







 本文介绍了多分类学习的三种基本策略:一对一(OVO)、一对其余(OVR)和多对多(MVM),并详细阐述了OVO与OVR的优缺点。此外,还探讨了纠错输出码(ECOC)方法及其容错能力。最后,文章提到了类别不平衡问题,提出了欠采样、过采样和阈值移动等解决策略。
本文介绍了多分类学习的三种基本策略:一对一(OVO)、一对其余(OVR)和多对多(MVM),并详细阐述了OVO与OVR的优缺点。此外,还探讨了纠错输出码(ECOC)方法及其容错能力。最后,文章提到了类别不平衡问题,提出了欠采样、过采样和阈值移动等解决策略。
多分类学习,考虑N个类别C1,C2,…CNC1,C2,…CN,多分类学习的基本思想就是:
将多分类任务拆为若干个二分类任务求解。
先对问题进行拆分,拆出的每个二分类任务训练一个分类器,在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。
最经典的拆分策略有三种:
- 一对一(OVO),对于N分类学习,OVO将这N个类别两两配对,从而产生N(N−1)/2N(N−1)/2个二分类任务,在测试阶段,新样本同时提交给所有分类器,于是我们将得到N(N−1)/2N(N−1)/2个分类结果,最终结果将由投票产生。
- 一对其余(OVR),每次将一个类的样例作为正例、所有其他类的样例作为反例来训练N个分类器,在测试时,如果仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果,若有多个分类器预测为正类,通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为最终分类结果。
- 多对多(MVM),每次将若干类作为正类,将若干类作为反类,OVO和OVR是MVM的特例!正反类不能随便选!一种常用的MVM技术:纠错输出码(ECOC)
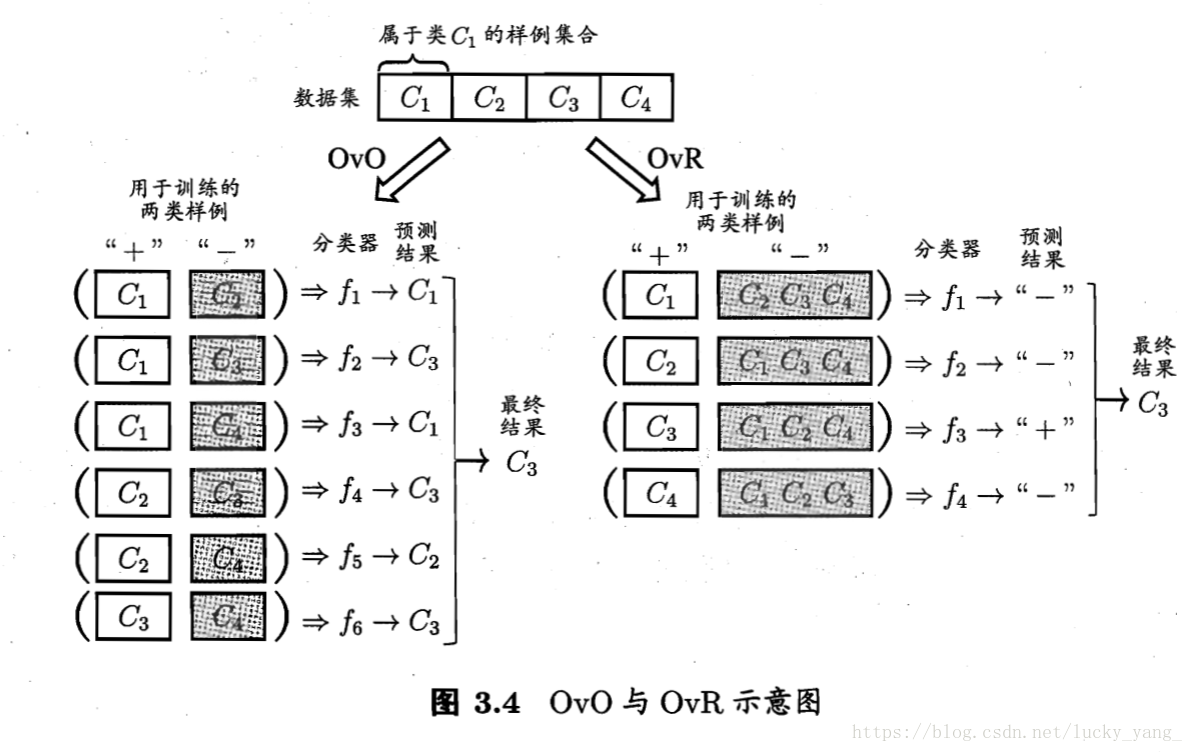
比较OVO和OVR:OVO的存储开销和测试时间开销通常比OVR更大。在类别很多时,OVO的训练时间开销比OVR更小(OVO每个分类器仅用两个类的样例,OVR中每次都用全部训练样例)。
ECOC是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性:
- 编码:对N个类做M次划分,每次划分将一部分类别划分为正类,一部分划分为反类,从而形成一个二分类训练集;这样一共产生M个训练集,训练出M个分类器。
- 解码:M个分类器分别对测试样本进行预测,这M个预测标记组成一个编码,这个预测编码与每个类别各自的编码进行比较
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









