







系列文章目录
第一章 初识LangChain以及相关介绍
第二章 搭建文档问答系统的核心组件
第三章 手把手搭建第一个文档问答系统
文章目录
前言
传统AI对话系统困于"知识孤岛":
✘ 无法读取最新文档
✘ 缺失专业领域认知
✘ 缺乏多步骤任务执行力
LangChain以三大革新破局:
模块化架构:200+预置组件自由拼装
RAG技术栈:实时检索+智能生成的黄金组合
工具互联:API/数据库/计算器的神经接口
参考文档可以查看:https://www.langchain.com.cn/docs/tutorials/
一、初识LangChain以及相关介绍
1. 什么是LangChain?
- 通俗解释:为语言模型打造的"瑞士军刀"
- 核心价值:让AI模型具备"动手能力"(连接工具/数据/服务)
- 生活比喻:就像给ChatGPT配了秘书团队(检索资料)+工程师(调用工具)
1.2 为什么需要LangChain?
传统AI对话的三大局限
- 知识更新滞后(无法读取最新文档)
- 缺乏执行能力(只能说不能做)
- 上下文碎片化(记不住长期对话)
场景案例:公司新员工培训手册问答系统
1.3 LangChain 的核心组件
- 模型 I/O 封装
- LLMs:大语言模型
- Chat Models:一般基于 LLMs,但按对话结构重新封装
- PromptTemple:提示词模板
- OutputParser:解析输出
- 数据连接封装
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作
- Verctorstores: (面向检索的)向量的存储
- Retrievers: 向量的检索
- 对话历史管理
- 对话历史的存储、加载与剪裁
- 架构封装
- Chain:实现一个功能或者一系列顺序功能组合
- Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
- Callbacks
二、搭建文档问答系统的核心组件
1.技术四要素图解
graph LR
A[你的文档] --> B{处理系统}
B --> C[向量数据库]
C --> D[LangChain]
D --> E[AI模型]
E --> F[用户界面]
2.关键概念速览
术语 通俗解释 类比说明
Embedding 把文字变成数学坐标 给每句话发"身份证号"
VectorDB 专门存数字坐标的数据库 文档内容的"数学地图"
RAG 检索+生成的组合技 先查资料再写作文
Chain 多个步骤的流水线 做菜的工序清单
三、手把手搭建第一个文档问答系统
1.申请OpenAI的key,进行测试
- 先创建自己虚拟环境,并且激活
conda create -n myenv python=3.10 -y
#刷新bash配置
source ~/.bashrc
conda activate myenv
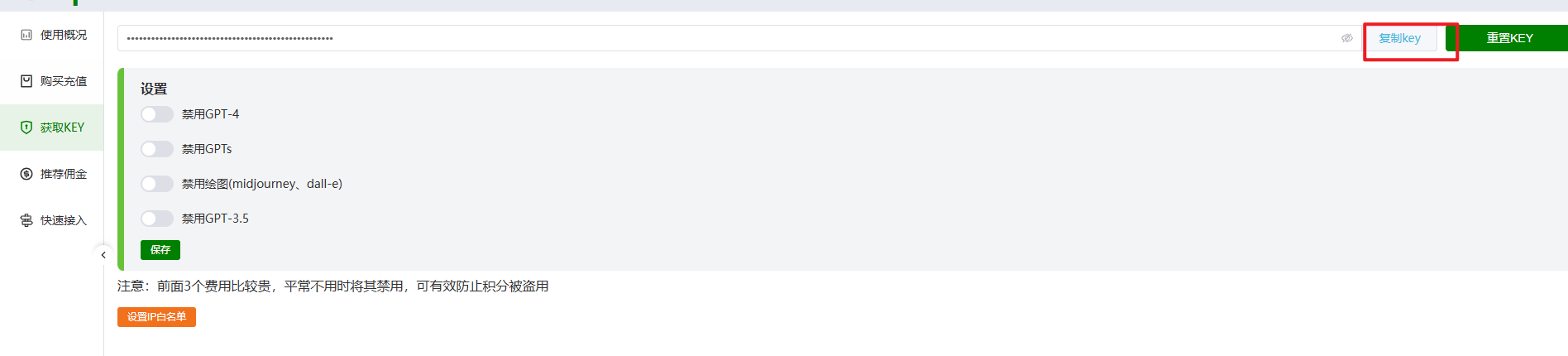
2.在这个网站申请的https://openai-hk.com/?i=53342,第三方代理openai的key
3.用脚本测试下你的服务器,能不能调通,下面的代码拷贝到服务器上进行执行:
import requests
import json
url = "https://api.openai-hk.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer hk-替换为你的key"
}
data = {
"max_tokens": 1200,
"model": "gpt-3.5-turbo",
"temperature": 0.8,
"top_p": 1,
"presence_penalty": 1,
"messages": [
{
"role": "system",
"content": "You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible."
},
{
"role": "user",
"content": "你是chatGPT多少?"
}
]
}
response = requests.post(url, headers=headers, data=json.dumps(data).encode('utf-8') )
result = response.content.decode("utf-8")
print(result)
输出的结果是:

2.用 LCEL 实现 RAG
简单介绍下LangChain Expression Language (LCEL):
LCEL 是 LangChain 的声明式工作流编排语言,专为构建复杂语言模型应用链而设计。它通过统一的操作符(如 |)和标准化接口,实现组件间的无缝衔接。
1. 配置对应需要的包
#安装langchain的包
pip install langchain
#文档加载器
pip install pymupdf
#向量数据库
conda install -c pytorch faiss-gpu
# 安装python-dotenv
pip install python-dotenv
#安装openai的包
pip install langchain-openai
# 社区模块(包含FAISS、PDF加载器等)
pip install langchain-community
2.进行分模块测试
将pdf文件进行上传到服务器指定位置

将下面代码进行拷贝到chain.py文件里(这个文件自己创建的)
import os
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_core.documents import Document
from langchain_core.prompts import PromptTemplate
# ------------------------
# 模块1:环境配置
# ------------------------
def config_environment():
# 硬编码API配置(替换为你的实际信息)
os.environ["OPENAI_API_KEY"] = "your_openai_key"
os.environ["OPENAI_API_BASE"] = "https://api.openai-hk.com/v1"
print("✅ 环境配置完成")
# ------------------------
# 模块2:文档加载
# ------------------------
def load_pdf_documents(path: str) -> list[Document]:
"""加载PDF并保留页码等元数据"""
try:
loader = PyMuPDFLoader(path)
pages = loader.load() # 👈 使用load()保留元数据
assert len(pages) > 0, "文档内容为空"
print(f"✅ 成功加载 {len(pages)} 页文档")
return pages
except Exception as e:
raise RuntimeError(f"❌ 文档加载失败: {str(e)}")
# ------------------------
# 模块3:文档切分(传递元数据)
# ------------------------
def split_documents(pages: list[Document]) -> list[Document]:
"""切分文档并继承元数据"""
try:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
split_texts = text_splitter.split_documents(pages) # 自动传递元数据
print(f"✅ 文档切分成功,生成 {len(split_texts)} 个片段")
return split_texts
except Exception as e:
raise RuntimeError(f"❌ 文档切分失败: {str(e)}")
# ------------------------
# 模块4:向量化灌库
# ------------------------
def create_vector_store(texts: list[Document]) -> FAISS:
"""创建向量库"""
try:
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=os.getenv("OPENAI_API_KEY"),
openai_api_base=os.getenv("OPENAI_API_BASE"),
max_retries=5,
request_timeout=60
)
db = FAISS.from_documents(texts, embeddings)
print("✅ 向量库创建成功")
return db
except Exception as e:
raise RuntimeError(f"❌ 向量化失败: {str(e)}")
# ------------------------
# 模块5:问答链构建(修复Prompt)
# ------------------------
def build_qa_chain(db: FAISS, model_name: str = "gpt-3.5-turbo") -> RetrievalQA:
"""构建问答链"""
try:
llm = ChatOpenAI(
model=model_name,
temperature=0.8,
openai_api_key=os.getenv("OPENAI_API_KEY"),
openai_api_base=os.getenv("OPENAI_API_BASE"),
max_retries=5,
request_timeout=60
)
# 定义标准化的提示模板
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template="根据以下LLama2知识库内容,用中文回答:\n{context}\n问题:{question}"
)
retriever = db.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt_template}
)
print("✅ 问答链构建成功")
return qa_chain
except Exception as e:
raise RuntimeError(f"❌ 问答链构建失败: {str(e)}")
# ------------------------
# 模块6:交互测试
# ------------------------
def test_qa_chain(qa_chain: RetrievalQA):
"""交互式问答测试(增强健壮性)"""
print("\n=== 进入问答模式 ===")
print("输入 'exit' 或 'quit' 退出,输入为空自动重试")
while True:
try:
# 输入处理(兼容不可见字符)
query = input("\n请输入问题: ").strip()
# 退出检测
if query.lower() in ('exit', 'quit'):
print("退出问答模式")
break
# 空输入处理
if not query:
print("⚠️ 问题不能为空,请重新输入")
continue
# 添加处理状态提示
print("🔍 正在查询,请稍候...")
# 执行查询(强制设置超时)
result = qa_chain.invoke({"query": query})
# 结果解析
answer = result.get('result', '未找到答案')
source_docs = result.get('source_documents', [])
# 显示答案
print(f"\n答案:{answer}")
# 显示来源(增强容错)
if source_docs:
print("\n来源信息:")
for i, doc in enumerate(source_docs, 1):
page_num = doc.metadata.get('page', 0) + 1
content = doc.page_content[:200].replace('\n', ' ') # 处理换行符
print(f"来源{i} (第{page_num}页): {content}...")
else:
print("\n⚠️ 未找到相关来源文档")
except Exception as e:
# 显示完整错误堆栈
import traceback
print(f"\n❌ 查询发生错误:{str(e)}")
traceback.print_exc() # 打印堆栈跟踪
# ------------------------
# 主流程
# ------------------------
if __name__ == "__main__":
config_environment()
raw_pages = load_pdf_documents("/root/autodl-tmp/demo08/pdf/llama2.pdf")
split_texts = split_documents(raw_pages)
vector_db = create_vector_store(split_texts)
qa_chain = build_qa_chain(vector_db)
test_qa_chain(qa_chain)
分别执行下面的脚本代码进行验证:
- 模块1:环境配置
python -c "from chain import config_environment; config_environment()"
- 模块2:文档加载
python -c "
from chain import config_environment, load_pdf_documents;
config_environment();
load_pdf_documents('/root/autodl-tmp/demo08/pdf/llama2.pdf')
"
- 模块3:文档切分
python -c "
from chain import config_environment, load_pdf_documents, split_documents;
config_environment();
pages = load_pdf_documents('/root/autodl-tmp/demo08/pdf/llama2.pdf');
split_documents(pages)
"
- 模块4:向量化灌库
python -c "
from chain import config_environment, create_vector_store;
from langchain_core.documents import Document;
config_environment();
create_vector_store([Document(page_content='test', metadata={'page': 0})])
"
- 模块5:问答链构建
python -c "
from chain import config_environment, build_qa_chain;
from langchain_community.vectorstores import FAISS;
from langchain_openai import OpenAIEmbeddings;
config_environment();
embeddings = OpenAIEmbeddings();
db = FAISS.from_texts(['test content'], embeddings);
build_qa_chain(db)
"
- 模块6:交互测试
python -c "
from chain import (config_environment, create_vector_store, build_qa_chain, test_qa_chain);
from langchain_core.documents import Document;
config_environment();
db = create_vector_store([Document(page_content='Llama2 has 70B parameters', metadata={'page': 5})]);
qa = build_qa_chain(db);
test_qa_chain(qa)
"
分别去点击进行测试对应代码,有错误解决错误,最终执行下面的命令,进行完整检验:
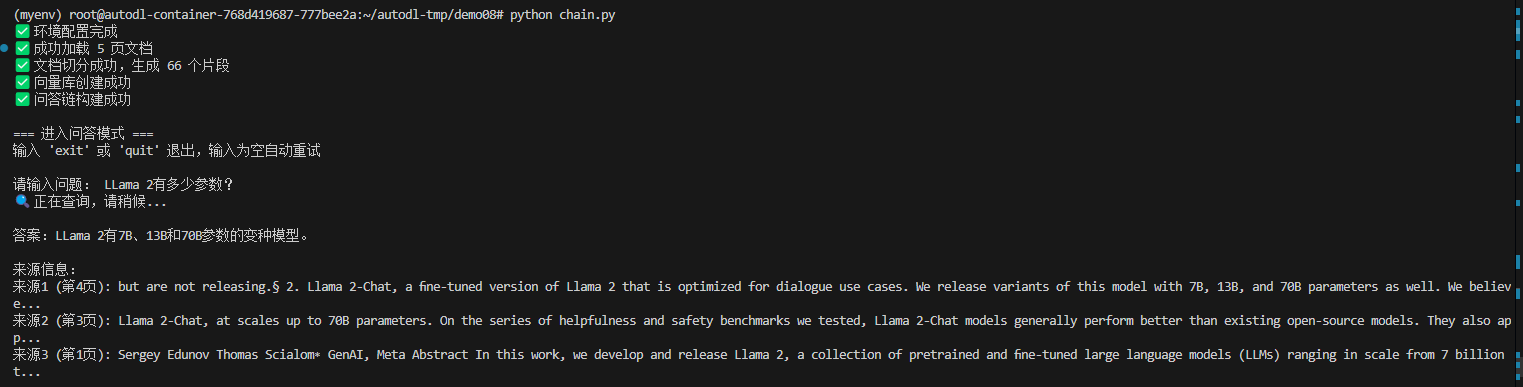
python chain.py
验证结果:

















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









