






一、RDD容错机制
当Spark集群中的某一个节点由于宕机导致数据丢失,则可以通过Spark中的RDD进行容错恢复已经丢失的数据。RDD提供了两种故障恢复的方式,分别是血统(Lineage)方式和设置检查点(checkpoint)方式。
(一)血统方式
根据RDD之间依赖关系对丢失数据的RDD进行数据恢复。若丢失数据的子RDD进行窄依赖运算,则只需要把丢失数据的父RDD的对应分区进行重新计算,不依赖其他节点,并且在计算过程中不存在冗余计算;若丢失数据的RDD进行宽依赖运算,则需要父RDD所有分区都要进行从头到尾计算,计算过程中存在冗余计算。
(二)设置检查点方式
本质是将RDD写入磁盘存储。当RDD进行宽依赖运算时,只要在中间阶段设置一个检查点进行容错,即Spark中的sparkContext调用setCheckpoint()方法,设置容错文件系统目录作为检查点checkpoint,将checkpoint的数据写入之前设置的容错文件系统中进行持久化存储,若后面有节点宕机导致分区数据丢失,则以从做检查点的RDD开始重新计算,不需要从头到尾的计算,从而减少开销。
二、RDD检查点
(一)RDD检查点机制
RDD的检查点机制(Checkpoint)相当于对RDD数据进行快照,可以将经常使用的RDD快照到指定的文件系统中,最好是共享文件系统,例如HDFS。当机器发生故障导致内存或磁盘中的RDD数据丢失时,可以快速从快照中对指定的RDD进行恢复,而不需要根据RDD的依赖关系从头进行计算,大大提高了计算效率。
(二)与RDD持久化的区别
cache()或者persist()是将数据存储于机器本地的内存或磁盘,当机器发生故障时无法进行数据恢复,而检查点是将RDD数据存储于外部的共享文件系统(例如HDFS),共享文件系统的副本机制保证了数据的可靠性。
在Spark应用程序执行结束后,cache()或者persist()存储的数据将被清空,而检查点存储的数据不会受影响,将永久存在,除非手动将其移除。因此,检查点数据可以被下一个Spark应用程序使用,而cache()或者persist()数据只能被当前Spark应用程序使用。
(三)RDD检查点案例演示
在net.xqq.rdd包里创建day06子包,然后在子包里创建CheckPointDemo对象
package net.huawei.rdd.day06
import org.apache.spark.{SparkConf, SparkContext}
object CheckPointDemo {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CheckPointDemo") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 设置检查点数据存储路径(目录会自动创建的)
sc.setCheckpointDir("hdfs://master:9000/spark-ck")
// 基于集合创建RDD
val rdd = sc.makeRDD(List(1, 1, 2, 3, 5, 8, 13))
// 过滤大于或等于5的数据,生成新的RDD
val rdd1 = rdd.filter(_ >= 5)
// 将rdd1持久化到内存
rdd1.cache(); // 相当于无参persist()方法
// 将rdd1标记为检查点
rdd1.checkpoint();
// 第一次行动算子 - 采集数据,将标记为检查点的RDD数据存储到指定位置
val result = rdd1.collect.mkString(", ")
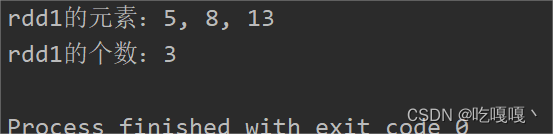
println("rdd1的元素:" + result)
// 第二次行动算子 - 计算个数,直接从缓存里读取rdd1的数据,不用从头计算
val count = rdd1.count
println("rdd1的个数:" + count)
// 停止Spark容器
sc.stop()
}
}
上述代码使用checkpoint()方法将RDD标记为检查点(只是标记,遇到行动算子才会执行)。在第一次行动计算时,被标记为检查点的RDD的数据将以文件的形式保存在setCheckpointDir()方法指定的文件系统目录中,并且该RDD的所有父RDD依赖关系将被移除,因为下一次对该RDD计算时将直接从文件系统中读取数据,而不需要根据依赖关系重新计算。
Spark建议,在将RDD标记为检查点之前,最好将RDD持久化到内存,因为Spark会单独启动一个任务将标记为检查点的RDD的数据写入文件系统,如果RDD的数据已经持久化到了内存,将直接从内存中读取数据,然后进行写入,提高数据写入效率,否则需要重复计算一遍RDD的数据。
运行结果

















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









