




 本文介绍了圣加仑大学的研究,使用IPA-Based Tacotron实现数据高效跨语言语音合成和发音增强的迁移学习。该系统通过修改Tacotron架构,利用IPA字符集兼容多语言,并提出自适应训练方法。实验表明该模型能在单语言和多语言环境下进行迁移学习,但缺乏与其他个性化方案的对比试验。
本文介绍了圣加仑大学的研究,使用IPA-Based Tacotron实现数据高效跨语言语音合成和发音增强的迁移学习。该系统通过修改Tacotron架构,利用IPA字符集兼容多语言,并提出自适应训练方法。实验表明该模型能在单语言和多语言环境下进行迁移学习,但缺乏与其他个性化方案的对比试验。
声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
USING IPA-BASED TACOTRON FOR DATA EFFICIENT CROSS-LINGUAL SPEAKER ADAPTATION AND PRONUNCIATION ENHANCEMENT
本文章由圣加仑大学2020.11.12更新。文章主要是做TTS迁移学习,就是目前做个性化的方案,具体文章链接https://arxiv.org/pdf/2011.06392.pdf
1 研究背景
现有商业落地的TTS大部分每位说话人使用十来多小时的训练语料,效果很好。目前,为了使用手中已有的语料来优化少量数据和跨语言的训练成为研究的热点。本文章就是提出了跨语言的迁移学习TTS,使用少数据量训练可以合成较高的语音并且可以跨语言,并且保留原来的说话人信息。
2 详细的系统设计
本系统是基于tacotron架构进行修改,主要的修改包括以下几点:第一,phone embedding是使用的IPA character集,因此可以兼容多种语言。第二, input vector与rnn输出进行拼接(该部分挺有意思)。另外本文章主要提出如何去做自适应训练,定义自适应更新的模块。
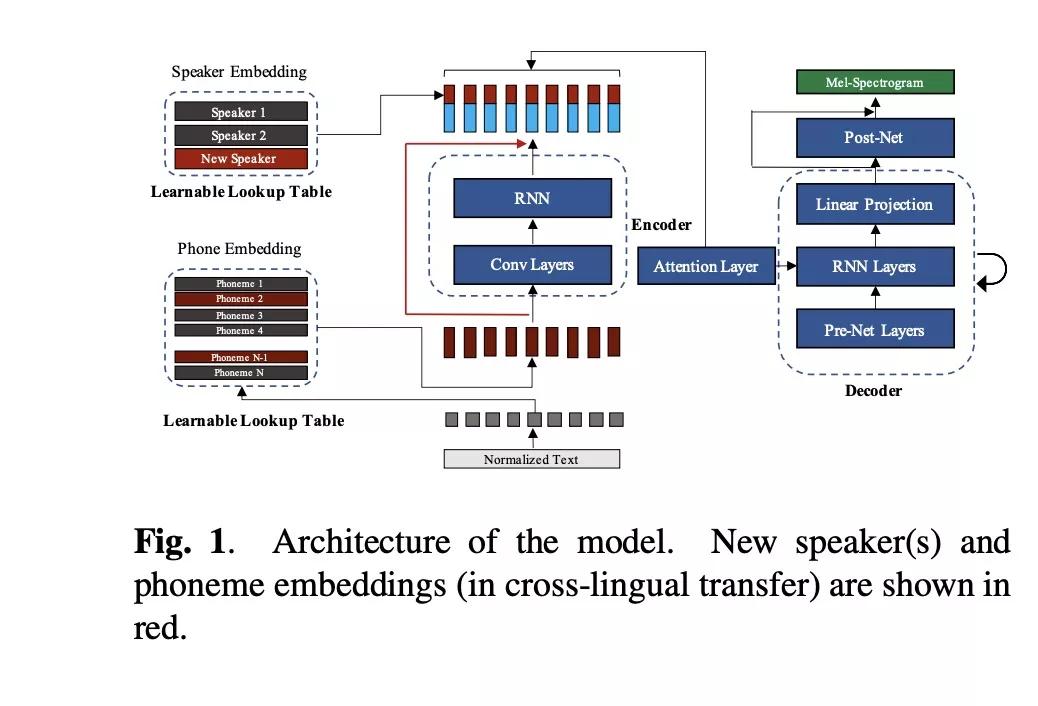
基于tacotron的声学模型如下公式表示:其中Y是声学特征,X是文本输入,Sid是说话者的id,We,Wd,Wp,Ws分别为encoder, decoder, phone table和speaker table的参数。做个性化训练的时候,如果相同语言的自适用使用公式2,加粗部分是freeze部分,不进行参数更新。训练跨语言模型则使用公式3。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











