







1、为什么是gpt2?
首先,gpt高版本模型没有开源,我们拿不到,其次,即使开源了,也无法部署,为什么呢,你猜对啦,还不是因为穷,么有卡吗,哈哈,因为只有一台macbook pro,因此gpt2-medium、gpt2-xl、gpt-large都部署不了,只剩下部署gpt2这个最小的模型试试了。
对于tritonserver不熟悉的,可以参考我之前的文章:
一共是9篇,这里只放了两篇,感兴趣的同学可以进入主页进行查阅。
2、私有化部署全过程
完成gpt2在本地的部署,一共分四个过程,分别是:
-
转换gpt2模型为triton支持的模式格式,我们转化为onnx。
-
编写模型配置文件,并把模型放到triton的model_repository目录中。
-
下载tritonserver、tritonclient两个镜像,并启动。
-
编写triton client发送请求,与gpt2进行对话。
完成上面四个步骤,就完成了在本地的部署,下面分别介绍。
3、下载gpt2原模型,将其转换为onnx
国内,如果没有翻墙,从huggingface镜像地址下载:下载模型
下载所有文件到本地文件夹:
编写转换脚本,脚本我放到文章最后,这里就不占用篇幅了,转换过程如下:
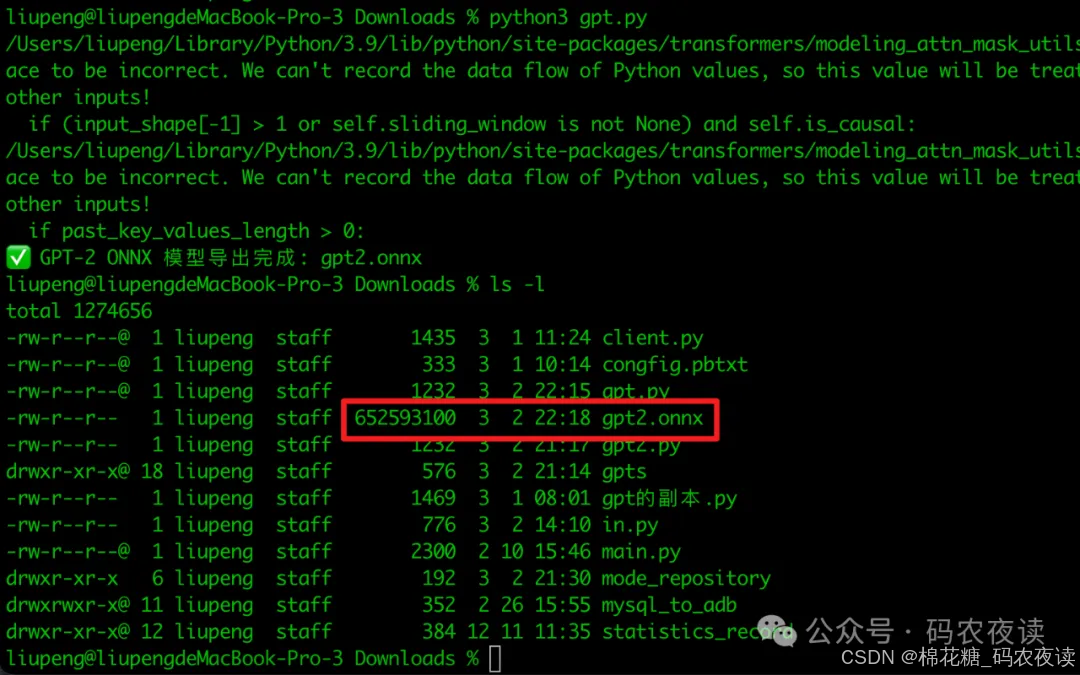 转换完成后,会生成一个以onnx结尾的模型文件,接下来,就编写一下模型的配置文件。
转换完成后,会生成一个以onnx结尾的模型文件,接下来,就编写一下模型的配置文件。
4、编写tritonserver需要的模型配置文件:config.pbtxt
name: "gpt2"
platform: "onnxruntime_onnx"
max_batch_size: 0
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ -1, -1 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ -1, -1 ]
}
]
output [
{
name: "logits"
data_type: TYPE_FP32
dims: [ -1, -1, -1 ]
}
]这个配置中,模型的输入、输出要和导出模型时设定的值一一对应,否则会出问题,对于这个配置的编写,也需要看一下之前tritonserver的文档先学习下,有什么问题,可以留言讨论。
设定一个目录为model_repository目录,我设定的本地是:
接下来在运行时,只需要将这个目录映射到docker容器中就成了,gpt2的目录结构如下:
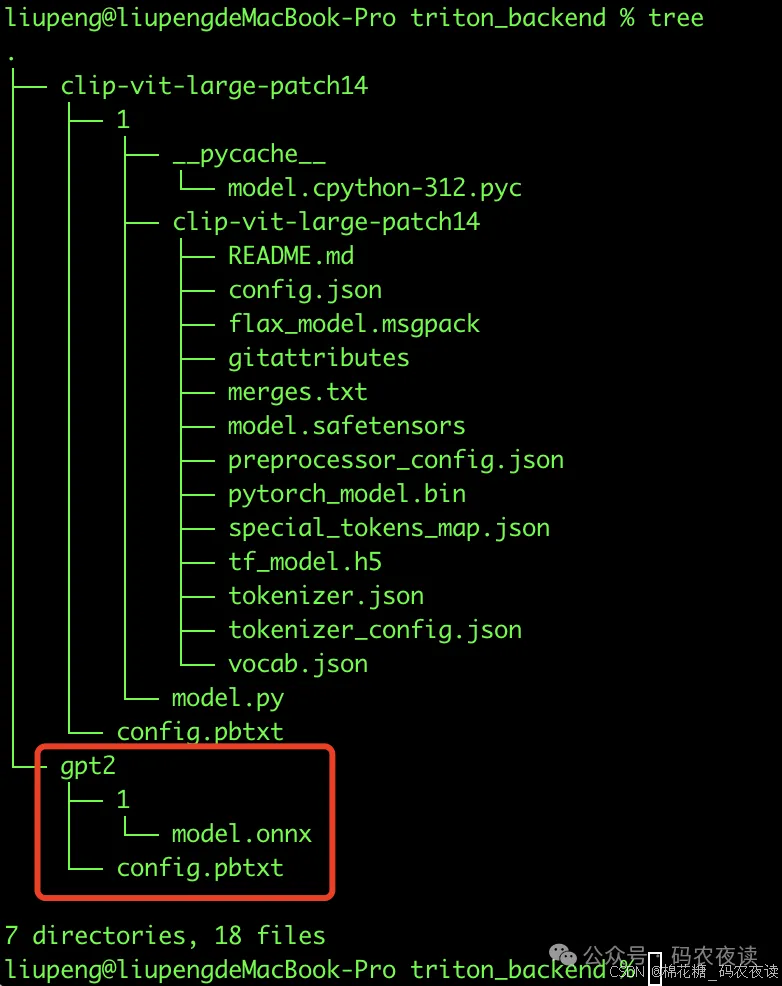
5、下载triton镜像
这个就比较简单了,首先需要你在机器上安装了docker,对于triton的镜像,直接docker pull即可,比如我本地pull下来的是24.12版本:

docker pull nvcr.io/nvidia/tritonserver:24.12-py3
docker pull nvcr.io/nvidia/tritonserver:24.12-py3-sdk一共是两个镜像,第一个是tritonserver运行镜像,模型跑在这个镜像里,第二个是triton client运行镜像,请求server的脚本跑在这个镜像里,都需要拉下来。
6、启动镜像,加载模型
启动镜像:
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -it -v /Users/liupeng/Documents/career/career/triton_backend:/models nvcr.io/nvidia/tritonserver:24.12-py3
启动triton:
tritonserver --model-repository=/models运行triton镜像之前,需要安装几个依赖包:
pip3 install transformers
pip3 install torch之后启动tritonserver镜像:
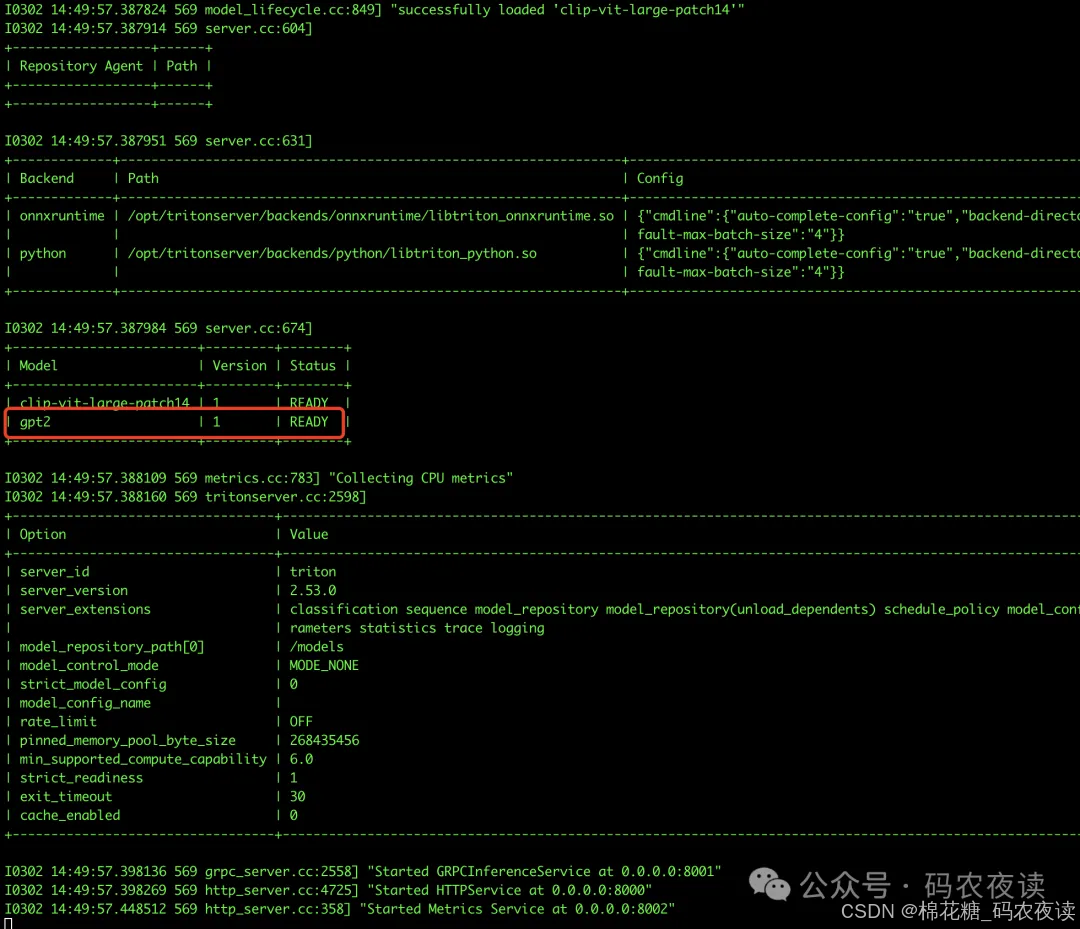
gpt2模型就在本地部署ok了,下面我们试试,这个老模型是否能用。
7、编写triton client,请求gpt2模型进行对话
先看最终效果,感觉gpt2那么傻呢
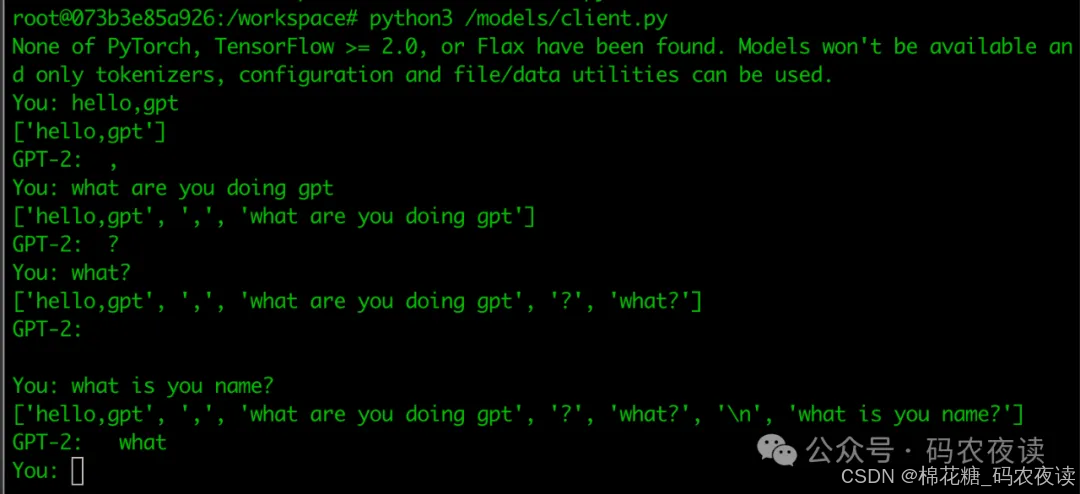
啥也问不出来,不知道是gpt2模型不行,还是咋回事。
不过呢,模型在mac上的私有化部署算是ok了,文章中涉及到的代码全部在这里:
https://github.com/liupengh3c/career/tree/main需要的同学可以自行下载,有任何问题可以留言,一起讨论。
期待小伙伴们加个关注,再关注下公众号,欢迎交流,感谢~~~~。

















 3374
3374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









