




 本文介绍了Cortex-A53处理器的顺序执行特点,强调了其8阶段双发射流水线的优势。同时讨论了在顺序流水线中内存屏障的重要性,以及乱序执行如何通过优化内存访问顺序来提升性能。
本文介绍了Cortex-A53处理器的顺序执行特点,强调了其8阶段双发射流水线的优势。同时讨论了在顺序流水线中内存屏障的重要性,以及乱序执行如何通过优化内存访问顺序来提升性能。
Cortex-A53 是顺序执行的还是乱序执行的?CA53 是顺序执行(in-order)的流水线。
The Cortex-A53 processor is Arm’s first Armv8-A processor aimed at providing power-efficient 64-bit processing. It features an
in-order, 8-stage,dual-issuepipeline, and improved integer, Neon, Floating-Point Unit (FPU) and memory performance.
CA53既然是顺序执行的流水线,那么还需要 memory barrier 做什么用?
顺序流水线指的是处理器按照它们在内存中出现的顺序发出指令(issue)。下一条指令不会早于上一条指令发出。 dual-issue pipeline意味着处理器可以同时发出2条指令。
乱序流水线指的是处理器可以不按照指令在内存中的顺序发出(issue)指令。
简单而言,一条指令的执行需要经过取指(fetch)、解码(decode)、发出(issue)。每条指令按照内存中的顺序解码(decode),并按序存储在指令解码缓冲区中(即中央窗口(?))。但是从解码缓冲区中的提取(即发出(issue))可能不是按顺序进行的。
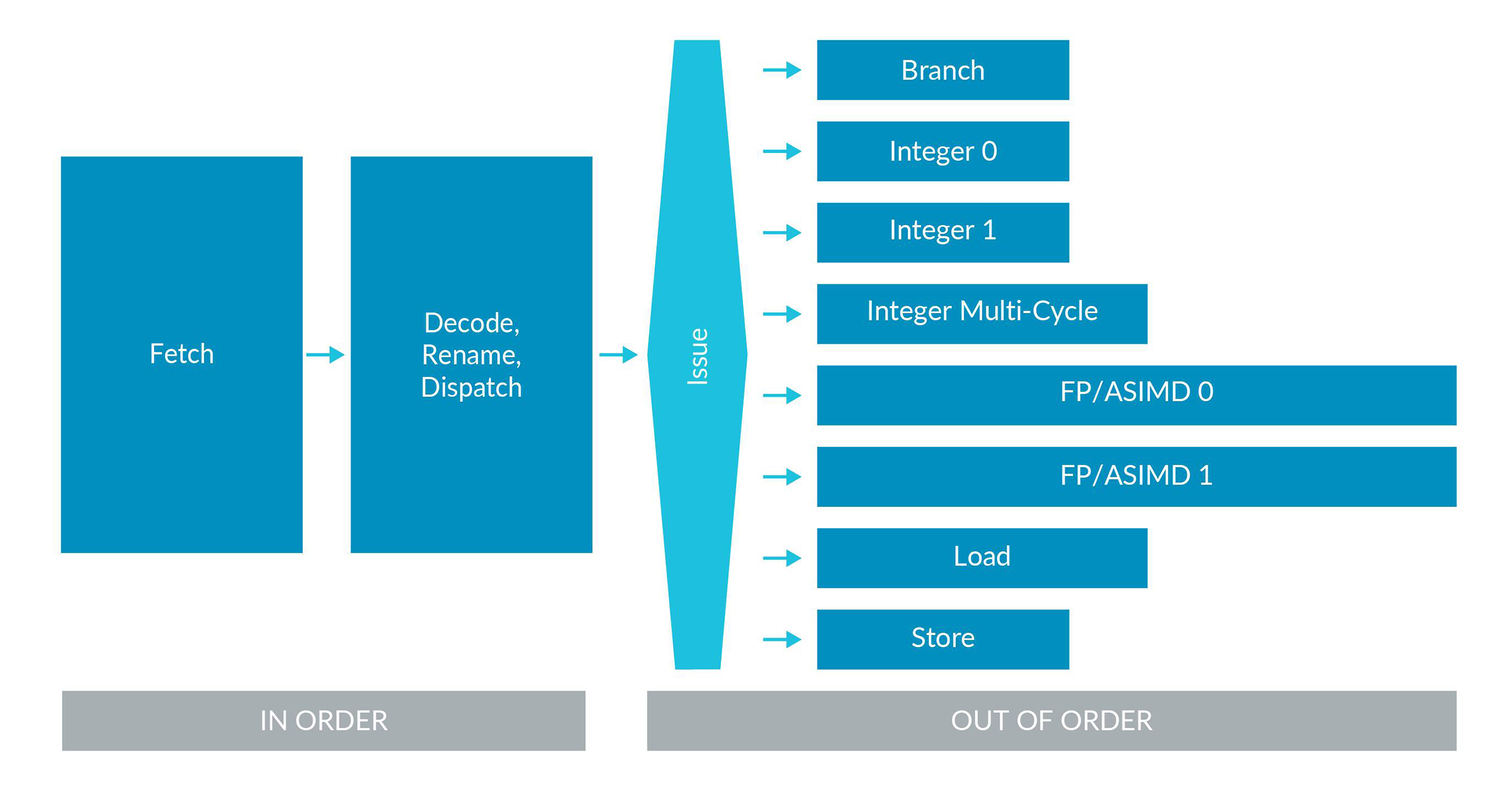
对于顺序流水线,是按序发出的,但是对于乱序流水线,可能就不是按序发出的了。
所以,不管是顺序还是乱序,指的都是issue的顺序。
内存访问顺序(memory ordering)指的是内存访问的顺序。即使在顺序流水线中,多条指令按序发出内存请求,但是响应请求的顺序却可能是不同的。
举个例子:
LDR x1, [x2]
LDR x3, [x4]
ADD x5, x3
在顺序流水线中,这些指令是按序发出。即,第二行指令不会在第一行指令之前发出;第三行指令也不会在第二行指令之前发出。如果支持 multi-issue pipeline,则某些指令可能同时发出,但也不会提前于前面的指令发出。
第二条LDR指令与第一条LDR指令无依赖性,假设读取x2所指向的内存地址发生cache miss,这条指令执行的就会比较久,此时第二条LDR指令就不必等到第一条LDR指令执行完就可以开始执行(issue),此为“内存乱序”。而第三行的ADD指令依赖于前一条LDR,所以它必须要等到前一条指令完成之后才可以执行。
在 cache miss 的情况下,内存乱序可以极大地改善系统性能。
内存屏障(memory barrier)是为了防止某些不符合预期的内存乱序。
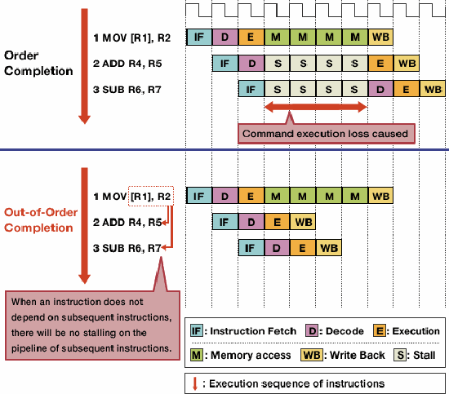
上图也很好地说明了顺序流水线中的乱序执行,MOV指令访问R1所指向的内存耗时较久,ADD指令无需等到MOV指令执行完,直接进入E(Execution,或者叫Issue)阶段。可见乱序执行节省了流水线停顿(Pipeline Stall)的时间。
Reference
- Cortex-A53简介
- Barriers in in-order cores like cortex-A53, A7
- CPU乱序执行原理
- Out-of-Order Architectures
- Pipeline and out-of-order instruction execution optimize performance

















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









