






构建企业级 RAG 知识库:从向量存储到全链路护栏
在当今的大模型应用开发中,RAG(Retrieval-Augmented Generation,检索增强生成)已成为构建垂直领域智能应用的主流范式。然而,从一个简单的 Demo 到一个真正的企业级知识库,中间隔着复杂的工程化架构。
本文将基于通用的企业级 RAG 架构图,结合实际业务场景,深入解析一个高可用知识库系统的核心要素,并重点探讨生产环境中的实际案例与技术选型对比。
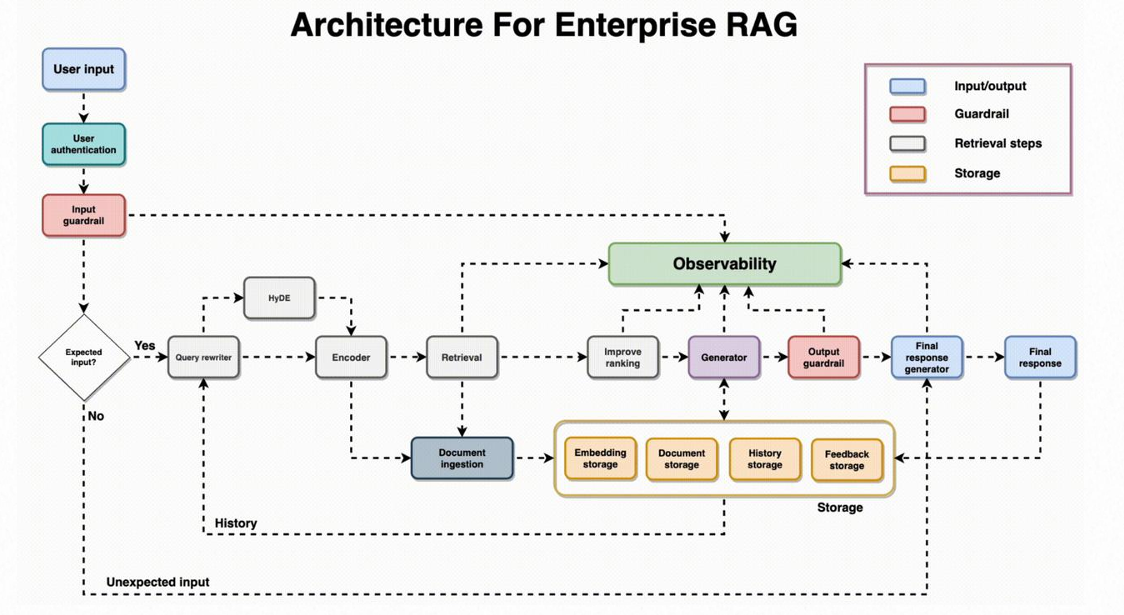
1. 入口层的安全与控制:权限与护栏
一切始于用户的输入,但在我们将问题抛给大模型之前,必须经过两道“关卡”。
用户权限校验 (User Authentication)
在企业环境中,并不是所有数据对所有人都是可见的。权限控制是业务落地的第一步。
💡 生产实战案例
场景:企业内部 HR 助手
- 普通员工询问:“公司的年假政策是怎样的?” -> 允许访问员工手册知识库。
- 普通员工询问:“CEO 的具体薪资是多少?” -> 拒绝访问高管薪酬数据库。
- 实现方式:在检索阶段前,先获取用户的
Role(角色)标签,构建 Filter(过滤器),确保用户只能在即得权限的文档切片中进行检索。
输入护栏 (Input Guardrail)
权限校验通过后,紧接着是输入护栏。它的核心作用是检测用户输入的合法性,防止 Prompt Injection(提示词注入)或恶意攻击。
⚖️ 方案横向对比
| 方案类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 规则/正则匹配 | 敏感词过滤、固定攻击模式拦截 | 响应极快,成本几乎为零 | 泛化能力差,容易被“绕过” |
| 小模型分类 (BERT等) | 识别情感、意图、甚至越狱尝试 | 速度较快,准确率优于规则 | 需要专门训练数据 |
| 大模型检测 (LLM-Guard) | 复杂的逻辑判断、隐含恶意检测 | 理解能力最强,防守全面 | 延迟高,Token 成本高 |
建议:生产环境中通常采用**“漏斗式”组合策略**,先用正则过滤掉 90% 的明显攻击,再用小模型处理剩下的 10%。
2. 提升理解力:查询重写与上下文
用户的提问往往是模糊或缺乏背景的。直接拿去检索,效果通常不佳。因此,我们需要对问题进行重写(Query Rewriting)。
结合上下文 (Context) 与意图识别
重写不仅仅是简单的拼接提示词,更重要的是利用上下文将用户的“短语”还原为“完整问题”。
💡 生产实战案例
场景:电商售后客服
- 用户第一句:“我上周买的联想小新 Pro 14 怎么开机没反应?”
- 用户第二句:“这就坏了?”
- 原始检索:“这就坏了?” -> 检索结果可能是完全无关的通用故障。
- 重写后:“用户购买的联想小新 Pro 14 笔记本电脑出现开机无反应的情况,这是质量问题吗?” -> 精准命中电源管理或退换货政策文档。
⚖️ 重写方案对比
| 方案 | 描述 | 优势 | 劣势 |
|---|---|---|---|
| 历史拼接 | 直接将历史对话作为 Context 扔给 LLM | 简单粗暴,实现最快 | 容易超出 Token 限制,包含大量噪声 |
| LLM 重写 | 专门调用一次 LLM 将多轮对话总结为单句 Query | 语义最精准,检索效果最好 | 增加了系统的整体延迟(需额外一次 LLM 调用) |
| HyDE (假设性文档嵌入) | 让 LLM 假设生成一段答案,用答案去检索文档 | 极大提高召回率,适合难检索问题 | 幻觉风险可能导致检索偏离 |
3. 核心引擎:向量化与检索
问题明确后,进入了 RAG 的心脏地带——检索层。
混合检索与重排序 (Hybrid Search & Rerank)
单一的向量检索(Dense Retrieval)并不完美,特别是对于专有名词或精确数字的匹配。
💡 生产实战案例
场景:工业设备维护知识库
- 查询:“报错代码 ERR-2024-X5 怎么解决?”
- 纯向量检索:可能会找来一堆关于“错误处理流程”的通用文档,因为语义相似,但没抓准那个具体的代码。
- 混合检索:结合**倒排索引(Keyword Search)**强制匹配
ERR-2024-X5,同时用向量匹配“解决办法”,准确率提升 40% 以上。
⚖️ 检索链路对比
| 阶段 | 常用技术 | 作用 |
|---|---|---|
| 初排 (Retrieval) | 向量检索 (Faiss/Milvus) + 关键词 (BM25/ES) | 广撒网:快速从百万文档中捞出 Top 100 |
| 精排 (Rerank) | Cross-Encoder (如 BGE-Reranker, Cohere) | 优中选优:对 Top 100 进行深度语义打分,选出 Top 3 |
4. 系统的基石:全能存储引擎
在整个架构中,存储引擎(Storage Engine)不仅仅是一个数据库,而是一个复合的存储体系。
存储架构设计
我们的数据库通常包含以下四类数据:
- Embedding Storage:向量数据。
- Document Storage:原始文本。
- History Storage:会话记录。
- Feedback Storage:用户反馈(点赞/点踩)。
⚖️ 存储选型横向对比
| 方案类型 | 代表产品 | 适用场景 | 生产建议 |
|---|---|---|---|
| 专用向量数据库 | Milvus, Pinecone, Weaviate, Chroma | 亿级以上海量数据,对延迟要求极高 | 适合大规模、高性能要求的核心知识库 |
| 传统数据库扩展 | PostgreSQL (pgvector), Elasticsearch | 中小规模数据,希望架构简单,统一运维 | 大多数中小企业首选,由于不用维护两套数据库,运维成本最低 |
| 内存型 | Redis (RediSearch) | 极速响应,实时性要求高 | 适合作为缓存层或高频热点知识的存储 |
5. 输出层的最后一道防线
当大模型根据检索到的信息生成了答案后,流程并没有结束。
输出护栏 (Output Guardrail) 与反馈闭环
模型可能会产生幻觉,或者因为即使输入合规但输出了不当内容。
💡 生产实战案例
场景:金融投资顾问 Bot
- LLM 生成:“根据目前趋势,比特币一定会涨到 10 万,建议您现在 All-in。”
- 输出护栏:检测到“建议 All-in”、“一定”等绝对化投资建议词汇,拦截输出,并替换为“市场有风险,投资需谨慎,建议咨询专业理财师。”
用户反馈 (User Feedback)
上线后的用户反馈(点赞/点踩/修改建议)是系统进化的关键。
- Data Flywheel(数据飞轮):将用户点踩的 Query + 错误 Answer + 正确文档 存入Feedback Storage,定期用于微调(Fine-tune)Embedding 模型或优化 Prompt。
总结
构建一个企业级的 RAG 知识库,绝不仅仅是调通一个 API 那么简单。
- 在入口层,我们要像做传统 Web 安全一样做权限和护栏。
- 在处理层,我们要权衡“重写”带来的延迟和“上下文”带来的精准度。
- 在检索层,混合检索 + 重排序(Rerank)几乎是生产环境的标配。
- 在存储层,选择适合自己数据量级的数据库方案至关重要。
只有建立起包含输入输出护栏、智能重写机制以及强大的存储引擎的完整架构,才能真正发挥大模型在业务中的价值。

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









