




声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
pretraining strategies, waveform model choice, and acoustic configurations for multi-speaker end-to-end speech synthesis
本文是日本国立情报学研究所在2020.11.10更新的文章,文章也是分享经验为主。该文章主要在预训练策略,声码器选择,采样率大小等因素进行试验,展示其对多说话人模型的影响,具体的文章链接https://arxiv.org/pdf/2011.04839.pdf
1 研究背景
multi-speaker tts需要大量的训练语料,因此pretraining策略对该任务具有重要的意义。本文章就是探索pretraining策略对multi-speaker模型的影响,主要包括预训练语料库的选择,声码器的选择等等。本文章主要使用vctk的数据作为multi-speaker模型训练语料,Nancy, LJSpeech, libriTTS clean-360和libriTTS other-500作为pretraining的语料,具体的各项参数如table 1展示,重点看一下SNR信噪比的大小,展示语料的干净程度。本文章主要对比语音的自然度,可懂度,相似度,错误率等指标进行对比试验。

2 实验
本文实验选择的音频包括24khz和16khz,声码器为Wavenet和WaveRNN。具体的语料库和训练策略搭配如下图显示,后边试验使用的名称为图中加粗缩写:

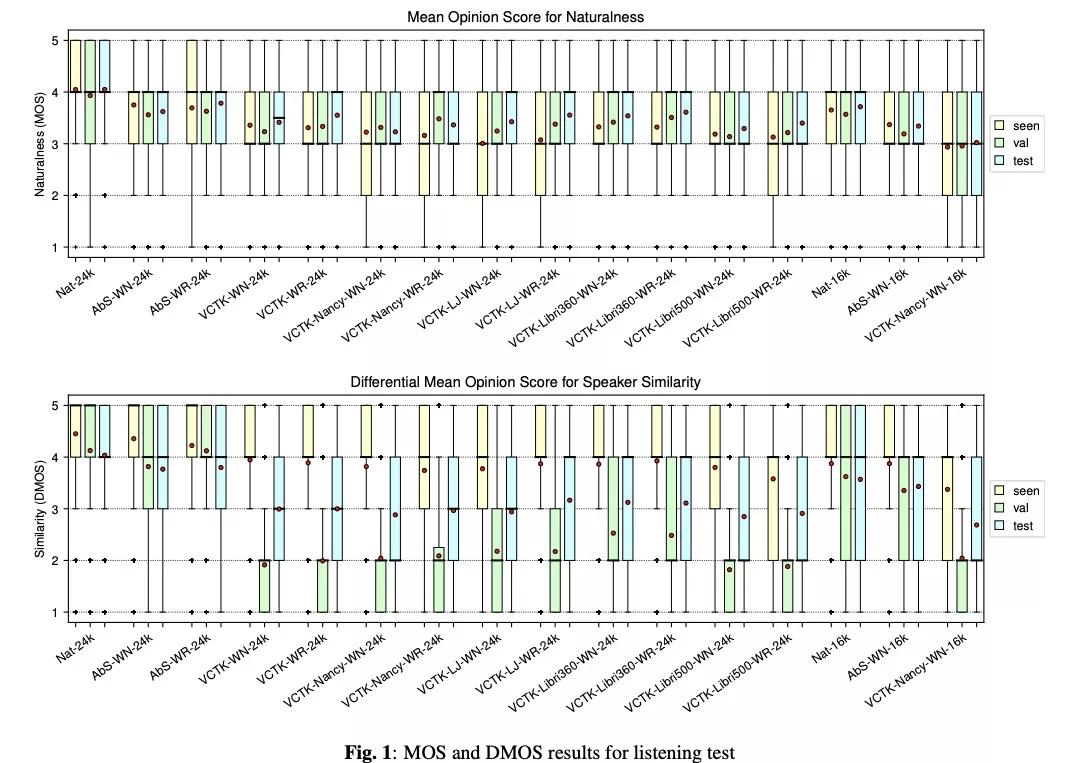
实验结果图1展示了各项实验策略MOS值的大小,从该结果得到如下几个结论:1)对vctk-nancy-wn-16k和vctk-nancy-wn-24k进行对比,得到24k的效果优于16k,因此音频采样率高的合成效果较优;2)WN和WR进行对比,结果wavenet和wavernn的mos差不多,合成音质差不多,但wavernn的复杂度小于wavenet;3)训练策略进行对比 a)warm-starting from nancy vs ljspeech,在训练集seen speaker 的自然度测试,使用nancy结果较好,unseen speaker使用ljspeech较好;b) libritts clean-360 vs other-500,clean的数据360效果较好;c) 最好的模型选取。自然度方面,对于seen speaker 的情况使用vctk直接训练的最好,对unseen speaker使用vctk-liri60-wr-24k最好。相似度方面,unseen speaker 在vctk-libri360-wn-24k和vctk-hj-wr-24k较好。
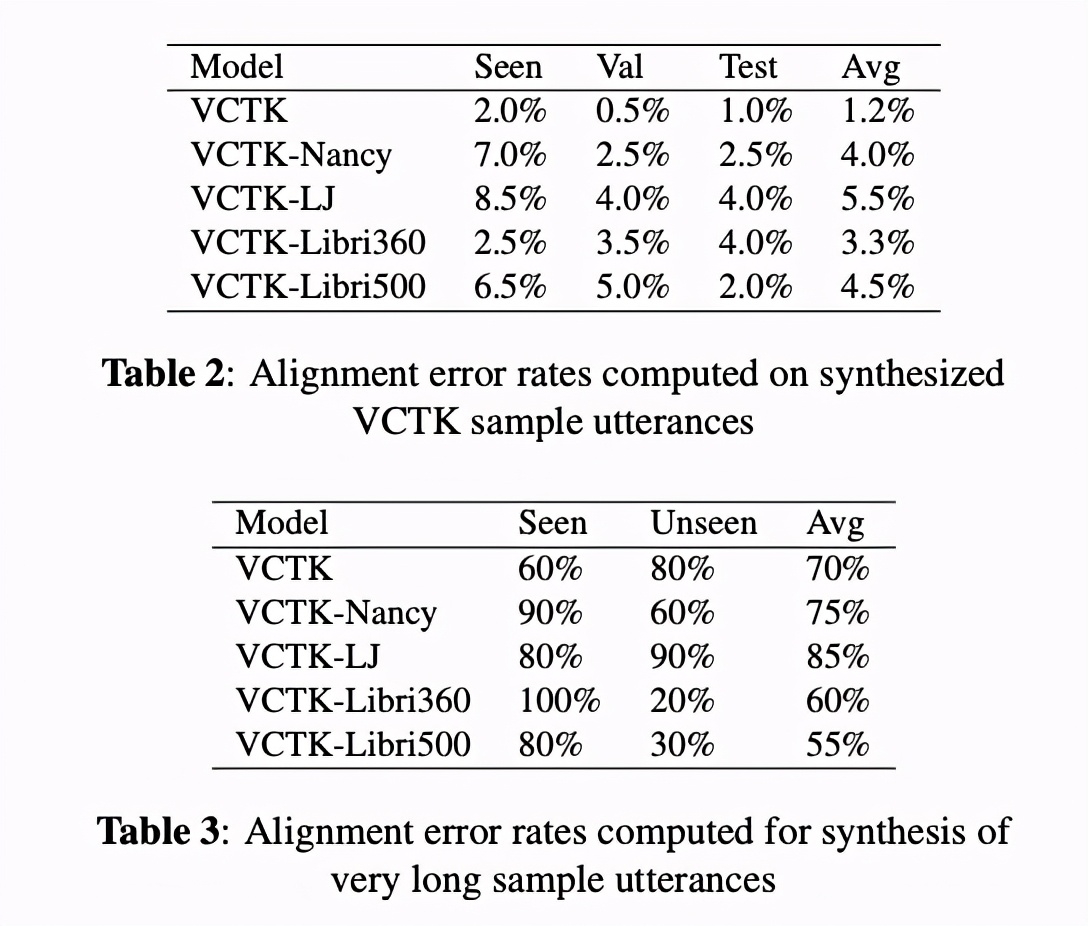
然后比较对齐方面,短句子的对齐错误率如table 2显示,vctk最低。长句子对齐错误率如table 3显示,vctk-libri错误率最低,主要因为libri说话人多和词汇量多。
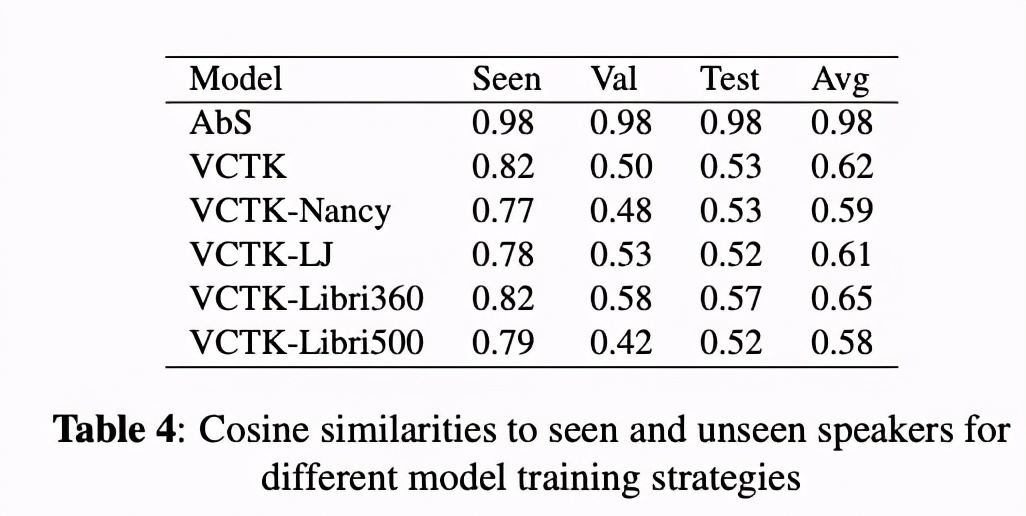
其次比较合成的相似性,图2展示了vctk-libri360和vctk-lj对比,libri效果较好,主要在于说话者多和词汇量大。table4 显示出对于unseen speaker的相似度,预训练的语料说话者多词汇量大的情况,效果较好。

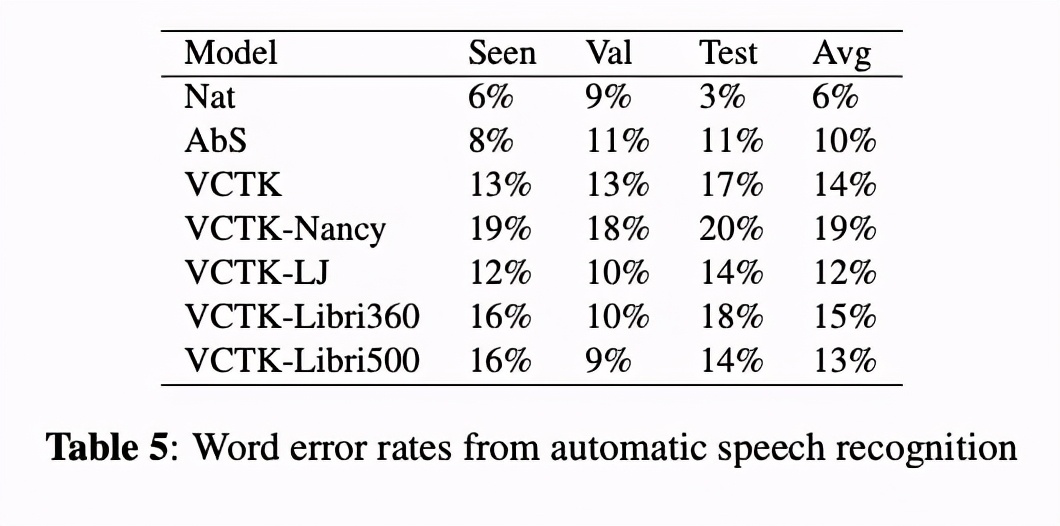
最后一个实验是对比word error,把合成的音频使用ASR进行转换,统计错误率。结果最好的还是直接使用vctk的数据,该结果与对齐实验的结果不一致,主要是发音问题。
3 总结
本文章主要对预训练语料库、声码器等因素对multi-sepaker模型训练影响的情况进行经验分享,尤其对于做zero-shot和few-shots的实验的同行具有参考价值。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











