




目录
SimpleFOC的教程比较多,做了一个总链接,欢迎点击阅读:SimpleFOC教程链接汇总
一、电机的三种控制模式
(为保证本文可读性,把之前写过的搬运到此。)
1.1、力矩控制模式
◎电机在运行过程的电流,始终等于给定的值。
◎比如使用电机来拉伸弹簧,设定电流值越大,弹簧被拉伸的长度越长。设定电流越小,弹簧被拉伸的长度越短。设定电流为零,弹簧不被拉伸。
◎在SimpleFOC项目中,受限于Arduino UNO的运行速度,大部分例程没有使用电流采样,所以设定电压值代替设定电流值。
1.2、速度控制模式
◎让电机始终按照设定的速度运转,不因负载的变化而变化。
◎速度控制一般会采用内环电流环,外环速度环的方式,所以可以限制转动过程中的电流不超过设定值。
◎比如传送带传送物品,给定的速度不会因为传送带上是空载或者带载发生变化,但是当负载过大,电流超过设定值的时候会报警或自动停止。
1.3、位置控制模式
◎精确控制电机转动到指定角度,
◎位置控制一般会采用内环电流环,外环速度环,最外环位置环的方式,所以可以限制转动过程中的最大速度,和最大电流。
◎比如机械臂从A点运动到B点,并限制挥舞过程中的最大速度和最大力矩。
二、硬件介绍
本节实验适合运行在SimpleMotor和STM32最小系统板上(Bluepill)。
2.1、原理图

2.2、SimpleMotor方案
2.2.1、准备清单
| 序号 | 名称 | 数量 |
|---|---|---|
| 1 | SimpleMotor | 1 |
| 2 | 带编码器云台电机 | 1 |
| 3 | USB转串口 | 1 |
| 4 | 12V电源 | 1 |

2.2.2、接线

只展示M1的接线,M2的接线根据原理图自行连接。
2.3、STM32方案
2.3.1、准备清单
| 序号 | 名称 | 数量 |
|---|---|---|
| 1 | STM32核心板 | 1 |
| 2 | SimpleFOCShield V2.0.3 | 1 |
| 3 | 带编码器的云台电机 | 1 |
| 4 | USB转串口 | 1 |
| 5 | 5V电源 | 1 |
| 6 | 12V电源 | 1 |
| 7 | 杜邦线 | 若干 |

2.3.2、接线

对照 Shield V2.0.3 的原理图:
| STM32核心板 | V2.0.3 |
|---|---|
| PA0 | 5 |
| PA1 | 9 |
| PA2 | 6 |
| PB9 | 8 |
| GND | GND |
| 如果是AS5600编码器,如下 | |
| STM32核心板 | AS5600电机 |
| ---- | ---- |
| PB6 | SCL |
| PB7 | SDA |
| 3V3 | VCC |
| GND | GND |
| 如果是TLE5012B编码器,如下 | |
| STM32核心板 | TLE5012电机 |
| ---- | ---- |
| PB15 | MOSI |
| PB14 | MISO |
| PB13 | SCK |
| PB8 | CSQ |
| GND | GND |
| 3V3 | VCC |

只展示M1的接线,M2的接线根据原理图自行连接。
三、控制原理
3.1、闭环控制原理
1、力矩模式

◎串口设定值为Uq,Ud固定为0;
◎控制原理与开环控制很像,核心代码是SVPWM;
◎开环的θ是人为设定的,而闭环的θ来自编码器。
2、速度模式

◎力矩闭环外增加了速度环;
◎串口设定值为期望速度(Vd);
◎实际速度和期望速度的差作为PID输入,输出值为SVPWM的输入(Uq),Ud固定为0;
◎编码器读到的角度为机械角度,先转为电角度供SVPWM使用(θ);
◎根据最近两次的角度差和时间差计算出当前速度(v),速度做滤波处理(Vf),因为速度要保持平滑不能突变;
3、位置模式

◎与速度环相比多了一个位置环,相应的要调试位置环PID,创作者的代码中只使用了P参数,实际应用中一般会用PD参数。
3.2、零点检测
一般的无刷电机驱动器会有个学习模式,用拨码开关切换,第一次使用先拨到学习模式,检测电机参数后保存到内部flash。然后切换到工作模式,驱动器每次上电都会导入存储的参数,执行控制。
SimpleFOC上电后也会检测电机参数,但是没有保存的动作,所以每次上电都要检测,对于带磁编码器的电机,需要检测机械角度和电角度的偏差(zero_electric_angle),和电机极对数(pole_pairs)。
机械角度零点和电角度的零点,在实际操作中基本是不可能对齐的,所以同学们不要有通过调整编码器角度,把零点对齐的这个想法。


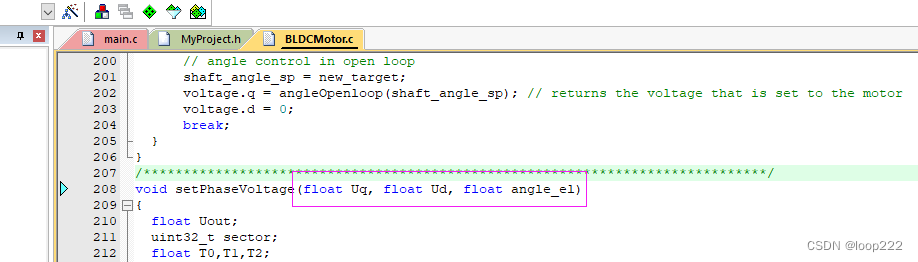
代码位置在:BLDCMotor.c,


3.3、零点检测代码简单说明
本小节20220814更新
关于代码中为什么要加 _3PI_2 的原因:

磁场方向为d轴,垂直于转子磁场方向为q轴,d轴建立磁场,q轴做功,
因为q轴是垂直磁场的,假如设置 θ=0°,电机最终停留在90°位置,所以要想让电机停留在0°,需设置 θ=270°。
而d轴是磁场方向,设置θ=0°,电机就停留在0°。
所以设置Uq=x,θ=270°,其效果等同于Ud=x,θ=0°。
以开环的方式实际测试,证明了确实是这样。
3.4、跳过零点检测说明
-
1、设置(0,UNKNOWN),烧写代码,

-
2、运行后电机会进行零点校准,获取两个参数,
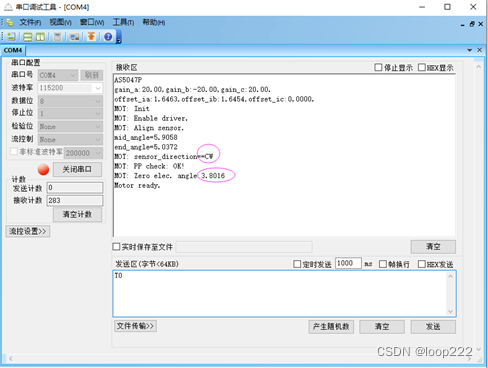
-
3、把获取的两个参数写入代码,编译后重新烧写,

-
4、运行后电机将跳过零点检测。
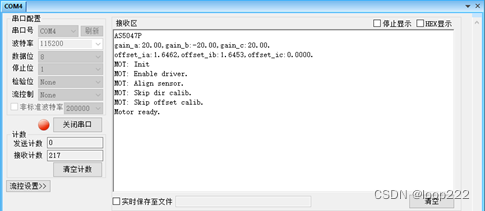
-
不同电机的零点参数不同,所以每个电机都要校准;
-
电机三相线如果有调整,需要重新校准。
四、程序演示



注意:如果检测到的极对数与实际不符,停止继续操作,否则电机会堵转
4.1、力矩模式
1、选择力矩模式,其它参数根据实际情况设置

2、编译下载
可以串口下载或者SWDIO下载;
如果是串口下载,Boot加上跳线帽,下载完毕后拿掉跳线帽,按复位键重启或者断电重启。
注意:复位重启只能重启单片机,编码器没有重启,这可能会导致重启后的I2C接口编码器不能正确读出,SPI接口编码器不受影响。
3、等待初始化完成
4、串口发送指令,此时发送的数据表示电压值Uq
注意:设置的电压值不能超过voltage_power_supply/√3,比如电源电压12V,设置不能超过6.92V。

5、给电机施加阻力,感受不同电压对应不同的力矩
注意:力矩模式不涉及PID,所以比较简单,大功率电机设置电压值不能太大。
4.2、速度模式
1、选择速度模式

注意:PID参数根据电机实际情况自行设置,不了解PID设置的请百度。
2、编译下载
3、重新上电,等待电机初始化完成
4、串口发送指令T6.28,观察电机是否以1圈/秒的速度转动。

5、设置不同速度,观察电机转动变化。给电机施加阻力,观察电机转动
4.3、位置模式
1、选择位置模式

注意:本例中,位置模式包含了位置PID和速度PID,根据电机实际情况自行设置,不了解PID的请百度。
2、编译下载
3、重新上电,等待电机初始化完成
4、串口发送指令T6.28,观察电机是否转动一圈
上电后为了保证电机为静止状态,设置初始化后的目标角度为当前角度,所以第一次设置角度6.28,电机不会转一圈。第一次可以设置目标角度为0。

(完)
本文只讲了M1电机的操作,源码中包含M1和M2两个工程,M2的操作可比照M1,不再赘述!
请继续阅读相关文章:
SimpleFOC移植STM32(一)—— 简介
SimpleFOC移植STM32(二)—— 开环控制
SimpleFOC移植STM32(三)—— 角度读取
SimpleFOC移植STM32(四)—— 闭环控制
SimpleFOC移植STM32(五)—— 电流采样及其变换

















 1682
1682










 到【灌水乐园】发言
到【灌水乐园】发言







