




声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention
本文是icassp2018的文章,是语音合成端到端兴起的初始文章,本文章是使用卷积网络来替代rnn网络,从而提升速度,文章链接
https://arxiv.org/pdf/1710.08969.pdf
(我看这篇文章主要是为了总结attention,本文提出Guided Attention。另外本文很多符号,看着很唬人)
1 研究背景
基于端到端的语音合成在2017年开始兴起,但端到端的系统大多使用rnn层,因此限制了训练速度,本文尝试使用卷积网络来实现端到端系统。实验证明只使用15小时就可以训练出较好的模型。
2 系统结构
该系统结构如图1所示,跟tacotron的结构差不多,不过该系统的encoder和decoder都是用卷积来实现。textenc使用non-causal convolution 而audioenc和audioDec使用causal convolution。具体的每层结构如图2所示(全部使用符号来表示,有兴趣的读者可以自己阅读,其实不难)。
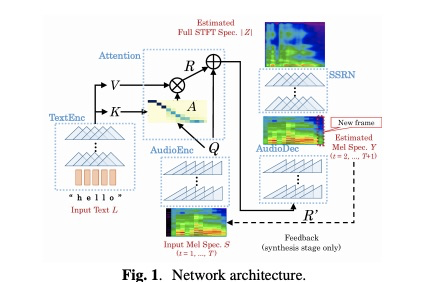

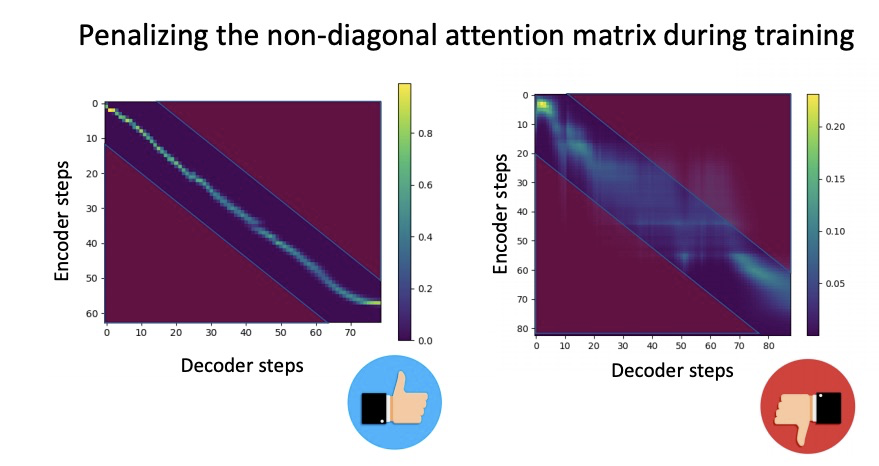
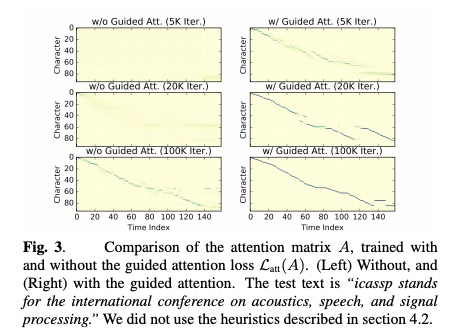
其实我比较感兴趣的部分是本文提出guided attention。因为音频具有时序性,因此attention的对齐满足对角线n~at,其中a~N/T(图片借鉴一下李宏毅老师的ppt)。guided attention把该条件带入到attention的限制中,每当对齐的值偏离该对角线,就要对齐惩罚。其函数如下所示。
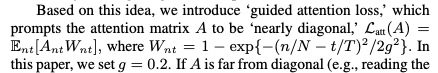

3 实验
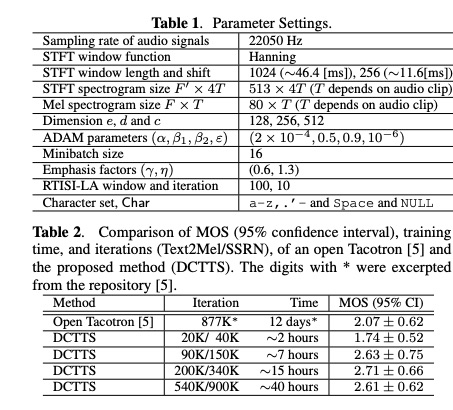
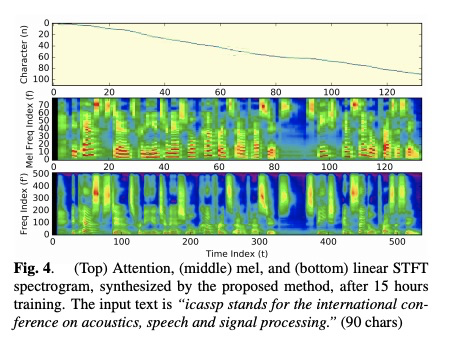
table 1列出本文的参数设置。table2实验与tacotron(tacotron刚提出系统)对比试验,由结果可以看出,本文提出的DCTTS花费15小时就可以获得较好的模型。图3和图4展示本文的guided attention的效果。
4 总结
本文章是使用卷积网络来替代rnn网络,从而提升速度。另外本文提出guided attention使该系统attention收敛更加迅速。



















 4395
4395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











