




模型小型化的工作,把肥肉去掉只保留肌肉。
我的理解
参考文章及代码:
通俗易懂的知识蒸馏 Knowledge Distillation(下)——代码实践(附详细注释) - 知乎
重点在于软硬目标训练的损失函数的加入,使得学生模型的准确率比原来高。
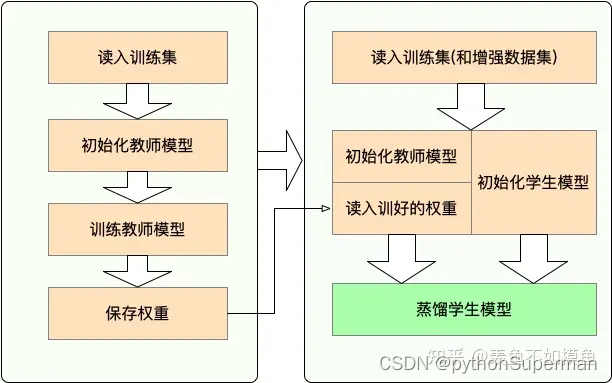
教师模型训练后,学生模型再训练,在学生模型训练的时候,数据要经过训练好的教师模型和待训练的学生模型,再通过知识蒸馏指定的损失函数(参数有学生的输出,教师的输出,温度及其他参数),再反向传播,最后更新学生模型的梯度。
为什么叫做知识的蒸馏?
蒸馏是一种有效的分离不同沸点组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。化学蒸馏条件:(1)蒸馏的液体是混合物;(2)各组分沸点不同。
蒸馏的液体是混合物,这个混合物一定是包含了各种组分,即在我们今天讲的知识蒸馏中指原模型包含大量的知识。各组分沸点不同,蒸馏时要根据目标物质的沸点设置蒸馏温度,即在我们今天讲的知识蒸馏中也有“温度”的概念,那这个“温度“代表了什么,又是如何选取合适的”温度“?这里先埋下伏笔,在文中给大家揭晓答案。
温度作为临界点,会提取出更加精华的东西。(类比于模型的压缩)
进入我们今天正式的主题,到底什么是知识蒸馏?一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型(老师模型)学习到的知识去指导小模型(学生模型)训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3087
3087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









