




 本文介绍了华为诺亚方舟实验室的一项研究,将韵律预测和多音字消歧整合在基于Distilled BERT的统一模型中,通过知识蒸馏优化模型大小和预测准确性。实验结果显示,尽管模型大小仍较大,但在语音合成前端任务上表现出色。
本文介绍了华为诺亚方舟实验室的一项研究,将韵律预测和多音字消歧整合在基于Distilled BERT的统一模型中,通过知识蒸馏优化模型大小和预测准确性。实验结果显示,尽管模型大小仍较大,但在语音合成前端任务上表现出色。
声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Unified Mandarin TTS Front-end Based on Distilled BERT Model
本文章是华为诺亚方舟实验室在2020.12.31更新的文章,主要做语音合成前端的工作,把韵律预测和多音字消歧进行同时预测,具体的文章链接
https://arxiv.org/pdf/2012.15404.pdf
(语音合成前端的文章真是稀少,阅读起来感觉倍感轻松有趣)
1 研究背景
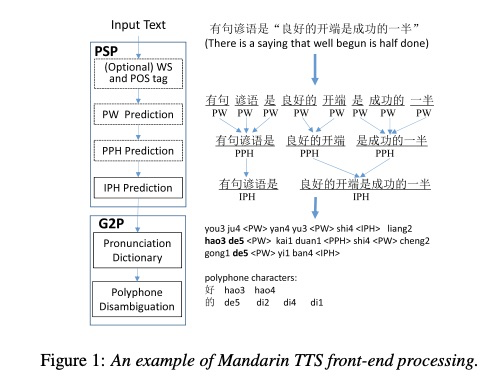
语音合成前端的主要工作是把输入的内容转换到统一格式的语言特征序列,其中最主要的两个工作是韵律预测PSP:prosodic structure prediction 和G2P: grapheme-to-phoneme,具体实例如图1所示,其中中文的g2p最艰难的任务是多音字消歧,因此本文把韵律预测和多音字消歧工作进行统一建模,使模型大小和预测准确度都得到优化。
2 详细设计
本文使用预训练的中文bert上进行多任务训练,具体如图2所示,对于多音字消歧主要是分类任务,把所有多音字的拼音个数作为分类种类,然后预测概率。韵律预测本文进行统一预测,不再单独预测pw.pph和iph三级预测,具体事例如图3所示。两者训练的loss为公式3,其中α为可调节的超参。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1829
1829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











