




1.Introduction
At present, the traditional speech-to-text translation is implemented by two models, the cascaded model and the end-to-end model.
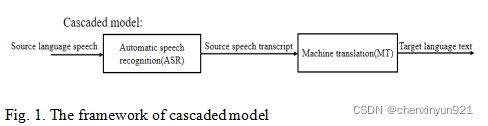
The cascaded model divides speech-to-text translation into two parts. The first part is to convert the speech in the source language into text in the source language, which is called automatic speech recognition (ASR). The second part is to translate the source language text into the target language text, which is called machine translation (MT). It needs to complete ASR first to complete MT.
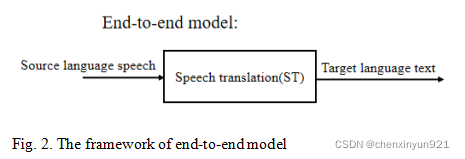
End-to-end model is to construct a complete neural network model, and jointly optimize speech recognition, post-recognition processing and machine translation, and establish the mapping relationship between source language speech signal and target language text, then implements the translation from source speech to target translation. In other words, the end-to-end model takes the source language speech as input and directly outputs the target language text after passing through the model. It integrates all speech translation functions into a single model, unlike the cascaded model, which has an intermediate result, the source language transcript. Note that although end-to-end systems are very promising, cascaded systems still dominate practical deployment in industry.[1]
The two models have some advantages. (a)The end-to-end model has advantages such as lower latency, smaller model size, and less error accumulation.[1] (b)For cascaded model, it can make better use of the independent speech recognition or machine translation corpus.
2.Problems
Although the two models have some advantages, they also have some disadvantages.
A.The disadvantages of the end-to-end model
The first disadvantage of the end-to-end model is that it is too complex, because it integrates multiple learning tasks into a single model, which places a great burden on a single model. Another disadvantage is that it cannot make full use of the external ASR or MT corpus. That is because the end-to-end model has only one input of source language speech and directly outputs target language text, which means the training dataset of end-to-end model is composed of source language speech and target language text. However, the training dataset of external ASR corpus is source language speech and source transcript, while the training dataset of external MT corpus is source transcript and target language text. Due to the different composition of training dataset, end-to-end model cannot make use of external ASR or MT corpus.
B.The disadvantages of the cascaded model
The main disadvantage of cascaded model is error accumulation. Because the cascaded model needs to complete the MT after completing the ASR, there will be errors propagation during this process. In the ASR stage, there may be recognition errors due to complex factors such as the speaker’s accent, environmental noise, and homophones or easily confused words in the language. The output of the ASR will continue to be used as the input of the MT, where an error propagation will occur, and incorrect speech recognition will cause incorrect source t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









