




代码链接:Analogical-Reasoning
传统目标检测
RCNN
1. Selective Search:初始分割+相似区域(颜色、纹理)合并,生成候选框(约2000个)
2. 特征提取:对所有候选框进行裁剪缩放,输入到CNN中提取特征
3. 分类:将所有候选框特征送进多个SVM分类器(二分类模型),选择置信度最高的类别
4. 边界框回归:对正样本(IoU较高)的候选框做线性回归,修正框的大小和位置,让预测更接近目标真实边界
Faster RCNN
相对于普通RCNN:引入了RPN(Region Proposal Network)
1. 直接对整张图片进行特征提取
2. 生成候选框(RPN):判断anchor内是否有目标(置信度)+偏移量
3. Rol Pooling:把不同大小的候选框区域映射到特征图上,并池化成固定大小
4. 根据特征图得到类别
Yolo
1. 缩放图像到固定大小,特征提取(DarkNet)
2. 把图像分割成S*S的网格,每个网格负责预测落在该网格中心的物体
3. 预测内容(每个网格):
B个边界框:中心坐标(x,y)、高宽(w,h)
置信度:边界框内包含物体的置信度(P*IoU,预测框和真实框的交并比)
C个类别概率分布:每个已知类别的概率
输出张量:S*S*(B*5+C)(后续优化了边界框的参数化和解码方式:Anchor Box+偏移量,多尺度(分辨率)预测,损失函数优化)
4. 组合预测结果:对于一个边界框的Class Confidence=confidence * P(Class|Object)
5. NMS非极大值抑制:选取分数最高的检测框去掉与它IoU大于阈值的其它框,循环直至没有候选框
前言
卫星遥感图像检测的挑战:物体尺寸较小,动态背景
目前解决方向
1. 区域划分+局部放大,提升密集目标检测效果
2. 增加网络结构模块以提升特征提取效果(注意力机制/多尺度特征融合)
高分辨率:保留更多细节,但语义信息弱
低分辨率:目标位置模糊,但语义信息强
3. 图像增强技术
Related Works
1.1 ClusDet
先通过类似Faster-RCNN的方式生成集群区域检测框,得到映射后的特征图(Rol Pooling),对该集群区域进行检测,与全局检测结果进行NMS
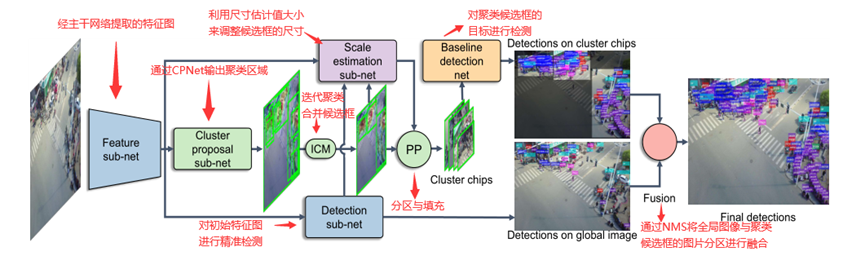
1.2 Casceded zoom-in
添加“crop”类,截取图像中物体密集区域标注为新类别,上采样后与原始图像一起加入训练,多级级联获得更详细子图。在推理时类似:识别基础类别物体与物体密集区,对高质量物体密集区(IoU合并结果)上采样后推理,合并检测结果
———————————————————————————————————————————
一点想法:先通过人工标注的物体密集区训练一个大模型,在该训练过程中,模型会截取物体密集区域并做裁剪、上采样等操作并合成为一个新的数据集,该数据集作为无监督学习/弱监督学习数据集在刚才的大模型基础上做微调。(大模型打伪标签/对比学习/半监督)
三路结构:
Backbone路:在无标注数据上做自监督预训练,学习图像特征,得到backbone初始化权重
Cluster路:训练Cluster Proposal Net:用少量密集区标注学习哪里有目标簇,裁切、上采样,生成密集区子图
Instance路:用少量实例级标注训练初始Teacher,Teacher给密集区子图&原图打伪标签用于Student半监督学习
训练阶段:
1. 自监督预训练(MAE/对比学习)
2. 双头监督预热:CPN头和Instance检测头,训练框簇预测模型和实例预测模型(Teacher v0)
3. 生成伪标签:CPN在无标签图上做预测+上采样获得子图,Teacher分别在原图和子图做推理,得到候选框做NMS作为伪标签
4. 半监督Student训练:监督损失(有标注)+无监督损失(未标注+弱标注)训练Student;Teacher更新
5. 迭代自训练:用当前更新的Teacher刷新伪标签,再训练
———————————————————————————————————————————
1.3 Adazoom
基于强化学习。
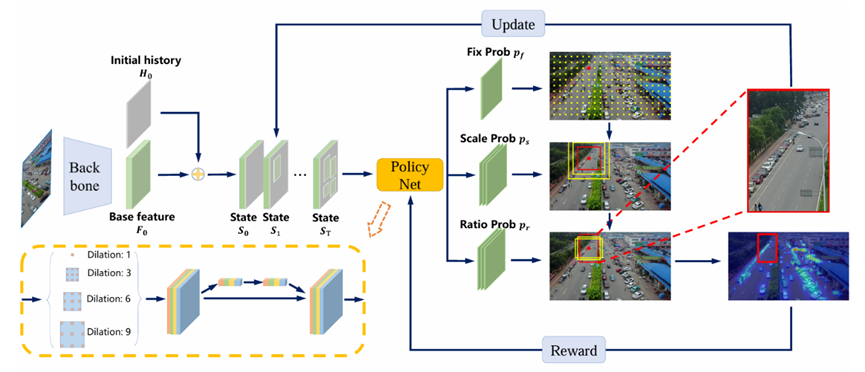
状态State:基础特征图+历史信息图(记录已被采样的区域)
动作Action:PolicyNet:动作被解耦为三类分量:Fixation(定位)、Scale(尺度)、Aspect ratio(长宽比);分别预测作为focus区域并用policy gradient优化
奖励Reward:对落在focus region内每个目标赋予权重(小目标高权重),region大尺度(与目标尺度相比)会被赋予系数衰减
检测网络:在原图和AdaZoom生成并放大的region上做检测;AdaZoom生成对检测有帮助的区域,检测器的输出反过来调整AdaZoom的reward(对检测器容易错过或置信度低的真实目标增加权重)
2.1 TPH-Yolo v5
在Yolo v5的基础上引入了注意力模块和多尺度融合
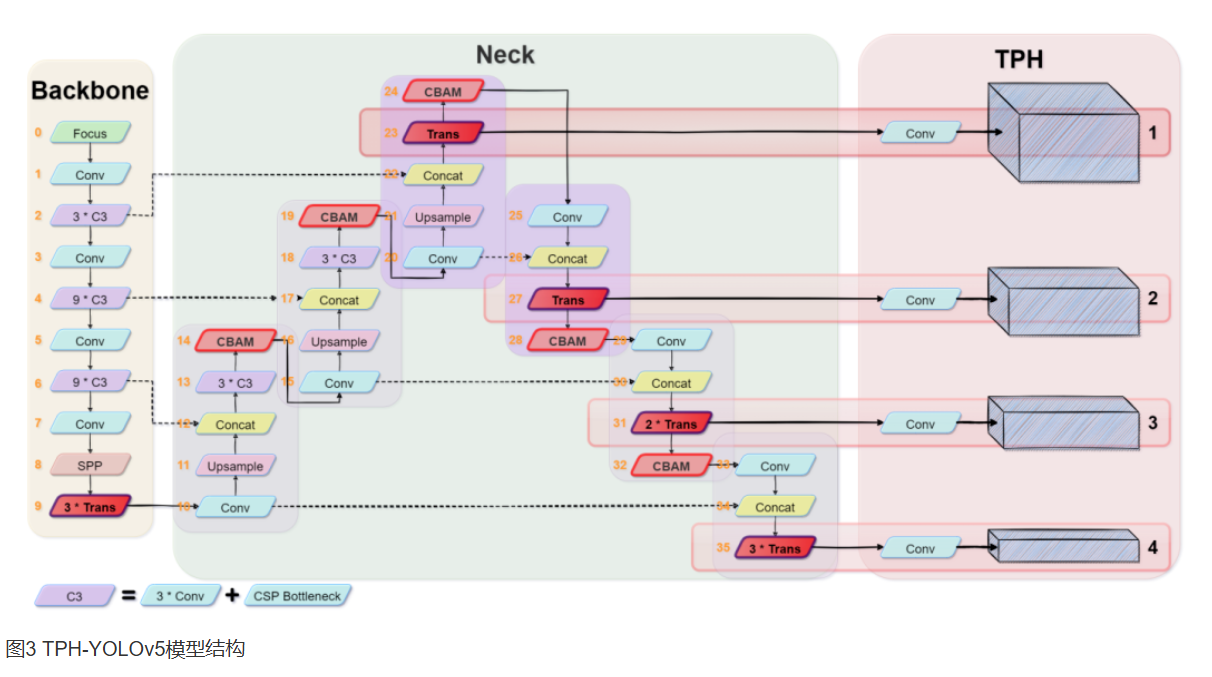
Backbone
Focus:把图片切分成4个部分并堆叠,类似对一张图片的Mosaic
Conv+C3(CSP Bottleneck):卷积层+跨阶段部分残差结构,提取特征
SPP:多尺度池化
Trans:用Transformer层代替部分卷积块,增强全局建模
Neck
Upsample+Concat:上采样+与浅层特征拼接
CBAM:通道注意力+空间注意力;输入特征按通道加权


TPH
在检测头中引入Transformer层:图像C、H、W(通道数、高度、宽度)展平成N*C(N=H*W),相当于一段长度为通道数的序列,每个“词”的维度数是图片像素数量
———————————————————————————————————————————
(基础知识学习)
1. 数据增强方法:扩展数据集,提升模型泛化能力。包括:Photometric(对图像色相、饱和度进行调整)、Geometric(对图像随机缩放、平移、裁剪、旋转等)、MixUp(通过线性插值生成新的图像和标签)、CutMix(切割并拼接两张图像的不同区域生成新的训练样本,混合标签)、Mosaic(将四张不同的图像按一定比例拼接成新的图像,调整标签)
2. 目标检测结果混合方法:多模型检测结果合并。包括:非极大值抑制(NMS)、Soft-NMS(根据IoU值对相邻边界box的置信度设衰减函数,而不是直接将其删除)、Weighted Boxes Fusion(WBF,通过加权平均来融合候选框,而不是抛弃)
3. 基于CNN的物体检测分类:
(1)One-Stage检测器:直接在图像的每个位置做端到端预测,无需生成候选框,例如Yolo v3
(2)Two-Stage检测器:先生成一组候选框,再对框进行精细预测,例如Faster-RCNN
(3)Anchor-Based检测器:使用预设的多尺度锚框,每个锚框代表一个潜在目标的位置, 训练尺度和比例,例如Scaled-Yolo v4、Yolo v5等
(4)Anchor-Free检测器:无需锚框,直接通过像素位置进行目标预测,例如YoloX
(5)无人机专用检测器:RRNet、PENet、CenterNet等
4. 检测器的组成
(1)Backbone:特征提取
(2)Neck:负责对特征图进行处理、融合和强化,包括:多尺度特征融合、通过额外层(自注意力层等)提高模型在复杂场景的辨识能力
(3)Head:检测头,输出目标类别和边界框
———————————————————————————————————————————
2.2 Sifdal
SIFDAL 利用通道拆分 + 对抗训练让模型分别学习“scale-related”(与尺度相关)和“scale-invariant”(与尺度无关)的特征,增强小目标检测对尺度变化的鲁棒
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















&spm=1001.2101.3001.5002&articleId=151116764&d=1&t=3&u=0e936f65050e4d07985817b4b4ad1762)
 2930
2930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









