 LangGraph时间旅行与重放实现
LangGraph时间旅行与重放实现




一.背景
LangGraph 作为 LangChain 生态中聚焦大模型应用流程编排与状态管理的核心框架,其 “时间旅行(Time Travel)” 与 “流程重放(Flow Replay)” 能力,是解决企业级大模型流程 “可追溯、可调试、可复现” 的关键特性 —— 本质是通过持久化流程全量状态(节点执行记录、上下文数据、决策路径),实现流程任意历史节点的回溯、状态恢复与重新执行。这一能力的需求源于传统大模型流程编排中 “不可追溯、调试难、故障复现成本高” 的核心痛点,也是 LangGraph 适配企业级生产环境 “可运维、可审计、可优化” 诉求的核心支撑。
1.传统大模型流程编排的核心痛点
在 LangGraph 出现前,企业级大模型流程(如多智能体协作、多轮对话、复杂业务决策流程)的编排多依赖简单脚本、无状态状态机或自研轻量框架,这类方式完全缺失 “时间旅行与流程重放” 能力,导致以下核心问题:
1. 流程执行不可追溯,故障排查无依据
大模型流程执行过程中,节点间的状态流转、大模型的调用参数 / 返回结果、决策分支的触发条件等信息均无结构化存储:例如多智能体合同审查流程执行失败后,无法定位是 “条款提取节点数据错误”“风险评估节点大模型输出异常” 还是 “人工审核节点操作失误”;仅能通过零散的日志(若有)推测问题,排查周期长、效率低,尤其在复杂流程(10 + 节点)中,几乎无法还原故障现场。
2. 流程调试成本高,无法复现历史问题
传统流程执行后状态立即丢失,若用户反馈 “某一次流程执行结果错误”(如智能客服回复偏离意图、数据分析结果错误),开发人员无法复现当时的流程上下文(如用户输入、节点执行顺序、大模型返回内容),只能凭记忆重构场景,导致调试不精准、问题无法根治;且无法对比 “正常流程” 与 “异常流程” 的执行差异,优化方向不明确。
3. 无流程回溯能力,人机协同效率低
在人机协同场景中(如大模型处理→人工介入→继续执行),若人工操作失误(如审核结论错误),传统流程无法回溯至 “人工介入前” 的状态重新处理,只能从头执行整个流程,浪费大量计算资源与时间;例如智能合同审查流程中,法务人员误判风险条款后,需重新执行 “文本提取→条款解析→风险识别” 所有步骤,效率降低 80% 以上。
4. 合规审计缺失,无法满足监管要求
金融、政企等行业对大模型流程执行有严格的合规审计要求:需记录 “流程执行全链路、每个节点的操作人 / 时间 / 结果、状态变更原因”,并支持回溯任意历史版本的流程执行记录。但传统流程无状态持久化能力,无法提供完整的审计链路,易引发合规风险。
5. 流程优化无数据支撑,迭代效率低
企业需基于历史流程执行数据优化大模型流程(如调整节点顺序、优化 Prompt、更换大模型),但传统流程无法统计 “哪些节点执行耗时最长”“哪些决策分支易出错”“大模型调用失败集中在哪些场景”,只能凭经验优化,缺乏数据支撑,迭代效果差。
2.LangGraph 时间旅行与重放流程的核心价值
LangGraph 基于 “检查点(Checkpoint)” 机制实现全流程状态持久化(支持本地存储、Redis、PostgreSQL、云存储等),结合 “状态回溯 + 流程重放” 能力,解决传统流程的核心痛点,核心价值体现在:
1. 全流程状态追溯,降低故障排查成本
LangGraph 会在每个节点执行完成后自动生成 “检查点”,持久化存储:
- 流程基本信息:流程 ID、执行时间、当前节点、分支决策依据;
- 上下文数据:用户输入、大模型调用参数 / 返回结果、节点输出数据;
- 系统状态:资源占用、大模型 API 调用状态、异常信息(若有)。通过 “时间旅行” 能力,可一键回溯任意检查点的状态,清晰还原流程执行全链路:例如排查故障时,可直接查看 “第 5 个节点执行时的大模型返回内容”“某分支触发的具体条件”,快速定位根因,排查效率提升 90% 以上。
2. 精准复现历史流程,提升调试效率
基于持久化的检查点,LangGraph 支持 “流程重放”:从任意历史检查点恢复状态,重新执行后续流程(可修改节点逻辑、大模型参数、上下文数据)。例如用户反馈 “3 小时前的智能客服回复错误”,开发人员可加载当时的检查点,复现完整的对话流程,并在重放过程中修改 Prompt 或节点逻辑,验证优化效果,无需重构场景,调试精准度大幅提升。
3. 灵活的流程回溯,支撑人机协同优化
在人机协同场景中,若人工操作失误或大模型执行结果不符合预期,可通过 “时间旅行” 回溯至错误节点前的检查点,修正问题后重新执行后续流程,无需从头开始:例如合同审查流程中,法务人员发现 “风险评估节点结论错误”,可回溯至该节点前的状态,重新调整评估规则后重放流程,避免重复执行前置步骤,提升人机协同效率。
4. 完整审计链路,满足合规管控要求
LangGraph 的检查点记录了流程执行的全量信息(操作人、时间、节点结果、状态变更),可生成标准化的审计报告:例如金融行业的风控决策流程,可回溯任意时间点的 “风控规则触发条件、大模型风险评分、人工审批意见”,满足等保三级、GDPR 等合规要求;同时支持权限管控,仅授权人员可查看 / 回溯敏感流程的执行记录。
5. 基于历史数据优化流程,驱动迭代升级
通过分析历史流程的重放数据,可统计关键指标:
- 节点维度:各节点执行耗时、失败率、大模型调用成本;
- 决策维度:各分支触发频率、错误率;
- 结果维度:流程输出准确率、用户满意度。基于这些数据,可精准优化流程(如拆分耗时节点、调整分支条件、替换低效率大模型),实现流程的持续迭代,而非凭经验优化。
3.典型应用场景
- 企业级智能客服流程:用户反馈某一次对话回复错误,通过时间旅行回溯对话流程的所有检查点,复现当时的用户输入、大模型返回内容,优化 Prompt 后重放流程验证效果;若人工坐席转接失误,可回溯至转接前的状态重新处理。
- 多智能体数据分析流程:大数据分析流程执行失败(如数据提取错误、大模型总结偏差),通过时间旅行定位故障节点,修改节点逻辑后重放流程,验证修复效果,无需重新执行全量数据处理步骤。
- 智能合同审查流程:法务人员审核后发现流程执行结果错误,回溯至风险识别节点前的状态,调整风险评估规则后重放流程,快速生成正确的审查报告。
- 大模型应用运维监控:运维人员定期重放高耗时 / 高失败率的流程,分析节点瓶颈(如大模型 API 调用超时、数据解析效率低),优化流程架构或资源配置。
- 合规审计与风险追溯:金融风控流程中,监管机构核查某笔交易的风控决策过程,通过时间旅行回溯完整的流程执行记录(规则触发、大模型评分、人工审批),提供可追溯的合规证据。
4.关键优势总结
LangGraph 时间旅行与重放流程的核心价值,是将大模型流程从 “一次性、不可追溯的黑盒执行” 转化为 “可记录、可回溯、可复现的透明流程”:既解决了传统流程 “排查难、调试难、合规难” 的痛点,又通过流程重放支撑人机协同优化与数据驱动的流程迭代,是 LangGraph 适配企业级生产环境的核心竞争力。这一能力让大模型应用从 “演示级原型” 走向 “可运维、可审计、可优化的生产级应用”,大幅降低企业落地大模型流程的运维成本与合规风险。
综上,LangGraph 时间旅行与重放流程的需求,源于企业对大模型流程 “可追溯、可调试、可合规” 的核心诉求:解决了传统流程编排无状态、无回溯能力的痛点,支撑故障排查、人机协同、合规审计、流程优化等企业级核心场景,为复杂大模型流程的稳定落地与持续迭代提供了高效、可靠的技术路径。
二.具体实现
1.添加依赖
import sys
import io
# 设置标准输出编码为UTF-8,解决Windows中文乱码问题
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
from IPython.display import Image, display
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.graph.state import CompiledStateGraph
from typing_extensions import TypedDict
import threading
import time
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
from langgraph.types import interrupt
from langgraph.types import Command
from langgraph.checkpoint.memory import MemorySaver
2.定义状态类
# 1. 定义状态
class EventState(TypedDict):
count_status: int #累计计数状态
3.定义节点1-5
def t1_node(state: EventState) -> EventState:
state["count_status"] += 1
print("当前节点:t1_node")
return state
def t2_node(state: EventState) -> EventState:
state["count_status"] += 1
print("当前节点:t2_node")
return state
def t3_node(state: EventState) -> EventState:
state["count_status"] += 1
print("当前节点:t3_node")
return state
def t4_node(state: EventState) -> EventState:
state["count_status"] += 1
print("当前节点:t4_node")
return state
def t5_node(state: EventState) -> EventState:
state["count_status"] += 1
print("当前节点:t5_node")
return state
4.构建图
# 创建事件流
graph = StateGraph(EventState)
graph.add_node("t1_node", t1_node)
graph.add_node("t2_node", t2_node)
graph.add_node("t3_node", t3_node)
graph.add_node("t4_node", t4_node)
graph.add_node("t5_node", t5_node)
graph.add_edge(START, "t1_node")
graph.add_edge("t1_node", "t2_node")
graph.add_edge("t2_node", "t3_node")
graph.add_edge("t3_node", "t4_node")
graph.add_edge("t4_node", "t5_node")
graph.add_edge("t5_node", END)
memory = MemorySaver()
graph = graph.compile(checkpointer=memory)
5.执行图流程
# 初始化状态
state = {"count_status": 0}
config = {"configurable": {"thread_id": "thread-123"}}
rs = graph.invoke(state, config=config)
print(rs)
结果如下:
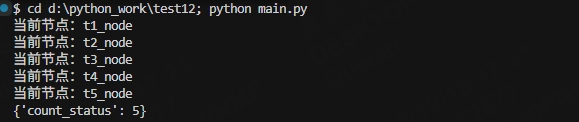
6.打印所有的快照
states = list(graph.get_state_history(config))
for state in states:
print(state.next)
print(state.config["configurable"]["checkpoint_id"])
print()
结果如下:
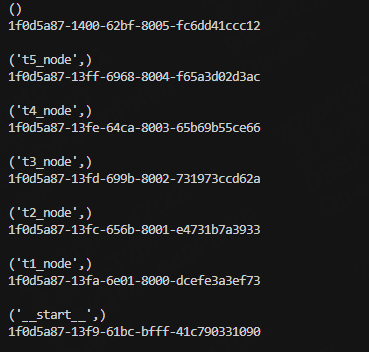
7.从第三个节点开始构建新的快照并更新状态信息
new_config = graph.update_state(states[3].config, values={'count_status': 100})
print(new_config)
结果如下:
![]()
8.从新快照开始执行
rs2 = graph.invoke(None, new_config)
print(rs2)
结果如下:
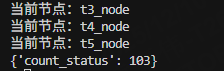


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











