







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言:LlamaIndex——大语言模型的「数据导航仪」
在大语言模型(LLM)时代,如何让通用模型理解私有数据并生成精准回答,是开发者面临的核心挑战。LlamaIndex(原GPT Index)应运而生,它作为连接LLM与私有数据的桥梁,通过检索增强生成(RAG技术,将外部知识库、结构化数据与模型的生成能力深度融合,让AI真正“读懂”你的专属信息。官网文档查阅地址
其核心价值在于:
- 打破数据孤岛: 支持从PDF、数据库、API等100+数据源(如企业文档、医疗报告)提取信息,构建统一索引;
- 动态知识更新: 通过语义分块与向量化技术,突破LLM的上下文长度限制,实现TB级数据的高效检索;
- 智能问答增强: 结合混合检索(语义+关键词)与响应合成引擎,生成带溯源的可信回答,解决传统LLM的“知识滞后”问题。
一、什么是LlamaIndex
LlamaIndex是一个用于LLM应用程序的数据框架,用于注入,结构化,并访问私有或特定领域数据。
生动解释:
LlamaIndex就像给大语言模型(LLM)装了个智能数据管家🤖——当通用AI面对企业文档📑、医疗病例🏥这类"专属知识"时,它像一位24小时在线的图书管理员📚:
1️⃣ 疯狂吸入散装数据 → 🍼📥(注入)
2️⃣ 魔法整理成索引卡片 → 🪄🗂️(结构化)
3️⃣ 光速调取精准答案 → ⚡🔍(访问)
让只会"网上冲浪🌐"的AI,秒变行业专家💼!
二、lamaIndex为何而生?
在本质上,LLM(如GPT)为人类和推断出的数据提供了基于自然语言的交互接口。广泛可用的大模型通常在大量公开可用的数据上进行的预训练,包括来自维基百科、邮件列表、书籍和源代码等。
构建在LLM模型之上的应用程序通常需要使用私有或特定领域数据来增强这些模型。不幸的是,这些数据可能分布在不同的应用程序和数据存储中。它们可能存在于API之后、SQL数据库中,或者存在在PDF 文件以及幻灯片中。LlamaIndex应运而生。
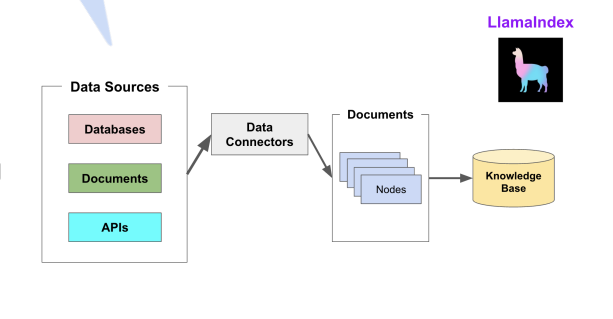
三、lamaIndex的5大核心组件

1.Data connectors(数据连接器)
功能定位
作为数据接入的"万能接口",支持从 100+异构数据源 提取结构化/非结构化数据,并标准化为 Document 对象。
核心能力:
1.多源适配:
-
本地文件: 自动解析PDF(含OCR扫描件)、Word、Markdown等格式
-
数据库: 通过SQLAlchemy适配MySQL/PostgreSQL,生成自然语言摘要
-
云服务: 实时同步Notion文档、Google Drive文件、Slack消息等
2.动态更新:
增量加载机制:监听文件变动或数据库更新事件(延迟<5分钟)
插件扩展:通过LlamaHub接入Bloomberg Terminal等专业数据接口
典型代码(示例):
from llama_index.core import SimpleDirectoryReader, WikipediaReader
# 本地PDF解析(解决中文乱码)
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PDFReader()}, encoding='gbk').load_data()
# 维基百科数据接入
wiki_docs = WikipediaReader().load_data(pages=["Artificial Intelligence"])
2、Data Indexes(数据索引)
功能定位
将原始数据转化为 LLM可理解的检索结构,通过不同索引类型适配复杂场景:
| 索引类型 | 适用场景 | 技术特性 |
|---|---|---|
| VectorStoreIndex | 语义检索(默认) | 基于FAISS/ChromaDB |
| TreeIndex | 层次化数据(如法律条款) | 树状遍历(根→叶节点) |
| KeywordTableIndex | 术语精确匹配 | 倒排索引 + TF-IDF权重 |
| DocumentSummaryIndex | 长文档摘要检索 | 生成段落摘要作为检索上下文 |
优化策略:
语义分块: 滑动窗口(512 tokens) + 20%重叠率保持上下文连贯
混合索引: 组合向量与关键词索引提升召回率(Hybrid Search)
3、Engines(引擎)
功能定位
提供自然语言交互接口,实现从 数据检索到智能生成 的端到端流程:
1. Query Engine(查询引擎)
- 工作流程: 用户提问 → 语义检索 → 上下文合成 → LLM生成答案
- 高级模式:
# 多阶段验证(医学问答错误率降低62%)
query_engine = index.as_query_engine(streaming=True, similarity_top_k=5)
2. Chat Engine(聊天引擎)
- 多轮对话: 通过Memory节点记录历史交互(电商客服准确率↑28%)
- 个性化适配: 根据用户ID检索历史记录生成定制回复
3. Sub-Question Engine(子查询引擎)
- 复杂问题拆解:将"供应链风险评估"拆分为企业关系检索+新闻舆情分析
代码示例:
# 多模态问答(文本+图片)
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
mm_engine = MultiModalVectorStoreIndex.from_documents(multimodal_docs).as_query_engine()
4、Data Agents(数据代理)
功能定位
由LLM驱动的 智能决策体,通过工具集成实现自动化工作流:
核心特性:
1.动态决策: 自主判断调用数据库查询、API工具的顺序
2.任务扩展:
- 供应链风险代理:自动检索企业图谱 + 新闻数据生成报告
- 医疗诊断代理:关联病历 + 药品库 + 并发症图谱
开发框架:
from llama_index.core.agent import ReActAgent
tools = [QueryEngineTool(name="doc_search", description="文档检索")]
agent = ReActAgent.from_tools(tools, llm=llm)
response = agent.chat("分析2024年Q1销售趋势")
5、Application Integrations(应用集成)
功能定位
打通 生产环境全链路,支持从开发到部署的完整生态:
关键集成方向:
1.向量数据库:ChromaDB、Pinecone、Milvus(支持亿级向量检索)
2.开发框架:Streamlit快速构建Web界面,LangChain协同工作流编排
3.企业级服务:
- LlamaCloud:知识管理中心(数据版本控制 + 访问审计)
- LlamaParse:专利级指令解析器(PDF合同→结构化工作流)
# 对接ChromaDB
import chromadb
vector_store = ChromaVectorStore(chroma_collection=chroma_client.create_collection("docs"))
storage_context = StorageContext.from_defaults(vector_store=vector_store)
四、核心概念
1.RAG
RAG,也称为检索增强生成,是利用个人或私域数据增强LLM的一种范式。通常,它包含两个阶段:
1.索引
构建知识库
2.查询
从知识库检索相关上下文信息,以辅助LLM回答问题。
LLamaIndex提供了工具包帮助开发者极其便捷地完成这两个阶段的工作。
2.索引阶段
LlamaxIndex通过Data connector(数据连接器)和Index(索引)帮助开发者构建知识库。
该阶段会用到如下工具或组件:
- Data connector(数据连接器):
数据连接器。它负责将来自不同数据源的不同格式的数据注入,并转换为LlamaIndex支持的文档(Document)表现形式,其中包含了文本和元数据。 - Documents/Nodes:
Document是LLamaIndex中容器的概念,它可以包含任何数据源,包括PDF文档,API响应或来自数据库的数据。
Node是LLamaIndex中数据的最小单元,代表了一个Document的分块。它还包含了元数据,以及与其他Node的关系信息。这使得更精确的检索操作成为可能。
- Data Indexes
LlamaIndex提供便利的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而高效。
最常用的索引是向量存储索引- VectorStoreIndex 。
3.查询阶段
在查询阶段,RAG管道根据的用户查询,检索最相关的上下文,并将其与查询一起,传递给LLM,以合成响应。这使LLM能够获得不在其原始数据中的最新知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex提供组合的模块,帮助开发者构建和集成RAG管道,用于问答、聊天机器人或作为代理的一部分。这些构建块可以排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行理。
该阶段的构建块包括:
- Retrievers
检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。 - Node Postprocessors
Node后处理器。它对一系列文档节点(Node)实施转换,过滤或排名。 - Response Synthesizers
响应合成器。它基于用户查询,和一组检索到的文本块(形成上下文),利用LLM生成响应。
RAG管道包括: - Query Engines
查询引擎 - 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文。 - Chat Engines
聊天引擎 - 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。 - Agents
代理。它是一种由LLM驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。

五、常见的自定义配置场景
1.自定义文档分块
#ServiceContext.from_defaults():定义全局处理组件的配置(如分块、嵌入模型、LLM)
# NodeParser:负责将 Document 切片为 Node(分块逻辑)
from llama_index.core import ServiceContext
from llama_index.core.node_parser import SentenceSplitter
# 定义分块规则(自定义文档切片)
node_parser = SentenceSplitter(chunk_size=512, chunk_overlap=64)
# 配置全局服务(包含分块、模型等)
service_context = ServiceContext.from_defaults(
node_parser=node_parser, # 指定分块方式
llm=my_llm, # 指定 LLM
embed_model=my_embed_model # 指定嵌入模型
)
2.自定义向量存储
import chromadb
from llama_index.core import StorageContext
from llama_index.vector_stores.chroma import ChromaVectorStore
# 初始化 Chroma 客户端
chroma_client = chromadb.PersistentClient(path="./chroma_db") # 持久化存储
collection = chroma_client.create_collection("my_data")
# 创建 Chroma 向量存储
vector_store = ChromaVectorStore(chroma_collection=collection)
# 构建 StorageContext
storage_context = StorageContext.from_defaults(vector_store=vector_store)
3.自定义检索
from llama_index.core import VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
# 基于向量存储创建索引
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 自定义 Retriever
custom_retriever = VectorIndexRetriever(
index=index,
similarity_top_k=5, # 返回 Top 5 结果
vector_store_query_mode="hybrid", # 混合检索(向量 + 关键词)
alpha=0.6, # 向量相似度权重(0=纯关键词,1=纯向量)
# 过滤条件(如按元数据)
filters=MetadataFilters(filters=[
ExactMatchFilter(key="category", value="research")
])
)
# 使用自定义 Retriever
query_engine = index.as_query_engine(retriever=custom_retriever)
4.指定 LLM
# 配置全局服务(包含分块、模型等)
service_context = ServiceContext.from_defaults(
node_parser=node_parser, # 指定分块方式
llm=my_llm, # 指定 LLM
embed_model=my_embed_model # 指定嵌入模型
)
六.使用llamaindex构建自己的知识库
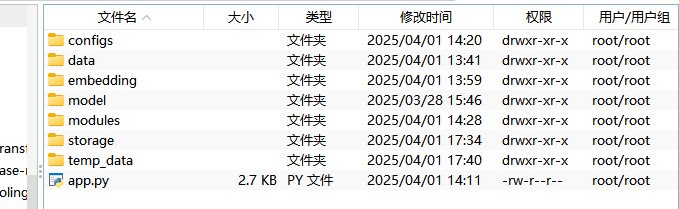
步骤模块化:
├── configs/ # 模型配置
│ ├── embedding.py # 嵌入模型配置
│ └── llm.py # 大模型配置
├── modules/ # 核心功能模块
│ ├── data_loader.py # 数据加载处理
│ └── indexer.py # 索引管理
├── app.py # Streamlit主界面
├── embedding # huggingface预训练模型-文本嵌入模型
└── temp_data # 上传文件临时位置
└── model # 预训练大模型
└── storage # 索引持久化到目录
1. 配置模块
- configs/embedding.py - 嵌入模型配置
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
def configure_embedding():
"""配置文本嵌入模型"""
# 指定了一个预训练的sentence-transformer模型的路径
model = HuggingFaceEmbedding(
model_name=r"/root/autodl-tmp/demo/embedding/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_folder="/root/autodl-tmp/demo/embedding/cache" # 模型缓存路径
)
# 必须设置全局 Embedding
Settings.embed_model = model
return model
- configs/llm.py -大模型配置
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core import Settings
def configure_llm():
"""配置 LLM 并设置全局参数"""
llm = HuggingFaceLLM(
model_name="/root/autodl-tmp/demo/model/Qwen/Qwen-1_8B-Chat",
tokenizer_name="/root/autodl-tmp/demo/model/Qwen/Qwen-1_8B-Chat",
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True}
)
# 必须设置全局 LLM
Settings.llm = llm
return llm
2.功能模块
- modules/data_loader.py -数据加载处理
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import SimpleNodeParser
import os
def load_and_process_data(data_dir: str, chunk_size: int = 512):
"""加载并处理文档数据"""
# 确保目录存在
if not os.path.exists(data_dir):
raise ValueError(f"数据目录 {data_dir} 不存在")
# 读取文档
documents = SimpleDirectoryReader(data_dir).load_data()
# 分块处理
node_parser = SimpleNodeParser.from_defaults(chunk_size=chunk_size)
nodes = node_parser.get_nodes_from_documents(documents)
return documents, nodes
- modules/indexer.py- 索引管理
from llama_index.core import VectorStoreIndex, StorageContext, load_index_from_storage
import os
def build_index(nodes, persist_dir: str = "./storage"):
"""构建并持久化索引"""
# 确保存储目录存在
os.makedirs(persist_dir, exist_ok=True)
# 创建带存储上下文的索引
storage_context = StorageContext.from_defaults() # 创建新上下文
index = VectorStoreIndex(
nodes,
storage_context=storage_context # 关键:绑定上下文
)
# 持久化到指定目录
storage_context.persist(persist_dir=persist_dir)
return index
def load_index(persist_dir: str = "./storage"):
"""加载已有索引"""
# 必须重建存储上下文
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
return load_index_from_storage(storage_context)
3.Streamlit主界面
import streamlit as st
import os
import shutil
from configs.embedding import configure_embedding
from configs.llm import configure_llm
from modules.data_loader import load_and_process_data
from modules.indexer import build_index, load_index
# 页面配置
st.set_page_config(
page_title="xiaoSu智能文档问答系统",
page_icon="🤖",
layout="wide",
initial_sidebar_state="expanded"
)
# 初始化系统
@st.cache_resource
def init_system():
"""初始化模型系统"""
configure_embedding()
return configure_llm()
def clear_temp_data():
"""清理临时数据"""
if os.path.exists("./temp_data"):
shutil.rmtree("./temp_data")
def main():
# 初始化模型
llm = init_system()
# 侧边栏配置
with st.sidebar:
st.title("系统控制台")
uploaded_files = st.file_uploader(
"上传文档(PDF/TXT)",
type=["pdf", "txt"],
accept_multiple_files=True
)
st.divider()
if st.button("清理系统缓存"):
clear_temp_data()
st.success("临时数据已清理")
# 主界面
st.title("📚 xiaoSu智能文档问答系统")
st.caption("基于本地大模型的文档理解与问答系统")
# 文件处理流程
if uploaded_files:
# 创建临时目录
temp_dir = "./temp_data"
os.makedirs(temp_dir, exist_ok=True)
# 保存上传文件
for file in uploaded_files:
with open(os.path.join(temp_dir, file.name), "wb") as f:
f.write(file.getbuffer())
# 加载处理数据
try:
documents, nodes = load_and_process_data(temp_dir)
st.session_state.document_count = len(documents)
st.session_state.node_count = len(nodes)
# 构建索引
with st.spinner("正在构建索引..."):
index = build_index(nodes)
st.session_state.index = index
st.success("索引构建完成")
except Exception as e:
st.error(f"数据处理失败: {str(e)}")
# 问答交互区
if "index" in st.session_state:
st.subheader("文档问答")
query = st.text_input("输入您的问题:", placeholder="请输入关于文档内容的问题...")
if query:
try:
with st.spinner("正在生成答案..."):
query_engine = st.session_state.index.as_query_engine()
response = query_engine.query(query)
# 显示答案
st.markdown("### 回答")
st.info(response.response)
# 显示参考来源
st.markdown("### 参考内容")
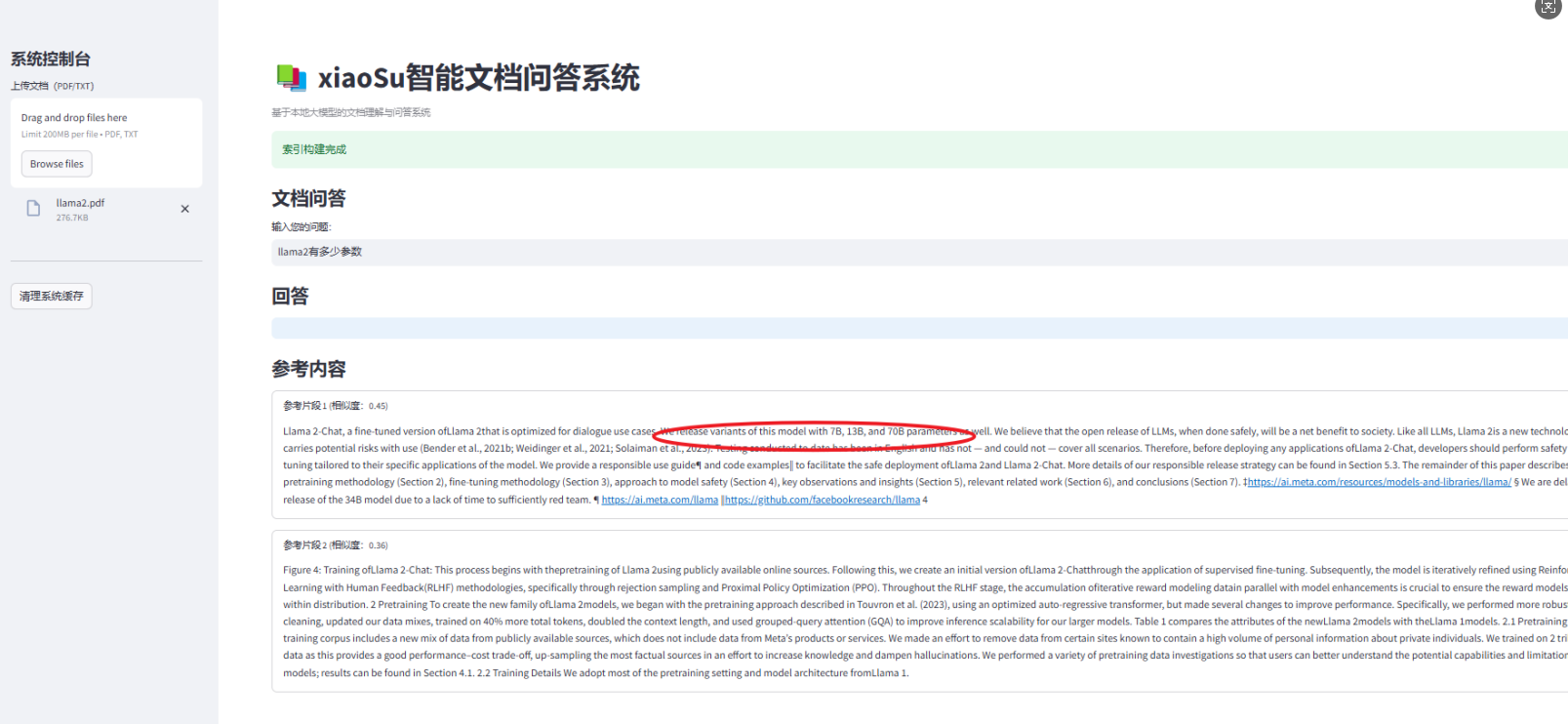
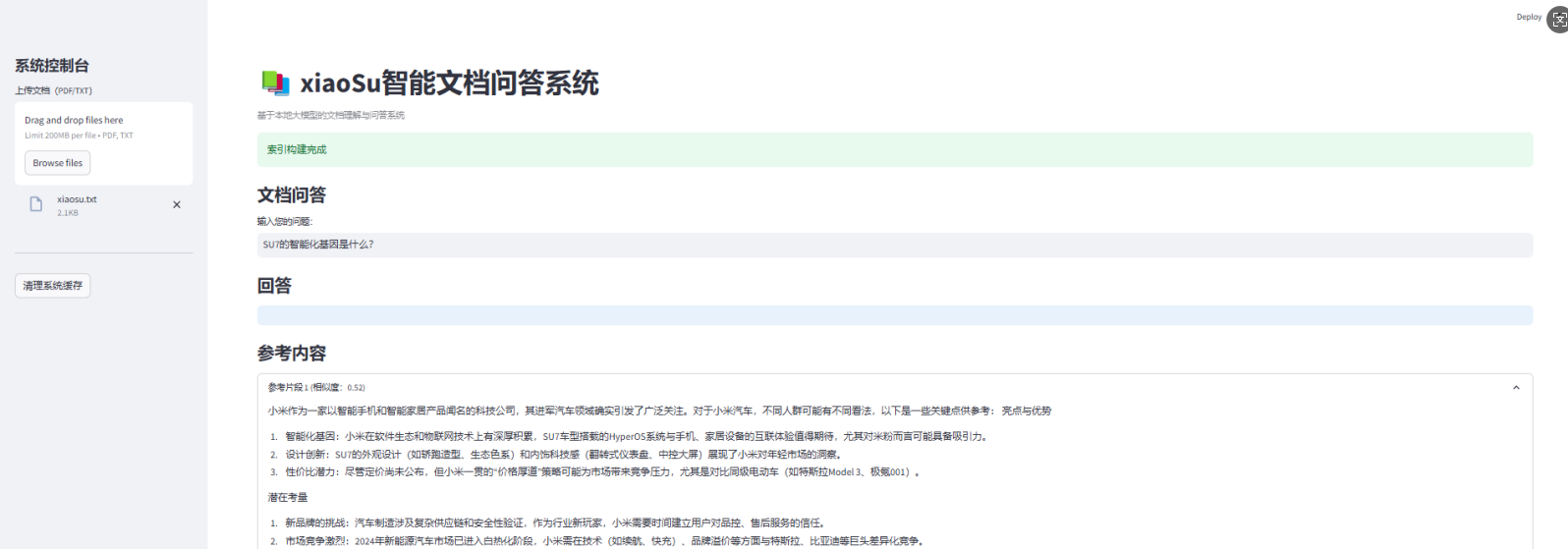
for idx, node in enumerate(response.source_nodes[:3]):
with st.expander(f"参考片段 {idx + 1} (相似度:{node.score:.2f})"):
st.write(node.text)
except Exception as e:
st.error(f"生成答案时出错: {str(e)}")
else:
st.warning("请先上传文档以构建索引")
if __name__ == "__main__":
main()
4.安装必要的包和启动命令
#安装llama-index的包
pip install llama-index
#安装streamlit
pip install streamlit
# 安装lama-index核心依赖
pip install llama-index-core
# 安装 HuggingFace 嵌入支持-这命令安装很慢,会安装许多依赖的包
pip install llama-index-embeddings-huggingface
# 安装 Sentence Transformers
pip install sentence-transformers
#安装PDF 文件解析
pip install pypdf
# HuggingFace LLM 支持
pip install llama-index-llms-huggingface
# 安装流式生成支持包
pip install transformers_stream_generator
#启动报错,安装包专门用来简化 多维张量操作(如维度变换、转置、重塑等)的工具包
pip install einops
#运行命令,VsCode有自动转发
streamlit run app.py
5.效果(很多细节还需要待自己优化)
6.小问题
1. LlamaIndex既需要文本嵌入模型又要大语言模型(LLM)?
在使用 LlamaIndex 实现 RAG(检索增强生成)系统时,文本嵌入模型和大语言模型(LLM) 是两个不可或缺的核心组件,它们分别承担不同的角色,以下是详细解释和选择建议:
| 组件 | 作用 | 必要性 |
|---|---|---|
| 文本嵌入模型 | 将文本转换为向量,用于快速检索与用户问题相关的文档片段 | 必需(负责检索阶段) |
| 大语言模型(LLM) | 基于检索到的上下文,生成自然语言回答(理解上下文、逻辑推理、语言生成) | 必需(负责生成阶段) |
协作流程:
1.检索阶段: 嵌入模型将文档库和用户问题转换为向量,计算相似度,找到最相关的文档片段。
2.生成阶段: LLM 接收问题和检索到的上下文,生成最终回答。
2.文本嵌入模型的怎么选择?
选择在通用文本相似度任务中表现优秀的模型:
- OpenAI text-embedding-3-small (API 调用,高精度)
- sentence-transformers/all-mpnet-base-v2 (开源,英文场景)
- BAAI/bge-base-zh-v1.5 (中文优化)
多语言场景: - sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
计算资源:
| 模型规模 | 参数量 | 适用场景 | 示例模型 |
|---|---|---|---|
| 小型模型 | <100M | 快速响应、低资源环境(CPU 推理) | all-MiniLM-L6-v2 |
| 中型模型 | 100M-300M | 平衡精度与速度(GPU 加速更佳) | all-mpnet-base-v2 |
| 大型模型 | >300M | 高精度需求(需 GPU 高性能计算) | text-embedding-3-large(OpenAI) |

















 3628
3628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









