




DAY 5 独热编码
题目:离散特征的独热编码
先按照示例代码过一遍,然后完成下列题目
现在在py文件中 一次性处理data数据中所有的连续变量和离散变量
1. 读取data数据
2. 对离散变量进行one-hot编码
3. 对独热编码后的变量转化为int类型
4.对所有缺失值进行填充
1.找出离散变量
import pandas as pd
data = pd.read_csv('data.csv')
data.columns
for discrete_features in data.columns:
if data[discrete_features].dtype == 'object':
print(discrete_features)结果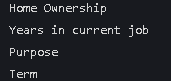
2.打印一下Home Ownership
data['Home Ownership']结果
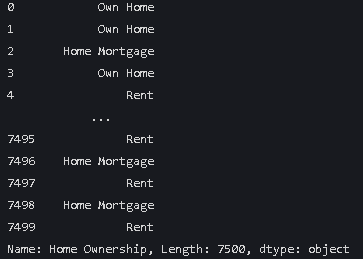
3.统计该列每个类别个数
data['Home Ownership'].value_counts()结果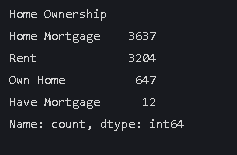
英文含义
4.对该列进行独热编码
data = pd.get_dummies(data, columns=['Home Ownership'])
data.columns结果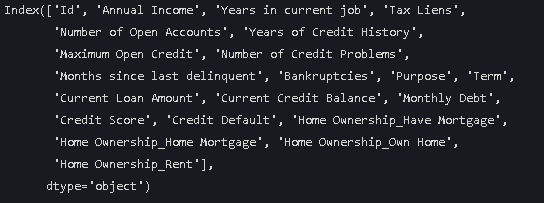
可以看到变成了该列名_Rent 或_Own Home 等 添加了下划线
5.查看一下转换后的数据类型,并将bool型转为int型
data.head()
data['Home Ownership_Have Mortgage'] =data ['Home Ownership_Have Mortgage'].astype(int)
data['Home Ownership_Have Mortgage']6.一次性对所有离散特征进行独热编码
data = pd.read_csv("data.csv")
discrete_lists = []
for discrete_features in data.columns:
if data[discrete_features].dtype == 'object':
discrete_lists.append(discrete_features)
data = pd.get_dummies(data, columns=discrete_lists, drop_first=True)
data.columns打印结果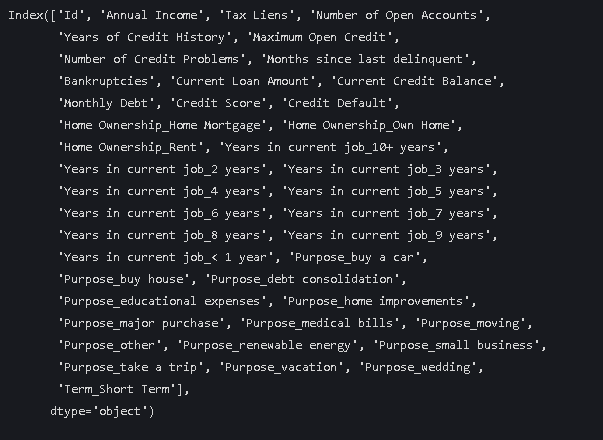
7.难点-如何找到被独热编码的列名
data2 = pd.read_csv("data.csv")
list_final = []
for i in data.columns:
if i not in data2.columns:
list_final.append(i)
list_final结果
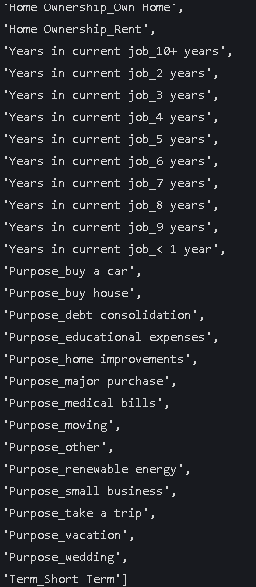
转换一下类型 将bool型转为int型
for i in list_final:
data[i] = data[i].astype(int)
data.head()
















 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









