




 本文深入探讨了使用 PyTorch 实现的 Seq2Seq 模型,并介绍了如何结合 Attention 机制以提高翻译等任务的性能。文章首先介绍了 Seq2Seq 基础,然后详细解释了 Attention 机制的工作原理,特别是 Concat 式 Attention 的计算过程。接着,给出了 Encoder 和 Decoder 的实现代码,并展示了 Attention 层的输出。最后,演示了整个解码过程,强调了 Attention 在解码中的作用。
本文深入探讨了使用 PyTorch 实现的 Seq2Seq 模型,并介绍了如何结合 Attention 机制以提高翻译等任务的性能。文章首先介绍了 Seq2Seq 基础,然后详细解释了 Attention 机制的工作原理,特别是 Concat 式 Attention 的计算过程。接着,给出了 Encoder 和 Decoder 的实现代码,并展示了 Attention 层的输出。最后,演示了整个解码过程,强调了 Attention 在解码中的作用。
本文主要参考github上一个开源的seq2seq教程,在此基础上稍作修改
https://github.com/bentrevett/pytorch-seq2seq/blob/master/3%20-%20Neural%20Machine%20Translation%20by%20Jointly%20Learning%20to%20Align%20and%20Translate.ipynb
1.Seq2Seq模型
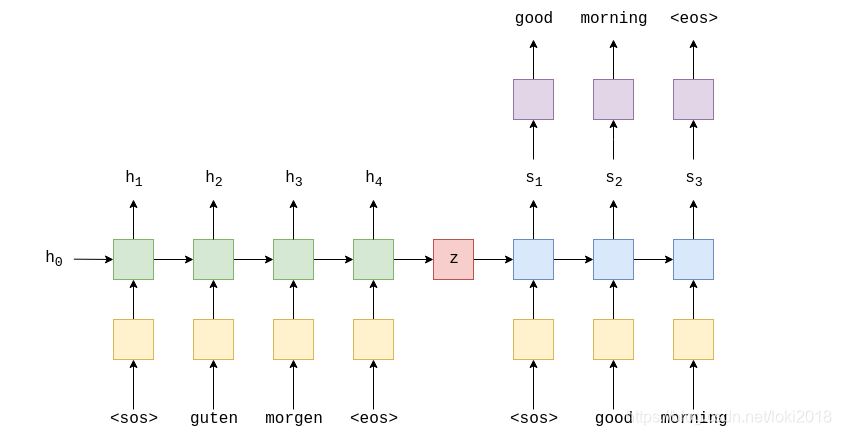
在我上一篇文章有这个代码,原理就是一开始利用编码器的hidden,解码器去生成相应的字符。
2.Attention机制
虽然Seq2Seq模型可以通过encoder生成的上文信息来生成相应的字符或者词语,但是却不能理解encoder中输入序列中句子内部的词语和词语,字符和字符之间潜在的关系。例如我们做翻译的时候,要将英文中的动词转化为中文,我们应该更关注英文中的动词词汇。这就是attention机制,它可以告诉我们每次翻译时更应该关注英文中的哪一部分。
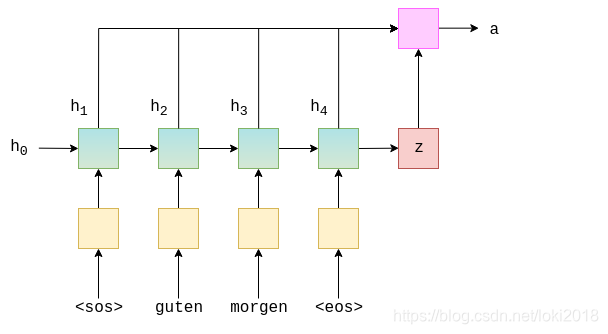
计算权重的方式有很多,这里介绍最基础的一种:concat
原理是通过encoder每层最后一个状态和encoder中每个输入进行相应计算,最后得到一个权重向量。如图所示,将encoder的输入和s0叠加之后,经过两个线性变换得到权重向量。得到的权重每次decoder做解码的时候都要更新一次。因此attention的计算量要比传统的Seq2Seq要大的多。
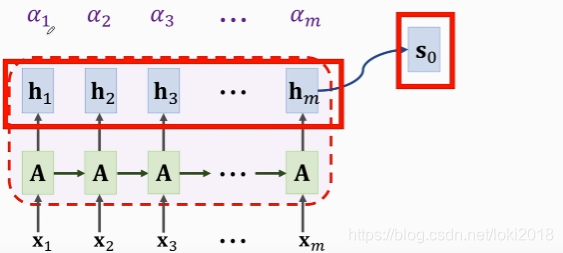
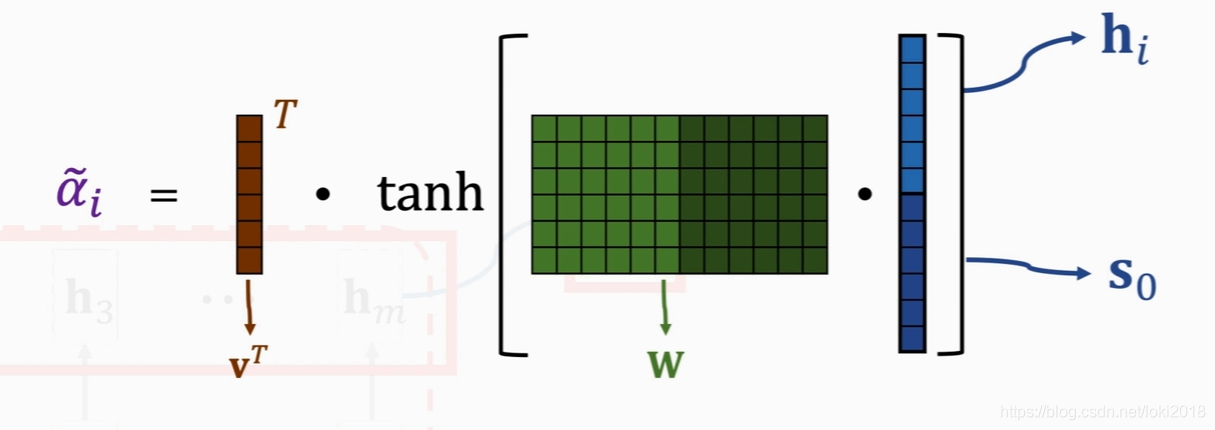
3.代码
首先是Encoder,和传统的Seq2Seq基本没有区别,只是多了一个要输出最后一层的状态。
# 此例子默认编码器解码器的hidden_size相同
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_size, n_layers, dropout=0.5, bidirectional=True):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim) # input_dim数量等于源语言的字符数
self.gru = nn.GRU(emb_dim, hidden_size, n_layers, dropout=dropout, bidirectional=bidirectional)
self.fc = nn.Linear(hidden_size*2, hidden_size)
def forward(self, input_seqs):
# input_seqs [seq_len, batch]
embedded = self.embedding(input_seqs)
# embedded [seq_len, batch, embed_dim]
outputs, hidden = self.gru(embedded)
# outputs [seq_len, batch, hidden_size * 2]
# hidden is stacked [forward_1, backward_1, forward_2, backward_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









