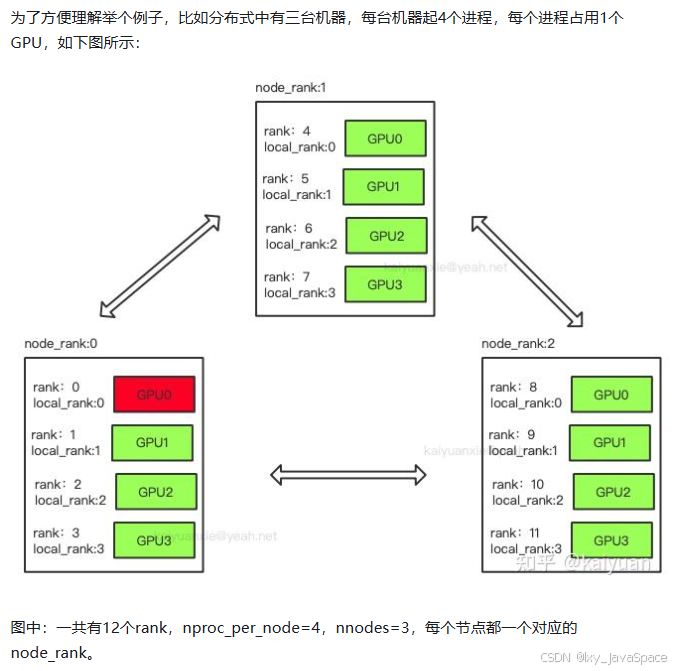

3. DDP是如何分布式的并行的运行代码的:
分布式训练通过启动多个进程,每个进程负责不同的 GPU 或部分计算任务。
--use_env 会自动设置分布式训练所需的环境变量,主要包括:
RANK:全局进程 ID。WORLD_SIZE:总进程数。LOCAL_RANK:当前进程对应的 GPU 索引(在本地节点上的 GPU 编号)。MASTER_ADDR:主节点地址。MASTER_PORT:主节点通信端口。
例如,假设你使用两张 GPU(nproc_per_node=2),会启动两个进程,分别负责 GPU 0 和 GPU 1。每个进程都会独立执行 main(args)。
## init_distributed_mode:
#给每个进程分配local rank序号,指导gpu的device序号
args.gpu = int(os.environ['LOCAL_RANK']) 这时,init_distributed_mode会根据环境变量进行初始化,比如说,上面两个进程,会分别得到:
arg.gpu=0和arg.gpu=1
Rank: 0, Local Rank: 0, World Size: 2
Rank: 1, Local Rank: 1, World Size: 2还有一个问题:
获得多gpu方法:
logging.info(f'GPU is available:{torch.cuda.is_available()}')
if torch.cuda.is_available():
gpus = torch.cuda.device_count()
for i in range(gpus):
print(f'\t GPU{i}.:{torch.cuda.get_device_name(i)}')如果要想高效的处理并行运算:
可以使用nn.parallel.DataParallel或nn.parallel.DistributedDataParallel,如:
从其他文章中学习的第一版(个人感觉不太符合我的需求):
在指定gpu的时候,如果device='cuda',并且是ddp多卡运行,那么xx.to(device)默认选择第一个卡作为选中的gpu,这意味着,即使系统中有多块 GPU,这条命令也只会指向默认的一块。比如:
device = torch.device(args.device) # args.device='cuda'
model.to(device)model 会在“cuda:0”上。
下面这种一次性输入多个device给ddp,不符合我一张gpu处理一个进程的需求,(不考虑):
#指定多个GPU
from torch.nn import DataParallel
#上面这一行一定要加,因为没加一直报错都开始怀疑torch版本是不是有问题了哈哈
import os
os.environ['CUDA_VISIBLE_DEVICES']='0,2,3,4'#代表使用的第一块,第三块,第四块和第五块卡
device_ids = [0,2,3,4]
model = torch.nn.Dataparallel(model, device_ids =device_ids)
model = model.cuda()
或:
model = torch.nn.Dataparallel(model)
# 默认适用所有gpu(这种可以通过CUDA_VISIBLE_DEVICES在命令行中指定使用的gpu)二改:
DDP单机多卡的gpu定义问题
torch.nn.parallel.DistributedDataParallel (简称 DDP) 时,device_ids参数指定的是 每个进程负责的设备列表,而不是整个系统的所有设备。
torch.nn.parallel.DistributedDataParallel的作用是copy model给每个进程。所以,该函数中的device_ids参数告诉 DDP 当前进程应该使用哪些设备(通常是一个或多个 GPU),并且这些设备是该进程独占的。
对于单机多卡训练,device_ids通常是每个进程对应的单个 GPU 的设备 ID 列表,如 [0], [1]。
如果一个进程负责多个 GPU,则 device_ids可以是一个列表,如 [0, 1]。(但通常不这样)
所以,正确代码:
torch.cuda.set_device(args.local_rank) # 设置当前进程使用的 GPU
model = DistributedDataParallel(model, device_ids=[args.local_rank])这样的话,每个model使用的device_ids就是当前进程分配的gpu id:例 [0]。
参考:Pytorch DistributedDataParallel(DDP)教程一:快速入门理论篇_distributeddataparallel教程-优快云博客PyTorch分布式训练基础--DDP使用 - 知乎
PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析_runtimeerror: distributeddataparallel is not neede-优快云博客


















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









