




等级变量与连续变量之间的相关性分析的概念:
等级变量与连续变量相关性分析是指研究和量化等级变量与连续变量之间关系的方法。其目的是探讨一个有序类别变量(等级变量)如何与一个连续变量相关,或者等级变量不同水平是否对连续变量产生显著影响。
1. 等级变量与连续变量的定义
a. 等级变量(Ordinal Variable)
等级变量是一种分类变量,其类别之间有明确的顺序关系,但各类别之间的距离不一定相等。例如:
- 教育程度(小学、中学、大学、研究生)
- 满意度(非常不满意、不满意、一般、满意、非常满意)
- 健康评分(差、一般、好、非常好)
b. 连续变量(Continuous Variable)
连续变量可以在某一范围内取任意值,具有大小和顺序,且可以量化差距。例如:
- 体重、身高、收入、血压
- 考试分数、温度、年龄
2. 等级变量与连续变量相关性分析的意义
通过等级变量与连续变量相关性分析,可以回答以下问题:
- 等级变量的顺序变化是否会引起连续变量的显著变化。
- 连续变量是否随着等级变量的增加呈现某种趋势,如正相关、负相关或无相关。
这种分析广泛应用于社会科学、市场分析、医学研究等领域。例如:
- 分析教育水平(等级变量)是否影响收入(连续变量)。
- 探讨健康评分(等级变量)与体重指数(BMI,连续变量)之间的关系。
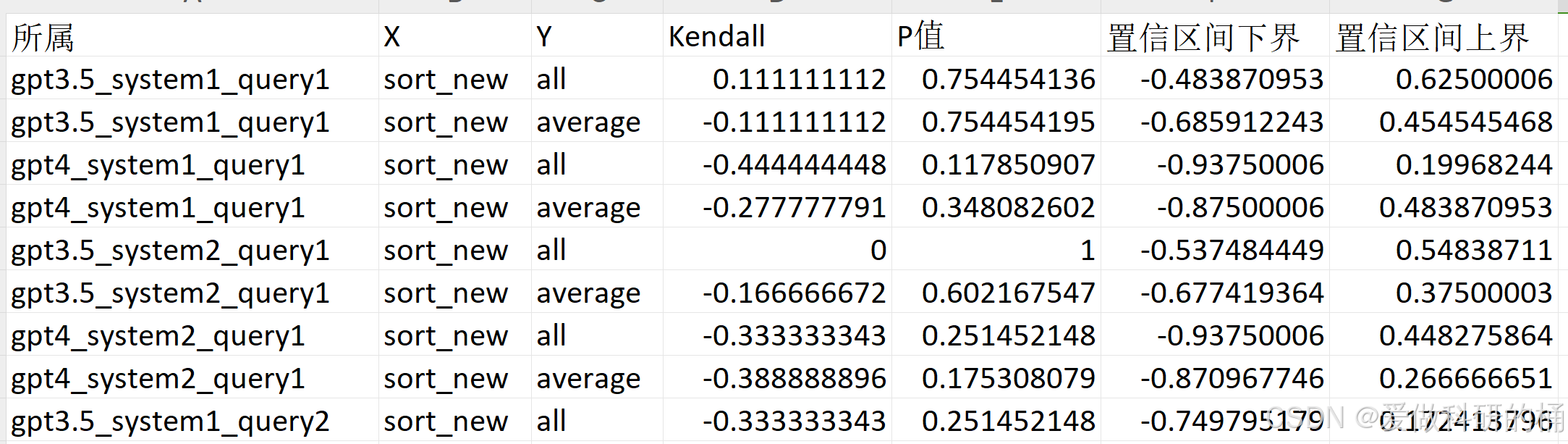
代码:
第一部分:加载所需包
library(ggplot2)
library(dplyr)
library(tidyr)
library(gridExtra)
library(openxlsx)
library(readxl)
library(MASS)
library(VGAM)
library(polycor)
library(DescTools)
library(Kendall)
library(boot)
- 主要功能:
- 数据处理:
dplyr、tidyr。 - 数据输入输出:
openxlsx、readxl。 - 统计分析:
Kendall、boot、DescTools、polycor等。 - 这些包为数据清理、相关性计算和结果保存提供了全面支持。
- 数据处理:
第二部分:数据导入与检查
mydata <- read.xlsx("combined_data【含sort】.xlsx")
cat("数据结构检查:\n")
str(mydata)
-
读取数据:
read.xlsx("combined_data【含sort】.xlsx"):从 Excel 文件中加载数据。- 文件名为
combined_data【含sort】.xlsx,包含用于分析的各类数据。
-
结构检查:
str(mydata):输出数据框的结构,检查变量类型和数据完整性。
第三部分:数据转换
mydata <- mydata %>%
mutate(
across(c(gpt, system, query), ~ factor(.x, ordered = TRUE)),
sort_new = factor(
sort,
labels = c("10%", "20%", "30%", "40%", "50%", "60%", "70%", "80%", "90%"),
ordered = TRUE
)
)
cat("转换后数据结构:\n")
str(mydata)
-
转换变量为因子:
- 使用
mutate和across将gpt、system和query转为有序因子。 sort_new列重命名并设为有序因子,代表比例值。
- 使用
-
再次检查数据结构:
str(mydata):确认转换后的变量类型是否符合预期。
第四部分:定义计算 Kendall's Tau 的函数
calculate_kendall <- function(var1, var2, data) {
# 数据检查
if (nrow(data) < 3) {
stop("数据行数不足,无法计算 Kendall's Tau")
}
if (any(is.na(data[[var1]])) || any(is.na(data[[var2]]))) {
stop("数据中存在 NA 值,请清理数据")
}
# 计算 Kendall's Tau-b 和显著性
kendall_result <- Kendall(data[[var1]], data[[var2]])
# 自举法计算置信区间
boot_kendall <- function(data, indices) {
d <- data[indices, ]
Kendall(d[[var1]], d[[var2]])$tau
}
set.seed(123)
boot_result <- boot(data, boot_kendall, R = 1000)
ci <- boot.ci(boot_result, type = "perc")
ci_lower <- if (!is.null(ci$percent)) ci$percent[4] else NA
ci_upper <- if (!is.null(ci$percent)) ci$percent[5] else NA
# 返回结果
data.frame(
X = var1,
Y = var2,
Kendall = kendall_result$tau,
P值 = kendall_result$sl,
置信区间下界 = ci_lower,
置信区间上界 = ci_upper
)
}
-
功能:
- 针对两列变量,计算 Kendall's Tau 相关系数及其显著性水平。
- 通过自举法(
boot包)计算 Tau 的置信区间。
-
数据检查:
- 如果数据行数不足或存在 NA 值,会终止执行并给出提示。
-
自举法:
boot_kendall是定义的自举函数,通过随机采样计算 Tau。boot.ci用于提取百分位置信区间。
-
返回值:
- 返回一个数据框,包括相关系数、p 值及置信区间上下界。
第五部分:生成分组组合并计算相关性
group_combinations <- expand.grid(
gpt = c("gpt3.5", "gpt4"),
system = c("system1", "system2"),
query = c("query1", "query2"),
stringsAsFactors = FALSE
)
- 创建分组组合:
- 使用
expand.grid生成所有可能的分组组合。 - 每个分组由
gpt、system和query定义。
- 使用
results <- purrr::map_dfr(seq_len(nrow(group_combinations)), function(i) {
group <- group_combinations[i, ]
mydata_subset <- mydata %>%
filter(
gpt == group$gpt,
system == group$system,
query == group$query
)
if (nrow(mydata_subset) >= 3) {
group_name <- paste(group, collapse = "_")
rbind(
cbind(所属 = group_name, calculate_kendall("sort_new", "all", mydata_subset)),
cbind(所属 = group_name, calculate_kendall("sort_new", "average", mydata_subset))
)
} else {
cat("跳过分组:", paste(group, collapse = "_"), "数据不足 3 行\n")
NULL
}
})
-
遍历分组组合:
- 对每个分组筛选数据子集(
filter)。 - 如果数据子集行数不足 3,跳过计算。
- 对每个分组筛选数据子集(
-
计算相关性:
- 调用
calculate_kendall计算每个分组的相关系数。
- 调用
-
结果整合:
- 使用
purrr::map_dfr将所有结果整合为一个数据框。
- 使用
第六部分:保存结果
final_results <- bind_rows(results, global_results)
write.xlsx(final_results, "相关性分析.xlsx", rowNames = FALSE)
cat("相关性分析完成,结果已保存为 相关性分析.xlsx\n")
-
结果保存:
- 将计算结果保存为 Excel 文件
相关性分析.xlsx。 bind_rows合并结果,write.xlsx写入文件。
- 将计算结果保存为 Excel 文件
-
完成提示:
cat打印提示信息。
总结:
# ------- 加载所需包 -------
library(ggplot2)
library(dplyr)
library(tidyr)
library(gridExtra)
library(openxlsx)
library(readxl)
library(MASS)
library(VGAM)
library(polycor)
library(DescTools)
library(Kendall)
library(boot)
# ------- 数据导入与检查 -------
mydata <- read.xlsx("combined_data【含sort】.xlsx") # 导入 Excel 数据
cat("数据结构检查:\n")
str(mydata)
# ------- 数据预处理 -------
mydata <- mydata %>%
mutate(
across(c(gpt, system, query), ~ factor(.x, ordered = TRUE)), # 转为有序因子
sort_new = factor(
sort,
labels = c("10%", "20%", "30%", "40%", "50%", "60%", "70%", "80%", "90%"),
ordered = TRUE
)
)
cat("转换后数据结构:\n")
str(mydata)
# ------- 定义计算 Kendall's Tau 的函数 -------
calculate_kendall <- function(var1, var2, data) {
# 数据检查
if (nrow(data) < 3) {
stop("数据行数不足,无法计算 Kendall's Tau")
}
if (any(is.na(data[[var1]])) || any(is.na(data[[var2]]))) {
stop("数据中存在 NA 值,请清理数据")
}
# 计算 Kendall's Tau 和显著性
kendall_result <- Kendall(data[[var1]], data[[var2]])
# 自举法计算置信区间
boot_kendall <- function(data, indices) {
d <- data[indices, ]
Kendall(d[[var1]], d[[var2]])$tau
}
set.seed(123) # 确保结果可重复
boot_result <- boot(data, boot_kendall, R = 1000)
ci <- boot.ci(boot_result, type = "perc")
ci_lower <- if (!is.null(ci$percent)) ci$percent[4] else NA
ci_upper <- if (!is.null(ci$percent)) ci$percent[5] else NA
# 返回结果
data.frame(
X = var1,
Y = var2,
Kendall = kendall_result$tau,
P值 = kendall_result$sl,
置信区间下界 = ci_lower,
置信区间上界 = ci_upper
)
}
# ------- 生成分组组合并计算相关性 -------
# 创建所有分组组合
group_combinations <- expand.grid(
gpt = c("gpt3.5", "gpt4"),
system = c("system1", "system2"),
query = c("query1", "query2"),
stringsAsFactors = FALSE
)
# 遍历每个分组组合
results <- purrr::map_dfr(seq_len(nrow(group_combinations)), function(i) {
group <- group_combinations[i, ]
# 筛选对应分组的数据
mydata_subset <- mydata %>%
filter(
gpt == group$gpt,
system == group$system,
query == group$query
)
if (nrow(mydata_subset) >= 3) {
group_name <- paste(group, collapse = "_")
rbind(
cbind(所属 = group_name, calculate_kendall("sort_new", "all", mydata_subset)),
cbind(所属 = group_name, calculate_kendall("sort_new", "average", mydata_subset))
)
} else {
cat("跳过分组:", paste(group, collapse = "_"), "数据不足 3 行\n")
NULL
}
})
# ------- 保存结果 -------
write.xlsx(results, "相关性分析.xlsx", rowNames = FALSE) # 保存为 Excel 文件
cat("相关性分析完成,结果已保存为 相关性分析.xlsx\n")


















 2409
2409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











