



MoPKL与SPAR都引入了文本模态+构图的思路来解决小目标难以检测的问题,具体来说:
SPAR:
将视觉特征与文本进行交互:SPAR将多尺度特征concat,对文本与图像做多头交叉注意力,这一步相当于将图像特征融入到文本描述中;后续再通过更新后的文本嵌入对图像像素特征进行更新,使特征图也包含文本的语义信息。
构图:SPAR从特征图中选出M个高分区域,表示“最容易识别,语义最明确”的特征;将M个像素节点与类别节点构图;通过计算节点的相似度构建归一化邻接矩阵,表示节点相连信息;依据此邻接矩阵更新图;最后回写特征图进行更新。
类比推理逻辑的实现:Self-prompting阶段模型已经初步建立了图像-文本的对齐;图卷积部分,模型把容易节点的特征与语义信息融合,使语义得到全局特征的更新;在检测时,困难目标会吸收高分区域传来的语义信息,实现“类比推理”。
MoPKL
构建文本描述:将图像划分网格,每个网格找到可能目标并计算两帧间的速度和方向,拼成模板句子并构成文本嵌入。
视觉特征与文本描述对齐:相较于SPAR模型中将交互后的文本节点与像素节点一起加入图的做法,MoPKL采取了将视觉特征与文本描述融合的方式。模型选取最相近的节点进行加权融合,得到了新的跨模态节点。
建边思路:利用帧间差分与互信息(单帧熵与联合熵)得到图中网格块的运动信息,选择出运动信息值最高的N块(更可能包含运动小目标),通过计算马氏距离来表示块间相关关系(运动模式相似的块构建边)。
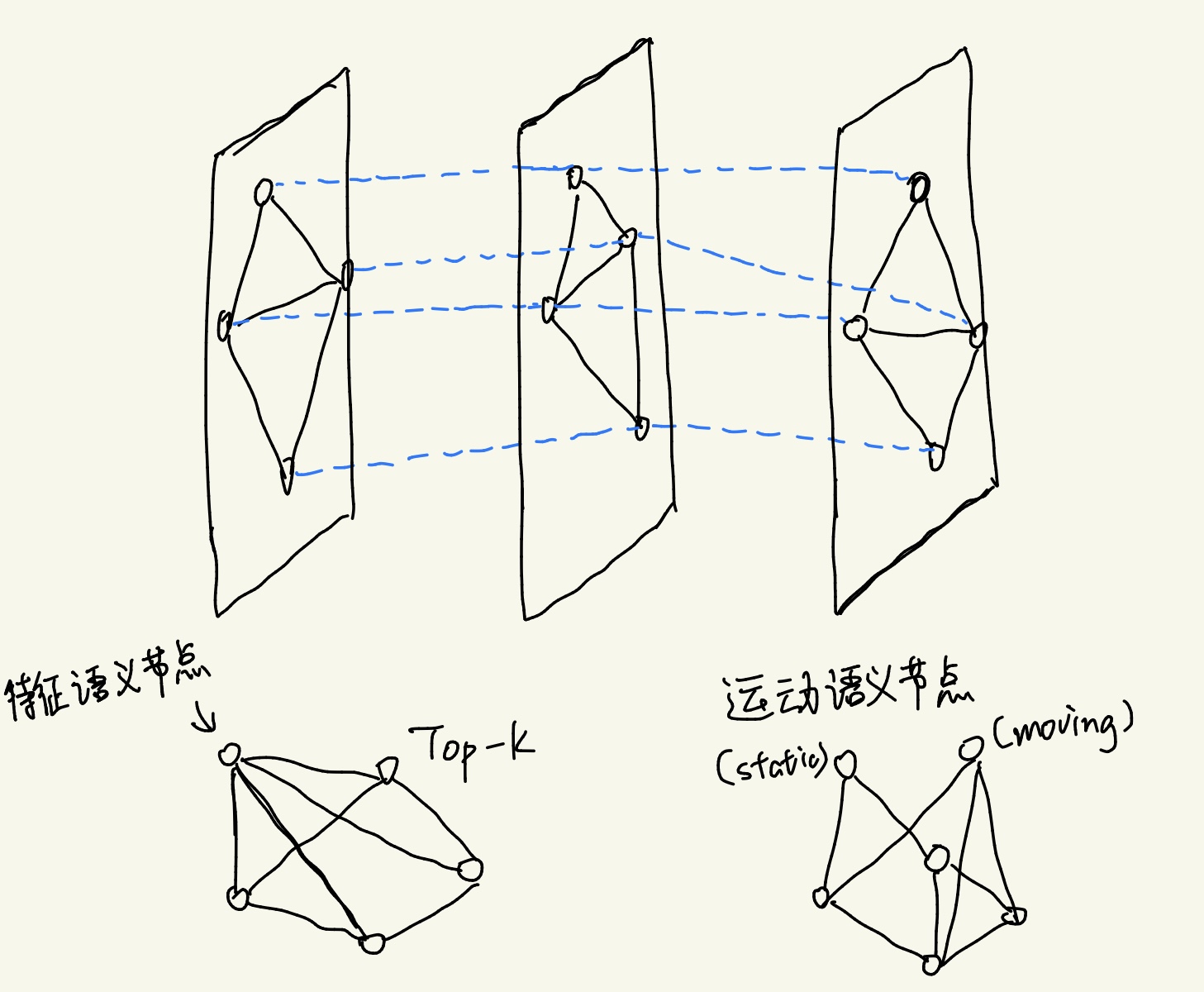
构图:跨模态节点与块间相关关系构图
语言先验逻辑:用先验约束视觉特征,减少噪声;提供运动语义信息,弥补小目标外观不足。
一些想法
1. 输入结构:三维时空特征
空间维度(H,W):每一帧经过backbone得到的特征图;
时间维度(T):图像序列跨帧信息
2. 提取高置信度候选区域:帧差分/光流,选取Top-k置信度候选框
3. 语义建模:与类别prompt交互
文本prompt:例如“a small moving vehicle on the road“
对Top-k区域做图像特征-文本嵌入交互,得到更新后的图像特征和携带图像上下文的文本描述
4. 运动建模:轨迹特征提取
在时间维度对候选区域做多目标跟踪,生成每个候选框的轨迹
轨迹编码:编码运动模式(匀快慢速/加速/直线/曲线/抖动),得到文本embedding
5. 类比推理
(1)语义图,节点为Top-k候选区域特征+类别文本嵌入;边由视觉相似度+类别语义相似度决定
(2)运动图,节点为Top-k候选框运动特征+运动逻辑嵌入;边由轨迹相似度决定
融合两张图的更新结果,使得弱小目标能获得来自大目标的类别+运动双重语义补强。

















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









