




声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling
本文是facebook在20210.04.01更新的文章,主要提出multi-rate attention减少latency,使其无论句子长短都保持RTF稳定,具体的文章链接
https://arxiv.org/pdf/2104.00705.pdf
1 研究背景
典型的tts主要分为两个阶段:生成声学特征的阶段和声码器阶段。然而现有的模型的latency和real-time factor跟句子的长度有关,句子越长,以上的两个指标越长,这不利于要求较少latency的服务。本文提出了multi-rate attention从而使较少latency和RTF。
2 详细设计
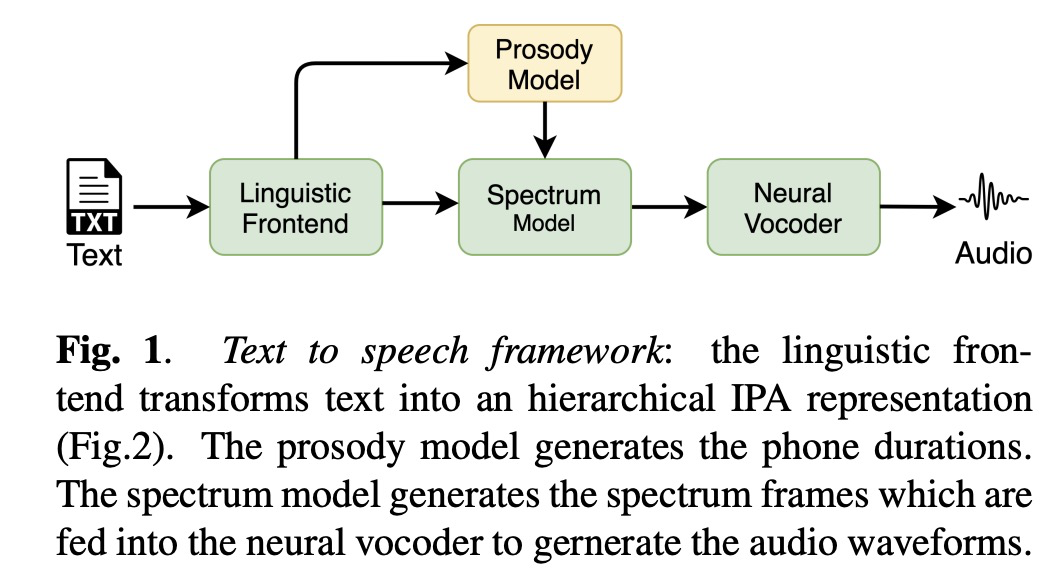
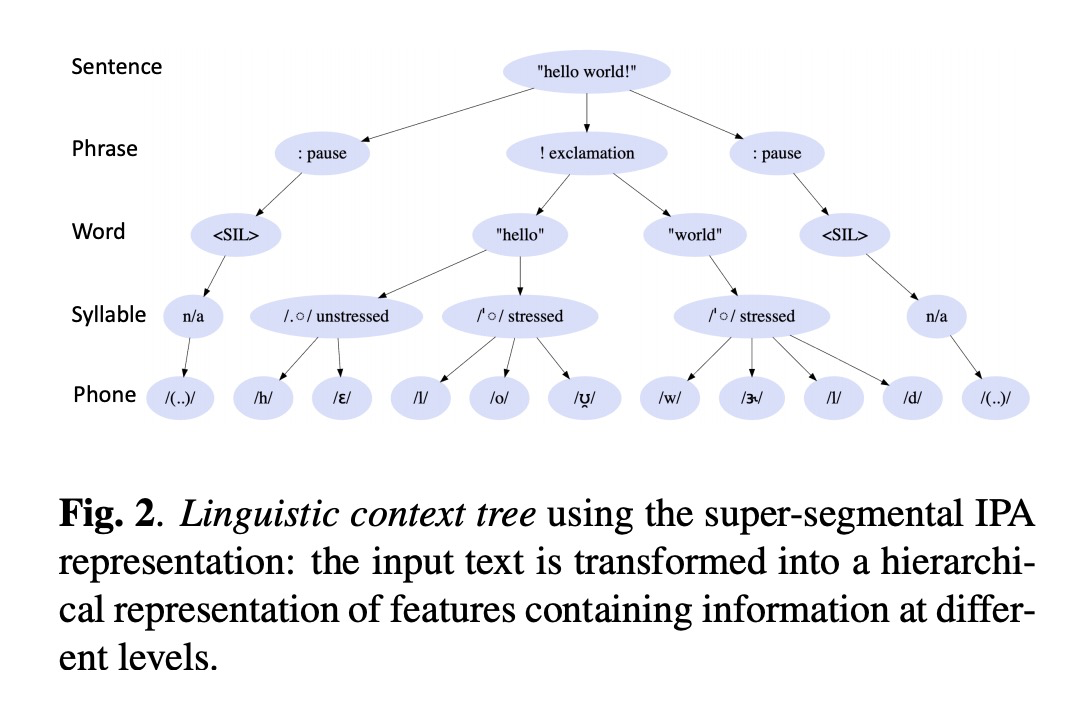
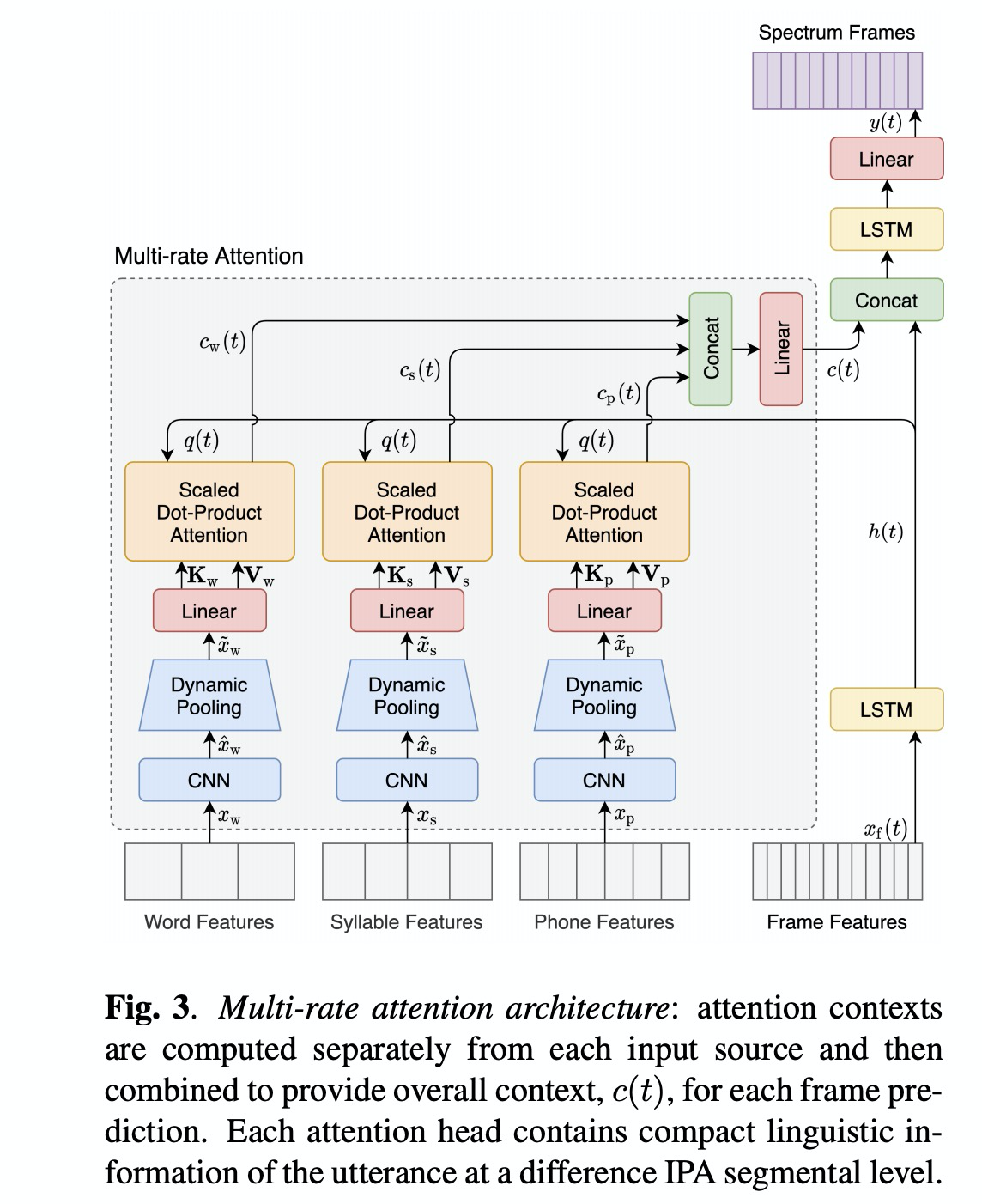
整体的架构如图1所示,其中linguistic frontend把文本转成图2中的多层级的语言特征,prosody model生成帧级特征,该特征主要由帧的位置,音素时长和f0等等。其中本文的spectrum model如图3所示,muti-rate attention的query的帧级别的特征,k,v为word ,syllable 和phone各自生成。
3 实验结果
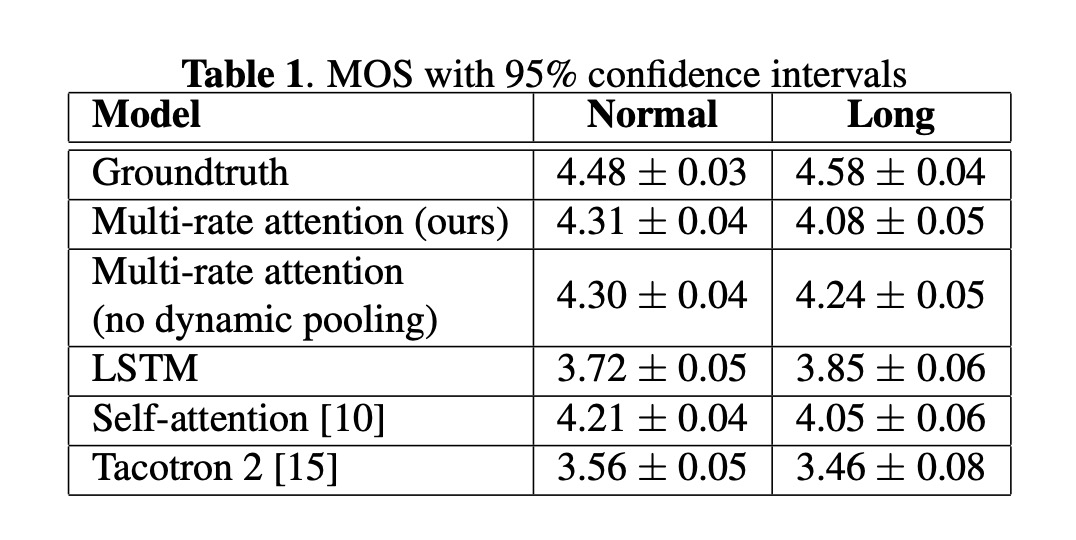
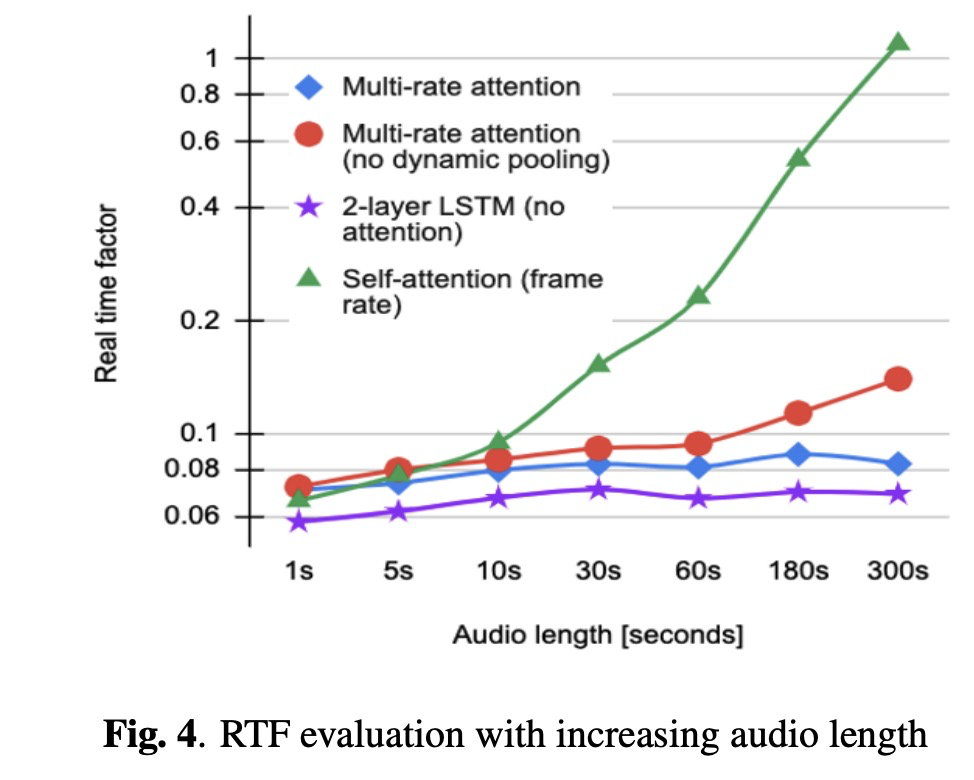
MOS的结果如table 1所示,其中本文mulit-rate attention效果最好(对该结果我感觉有些问题,尤其tacotron 2竟这么低?不做太多评论)。另外RTF的随着句子长度的变化情况,本文的mulit-rate attention变化很小。
4 总结
本文提出了提出multi-rate attention减少latency,使其无论句子长短都保持RTF稳定。



















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











