




 本文介绍了Google在2021年关于优化RNN-T解码器的研究,旨在在不降低性能的情况下,提高语音识别速度。通过改进预测网络和共享嵌入权重,模型参数量减少了90%,速度提升了2到3倍。
本文介绍了Google在2021年关于优化RNN-T解码器的研究,旨在在不降低性能的情况下,提高语音识别速度。通过改进预测网络和共享嵌入权重,模型参数量减少了90%,速度提升了2到3倍。
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
Tied & Reduced RNN-T Decoder
本文为google在2021.09.15发表的文章,主要的工作为优化rnn-t的decoder模型大小,使其在性能不下降的情况下,速度提高3到4倍。具体的文章链接
https://arxiv.org/pdf/2109.07513.pdf
1 研究背景
近几年的端到端语音识别受到更多人的关注,具有代表性的系统为RNN-T。边缘设备的爆炸式增长,增加在边缘设备上运行端到端语音识别系统的需求,因此本文主要研究在不牺牲系统性能情况下,优化RNN-T的decoder的大小。
2 详细设计
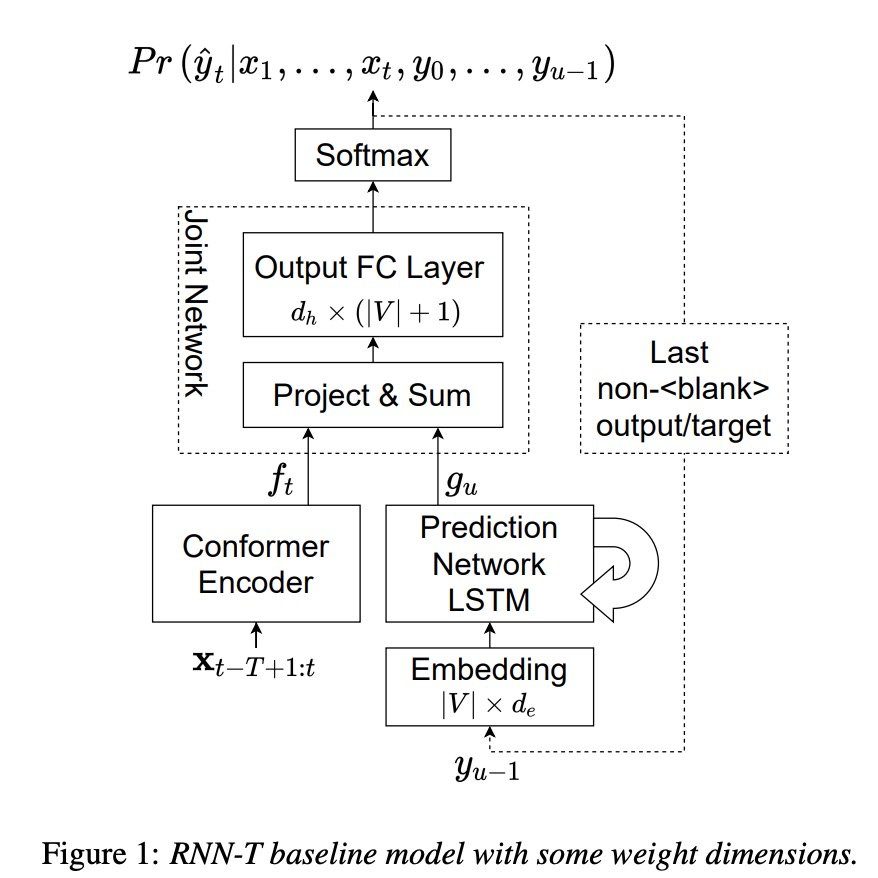
RNN-T架构如图1所示,主要由三部分组成:encoder,predicition network (PN)和 joint network。本文主要优化prediction network和joint network部分。第一个优化方案是对prediction的优化,如如图2所示。该网络替换掉了LSTM结构。PN网络中的Pn为位置向量,En为embedding 向量,N为context的长度。其中average和multihead求平均如下面的公式。第二个优化方案称为tied embeddings,该方案就是把图1中de和dh大小设置一样,然后把embedding和fc layer的weights进行共享,这样就大大较少decoder的参数量。可参考table1所示,本文的ReducedSmall参数只有1.9M,而原始lstm为23M。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











