




声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
EmoCat: Language-agnostic Emotional Voice Conversion
本文为瑞士马蒂尼,艾迪亚普研究所在2021.01.14更新的文章,文章主要做情感语音转换,即只进行情感的转换。具体的文章链接
https://arxiv.org/pdf/2101.05695.pdf
1 研究背景
情感语音转换(emotional voice conversion)是语音转换的研究子领域,该研究的任务是保持音频内容和说话者的信息不变,改变音频的情感。本文主要研究非平行数据的转换,即转换的源音频和目标音频的内容不一样。本文实验只使用45分钟的德语情感就可以进行多等级的情感转换控制。
2 详细设计
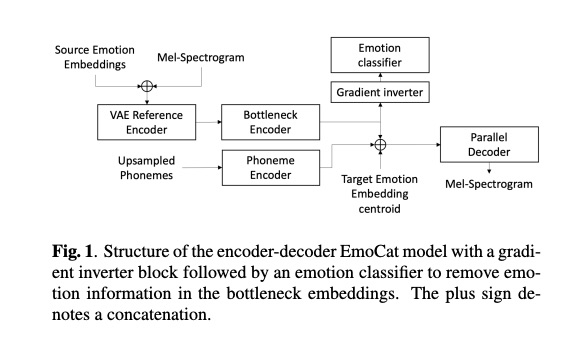
详细的系统如图1所示,该系统🈶vae encoder, bottleneck encoder, phoneme encoder和parallel decoder组成。首先可以看到vae reference encoder和decoder都需要emotion embedding。该embedding可以使用情感识别系统生成,或者使用类似tacotron-tts中的reference encoder获取该embedding,也可以联合训练获取,但需要大量情感数据来训练该embedding。其次,bottleneck encoder的输出往往带入原始音频的情感,因此需要对该部分的输出进行情感信息的过滤,常用的方法是使用公式1进行梯度翻转。本文在此基础上提出了公式2和公式3样式的梯度翻转器。最后,本文也进行微调的训练策略。


3 实验
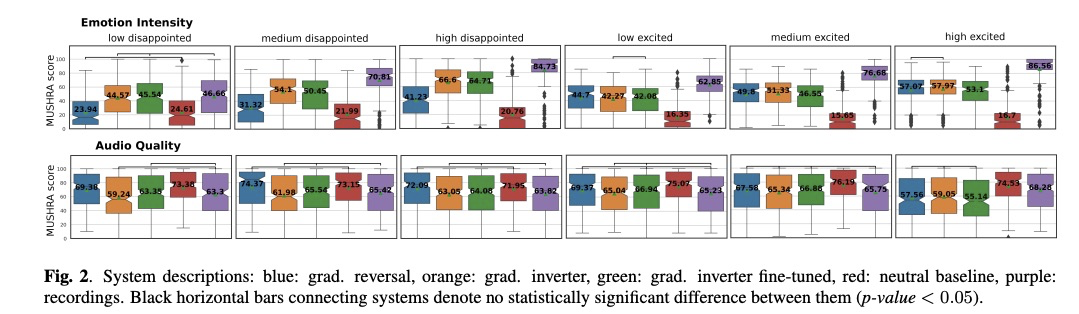
本文的实验很简单,在德语的两种情感兴奋和失望上进行测试。结果如图2所示,蓝色为原始的梯度翻转,橙色为本文改进的梯度翻转器,绿色为梯度翻转器加上微调策略,红色为中性语料基准,紫色为原始情感音频。第一行为情感强烈等级,可以看出橙色和绿色最接近紫色。第二列为音频质量,橙色和绿色最低,因此需要在情感控制和音频质量之间进行权衡。
4 总结
本文主要研究非平行数据的转换,即转换的源音频和目标音频的内容不一样。本文实验只使用45分钟的德语情感就可以进行多等级的情感转换控制。


















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











