



0 前言
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。并且很难找到完整的毕设参考学习资料。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目提供大家参考学习,今天要分享的是
🚩 毕业设计 深度学习yolo11作物杂草识别系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
难度系数:3分
工作量:4分
创新点:5分
🧿 项目分享:见文末!
1 项目运行效果
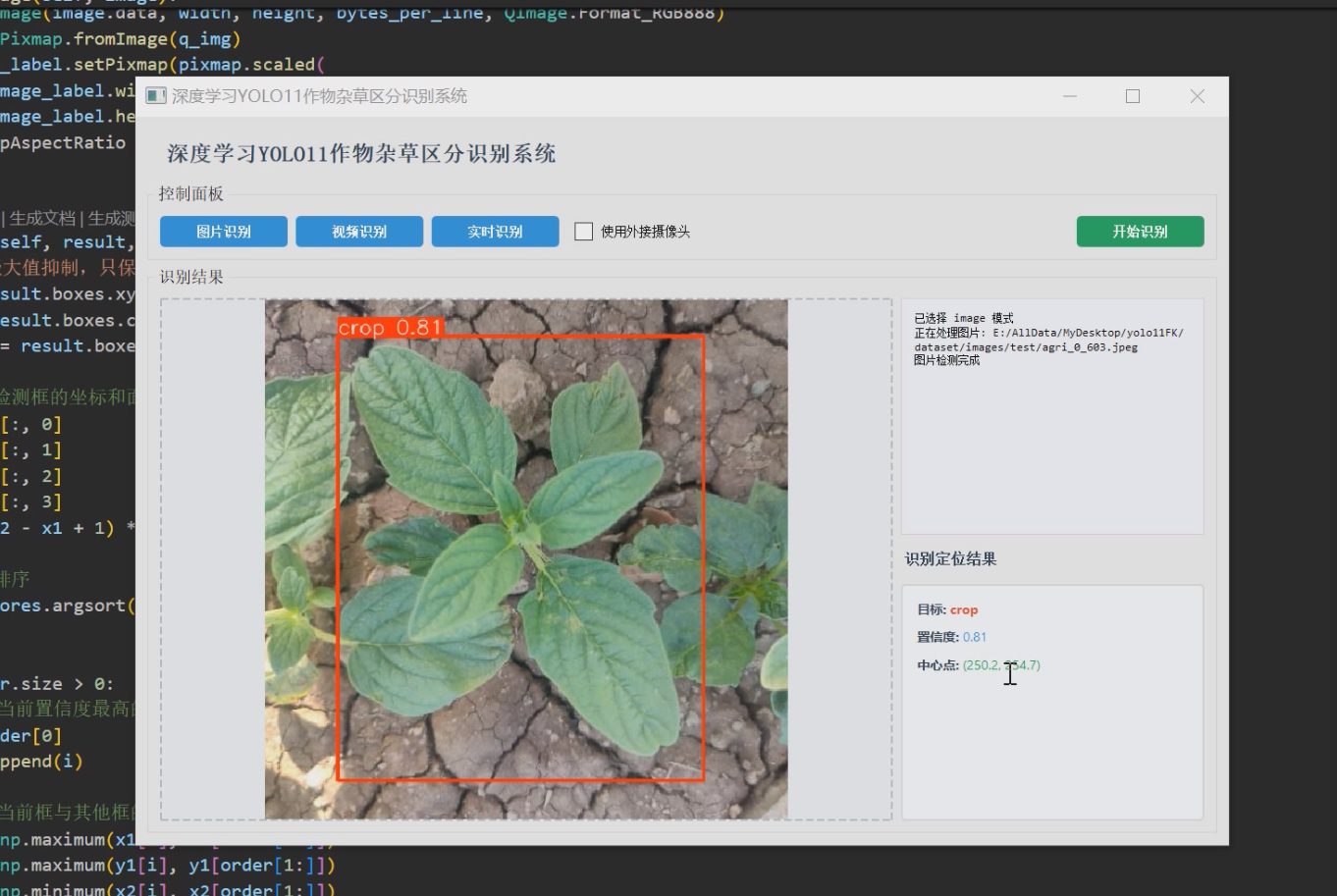
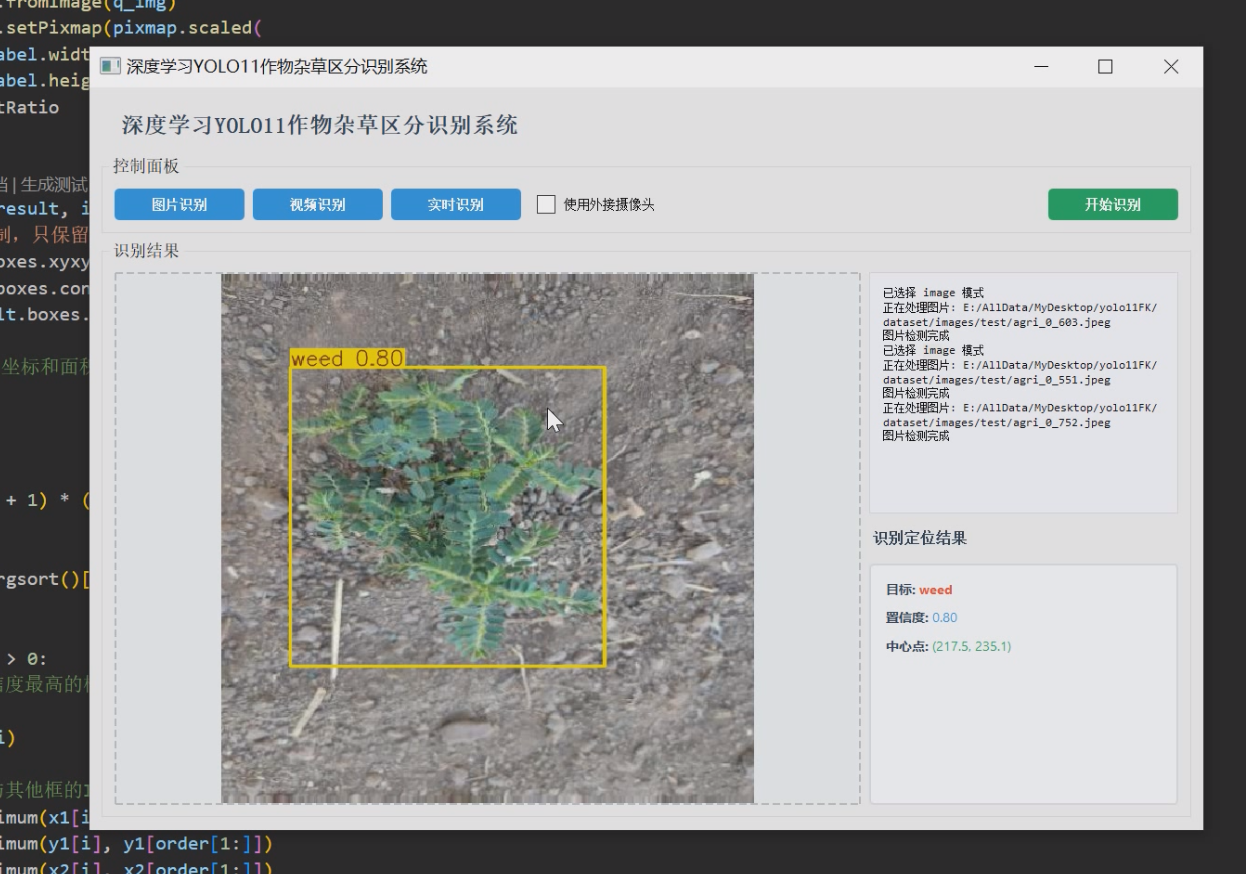
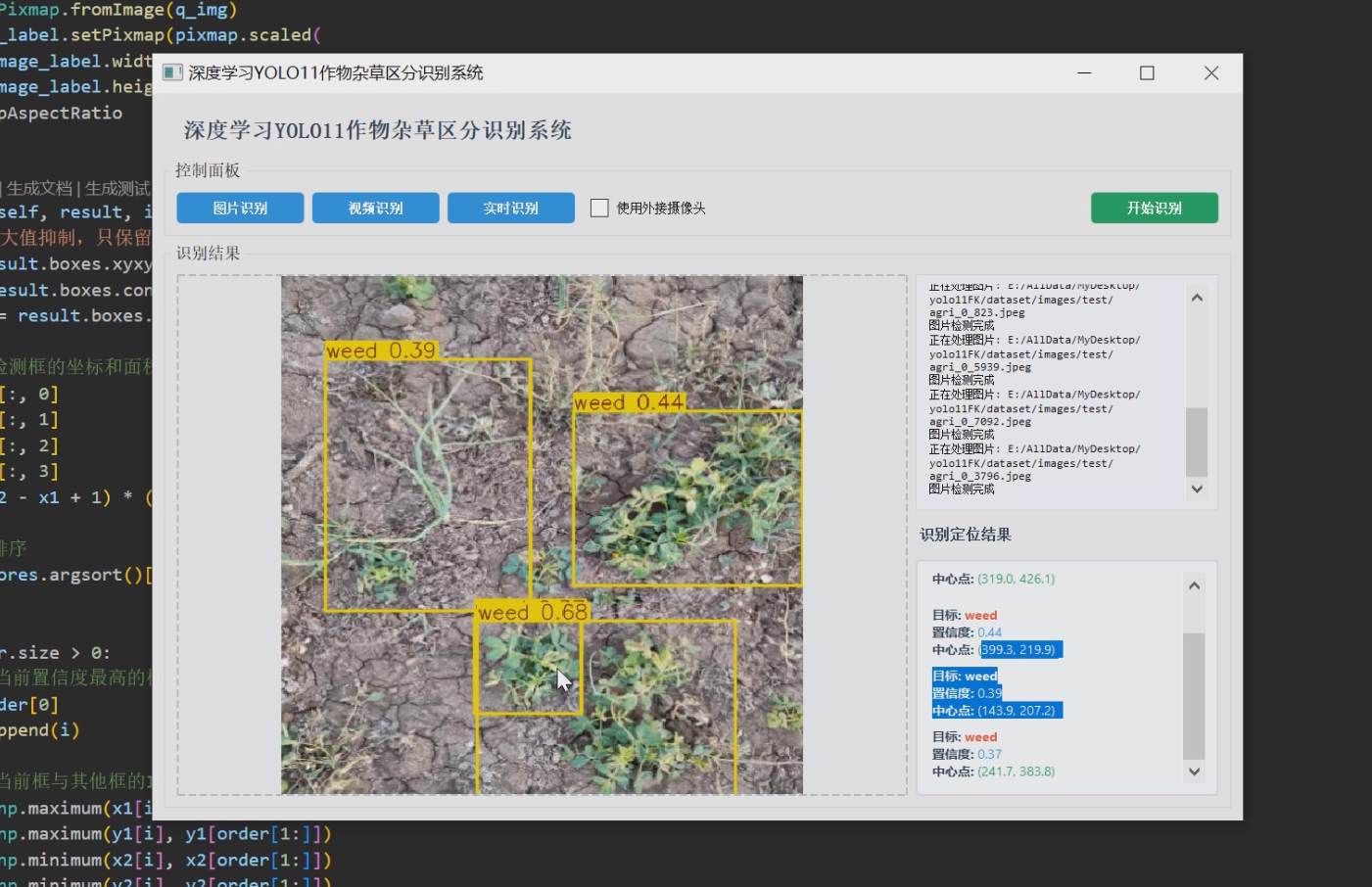

2 课题背景
2.1. 农业现代化与智能化发展背景
随着全球人口持续增长和耕地资源日益紧张,提高农业生产效率已成为世界各国面临的共同挑战。根据联合国粮农组织(FAO)统计数据显示,到2050年全球粮食需求预计将增长60%,而传统农业生产方式已难以满足这一需求。在此背景下,农业现代化和智能化发展成为必然趋势,其中精准农业技术作为现代农业的重要发展方向,通过信息技术与农业生产的深度融合,实现资源优化配置和生产效率提升。
中国作为农业大国,近年来大力推进农业现代化进程。《数字农业农村发展规划(2019-2025年)》明确提出要加快农业农村数字化、网络化、智能化转型。在政策推动下,我国农业智能化水平显著提升,但与国际先进水平相比仍存在一定差距,特别是在田间作业智能化方面仍有较大发展空间。
2. 2. 杂草识别在精准农业中的重要性
杂草是影响农作物生长的主要生物胁迫因素之一,据统计,全球每年因杂草造成的农作物减产高达34%。传统杂草治理主要依赖人工识别和化学除草剂喷洒,这种方式存在以下突出问题:
- 人工识别效率低下,难以满足大规模农田管理需求
- 过度依赖化学除草剂导致环境污染和生态破坏
- 无差别喷洒造成资源浪费和成本增加
- 长期使用导致杂草抗药性增强
精准杂草治理技术能够有效解决上述问题,其核心在于准确识别杂草并精确定位,为后续差异化治理提供依据。研究表明,采用精准除草技术可减少除草剂使用量50-70%,同时提高除草效果30%以上。因此,开发高效、准确的杂草识别系统对推动精准农业发展具有重要意义。
2. 3. 现有杂草识别技术分析
当前杂草识别技术主要分为三类:基于光谱分析、基于传统图像处理和基于深度学习的方法。
2. 3.1 基于光谱分析的识别技术
该方法利用植物在不同波段的光谱反射特性差异进行识别,主要特点包括:
- 依赖专业光谱设备,成本较高
- 受环境光照条件影响大
- 适用于特定作物场景
- 难以实现实时处理
2. 3.2 基于传统图像处理的识别技术
采用图像分割、特征提取等传统计算机视觉方法,其局限性表现为:
- 依赖人工设计特征,泛化能力有限
- 对复杂背景适应性差
- 识别准确率普遍低于85%
- 难以区分形态相似的作物与杂草
2. 3.3 基于深度学习的识别技术
深度学习技术通过自动学习特征表达,在杂草识别领域展现出显著优势:
- 端到端的识别流程简化了传统方法的多步骤处理
- 特征学习能力强,识别准确率高
- 对复杂环境适应性强
- 便于与现有农业装备集成
然而,现有基于深度学习的杂草识别系统仍存在模型计算复杂度高、实时性不足、小目标检测效果差等问题,制约了其在田间实际场景中的应用。
2. 4. 目标检测技术的发展现状
目标检测作为计算机视觉的核心任务之一,近年来取得显著进展。从R-CNN系列到YOLO系列,检测算法在精度和速度上不断突破。特别是YOLOv11作为最新版本,在保持实时性的同时进一步提高了检测精度,其特点包括:
- 采用更高效的网络结构和训练策略
- 引入多尺度特征融合机制
- 优化损失函数设计
- 支持多种硬件平台部署
这些技术进步为目标检测在农业场景中的应用提供了新的可能性。
2. 5. 本课题的研究价值与创新点
基于上述分析,本研究选择YOLOv11算法构建作物杂草识别系统,具有以下研究价值:
2. 5.1 理论价值
- 探索深度学习算法在农业场景中的优化方法
- 研究复杂田间环境下的目标检测技术
- 开发适用于农业应用的模型轻量化策略
2. 5.2 应用价值
- 为精准除草作业提供技术支持
- 减少除草剂使用,降低环境污染
- 提高农业生产效率和经济效益
- 推动农业智能化装备升级
2. 5.3 技术创新点
- 基于YOLOv11的作物杂草检测模型优化
- 多模式检测系统设计(图片/视频/实时)
- 面向田间场景的模型轻量化实现
- 用户友好的交互界面开发
2. 6. 国内外相关研究对比
与国际同类研究相比,本课题具有以下特色:
- 针对中国主要农作物种植场景优化
- 考虑实际农田环境的光照、遮挡等因素
- 系统设计兼顾算法性能和使用便捷性
- 支持多种输入源满足不同应用需求
与国内现有研究相比,本课题的创新之处在于:
- 采用最新的YOLOv11算法提升检测性能
- 实现完整的端到端识别系统
- 注重实际部署的可行性
- 提供详细的技术实现方案
2. 7. 研究基础与可行性分析
本课题的可行性基于以下条件:
- 开源深度学习框架的成熟发展
- 农业图像数据集的逐步完善
- 硬件计算能力的持续提升
- 课题组在计算机视觉领域的研究积累
通过合理的技术路线设计和系统实现方案,本课题有望开发出一套实用性强、识别效果好的作物杂草识别系统,为精准农业技术发展做出贡献。
3 设计框架
3.1. 系统总体架构设计
3. 1.1 系统架构图
3. 1.2 模块功能说明
-
用户界面模块
- 提供图片/视频/实时三种检测模式选择
- 显示检测结果和识别信息
- 记录系统运行日志
-
控制模块
- 处理用户交互逻辑
- 协调各模块运行
- 管理数据流
-
图像处理模块
- 图像/视频帧读取
- 格式转换
- 预处理
-
YOLOv11模型
- 目标检测核心算法
- 非极大值抑制处理
- 结果解析
-
结果可视化模块
- 标注框绘制
- 识别结果显示
- 图表生成
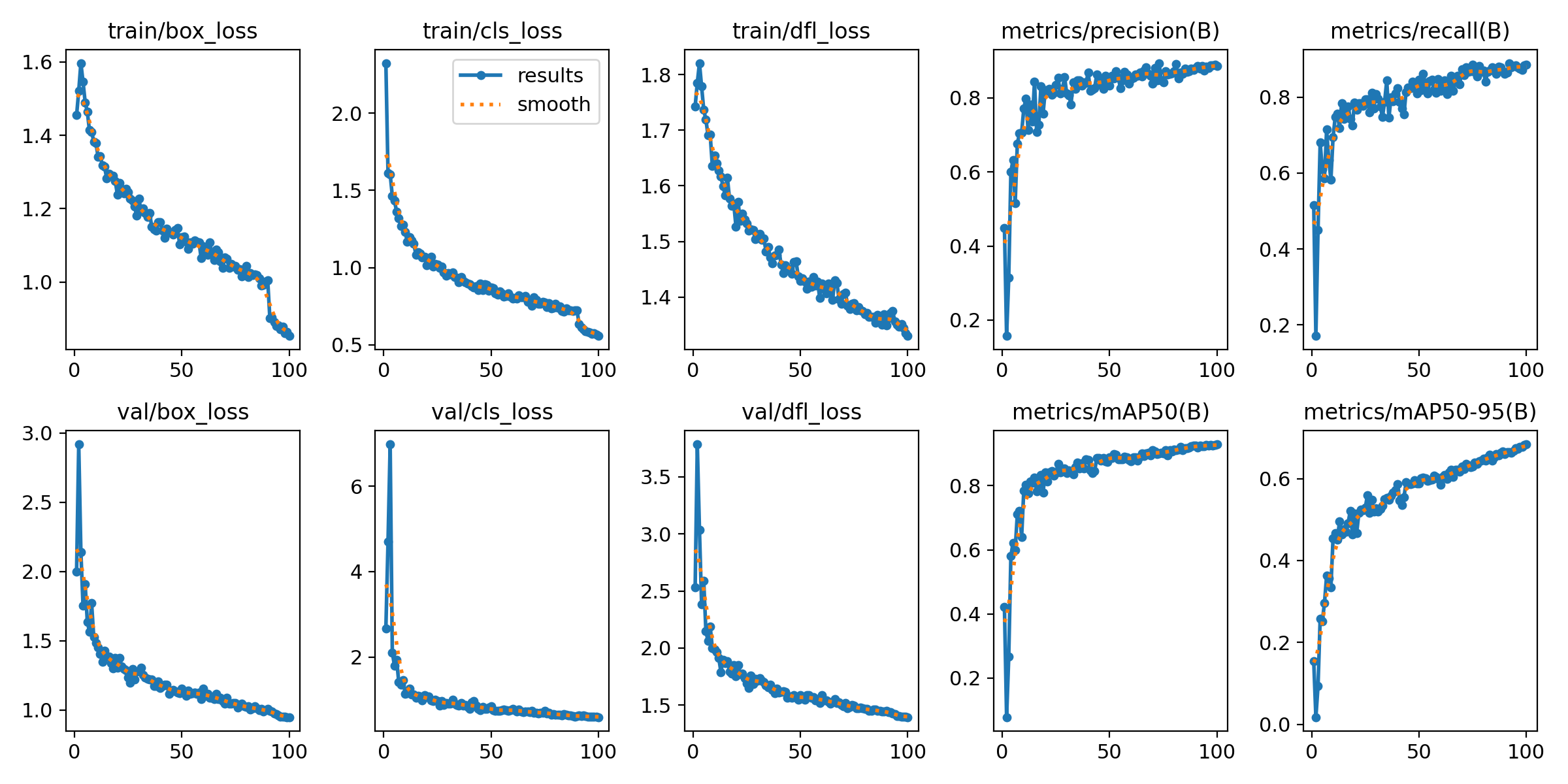
3. 2. YOLOv11模型训练流程
3. 2.1 训练流程图
3. 2.2 关键步骤说明
-
数据收集
- 采集田间作物和杂草图像
- 覆盖不同生长阶段和环境条件
- 平衡各类别样本数量
-
数据标注
- 使用LabelImg等工具标注
- 保存为YOLO格式
- 生成Mydata.yaml配置文件
-
数据增强
- 随机旋转/翻转
- 色彩空间变换
- 添加噪声
-
模型训练伪代码
# 加载预训练权重
model = YOLO('yolov11n.pt')
# 训练配置
config = {
'data': 'Mydata.yaml',
'epochs': 100,
'imgsz': 640,
'batch': 16,
'optimizer': 'AdamW'
}
# 开始训练
results = model.train(**config)
3. 3. UI交互系统设计
3. 3.1 界面布局设计
+-------------------------------------------+
| 标题栏 |
+-------------------------------------------+
| 控制面板 [图片][视频][实时][摄像头][开始] |
+-------------------+-----------------------+
| 图像显示区域 | 日志区域 |
| +-----------------------+
| | 识别定位结果 |
+-------------------+-----------------------+
3. 3.2 交互逻辑流程图
3. 3.3 核心交互逻辑伪代码
class MainWindow(QMainWindow):
def init_ui(self):
# 创建控制按钮
self.btn_image = QPushButton("图片识别")
self.btn_image.clicked.connect(self.set_image_mode)
# 创建显示区域
self.image_label = QLabel()
self.log_text = QTextEdit()
def set_image_mode(self):
self.current_mode = "image"
self.btn_start.setEnabled(True)
def start_detection(self):
if self.current_mode == "image":
self.detect_image()
def detect_image(self):
file_path = QFileDialog.getOpenFileName()
frame = cv2.imread(file_path)
results = self.model.predict(frame)
self.display_results(results)
3. 4. 图表显示逻辑
4.1 结果显示流程图
3. 4.2 关键显示逻辑伪代码
def display_image(self, image):
# 转换图像格式
height, width, _ = image.shape
bytes_per_line = 3 * width
q_img = QImage(image.data, width, height, bytes_per_line, QImage.Format_RGB888)
# 显示图像
pixmap = QPixmap.fromImage(q_img)
self.image_label.setPixmap(pixmap)
def update_detection_results(self, results):
html_text = "<div>"
for box in results.boxes:
# 解析每个检测框信息
class_name = self.classes[int(box.cls)]
conf = box.conf
x_center, y_center = calculate_center(box.xyxy)
# 生成HTML格式文本
html_text += f"""
<div>
<span style='color: red'>目标: {class_name}</span><br>
<span>置信度: {conf:.2f}</span><br>
<span>中心点: ({x_center:.1f}, {y_center:.1f})</span>
</div>
"""
html_text += "</div>"
self.result_text.setHtml(html_text)
3. 5. 系统关键技术实现
3. 5.1 非极大值抑制实现
def apply_nms(boxes, scores, iou_threshold):
# 按置信度排序
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
# 保留当前最高分框
i = order[0]
keep.append(i)
# 计算IOU
ious = calculate_iou(boxes[i], boxes[order[1:]])
# 保留IOU小于阈值的框
inds = np.where(ious <= iou_threshold)[0]
order = order[inds + 1]
return keep
3. 5.2 多线程处理逻辑
class DetectionThread(QThread):
finished = pyqtSignal(object)
def __init__(self, frame, model):
super().__init__()
self.frame = frame
self.model = model
def run(self):
results = self.model.predict(self.frame)
self.finished.emit(results)
# 在主窗口中使用
def process_frame(self, frame):
self.thread = DetectionThread(frame, self.model)
self.thread.finished.connect(self.show_results)
self.thread.start()
4 最后
项目包含内容

论文摘要

🧿 项目分享:大家可自取用于参考学习,获取方式见文末!


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









