



文章目录
0 前言
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。并且很难找到完整的毕设参考学习资料。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目提供大家参考学习,今天要分享的是
🚩 毕业设计 yolo11智能安防偷盗行为识别系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
难度系数:3分
工作量:4分
创新点:5分
🧿 项目分享:见文末!
1 项目运行效果
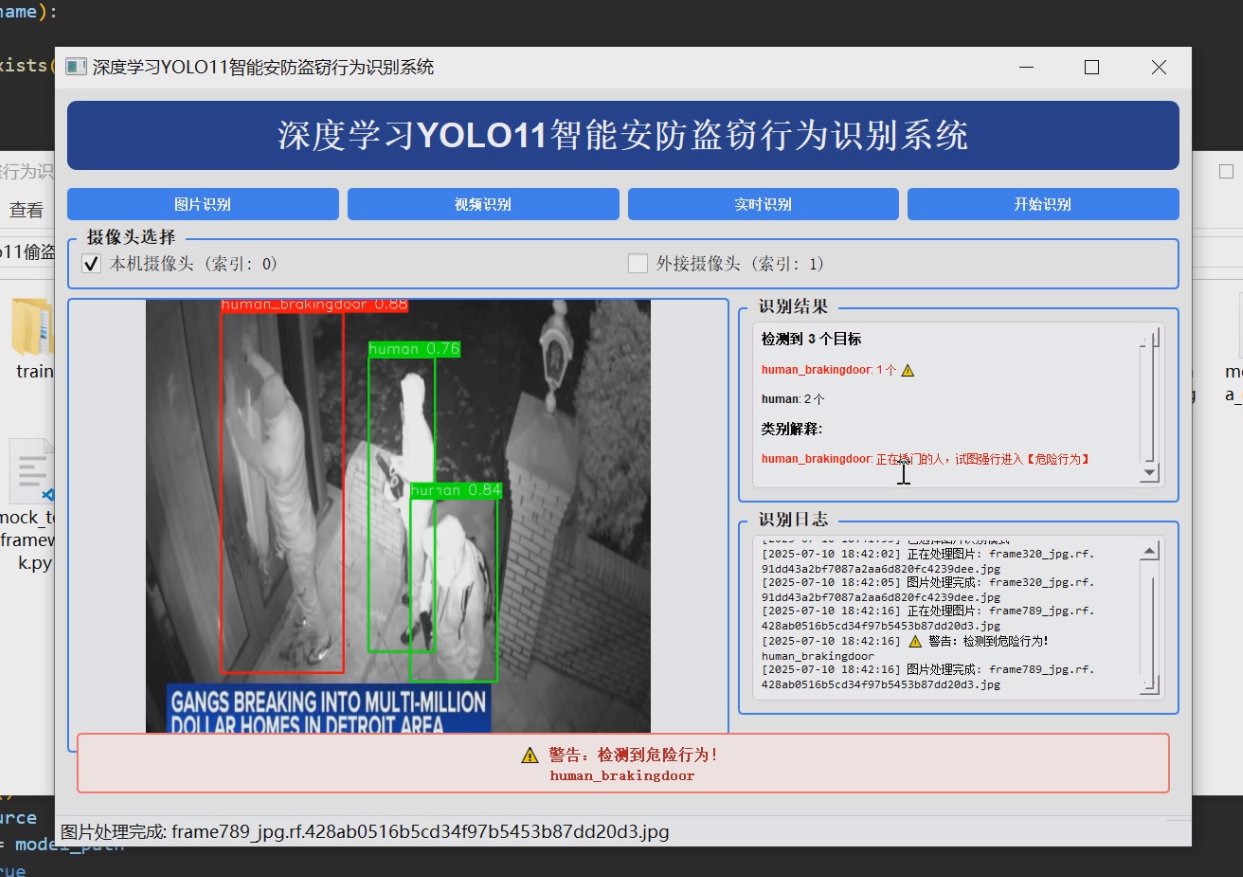
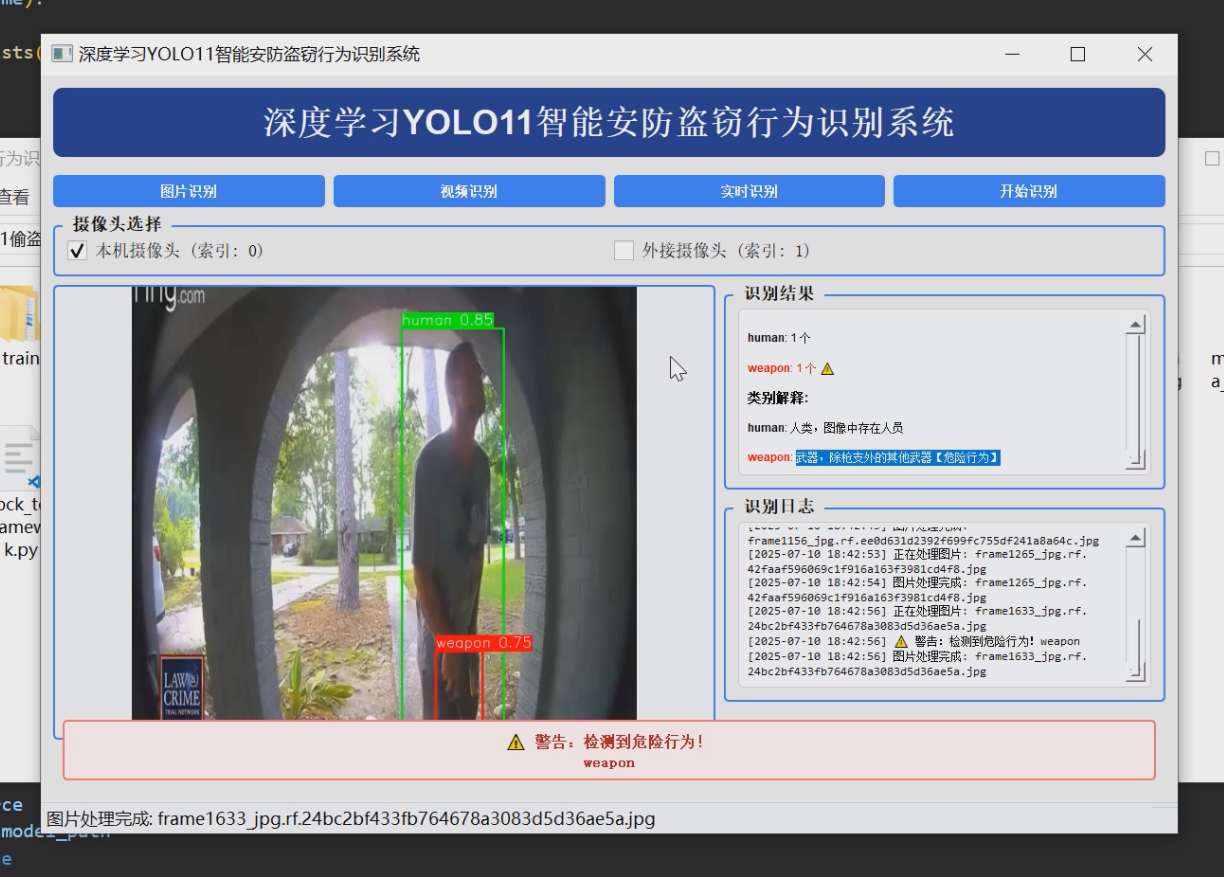

2 课题背景
2.1 研究背景与意义
随着城市化进程的加快和社会经济的不断发展,公共安全问题日益凸显,盗窃等违法犯罪行为在特定区域和时段仍然存在较高的发生率。传统的安防手段主要依赖于人工监控和报警系统,但这种方式存在效率低、响应慢、误报率高等问题,难以满足现代社会对高效智能安防系统的迫切需求。因此,如何利用先进的计算机视觉技术和人工智能算法,开发出一种能够实时、准确识别盗窃行为的智能监控系统,成为当前安防领域的重要研究方向。
近年来,深度学习技术在计算机视觉领域取得了显著进展,特别是在目标检测、行为识别等方面展现出强大的性能优势。YOLO系列算法作为单阶段目标检测模型的代表,以其高速度和高精度的特点广泛应用于实时视频分析场景。最新版本的YOLOv8进一步优化了网络结构和训练策略,提升了小目标检测能力和复杂环境下的鲁棒性,为开发高效的盗窃行为识别系统提供了坚实的技术基础。
本课题旨在基于YOLOv8模型构建一个智能安防盗窃行为识别系统,通过深度学习技术实现对可疑行为的自动检测和预警。该系统不仅可以提高安防工作的智能化水平,减少人工监控的工作强度,还能有效提升对盗窃行为的及时发现能力,为公安机关提供有力的技术支持。此外,该系统的研发对于推动人工智能技术在公共安全领域的应用落地也具有重要的实践价值。
2.2 国内外研究现状
在盗窃行为识别领域,国内外学者已经开展了大量的研究工作。早期的研究主要集中在传统计算机视觉方法的应用上,如基于运动特征提取、人体姿态估计、轨迹分析等方法。这些方法虽然在特定场景下取得了一定的效果,但由于缺乏对复杂行为模式的有效建模能力,在实际应用中往往面临着识别精度低、泛化能力差等问题。
随着深度学习技术的发展,基于卷积神经网络(CNN)的行为识别方法逐渐成为研究热点。国内外许多高校和科研机构都在积极探索深度学习在视频监控和行为识别方面的应用。例如,美国麻省理工学院(MIT)提出了基于时空卷积网络的行为识别框架,中国科学院自动化研究所开发了基于多模态特征融合的异常行为检测系统,清华大学则在基于图神经网络的人体动作识别方面取得了重要进展。
在具体应用方面,一些企业和研究机构已经开始尝试将深度学习技术应用于智能安防系统。如海康威视推出了基于深度学习的智能视频分析平台,大华股份开发了具备行为识别功能的智能摄像头,商汤科技则在公共场所的安全监控系统中集成了异常行为检测模块。然而,目前大多数商用系统仍然存在着成本高、部署难、实时性差等问题,难以大规模推广应用。
2.3 研究内容与目标
本课题的主要研究内容是基于YOLOv8模型开发一套智能安防盗窃行为识别系统。该系统应具备以下核心功能:
- 实时视频流处理:能够接入摄像头或视频文件输入,并对视频流进行实时分析。
- 目标检测与跟踪:利用YOLOv8模型检测视频中的人员、车辆及其他相关目标,并实现对目标的持续跟踪。
- 行为特征提取:通过对检测到的目标进行行为特征分析,识别出可能与盗窃行为相关的动作模式。
- 危险行为识别:建立危险行为分类模型,对识别出的行为模式进行风险评估,判断是否存在盗窃嫌疑。
- 预警与记录:当检测到疑似盗窃行为时,系统应能及时发出预警,并保存相关视频片段以供后续核查。
本课题的研究目标主要包括以下几个方面:
- 构建高效的目标检测模型:基于YOLOv8模型进行改进和优化,使其能够在保证检测精度的同时满足实时性的要求。
- 设计合理的行为特征表示:探索适合盗窃行为识别的行为特征表示方法,提高对复杂行为模式的建模能力。
- 实现精准的风险评估机制:通过机器学习方法建立风险评估模型,降低误报率和漏报率。
- 开发完整的系统原型:搭建包含前端界面、后端处理和数据存储的完整系统架构,验证所提出方法的有效性和实用性。
2.4 研究方法与技术路线
本课题将采用理论研究与实验验证相结合的方法,按照“文献调研→需求分析→模型设计→系统实现→测试验证”的总体思路开展研究工作。具体的技术路线如下:
-
文献调研与需求分析:通过查阅国内外相关文献和技术资料,了解当前盗窃行为识别领域的研究现状和发展趋势,明确系统的需求和功能定位。
-
数据采集与预处理:收集包含各种盗窃行为场景的视频数据集,并对其进行标注、清洗和增强等预处理操作,为模型训练提供高质量的数据支持。
-
模型设计与训练:基于YOLOv8模型进行改进,设计适用于盗窃行为识别的深度学习模型,并使用预处理后的数据集进行训练和调优。
-
系统实现与集成:利用Python编程语言和相关开源库(如OpenCV、PyQt等),开发具备图形用户界面的智能安防盗窃行为识别系统,并将其与训练好的模型进行集成。
-
测试与优化:在实际环境中对系统进行测试,根据测试结果不断调整和优化模型参数及系统配置,提高系统的稳定性和可靠性。
-
总结与展望:对整个研究过程进行总结,分析存在的问题和不足,并对未来的研究方向提出建议。
2.5 预期成果
通过本课题的研究,预计可以获得以下几方面的成果:
-
构建一个基于YOLOv8的盗窃行为识别模型:该模型能够在多种场景下准确地检测和识别出潜在的盗窃行为。
-
开发一套完整的智能安防盗窃行为识别系统:该系统具备良好的用户交互界面和实用的功能模块,能够满足实际应用的需求。
-
形成一套完整的系统设计方案和技术文档:包括系统架构设计、模块划分、接口定义等内容,为后续的系统维护和升级提供依据。
-
撰写并发表相关的学术论文和技术报告:分享研究成果,推动相关领域的学术交流和技术进步。
2.6 创新点与难点
本课题的创新点主要体现在以下几个方面:
-
应用场景创新:将最新的YOLOv8目标检测模型应用于盗窃行为识别领域,探索其在智能安防中的实际应用效果。
-
技术集成创新:结合计算机视觉、深度学习和嵌入式开发等多种技术,构建一个完整的智能安防盗窃行为识别系统。
-
实时性优化:针对YOLOv8模型进行轻量化改造和加速优化,确保系统能够在资源受限的设备上实现实时检测。
本课题的难点主要包括:
-
数据获取与标注:由于盗窃行为属于相对少见的事件,公开可用的数据集较为有限,需要自行收集和标注大量高质量的训练数据。
-
模型泛化能力:如何使模型在不同场景、不同光照条件、不同视角下都能保持稳定的识别性能是一个挑战。
-
系统稳定性与鲁棒性:在实际部署过程中,系统可能会遇到各种复杂的环境干扰,需要采取有效的措施来提高系统的稳定性和抗干扰能力。
-
用户体验优化:为了便于用户使用,需要设计简洁直观的操作界面,并提供清晰的提示信息和帮助文档。
3 设计框架
3.1 技术架构概述
本系统采用分层架构设计,主要包括以下四个层次:
3.1.1 数据采集层
- 功能:负责视频流或图片的采集与预处理
- 关键技术:OpenCV 视频读取与处理
- 输入:摄像头视频流、本地视频文件、单张图片
- 输出:经过预处理的图像帧
1.1.2 目标检测层
- 功能:使用 YOLOv11 模型进行目标检测
- 关键技术:YOLOv11 目标检测算法、非极大值抑制(NMS)
- 输入:原始图像帧
- 输出:检测到的目标及其类别信息
3.1.3 行为分析层
- 功能:分析检测结果,识别危险行为
- 关键技术:行为模式匹配、风险评估算法
- 输入:目标检测结果
- 输出:行为风险等级、预警信息
3.1.4 用户交互层
- 功能:提供图形用户界面,展示检测结果和预警信息
- 关键技术:PyQt5 GUI 开发、QThread 多线程处理
- 输入:用户操作指令
- 输出:可视化检测结果、日志信息、警告提示
3.2 关键技术详解
3.2.1 YOLOv11 目标检测
YOLOv11 是目前最先进的实时目标检测模型之一,具有以下特点:
- 高速度:能够在普通GPU上实现实时检测
- 高精度:在COCO数据集上达到SOTA性能
- 多尺度预测:支持多种尺寸输入,适应不同场景需求
YOLOv11 检测流程伪代码
# 加载YOLOv11模型
model = YOLO("best.pt")
# 图像预处理
def preprocess(image):
# 调整尺寸至640x640
resized_image = cv2.resize(image, (640, 640))
# 归一化处理
normalized_image = resized_image / 255.0
return normalized_image
# 执行目标检测def detect(image):
# 预处理
processed_img = preprocess(image)
# 模型推理
results = model(processed_img)
# 解析结果
detections = []
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy().astype(int)
conf = float(box.conf[0].cpu().numpy())
cls = int(box.cls[0].cpu().numpy())
class_name = result.names[cls]
detections.append((x1, y1, x2, y2, conf, class_name))
return detections
3.2.2 非极大值抑制(NMS)
NMS 是目标检测中用于去除重复检测框的关键技术。其实现原理如下:
- 按置信度排序:将所有检测框按照置信度从高到低排序
- 选择最佳检测框:选取当前置信度最高的检测框作为基准
- 计算IoU:计算该基准框与其他所有框的交并比(IoU)
- 移除重叠框:移除IoU超过阈值的所有框
- 重复步骤2-4:直到所有框都被处理完毕
NMS 实现伪代码
def non_max_suppression(detections, iou_threshold=0.5):
if not detections:
return []
# 按置信度排序
detections.sort(key=lambda x: x[4], reverse=True)
keep_detections = []
while detections:
best_detection = detections.pop(0)
keep_detections.append(best_detection)
# 计算与其余检测的IoU并移除高重叠的检测
new_detections = []
for detection in detections:
iou = calculate_iou(best_detection, detection)
if iou < iou_threshold:
new_detections.append(detection)
detections = new_detections
return keep_detections
# 计算两个框之间的IoUdef calculate_iou(box1, box2):
# 解包边界框坐标
x1_min, y1_min, x1_max, y1_max = box1[:4]
x2_min, y2_min, x2_max, y2_max = box2[:4]
# 计算交集区域的坐标
inter_xmin = max(x1_min, x2_min)
inter_ymin = max(y1_min, y2_min)
inter_xmax = min(x1_max, x2_max)
inter_ymax = min(y1_max, y2_max)
# 计算交集面积
inter_area = max(0, inter_xmax - inter_xmin) * max(0, inter_ymax - inter_ymin)
# 计算两个框各自的面积
box1_area = (x1_max - x1_min) * (y1_max - y1_min)
box2_area = (x2_max - x2_min) * (y2_max - y2_min)
# 计算并集面积
union_area = box1_area + box2_area - inter_area
# 计算IoU
return inter_area / union_area if union_area > 0 else 0
1.2.3 PyQt5 用户界面
用户界面采用 PyQt5 开发,主要包含以下几个核心组件:
- 主窗口类
SecurityApp:继承自QMainWindow,管理整个应用程序的界面布局和事件处理 - 视频处理线程
VideoThread:继承自QThread,负责视频流的处理和检测结果的更新 - 图像处理器
ImageProcessor:负责静态图像的处理和检测
UI 核心模块设计
PyQt5 主要交互流程
- 模式选择:用户可以选择图片识别、视频识别或实时识别模式
- 开始识别:根据选择的模式启动相应的处理流程
- 结果显示:在界面上显示检测结果和相关解释
- 日志记录:记录系统的运行状态和重要事件
- 警告提示:当检测到危险行为时,显示警告信息
PyQt5 核心交互逻辑伪代码
class SecurityApp(QMainWindow):
def __init__(self):
super().__init__()
self.model_path = "best.pt" # 模型路径
self.image_processor = ImageProcessor(self.model_path)
self.video_thread = None
self.current_mode = None # 'image', 'video', 'camera'
self.camera_index = 0 # 默认摄像头索引
self.init_ui()
def init_ui(self):
# 初始化界面元素
self.create_buttons()
self.create_display_areas()
self.setup_layout()
self.connect_signals()
def create_buttons(self):
# 创建模式选择按钮和开始按钮
self.image_btn = QPushButton("图片识别")
self.video_btn = QPushButton("视频识别")
self.camera_btn = QPushButton("实时识别")
self.start_btn = QPushButton("开始识别")
def create_display_areas(self):
# 创建显示区域和结果区域
self.display_label = QLabel()
self.result_text = QTextEdit()
self.log_text = QTextEdit()
self.warning_label = QLabel()
def connect_signals(self):
# 连接按钮信号
self.image_btn.clicked.connect(self.select_image_mode)
self.video_btn.clicked.connect(self.select_video_mode)
self.camera_btn.clicked.connect(self.select_camera_mode)
self.start_btn.clicked.connect(self.start_detection)
def start_detection(self):
# 启动检测过程
if self.current_mode == 'image':
self.start_image_detection()
elif self.current_mode == 'video':
self.start_video_detection()
elif self.current_mode == 'camera':
self.start_camera_detection()
def update_frame(self, frame, detections):
# 更新视频帧显示
frame_with_boxes = self.draw_boxes(frame, detections)
self.display_image(frame_with_boxes)
self.update_result_text(detections)
self.check_dangerous_behavior(detections)
def draw_boxes(self, frame, detections):
# 绘制检测框
for x1, y1, x2, y2, conf, class_name in detections:
color = (0, 0, 255) if class_name in DANGEROUS_CLASSES else (0, 255, 0)
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
# 绘制标签
label = f"{class_name} {conf:.2f}"
cv2.putText(frame, label, (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 1)
return frame
def check_dangerous_behavior(self, detections):
# 检查是否有危险行为
dangerous_classes = [d[5] for d in detections if d[5] in DANGEROUS_CLASSES]
if dangerous_classes:
self.warning_label.setText(f"⚠️ 警告:检测到危险行为!{', '.join(set(dangerous_classes))}")
self.warning_label.setVisible(True)
else:
self.warning_label.setVisible(False)
3.3 系统工作流程
3.4 数据集训练流程
3.4.1 数据准备
- 数据来源:公开数据集 + 自建数据集
- 标注工具:LabelImg 或其他标注工具
- 数据增强:随机翻转、旋转、亮度调整等
- 数据格式:YOLO 标准格式(每个图像对应一个
.txt文件)
3.4.2 模型训练
- 训练工具:Ultralytics 提供的 YOLOv11 训练接口
- 训练参数:
- epochs: 100
- batch_size: 16
- imgsz: 640
- optimizer: AdamW
- learning_rate: 0.001
- 硬件要求:NVIDIA GPU(建议至少 RTX 3060)
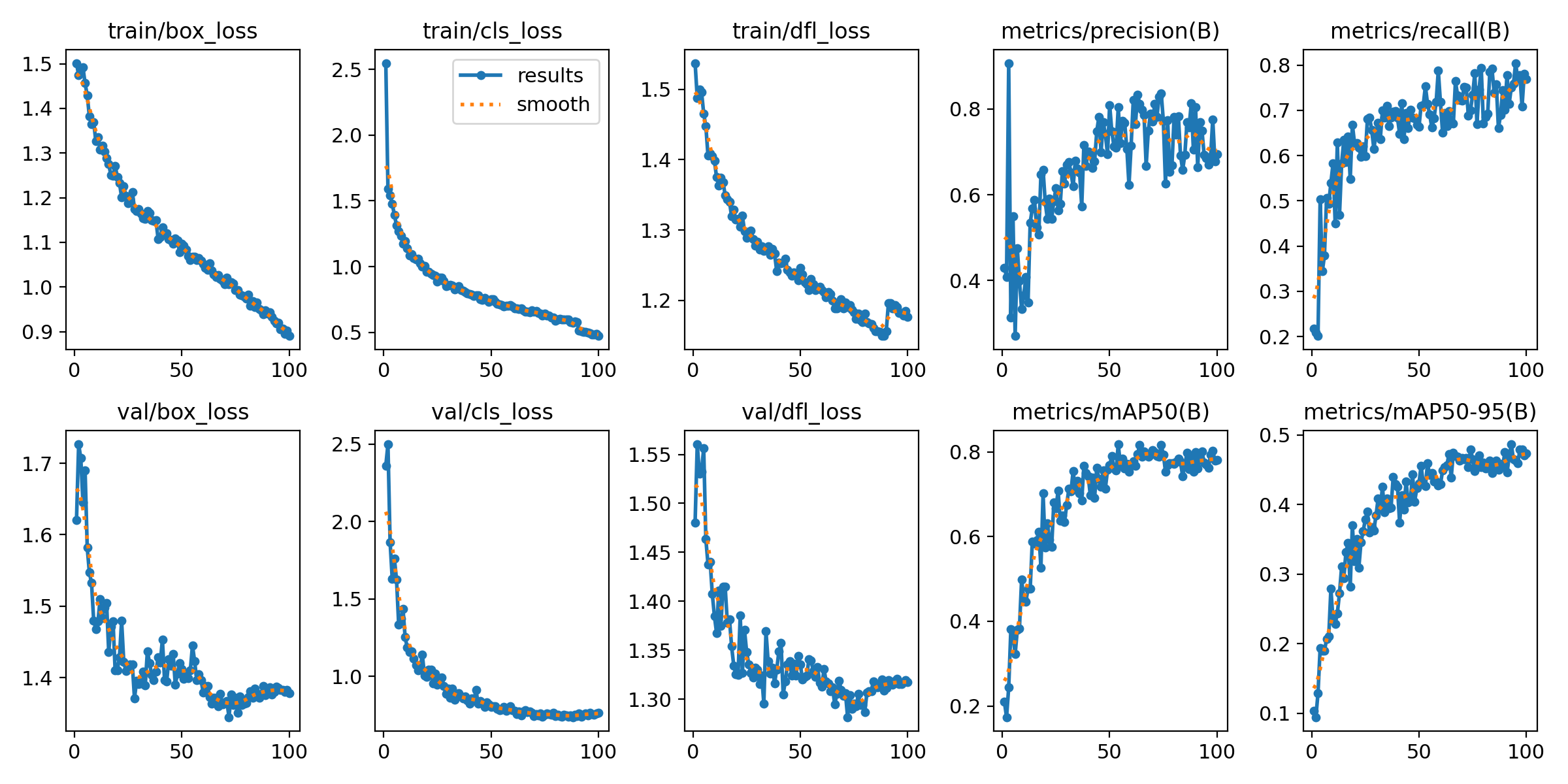
3.4.3 模型评估
- 评估指标:mAP@0.5, mAP@0.5:0.95, Precision, Recall
- 可视化工具:TensorBoard, Confusion Matrix
3.5 UI 交互系统设计逻辑
3.5.1 界面布局
3.5.2 控件设计
- 模式选择按钮:用于切换图片识别、视频识别、实时识别模式
- 摄像头选择复选框:允许用户选择本机摄像头或外接摄像头
- 结果显示区域:以文本形式展示检测到的目标类别及数量
- 日志记录区域:显示系统运行状态和关键事件
- 警告提示区域:当检测到危险行为时,显示醒目的警告信息
1.5.3 交互逻辑
- 初始化阶段:加载模型并初始化界面元素
- 用户选择阶段:用户选择识别模式和数据源
- 处理阶段:根据选择的模式启动相应的处理流程
- 结果显示阶段:在界面上显示检测结果和相关解释
- 日志记录阶段:记录系统的运行状态和重要事件
- 警告提示阶段:当检测到危险行为时,显示警告信息
3.6 可视化图表显示逻辑
3.6.1 检测结果统计图
示例:检测结果统计
def update_result_text(self, detections):
# 清空结果文本
self.result_text.clear()
if not detections:
self.result_text.append("未检测到任何目标")
return
# 统计各类别数量
class_counts = {}
for _, _, _, _, conf, class_name in detections:
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# 显示检测结果统计
self.result_text.append(f"<h3>检测到 {len(detections)} 个目标</h3>")
for class_name, count in class_counts.items():
# 设置危险行为的文本颜色
if class_name in DANGEROUS_CLASSES:
self.result_text.append(f"<p style='color: red;'><b>{class_name}</b>: {count} 个 ⚠️</p>")
else:
self.result_text.append(f"<p><b>{class_name}</b>: {count} 个</p>")
# 添加类别解释
self.result_text.append("<h3>类别解释:</h3>")
for class_name in class_counts.keys():
description = CLASS_DESCRIPTIONS.get(class_name, "无描述")
# 设置危险行为的文本颜色
if class_name in DANGEROUS_CLASSES:
self.result_text.append(f"<p style='color: red;'><b>{class_name}</b>: {description}</p>")
else:
self.result_text.append(f"<p><b>{class_name}</b>: {description}</p>")
3.6.2 日志记录与显示
示例:日志记录函数
def log(self, message):
# 添加时间戳
timestamp = time.strftime("%Y-%m-%d %H:%M:%S")
log_message = f"[{timestamp}] {message}"
# 添加到日志文本框
self.log_text.append(log_message)
# 滚动到底部
self.log_text.verticalScrollBar().setValue(self.log_text.verticalScrollBar().maximum())
4 最后
项目包含内容

论文摘要

🧿 项目分享:大家可自取用于参考学习,获取方式见文末!


















&spm=1001.2101.3001.5002&articleId=149594438&d=1&t=3&u=d3c92bcb47a842368b19802ee1335d4a)
 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









