







 本文深入探讨了朴素贝叶斯理论,包括高斯朴素贝叶斯和多项式朴素贝叶斯,并介绍了贝叶斯网络的概念,强调了条件独立在贝叶斯网络中的作用,通过tail-to-tail、head-to-tail和head-to-head三种情况说明了如何判断变量间的独立性。
本文深入探讨了朴素贝叶斯理论,包括高斯朴素贝叶斯和多项式朴素贝叶斯,并介绍了贝叶斯网络的概念,强调了条件独立在贝叶斯网络中的作用,通过tail-to-tail、head-to-tail和head-to-head三种情况说明了如何判断变量间的独立性。
contents
朴素贝叶斯
朴素贝叶斯的假设:对于给定分类的条件下,特征独立——每个特征同等重要(特征均衡性),即
P
(
x
i
∣
y
,
x
1
,
⋯
,
x
i
−
1
,
x
i
+
1
,
⋯
,
x
n
)
=
P
(
x
i
∣
y
)
P\left(x_{i} \mid y, x_{1}, \cdots, x_{i-1}, x_{i+1}, \cdots, x_{n}\right)=P\left(x_{i} \mid y\right)
P(xi∣y,x1,⋯,xi−1,xi+1,⋯,xn)=P(xi∣y)
由贝叶斯公式,可得
P
(
y
∣
x
1
,
x
2
,
⋯
,
x
n
)
=
P
(
y
)
P
(
x
1
,
x
2
,
⋯
,
x
n
∣
y
)
P
(
x
1
,
x
2
,
⋯
,
x
n
)
=
P
(
y
)
∏
i
=
1
n
P
(
x
i
∣
y
)
P
(
x
1
,
x
2
,
⋯
,
x
n
)
P\left(y \mid x_{1}, x_{2}, \cdots, x_{n}\right)=\frac{P(y) P\left(x_{1}, x_{2}, \cdots, x_{n} \mid y\right)}{P\left(x_{1}, x_{2}, \cdots, x_{n}\right)}=\frac{P(y) \prod_{i=1}^{n} P\left(x_{i} \mid y\right)}{P\left(x_{1}, x_{2}, \cdots, x_{n}\right)}
P(y∣x1,x2,⋯,xn)=P(x1,x2,⋯,xn)P(y)P(x1,x2,⋯,xn∣y)=P(x1,x2,⋯,xn)P(y)∏i=1nP(xi∣y)
在给定样本的前提下,
P
(
x
1
,
x
2
,
⋯
,
x
n
)
P\left(x_{1}, x_{2}, \cdots, x_{n}\right)
P(x1,x2,⋯,xn) 是常数:
P
(
y
∣
x
1
,
x
2
,
⋯
,
x
n
)
∝
P
(
y
)
∏
i
=
1
n
P
(
x
i
∣
y
)
P\left(y \mid x_{1}, x_{2}, \cdots, x_{n}\right) \propto P(y) \prod_{i=1}^{n} P\left(x_{i} \mid y\right)
P(y∣x1,x2,⋯,xn)∝P(y)i=1∏nP(xi∣y)
从而,
y
^
=
arg
max
y
P
(
y
∣
x
1
,
x
2
,
⋯
,
x
n
)
=
arg
max
y
P
(
y
)
∏
i
=
1
n
P
(
x
i
∣
y
)
\hat{y}=\underset{y}{\arg \max } P\left(y \mid x_{1}, x_{2}, \cdots, x_{n}\right) =\underset{y}{\arg \max }P(y) \prod_{i=1}^{n} P\left(x_{i} \mid y\right)
y^=yargmaxP(y∣x1,x2,⋯,xn)=yargmaxP(y)i=1∏nP(xi∣y)
其中,对
P
(
x
i
∣
y
)
P\left(x_{i} \mid y\right)
P(xi∣y)服从什么分布的假设不同,则有了高斯朴素贝叶斯,多项式朴素贝叶斯等等。
高斯朴素贝叶斯GaussianNB(连续)
假设某个特征服从高斯分布,即
P
(
x
i
∣
y
)
=
1
2
π
σ
y
exp
(
−
(
x
i
−
μ
y
)
2
2
σ
y
2
)
P\left(x_{i} \mid y\right)=\frac{1}{\sqrt{2\pi}\sigma_y}\exp \left(-\frac{(x_i-\mu_y)^2}{2\sigma_y^2}\right)
P(xi∣y)=2πσy1exp(−2σy2(xi−μy)2)
参数可通过MLE计算
多项分布朴素贝叶斯MultinomialNB(离散)
假设某个特征服从多项式分布,即对于整体每个类别y,参数为
θ
y
=
(
θ
y
1
,
θ
y
2
,
…
,
θ
y
p
)
\theta_y=(\theta_{y1},\theta_{y2},\dots,\theta_{yp})
θy=(θy1,θy2,…,θyp),其中
p
p
p为该特征的属性数,则
P
(
x
i
=
i
∣
y
)
=
θ
y
i
P\left(x_{i}=i \mid y\right)=\theta_{yi}
P(xi=i∣y)=θyi
用MLE估算参数
θ
y
\theta_y
θy的结果为:
θ
^
y
i
=
N
y
i
+
α
N
y
+
α
n
,
N
y
i
=
∑
I
{
x
i
=
i
}
,
N
y
=
n
\hat{\theta}_{yi}=\frac{N_{yi}+\alpha}{N_y+\alpha n},N_{yi}=\sum I_{\{x_i=i\}},N_y=n
θ^yi=Ny+αnNyi+α,Nyi=∑I{xi=i},Ny=n
α = 0 \alpha=0 α=0时,为经典MLE, α = 1 \alpha=1 α=1时,为laplace平滑, α < 1 \alpha <1 α<1时,为lidstone平滑, α ≠ 0 \alpha \not= 0 α=0可以解释为防止过拟合
生成模型
过程考虑
P
(
x
i
∣
y
)
P\left(x_{i} \mid y\right)
P(xi∣y)属于什么分布
→
\rightarrow
→生成模型
过程考虑
P
(
y
∣
x
i
)
P\left(y \mid x_i\right)
P(y∣xi)属于什么分布
→
\rightarrow
→判别模型
贝叶斯网络
- 把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。
- 贝叶斯网络(Bayesian Network),又称有向无环图模型(无环,即不能存在这样的路径:从某个结点开始,沿着链接中箭头的⽅向运动,结束点为起点。),是一种概率图模型,根据概率图的拓扑结构,考察一组随机变量 X 1 , X 2 . . . X n X_1,X_2...X_n X1,X2...Xn及其 n n n组条件概率分布的性质。
贝叶斯网络举例:
下图可写成
p
(
a
,
b
,
c
)
=
p
(
c
∣
a
,
b
)
p
(
b
∣
a
)
p
(
a
)
p(a,b,c)=p(c|a,b)p(b|a)p(a)
p(a,b,c)=p(c∣a,b)p(b∣a)p(a)
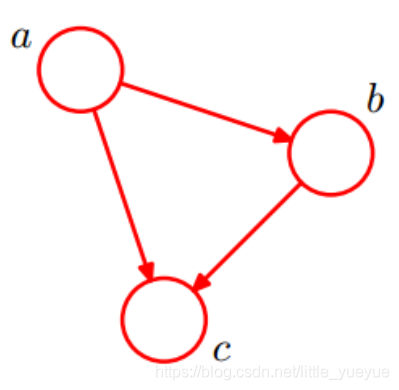
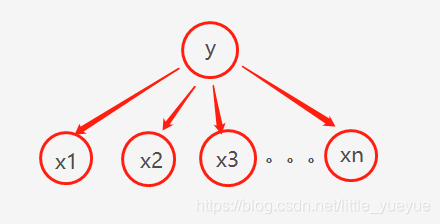
而朴素贝叶斯的这种假设
P
(
x
1
,
x
2
,
⋯
,
x
n
∣
y
)
=
∏
i
=
1
n
P
(
x
i
∣
y
)
P\left(x_{1}, x_{2}, \cdots, x_{n}|y\right) = \prod_{i=1}^{n} P\left(x_{i} \mid y\right)
P(x1,x2,⋯,xn∣y)=∏i=1nP(xi∣y),相当于下图,
x
1
,
x
2
,
…
,
x
n
x_1,x_2,\dots,x_n
x1,x2,…,xn之间没有连接。
下图
x
1
,
x
2
,
…
,
x
7
x_1,x_2,\dots,x_7
x1,x2,…,x7的联合分布:
p
(
x
1
)
p
(
x
2
)
p
(
x
3
)
p
(
x
4
∣
x
1
,
x
2
,
x
3
)
p
(
x
5
∣
x
1
,
x
3
)
p
(
x
6
∣
x
4
)
p
(
x
7
∣
x
4
,
x
5
)
p(x_1)p(x_2)p(x_3)p(x_4|x_1,x_2,x_3)p(x_5|x_1,x_3)p(x_6|x_4)p(x_7|x_4,x_5)
p(x1)p(x2)p(x3)p(x4∣x1,x2,x3)p(x5∣x1,x3)p(x6∣x4)p(x7∣x4,x5)
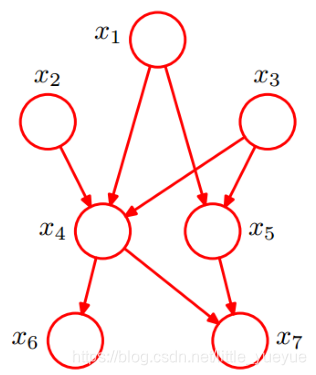
全部随机变量变量的联合分布为:
p
(
x
1
,
x
2
,
…
,
x
n
)
=
∏
i
=
1
n
p
(
x
i
∣
p
a
r
e
n
t
s
(
x
i
)
)
p(x_1,x_2,\dots,x_n)=\prod_{i=1}^n p(x_i|parents(x_i))
p(x1,x2,…,xn)=i=1∏np(xi∣parents(xi))
叶斯网络判定条件独立
下述结论可从结点推广到结点集
tail-to-tail
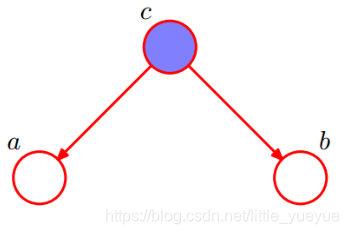
P
(
a
,
b
,
c
)
=
P
(
c
)
∗
P
(
a
∣
c
)
∗
P
(
b
∣
c
)
P
(
a
,
b
,
c
)
P
(
c
)
=
P
(
a
∣
c
)
∗
P
(
b
∣
c
)
P
(
a
,
b
∣
c
)
=
P
(
a
∣
c
)
∗
P
(
b
∣
c
)
\begin{aligned} P(a,b,c)&=P(c)*P(a|c)*P(b|c)\\ \frac{P(a,b,c)}{P(c)}&=P(a|c)*P(b|c)\\ P(a,b|c)&=P(a|c)*P(b|c) \end{aligned}
P(a,b,c)P(c)P(a,b,c)P(a,b∣c)=P(c)∗P(a∣c)∗P(b∣c)=P(a∣c)∗P(b∣c)=P(a∣c)∗P(b∣c)
在
c
c
c给定的条件下,
a
,
b
a,b
a,b被阻断(blocked),是独立的。
head-to-tail
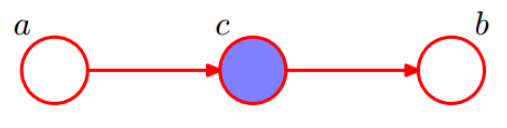
P
(
a
,
b
∣
c
)
=
P
(
a
)
∗
P
(
c
∣
a
)
∗
P
(
b
∣
c
)
P
(
c
)
P
(
a
,
b
∣
c
)
=
P
(
a
∣
c
)
∗
P
(
b
∣
c
)
\begin{aligned} P(a,b|c)&=\frac{P(a)*P(c|a)*P(b|c)}{P(c)}\\ P(a,b|c)&=P(a|c)*P(b|c)\\ \end{aligned}
P(a,b∣c)P(a,b∣c)=P(c)P(a)∗P(c∣a)∗P(b∣c)=P(a∣c)∗P(b∣c)
在
c
c
c给定的条件下,
a
,
b
a,b
a,b被阻断(blocked),是独立的。
head-to-head
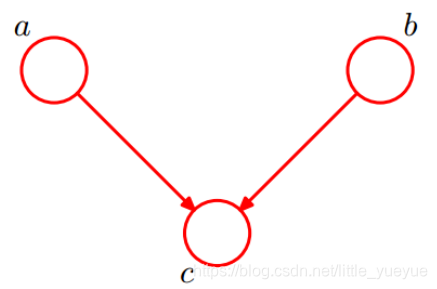
P
(
a
,
b
,
c
)
=
P
(
a
)
∗
P
(
b
)
∗
P
(
c
∣
a
,
b
)
P
(
a
,
b
)
=
∑
c
P
(
a
,
b
,
c
)
=
P
(
a
)
∗
P
(
b
)
\begin{aligned} P(a,b,c)&=P(a)*P(b)*P(c|a,b)\\ P(a,b)&=\sum_c P(a,b,c)=P(a)*P(b)\\ \end{aligned}
P(a,b,c)P(a,b)=P(a)∗P(b)∗P(c∣a,b)=c∑P(a,b,c)=P(a)∗P(b)
在
c
c
c未知条件下,
a
,
b
a,b
a,b被阻断(blocked),是独立的。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









