



我们已经知道如何使用线性模型进行回归学习,如果要做分类任务呢?
广义线性模型:y=g−1(wTx+b)y=g−1(wTx+b)
现在只需找到一个单调可微函数g−1g−1将分类任务的真实标记yy与线性回归模型的预测值联系起来.
考虑二分类任务,y∈{0,1}y∈{0,1},z=wTx+bz=wTx+b 是实值,将实值z转化微0/1值,最理想的是单位跃进函数
但是单位跃进函数不连续,不是我们要找的g−1g−1,所以要找一个在一定程度上近似单位跃进函数的单调可微的函数,就是对数几率函数(logistic function)
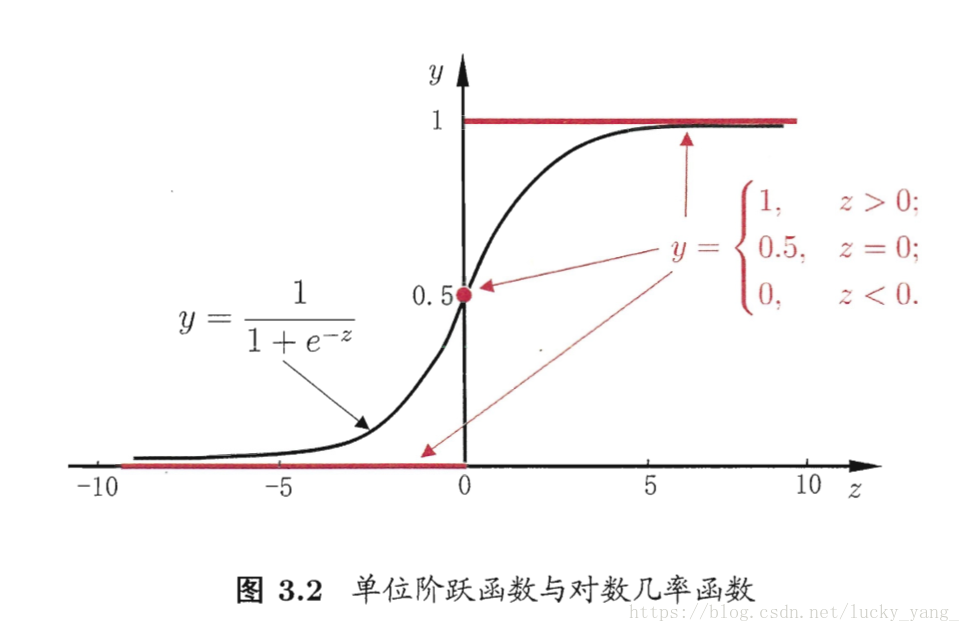
从图中可以看到,对数几率函数是一种sigmoid函数(形似S的函数)
将对数几率函数作为g−1g−1,得到
做变换后:
若将y视作x作为正例的可能性,则1-y是x作为反例的可能性,y1−yy1−y称作几率,lny1−ylny1−y称为对数几率
可以看出式(2)是在用线性回归模型的预测结果去逼近真实标记y的对数几率,对应的模型叫对数几率回归模型(logistic regression), 注意:它实际是一种分类学习方法。
如何来确定(1)式中的ww和b?将y视为类后验概率估计p(y=1|x)p(y=1|x),得到下式:
显然,
于是,我们可以通过极大似然法来估计ww和b,给定数据集(xi,yi),i=1,2…,m(xi,yi),i=1,2…,m,对数几率回归模型最大化对数似然,即每个样本属于其真实标记的概率越大越好:
令:β=(w;b)β=(w;b),x^=(x;1)x^=(x;1),故wTx+b=βTx^wTx+b=βTx^
令: p1(x^;β)=p(y=1|x^;β)p1(x^;β)=p(y=1|x^;β),p0(x^;β)=p(y=0|x^;β)p0(x^;β)=p(y=0|x^;β)
似然项可以重写为:
对上式取对数
因为yi∈{0,1}yi∈{0,1},所以上式的第一项要么为0,要么为βTx^βTx^,故上边的最大化式等价于下面这个最小化式
利用经典的数值优化算法如梯度下降、牛顿法都可以得到上式最优解。
线性判别分析(LDA)也称为Fisher判别分析
思想:给定训练样例集,设法将样例投影到一条直线上,使类内方差最小,类间方差最大,使分类效果最好。
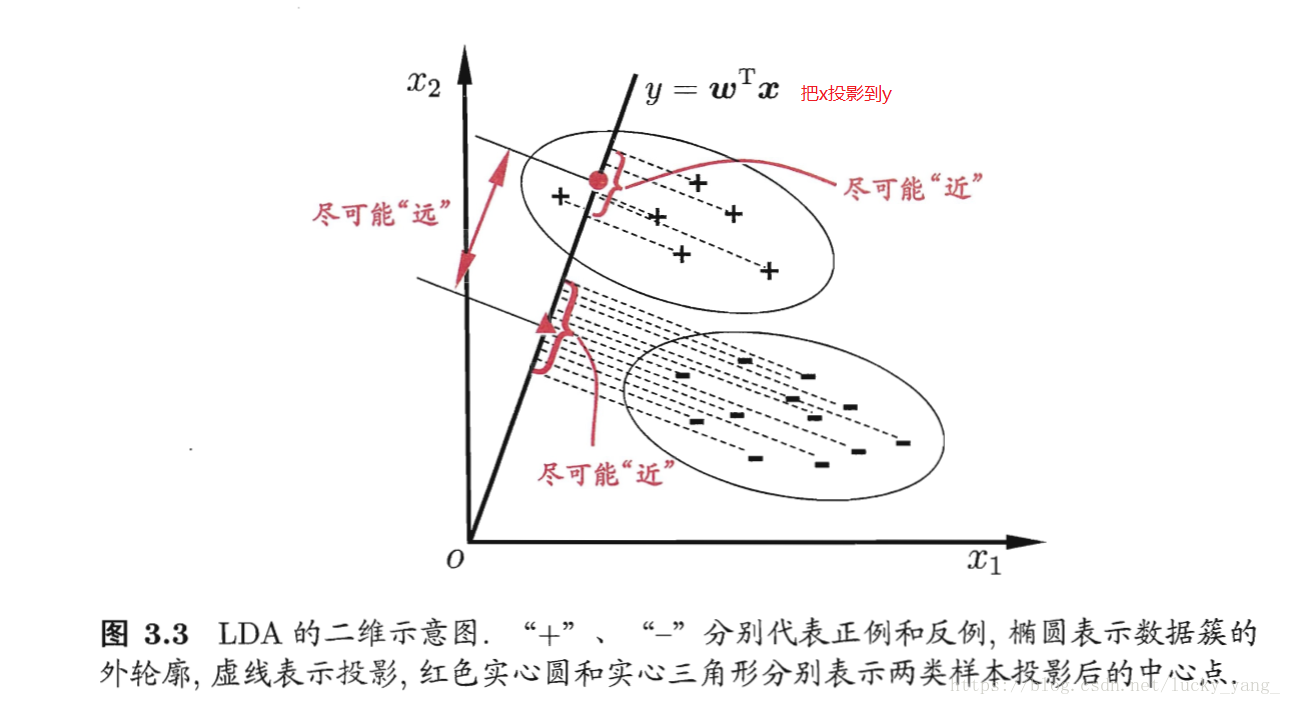
给定数据集(xi,yi),i=1,2…,m(xi,yi),i=1,2…,m,yi∈{0,1}yi∈{0,1},令Xi,μi,ΣiXi,μi,Σi分别表示第i∈{0,1}i∈{0,1}类示例的集合、均值向量、协方差矩阵。
则两类样本的中心在直线上的投影分别为:wTμ0wTμ0和wTμ1wTμ1
两类样本的协方差分别为:wTΣ0wwTΣ0w和wTΣ1wwTΣ1w
使同类样例投影点尽可能近,可以让同类样例投影点的协方差尽可能小,即wTΣ0w+wTΣ1wwTΣ0w+wTΣ1w尽可能小。
使异类样例的投影点尽可能远,可以让类中心之间的距离尽可能大,即||wTμ0−wTμ1||2||wTμ0−wTμ1||2尽可能大。
所以我们的目标是最大化下式:
定义类内散度矩阵SwSw:
定义类间散度矩阵SbSb:
所以J可以重写为:
这就是LDA要最大化的目标,即SbSb与SwSw的广义瑞利商。
可以看到,上式分子分母都是w的二次项,所以解与w的长度无关,只与其方向有关,不失一般性,令wTSww=1wTSww=1,则上式等价于
由拉格朗日乘子法,上式等价于:
Sbw=(μ0−μ1)(μ0−μ1)TwSbw=(μ0−μ1)(μ0−μ1)Tw,其中(μ0−μ1)Tw(μ0−μ1)Tw是一个标量,所以SbwSbw的方向恒为μ0−μ1μ0−μ1,故有:Sbw=λ(μ0−μ1)Sbw=λ(μ0−μ1).
所以可以得到:w=S−1w(μ0−μ1)w=Sw−1(μ0−μ1)
当两类数据同先验,满足高斯分布且协方差相等时,LDA可以达到最优分类!
LDA推广到多分类任务中,emmmmm以后再看吧

















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









