







 本文深入探讨了聚类算法,包括距离和相似度度量、k-Means算法及其优化(K-Means++和mini batch k-means)、Canopy算法以及聚类的衡量指标如轮廓系数、V-measure等。此外,还介绍了层次聚类方法(AGNES和DIANA)、度聚类方法(DBSCAN等)和谱聚类,提供了理解聚类算法全面视角。
本文深入探讨了聚类算法,包括距离和相似度度量、k-Means算法及其优化(K-Means++和mini batch k-means)、Canopy算法以及聚类的衡量指标如轮廓系数、V-measure等。此外,还介绍了层次聚类方法(AGNES和DIANA)、度聚类方法(DBSCAN等)和谱聚类,提供了理解聚类算法全面视角。
contents
聚类
- 聚类就是对大量未知标注的数据集(无监督),按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。
- 可用于降维
- 给定一个有N个对象的数据集,构造数据的k个簇,
k
≤
n
k\le n
k≤n。
条件:每一个簇至少包含一个对象;每一个对象属于且仅属于一个簇将满足上述条件的k个簇称作一个合理划分。
基本思想:对于给定的类别数目k,首先给出初始划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好
距离、相似度
闵可夫斯基距离Minkowski dis t ( X , Y ) = ( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 p ( p = 1 曼 哈 顿 距 离 ; p = 2 欧 氏 距 离 ; p = ∞ 最 大 分 量 ) 杰卡德相似系数(Jaccard) J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ 余弦相似度(cosine similarity) cos ( θ ) = a T b ∣ a ∣ ⋅ ∣ b ∣ Pearson相似系数 ρ x x = cov ( X , Y ) σ x σ r = E [ ( X − μ x ) ( Y − μ r ) ] σ x σ r = ∑ i = 1 n ( x i − μ x ) ( x i − μ r ) ∑ i = 1 n ( x i − μ x ) 2 ∑ i = 1 n ( y i − μ r ) 2 μ x = μ y = 0 时 , 等 价 于 余 弦 相 似 度 相对熵K-L散度 D ( p ∥ q ) = ∑ x p ( x ) log p ( x ) q ( x ) = E p ( x ) log p ( x ) q ( x ) Hellinger距离 D α ( p ∥ q ) = 2 1 − α 2 ( 1 − ∫ p ( x ) 1 + α 2 q ( x ) 1 − α 2 d x ) α = 0 时 , 满 足 三 角 不 等 式 , 对 称 非 负 性 \begin{aligned} &\text { 闵可夫斯基距离Minkowski} \operatorname{dis} t(X, Y)=\left(\sum_{i=1}^{n}\left|x_{i}-y_{i}\right|^{p}\right)^{\frac{1}{p}}\quad(p=1曼哈顿距离;p=2欧氏距离;p=\infty最大分量)\\ &\text { 杰卡德相似系数(Jaccard) } J(A, B)=\frac{|A \cap B|}{|A \cup B|}\\ &\text {余弦相似度(cosine similarity) } \cos (\theta)=\frac{a^{T} b}{|a| \cdot|b|}\\ &\text { Pearson相似系数 } \quad \rho_{x x}=\frac{\operatorname{cov}(X, Y)}{\sigma_{x} \sigma_{r}}=\frac{E\left[\left(X-\mu_{x}\right)\left(Y-\mu_{r}\right)\right]}{\sigma_{x} \sigma_{r}}=\frac{\sum_{i=1}^{n}\left(x_{i}-\mu_{x}\right)\left(x_{i}-\mu_{r}\right)}{\sqrt{\sum_{i=1}^{n}\left(x_{i}-\mu_{x}\right)^{2}} \sqrt{\sum_{i=1}^{n}\left(y_{i}-\mu_{r}\right)^{2}}}\quad \mu_{x}=\mu_{y}=0时,等价于余弦相似度\\ &\text { 相对熵K-L散度} \quad D(p \| q)=\sum_{x} p(x) \log \frac{p(x)}{q(x)}=E_{p(x)} \log \frac{p(x)}{q(x)}\\ &\text { Hellinger距离} \quad D_{\alpha}(p \| q)=\frac{2}{1-\alpha^{2}}\left(1-\int p(x)^{\frac{1+\alpha}{2}} q(x)^{\frac{1-\alpha}{2}} d x\right) \quad\alpha=0时,满足三角不等式,对称非负性 \end{aligned} 闵可夫斯基距离Minkowskidist(X,Y)=(i=1∑n∣xi−yi∣p)p1(p=1曼哈顿距离;p=2欧氏距离;p=∞最大分量) 杰卡德相似系数(Jaccard) J(A,B)=∣A∪B∣∣A∩B∣余弦相似度(cosine similarity) cos(θ)=∣a∣⋅∣b∣aTb Pearson相似系数 ρxx=σxσrcov(X,Y)=σxσrE[(X−μx)(Y−μr)]=∑i=1n(xi−μx)2∑i=1n(yi−μr)2∑i=1n(xi−μx)(xi−μr)μx=μy=0时,等价于余弦相似度 相对熵K-L散度D(p∥q)=x∑p(x)logq(x)p(x)=Ep(x)logq(x)p(x) Hellinger距离Dα(p∥q)=1−α22(1−∫p(x)21+αq(x)21−αdx)α=0时,满足三角不等式,对称非负性
k-Means算法
也被称为k-平均或k-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础。
step1:假定输入样本为
S
=
x
1
,
x
2
,
.
.
.
,
x
m
S=x_1,x_2,...,x_m
S=x1,x2,...,xm,
step2:选择初始的k个类别中心
μ
1
,
μ
2
…
μ
k
μ_1,μ_2…μ_k
μ1,μ2…μk
step3:对于每个样本
x
i
x_i
xi,将其标记为距离类别中心最近的类别,即::将每个类别中心更新为隶属该类别的所有样本的均值
step4:重复最后两步,直到类别中心的变化小于某阈值。
note:
- 中止条件:迭代次数/簇中心变化率/最小平方误差MSE(MinimumSquaredError)
- 若簇中含有异常点,将导致均值偏离严重,可改为K-Mediods
- 初值敏感(可用分值推荐来做K-Means++,优化初始聚类的中心选取的方式)
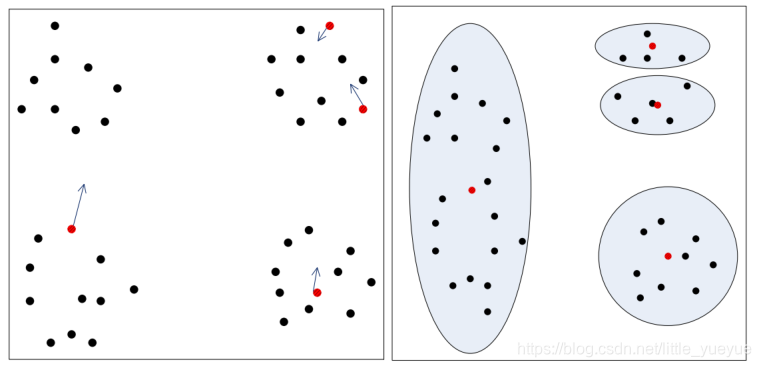
极大似然角度
假设分为
K
K
K个簇
C
1
,
…
,
C
K
C_1,\dots,C_K
C1,…,CK,每个簇服从
N
(
μ
k
,
σ
2
)
N(\mu_k,\sigma^2)
N(μk,σ2),对于样本点
x
i
x_i
xi属于簇k的概率为
e
x
p
(
−
x
i
−
μ
k
σ
2
)
exp(-\frac{x_i-\mu_k}{\sigma^2})
exp(−σ2xi−μk)样本
x
i
x_i
xi属于
C
k
C_k
Ck记为
c
i
k
c_{ik}
cik,取值为0或1.
从而极大似然函数为
∏
i
=
1
n
∏
k
=
1
K
(
exp
−
(
x
i
−
μ
k
)
2
σ
2
)
c
i
k
\prod_{i=1}^n\prod_{k=1}^K \left(\exp-\frac{(x_i-\mu_k)^2}{\sigma^2}\right)^{c_{ik}}
i=1∏nk=1∏K(exp−σ2(xi−μk)2)cik
极大化对数似然函数可转化为损失函数
max
c
i
k
,
μ
1
,
…
,
μ
k
−
∑
i
=
1
n
∑
k
=
1
K
c
i
k
(
x
i
−
μ
k
)
2
→
J
(
μ
1
,
…
,
μ
k
)
=
min
c
i
k
,
μ
1
,
…
,
μ
k
1
2
∑
j
=
1
K
∑
i
=
1
N
j
(
x
i
−
μ
j
)
2
\max_{ c_{ik},\mu_1,\dots,\mu_k}-\sum_{i=1}^n\sum_{k=1}^K c_{ik} (x_i-\mu_k)^2 \rightarrow J(\mu_1,\dots,\mu_k)=\min_{c_{ik},\mu_1,\dots,\mu_k}\frac{1}{2}\sum_{j=1}^K\sum_{i=1}^{N_j} (x_i-\mu_j)^2
cik,μ1,…,μkmax−i=1∑nk=1∑Kcik(xi−μk)2→J(μ1,…,μk)=cik,μ1,…,μkmin21j=1∑Ki=1∑Nj(xi−μj)2
对于
μ
1
,
…
,
μ
k
\mu_1,\dots,\mu_k
μ1,…,μk求偏导,其驻点为
∂
J
∂
μ
j
=
∑
i
=
1
N
j
(
x
i
−
μ
j
)
→
0
μ
j
=
1
N
j
∑
i
=
1
N
j
x
i
\frac{\partial J}{\partial \mu_j}=\sum_{i=1}^{N_j} (x_i-\mu_j)\rightarrow0 \qquad \mu_j=\frac{1}{N_j}\sum_{i=1}^{N_j} x_i
∂μj∂J=i=1∑Nj(xi−μj)→0μj=Nj1i=1∑Njxi
实际上,k-means我们认为每个簇服从高斯分布,且每个高斯分布的方差相等。
K-Means++的步骤
step1:从数据集中随机选取一个点作为初始聚类的中心
μ
i
\mu_i
μi
step2:计算每个样本
x
i
x_i
xi与已有聚类中心点的距离,用
D
(
x
i
)
D(x_i)
D(xi)表示;然后计算每个样本被选为下一个聚类中心点的概率
D
(
x
i
)
∑
j
D
(
x
j
)
\frac{D(x_i)}{\sum_jD(x_j)}
∑jD(xj)D(xi) ,之后通过轮盘法选出下一个聚类中心点
step3:重复步骤二直到选择出 K 个聚类中心点(当K值大于2时,每个样本和多个聚类中心进行计算,就会有多个距离,需要取最小的那个距离作为
D
(
x
)
D(x)
D(x))
mini batch k-means步骤
step1:从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
step2:对该小批量数据,计算平均值得到更新质心
step3:重复迭代次数直到质心稳定或者达到指定的迭代次数,停止计算
Mini Batch K-Means比K-Means有更快的收敛速度,但同时也降低了聚类的效果(实际效果降低不明显)
Canopy算法
Canopy算法是一种快速地聚类技术,Canopy聚类算法是可以并行运行的算法。只需一次遍历数据科技得到结果,无法给出精确的簇结果,但能给出最优的簇数量。得到 k 值后再使用 K-means 进行进一步“细”聚类。
note:
- Canopy 聚类最大的特点是不需要事先指定 k 值( 即 clustering 的个数)。
- canopy算法需要选择两个距离阈值: T 1 T_1 T1(the loose distance)和 T 2 T_2 T2(the tight distance)
步骤
step1:从数据集中任取一个样本,将其设为一个新的 ‘canopy’,并将其从待聚类的数据集中删除.
step2:对于剩下的数据集中,任取一个样本,用低计算成本方法快速计算该点与所有Canopy之间的距离。若该样本与某个Canopy距离在
T
1
T_1
T1以内,则加入到这个Canopy,进一步若距离在
T
2
T_2
T2以内,则需要把样本从待聚类的数据集中删除。
step3:重复第二步,直到待聚类数据集中没有样本。
聚类的衡量指标
均一性 Homogeneity和完整性 Completeness
同质性和完整性是基于条件熵的互信息分数来衡量簇向量间的相似度
h
=
{
1
if
H
(
C
)
=
0
1
−
H
(
C
∣
K
)
H
(
C
)
otherwise
h=\left\{\begin{array}{cc} 1 & \text { if } H(C)=0 \\ 1-\frac{H(C \mid K)}{H(C)} & \text { otherwise } \end{array}\right.
h={11−H(C)H(C∣K) if H(C)=0 otherwise
c
=
{
1
if
H
(
K
)
=
0
1
−
H
(
K
∣
C
)
H
(
K
)
otherwise
c=\left\{\begin{array}{cc} 1 & \text { if } H(K)=0 \\ 1-\frac{H(K \mid C)}{H(K)} & \text { otherwise } \end{array}\right.
c={11−H(K)H(K∣C) if H(K)=0 otherwise
V-measure
V-measure是结合同质性和完整性两个因素来评价簇向量间的相似度,V-measure为1表示最优的相似度:
V β = ( 1 + β 2 ) h ⋅ c β 2 h + c V_{\beta}=\frac{(1+\beta^2)h\cdot c}{\beta^2h + c} Vβ=β2h+c(1+β2)h⋅c
RI(兰德系数)
对于每一顶点对 ,在某种划分下,可能落在同一社区(cluster),也可能落在不同的社区。a指两个划分中,顶点对的两定点落在同一个社区的数量,b指两个划分中,顶点对的两两定点落在不同社区的对数。RI是衡量两个簇类的相似度,假设样本个数是n,定义:
R
I
=
a
+
b
C
2
n
RI=\frac{a+b}{C_2^n}
RI=C2na+b
随着聚类数的增加,随机分配簇类向量的RI也逐渐增加,这是不符合理论的,随机分配簇类标记向量的RI应为0。
ARI(调整兰德系数)

解决了RI不能很好的描述随机分配簇类标记向量的相似度问题
A
R
I
=
R
I
−
E
(
R
I
)
max
R
I
−
E
(
R
I
)
=
∑
i
,
j
C
n
i
j
2
−
[
(
∑
i
C
a
i
2
)
⋅
(
∑
j
C
b
j
2
)
]
/
C
n
2
1
2
[
(
∑
i
C
a
i
2
)
+
(
∑
j
C
b
j
2
)
]
−
[
(
∑
i
C
a
i
2
)
⋅
(
∑
j
C
b
j
2
)
]
/
C
n
2
ARI=\frac{RI-E(RI)}{\max RI-E(RI)}=\frac{\sum_{i, j} C_{n_{i j}}^{2}-\left[\left(\sum_{i} C_{a_{i}}^{2}\right) \cdot\left(\sum_{j} C_{b_{j}}^{2}\right)\right] / C_{n}^{2}}{\frac{1}{2}\left[\left(\sum_{i} C_{a_{i}}^{2}\right)+\left(\sum_{j} C_{b_{j}}^{2}\right)\right]-\left[\left(\sum_{i} C_{a_{i}}^{2}\right) \cdot\left(\sum_{j} C_{b_{j}}^{2}\right)\right] / C_{n}^{2}}
ARI=maxRI−E(RI)RI−E(RI)=21[(∑iCai2)+(∑jCbj2)]−[(∑iCai2)⋅(∑jCbj2)]/Cn2∑i,jCnij2−[(∑iCai2)⋅(∑jCbj2)]/Cn2
note:
1)ARI的取值范围为[-1,1],ARI越大表示预测簇向量和真实簇向量相似度越高,,ARI接近于0表示簇向量是随机分配,ARI为负数表示非常差的预测簇向量;
2)对于任意的簇类数和样本数,随机分配标签的ARI分数接近于0;
3)可用于评估无假设簇类结构的性能度量,如比较通过谱聚类降维后的k均值聚类算法的性能
AMI
AMI是基于预测簇向量与真实簇向量的互信息分数来衡量其相似度的,AMI越大相似度越高,AMI接近于0表示簇向量是随机分配的。
M
I
(
X
,
Y
)
=
∑
i
=
1
r
∑
j
=
1
s
P
(
i
,
j
)
log
P
(
i
,
j
)
P
(
i
)
P
(
j
)
MI(X, Y)=\sum_{i=1}^{r} \sum_{j=1}^{s} P(i, j) \log \frac{P(i, j)}{P(i) P(j)}
MI(X,Y)=i=1∑rj=1∑sP(i,j)logP(i)P(j)P(i,j)
其中,
P
(
i
)
=
∑
j
=
1
s
P
(
i
,
j
)
,
P
(
j
)
=
∑
i
=
1
s
P
(
i
,
j
)
,
P
(
i
,
j
)
=
n
i
j
n
P(i)=\sum_{j=1}^{s} P(i, j),P(j)=\sum_{i=1}^{s} P(i, j),P(i,j)=\frac{n_{ij}}{n}
P(i)=∑j=1sP(i,j),P(j)=∑i=1sP(i,j),P(i,j)=nnij
正则化互信息为
N
M
I
(
X
,
Y
)
=
M
I
(
X
,
Y
)
H
(
X
)
H
(
Y
)
NMI(X, Y)=\frac{MI(X, Y)}{\sqrt{H(X) H(Y)}}
NMI(X,Y)=H(X)H(Y)MI(X,Y)
MI(互信息指数)和NMI(标准化的互信息指数)不符合簇向量随机分配的理论,即随着分配簇的个数增加,MI和NMI亦会趋向于增加,AMI的值一直接近于0。。
A
M
I
(
X
,
Y
)
=
M
I
(
X
,
Y
)
−
E
[
M
I
(
X
,
Y
)
]
max
{
H
(
X
)
,
H
(
Y
)
}
−
E
[
M
I
(
X
,
Y
)
]
(
这
个
期
望
该
咋
求
?
)
AMI(X, Y)=\frac{M I(X, Y)-E[M I(X, Y)]}{\max \{H(X), H(Y)\}-E[M I(X, Y)]}(这个期望该咋求?)
AMI(X,Y)=max{H(X),H(Y)}−E[MI(X,Y)]MI(X,Y)−E[MI(X,Y)](这个期望该咋求?)
轮廓系数
- 计算样本
i
i
i到同簇其他样本的平均距离
a
i
a_i
ai。
a
i
a_i
ai越小,说明样本
i
i
i越应该被聚类到该簇。
将 a i a_i ai称为样本 i i i的簇内不相似度。
簇C中所有样本的 a i a_i ai均值称为簇C的簇不相似度。 - 计算样本
i
i
i到其他某簇
C
j
C_j
Cj的所有样本的平均距离
b
i
j
b_{ij}
bij。
b
i
j
b_{ij}
bij越大,说明样本
i
i
i越不属于簇
C
j
C_j
Cj。
将 b i j b_{ij} bij称为样本 i i i与簇 C j C_j Cj的不相似度。定义为样本 i i i的簇间不相似度 b i = min { b i 1 , b i 2 , … , b i k } b_i=\min\{b_{i1},b_{i2},\dots,b_{ik}\} bi=min{bi1,bi2,…,bik}, b i b_{i} bi越大,说明样本 i i i越不属于其他簇。 - 根据样本
i
i
i的簇内不相似度
a
i
a_i
ai和簇间不相似度
b
i
b_i
bi,定义样本
i
i
i的轮廓系数
s ( i ) = b i − a i max ( a i , b i ) s(i)=\frac{b_i-a_i}{\max(a_i,b_i)} s(i)=max(ai,bi)bi−ai
s
(
i
)
=
{
1
−
a
i
b
i
i
f
a
i
<
b
i
0
i
f
a
i
=
b
i
b
i
a
i
−
1
i
f
a
i
>
b
i
s(i)=\left\{\begin{array}{cc} 1-\frac{a_i}{b_i} & if a_i<b_i \\ 0 &if a_i=b_i\\ \frac{b_i}{a_i}-1 & if a_i>b_i \end{array}\right.
s(i)=⎩⎨⎧1−biai0aibi−1ifai<biifai=biifai>bi
s(i)接近0,说明在簇边界,s(i)接近1,样本
i
i
i聚类合理,s(i)接近-1,样本
i
i
i聚类不合理,应该分到另外簇。
所有样本的s(i)均值为该聚类的轮廓系数。
层次聚类方法
层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足为止。可分为凝聚的层次聚类和分裂的层次聚类。
凝聚的层次聚类:AGNES算法
一种自底向上的策略。
step1:算法最初将每个对象作为一个簇
step2:这些簇根据某些准则被一步步地合并。两个簇间的距离由这两个不同簇中距离最近的数据点对的相似度来确定
step3:聚类的合并过程反复进行直到所有的对象最终满足簇的数量
| AGNES中簇间距离的不同定义 | 说明 | 缺点 |
|---|---|---|
| 最小距离prime | 两个集合中最近的两个样本的距离 | 容易形成链状结构 |
| 最大距离complete | 两个集合中最远的两个样本的距离 | 若存在异常值则不稳定 |
| 平均距离average | 两个集合中样本间两两距离的平均值average | |
| 平方和距离 | 两个集合中样本间两两距离的平方和ward |
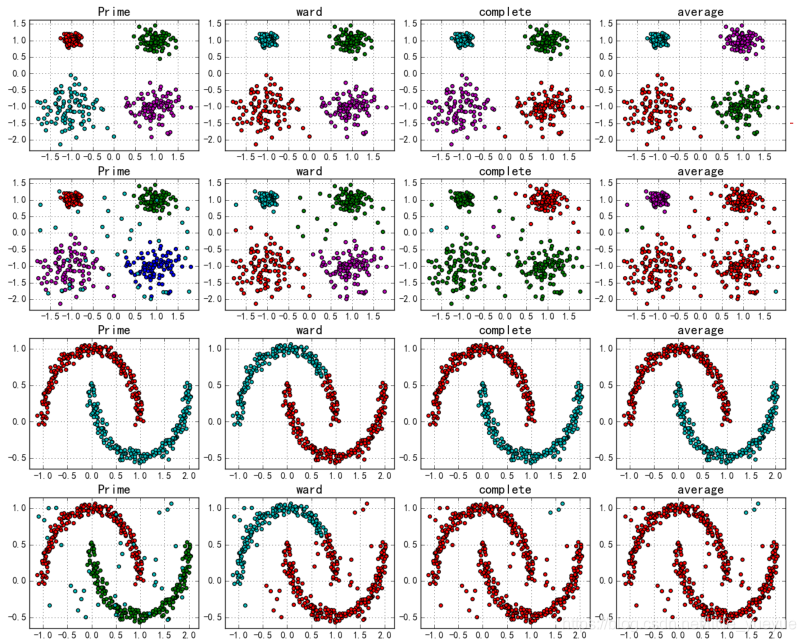
分裂的层次聚类:DIANA算法
采用自顶向下的策略。
step1:算法最初将每个对象作为一个簇
step2:根据一些原则(比如最大的欧式距离),将该簇分类。
step3:直到到达用户指定的簇的数量或者两个簇之间的距离超过了某个阈值。
度聚类方法
密度聚类方法的指导思想是,只要样本点的密度大于某阈值,则将该样本添加到最近的簇中。
- 优点:这类算法能克服基于距离的算法只能发现“类圆形”(凸)的聚类的缺点,可发现任意形状的聚类,且对噪声数据不敏感。
- 缺点:计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的数据中发现任意形状的聚类。
| 概念 | 说明 |
|---|---|
| 对象的 ϵ \epsilon ϵ-邻域 | 给定对象在半径 ϵ \epsilon ϵ内的区域。 |
| 核心对象 | 对于给定的数目m,如果一个对象的 ϵ \epsilon ϵ-邻域至少包含m个对象,则称该对象为核心对象。 |
| 直接密度可达 | 给定一个对象集合D,如果p是在q的ε-邻域内,且q是一个核心对象,则对象p从对象q出发是直接密度可达的。 |
| 密度可达 | 如果存在一个对象链 p 1 p 2 … p n , p 1 = q , p n = p p_1p_2…p_n,p_1=q,p_n=p p1p2…pn,p1=q,pn=p,对 ∀ p i ∈ D , ( 1 ≤ i < n ) , p i + 1 \forall p_i\in D,(1\le i< n),p_{i+1} ∀pi∈D,(1≤i<n),pi+1是从 p i p_i pi(核心对象)关于 ϵ \epsilon ϵ和 m m m直接密度可达的,则对象p是从对象q关于ε和m密度可达的。 |
| 密度相连 | 如果对象集合D中存在一个对象o,使得对象p和q是从o关于 ϵ \epsilon ϵ和m密度可达的,那么对象p和q是关于ε和m密度相连的。 |
| 簇 | 一个基于密度的簇是最大的密度相连对象的集合。 |
| 噪声 | 不包含在任何簇中的对象称为噪声 |
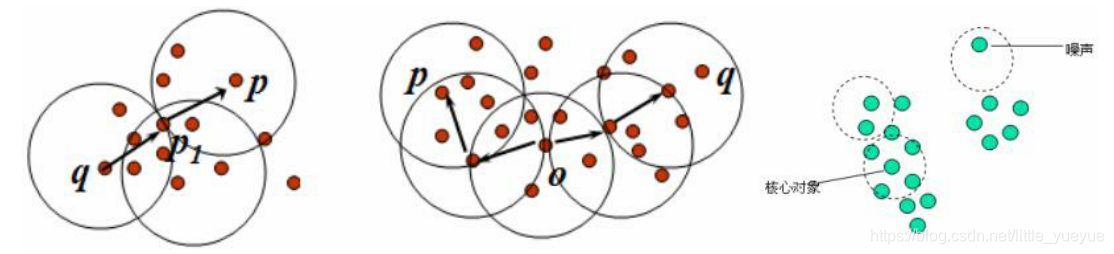
步骤:
step1:如果一个点p的ε-邻域包含多于m个对象,则创建一个p作为核心对象的新簇
step2:寻找+合并核心对象直接密度可达的核心对象
step3:没有新点可以更新簇时,算法结束。
在边界上的点,属于哪个簇关系不大
密度最大值算法
| 名称 | 局部密度 |
|---|---|
| 截断值 | ρ i = ∑ j δ ( d i j − d c ) \rho_i=\sum_j \delta_{(d_{ij}-d_c)} ρi=∑jδ(dij−dc), d c d_c dc是一个截断距离,到对象 i i i的距离小于 d c d_c dc |
| 高斯核相似度 | ρ i = ∑ j ∈ I s \ { i } exp − ( d i j d c ) 2 , \rho_i=\sum_{j\in I_s \backslash\{i\}} \exp{-(\frac{d_{ij}}{d_c})^2}, ρi=∑j∈Is\{i}exp−(dcdij)2,d_c 是 一 个 截 断 距 离 , 到 对 象 是一个截断距离,到对象 是一个截断距离,到对象i 的 距 离 小 于 的距离小于 的距离小于d_c$$ |
| K近邻均值 | ρ i = 1 K ∑ j = 1 k d i j \rho_i=\frac{1}{K}\sum_{j=1}^kd_{ij} ρi=K1∑j=1kdij,其中 d i 1 < d i 2 < ⋯ < d i K d_{i1}<d_{i2}<\dots<d_{iK} di1<di2<⋯<diK(应该有错,去倒数?) |
高局部密度点距离: δ i = min j : ρ j > ρ i ( d i j ) \delta_i=\min_{j:\rho_j>\rho_i}(d_{ij}) δi=j:ρj>ρimin(dij)
- 在密度高于对象 i i i的所有对象中,到对象 i i i最近的距离的点,两者之间的距离,即高局部密度点距离。
- 只有那些密度是局部或者全局最大的点才会有远大于正常值的高局部密度点距离。
| 簇中心识别 | 解释 |
|---|---|
| ρ i \rho_i ρi大, δ i \delta_i δi大 | 簇的中心 |
| ρ i \rho_i ρi小, δ i \delta_i δi大 | 异常点 |
步骤:
- 识别簇中心
- 为每个簇定义一个边界区域(borderregion)
划分给该簇,但距离其他簇的点的距离小于 d c d_c dc的点的集合。然后为每个簇找到其边界区域的局部密度最大的点,令其局部密度为 ρ h \rho_h ρh - 该簇中所有局部密度大于
ρ
h
\rho_h
ρh的点被认为是簇核心的一部分(即将该点划分给该类簇的可靠性很大)。
其余的点被认为是该类簇的光晕(halo),即可以认为是噪声。
也可根据该方法得到的簇中心,结合其他方法聚类
Affinity Propagation
基本思想: 认为样本 i i i的聚类性质是由 i i i对 j j j吸引力和 j j j对 i i i归属性决定的 ( ∀ j ≠ i ) (\forall j\neq i) (∀j=i)。
- 将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。
- 聚类过程中,共有两种消息在各节点间传递,分别是吸引度( responsibility)和归属度(availability) 。
- AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。
| 概念 | 解释 | 设置 |
|---|---|---|
| Exempla(聚类中心) | 类似K-Means中的质心。 | |
| Similarity(相似度) | 点 j j j作为点 i i i的聚类中心的能力,记为 S ( i , j ) S(i,j) S(i,j)。 | 一般使用负的欧式距离,表示两个点距离越近,相似度也就越高。 |
| Preference | 指点 i i i作为聚类中心的参考度(不能为0),取值为 S S S对角线的值,此值越大,最为聚类中心的可能性就越大。 | 由于对角线的值为0,需要重新设置对角线的值,可以根据实际情况设置不同的值,也可设置成同一值。一般设置为S相似度值的中值。 |
| Responsibility(吸引度) | r ( i , k ) r(i,k) r(i,k)用来描述点 k k k适合作为数据点 i i i的聚类中心的程度 | |
| Availability(归属度) | a ( i , k ) a(i,k) a(i,k)用来描述点 i i i选择点 k k k作为其聚类中心的适合程度。 | |
| Damping factor(阻尼系数) | 主要是起收敛作用的。 |
reference和Damping factor需要手动设定,前者定了成为聚类中心的可能性;后者控制算法收敛效果。
步骤:
- 算法初始, 将吸引度矩阵 R R R和归属度矩阵 A A A初始化为0矩阵
- 更新吸引度矩阵
r t + 1 ( i , k ) = { S ( i , k ) − max j ≠ k { a t ( i , j ) + r t ( i , j ) } , i ≠ k S ( i , k ) − max j ≠ k { S ( i , j ) } , i = k r_{t+1}(i, k)=\left\{\begin{array}{l} S(i, k)-\max _{j \neq k}\left\{a_{t}(i, j)+r_{t}(i, j)\right\}, i \neq k \\ S(i, k)-\max _{j \neq k}\{S(i, j)\}, i=k \end{array}\right. rt+1(i,k)={S(i,k)−maxj=k{at(i,j)+rt(i,j)},i=kS(i,k)−maxj=k{S(i,j)},i=k
(主体是样本 k k k,求 k k k对 i i i的吸引度,
i ≠ k , i\neq k, i=k,即 i , k i,k i,k之间的相似度 − - −( i i i归属其他样本的程度+其他样本对 i i i的吸引)的最大值
i = k i=k i=k,即 i i i为聚类中心的参考度 − i -i −i与其他点之间的相似度,是个定值?) - 更新归属度矩阵
a t + 1 ( i , k ) = { min { 0 , r t + 1 ( k , k ) + ∑ j ≠ i , k max { r t + 1 ( j , k ) , 0 } } , i ≠ k ∑ j ≠ k max { r t + 1 ( j , k ) , 0 } , i = k a_{t+1}(i, k)=\left\{\begin{array}{l} \min \left\{0, r_{t+1}(k, k)+\sum_{j \neq i, k} \max \left\{r_{t+1}(j, k), 0\right\}\right\}, i \neq k \\ \sum_{j \neq k} \max \left\{r_{t+1}(j, k), 0\right\}, i=k \end{array}\right. at+1(i,k)={min{0,rt+1(k,k)+∑j=i,kmax{rt+1(j,k),0}},i=k∑j=kmax{rt+1(j,k),0},i=k
(主体是样本 i i i,求 i i i归属 k k k的程度,
i ≠ k , min { 0 , r t + 1 ( k , k ) + max { k i\neq k,\min \{0, r_{t+1}(k, k)+\max \{k i=k,min{0,rt+1(k,k)+max{k对其他点的吸引程度,0 } } \}\} }}求和
i = k , max { i i=k,\max \{i i=k,max{i对其他点吸引程度,0 } \} }求和 - 根据衰减系数
λ
\lambda
λ 对两个公式进行衰减
r t + 1 ( i , k ) = λ ∗ r t ( i , k ) + ( 1 − λ ) ∗ r t + 1 ( i , k ) a t + 1 ( i , k ) = λ ∗ a t ( i , k ) + ( 1 − λ ) ∗ a t + 1 ( i , k ) \begin{aligned} r_{t+1}(i, k) &=\lambda * r_{t}(i, k)+(1-\lambda) * r_{t+1}(i, k) \\ a_{t+1}(i, k) &=\lambda * a_{t}(i, k)+(1-\lambda) * a_{t+1}(i, k) \end{aligned} rt+1(i,k)at+1(i,k)=λ∗rt(i,k)+(1−λ)∗rt+1(i,k)=λ∗at(i,k)+(1−λ)∗at+1(i,k) - 重复步骤2, 3,4 直至矩阵稳定或者达到最大迭代次数,算法结束。
- 最终取 a ( k , k ) + r ( k , k ) a(k,k)+r(k,k) a(k,k)+r(k,k)最大的k作为聚类中心。
优点:
- 无需指定聚类“数量”参数。这使得先验经验成为应用的非必需条件。
- 明确的质心(聚类中心点)。样本中的所有数据点都可能成为AP算法中的质心,叫做Examplar(不是由多个数据点求平均而得到的聚类中心,如K-Means)。
- 对距离矩阵的对称性没要求。AP通过输入相似度矩阵来启动算法,因此允许数据呈非对称,数据适用范围非常大。
- 初始值不敏感。多次执行AP聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤(对比K-Means初值敏感)。
- 若以误差平方和来衡量算法间的优劣,AP聚类比其他方法的误差平方和都要低。(无论k-center clustering重复多少次,都达不到AP那么低的误差平方和)
缺点:
- AP聚类应用中需要手动指定Preference和Damping factor,这其实是原有的聚类“数量”控制的变体。
- 算法较慢。由于AP算法复杂度较高 ( O ( k n 2 ) ) (O(kn^2)) (O(kn2)),运行时间相对K-Means长,这会使得尤其在海量数据下运行时耗费的时间很多。
谱和谱聚类
pre knowledge:
- 实对称阵不同特征值的特征向量正交实对称阵的特征值是实数
- 方阵作为线性算子,它的所有特征值的全体统称方阵的谱。
方阵的谱半径为最大的特征值
矩阵A的谱半径: A T A A^TA ATA的最大特征值 - 谱聚类是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据聚类的目的。
- 对于无向图
G
(
E
,
V
)
G(E,V)
G(E,V)邻接矩阵
W
=
(
w
i
j
)
n
×
n
W=(w_{ij})_{n\times n}
W=(wij)n×n,顶点的度
d
i
=
∑
j
=
1
n
w
i
j
d_i=\sum_{j=1}^n w_{ij}
di=∑j=1nwij,度矩阵为
D
=
d
i
a
g
(
d
1
,
…
,
d
n
)
D=diag(d_1,\dots,d_n)
D=diag(d1,…,dn),未正则的拉普拉斯矩阵:
L
=
D
−
W
L=D-W
L=D−W。
以上均为对称矩阵, L L L为半正定矩阵,最小特征值为0. - 正则拉普拉斯矩阵 :
对称拉普拉斯矩阵: L s y m = D − 1 2 L D − 1 2 = I − D − 1 2 W D − 1 2 L_{sym}=D^{-\frac{1}{2}}LD^{-\frac{1}{2}}=I-D^{-\frac{1}{2}}WD^{-\frac{1}{2}} Lsym=D−21LD−21=I−D−21WD−21
随机游走拉普拉斯矩阵 L r w = D − 1 L = I − D − 1 W L_{rw}=D^{-1}L=I-D^{-1}W Lrw=D−1L=I−D−1W - k的确定,可用 k = arg max k ∣ λ k + 1 − λ k ∣ k=\argmax_k |\lambda_{k+1}-\lambda_k| k=kargmax∣λk+1−λk∣
基本思想:
给定一组数据
x
1
,
x
2
,
.
.
.
x
n
x_1,x_2,...x_n
x1,x2,...xn,记任意两个点之间的相似度为
s
i
j
=
<
x
i
,
x
j
>
s_{ij}=<x_i,x_j>
sij=<xi,xj>,形成相似度图(similaritygraph):
G
=
(
V
,
E
)
.
G=(V,E).
G=(V,E).
如果
x
i
x_i
xi和
x
j
x_j
xj之间的相似度
s
i
j
s_{ij}
sij大于一定的阈值,那么,两个点是连接的,权值记做
s
i
j
s_{ij}
sij。
相似度图G的建立方法
先构建样本之间的相似度,可用欧氏距离倒数,多项式核函数,高斯核函数和Sigmoid核函数等,一般用高斯核函数。
-
ϵ-邻近法
设置一个距离阈值ϵ,
w i j = w j i = { 0 , ϵ > s i j ϵ , ϵ < s i j w_{i j}=w_{j i}=\left\{\begin{array}{ll} 0, & \epsilon>s_{ij} \\ \epsilon ,&\epsilon<s_{ij} \end{array}\right. wij=wji={0,ϵ,ϵ>sijϵ<sij -
K邻近法
第一种K邻近法是只要一个点在另一个点的K近邻中,则保留 s i j s_{i j} sij
w i j = w j i = { 0 x i ∉ k n n ( x j ) a n d x j ∉ k n n ( x i ) exp ( − ∥ x i − x j ∥ 2 2 2 σ 2 ) x i ∈ k n n ( x j ) o r x j ∈ k n n ( x i ) w_{i j}=w_{j i}=\left\{\begin{array}{ll} 0 & x_{i} \notin knn(x_{j}) \quad and \quad x_{j}\notin knn(x_{i}) \\ \exp \left(-\frac{\left\|x_{i}-x_{j}\right\|_{2}^{2}}{2 \sigma^{2}}\right) &x_{i} \in knn(x_{j}) \quad or \quad x_{j}\in knn(x_{i}) \\ \end{array}\right. wij=wji={0exp(−2σ2∥xi−xj∥22)xi∈/knn(xj)andxj∈/knn(xi)xi∈knn(xj)orxj∈knn(xi)
第二种K邻近法是必须两个点互为K近邻中,才能保留 s i j s_{i j} sij
w i j = w j i = { 0 ∉ k n n ( x j ) o r x j ∉ k n n ( x i ) exp ( − ∥ x i − x j ∣ 2 2 σ 2 ) x i x i ∈ k n n ( x j ) a n d x j ∈ k n n ( x i ) w_{i j}=w_{j i}=\left\{\begin{array}{ll} 0 & \notin knn(x_{j}) \quad or \quad x_{j}\notin knn(x_{i})\\ \exp \left(-\frac{\| x_{i}-x j \mid 2}{2 \sigma^{2}}\right) & x_{i} x_{i} \in knn(x_{j}) \quad and \quad x_{j}\in knn(x_{i}) \end{array}\right. wij=wji={0exp(−2σ2∥xi−xj∣2)∈/knn(xj)orxj∈/knn(xi)xixi∈knn(xj)andxj∈knn(xi) -
全连接法。
所有的点之间的权重值都大于0, 因此称之为全连接法。
w i j = w j i = exp ( − ∥ x i − x j ∥ 2 2 2 σ 2 ) w_{i j}=w_{j i}=\exp \left(-\frac{\left\|x_{i}-x_{j}\right\|_{2}^{2}}{2 \sigma^{2}}\right) wij=wji=exp(−2σ2∥xi−xj∥22)
| 连接方式 | 特点 |
|---|---|
| ϵ \epsilon ϵ近邻法 | 不同密度的数据群,往往无法连接 |
| K近邻 | 可以解决数据存在不同密度时有些无法连接的问题 |
| 互K近邻 | 趋向于连接相同密度的部分,而不连接不同密度的部分。这种性质介于ε近邻图和k近邻图之间。如果需要聚类不同的密度,这个性质非常有用。 |
| 全连接 | 建立的矩阵不是稀疏的 |
谱聚类算法步骤
未正则化的拉普拉斯矩阵和随机游走的拉普拉斯矩阵:
- 输入对应矩阵 L L L或 L r w L_{rw} Lrw
- 计算 L L L( L r w L_{rw} Lrw)的前k个特征向量 u 1 , u 2 , … , u k u_{1}, u_{2}, \dots, u_k u1,u2,…,uk
- 将k个列向量 u 1 , u 2 , … , u k u_{1},u_{2}, \dots, u_k u1,u2,…,uk组成矩阵 U ∈ R n × k U \in \mathrm{R}^{n \times k} U∈Rn×k;
- 对于 i = 1 , 2 , . . . , n i=1,2,...,n i=1,2,...,n,令 y i ∈ R k y_i\in R_k yi∈Rk是 U U U的第 i i i行的向量
- 使用K-Means算法将点 y i y_i yi聚成 C 1 , C 2 , … C k C_{1}, C_{2}, \dots C_k C1,C2,…Ck
对称的拉普拉斯矩阵:
- 输入对应矩阵 L s y m L_{sym} Lsym
- 计算 L s y m L_{sym} Lsym的前k个特征向量 u 1 , u 2 , … , u k u_{1}, u_{2}, \dots, u_k u1,u2,…,uk
- 将k个列向量 u 1 , u 2 , … , u k u_{1},u_{2}, \dots, u_k u1,u2,…,uk组成矩阵 U ∈ R n × k U \in \mathrm{R}^{n \times k} U∈Rn×k;
- 对于 i = 1 , 2 , . . . , n i=1,2,...,n i=1,2,...,n,令 y i ∈ R k y_i\in R_k yi∈Rk是 U U U的第 i i i行的向量
- 对于 i = 1 , 2 , . . . , n i=1,2,...,n i=1,2,...,n,令 y i ∈ R k y_i\in R_k yi∈Rk依次单位化,使得 ∣ y i ∣ = 1 |y_i|=1 ∣yi∣=1
- 使用K-Means算法将点 y i y_i yi聚成 C 1 , C 2 , … C k C_{1}, C_{2}, \dots C_k C1,C2,…Ck
取前k个特征向量的具体原因可见链接中的RatioCut切图。
大致思想如下:
-
先定义图cut c u t ( A 1 , … , A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) cut(A_1,\dots,A_k)=\frac{1}{2} \sum_{i=1}^{k} W\left(A_{i}, \bar{A}_{i}\right) cut(A1,…,Ak)=21i=1∑kW(Ai,Aˉi)
最小化cut的方式,仅考虑簇之间的连接权重和来聚类,会导致簇大的很大,小的很小 -
RatioCut切图为了避免这种情况,加入考虑最大化每个子图点的个数, 即:
RatioCut ( A 1 , A 2 , … A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) ∣ A i ∣ \operatorname{RatioCut}\left(A_{1}, A_{2}, \dots A_{k}\right)=\frac{1}{2} \sum_{i=1}^{k} \frac{W\left(A_{i}, \bar{A}_{i}\right)}{\left|A_{i}\right|} RatioCut(A1,A2,…Ak)=21i=1∑k∣Ai∣W(Ai,Aˉi) -
引入指示向量 h j ∈ { h 1 , h 2 , … h k } j = 1 , 2 , … k h_{j} \in\left\{h_{1}, h_{2}, \ldots h_{k}\right\} j=1,2, \ldots k hj∈{h1,h2,…hk}j=1,2,…k, 对于任意一个向量 h j h_{j} hj, 它是一个n维向量 ( ( ( n为样本数 ) ) )
h i j = { 0 v i ∉ A j 1 ∣ A j ∣ v i ∈ A j h_{i j}=\left\{\begin{array}{ll} 0 & v_{i} \notin A_{j} \\ \frac{1}{\sqrt{\left|A_{j}\right|}} & v_{i} \in A_{j} \end{array}\right. hij={0∣Aj∣1vi∈/Ajvi∈Aj
可以看出样本 i i i属于簇 A j A_j Aj时, h i j h_{ij} hij才不为0,每个向量 h j h_j hj的分量可以看做是每个样本 i i i对于簇 A j A_j Aj的属性值(这个想法很重要,后续聚类的前提假设就是这!) -
那么我们对于 h i T L h i h_{i}^{T} L h_{i} hiTLhi,有:
h i T L h i = cut ( A i , A ˉ i ) ∣ A i ∣ \begin{aligned} h_{i}^{T} L h_{i} =\frac{\operatorname{cut}\left(A_{i}, \bar{A}_{i}\right)}{\left|A_{i}\right|} \end{aligned} hiTLhi=∣Ai∣cut(Ai,Aˉi)
从而k个子图对应的RatioCut函数表达式为:
RatioCut ( A 1 , A 2 , … A k ) = ∑ i = 1 k h i T L h i = ∑ i = 1 k ( H T L H ) i i = tr ( H T L H ) \text { RatioCut }\left(A_{1}, A_{2}, \ldots A_{k}\right)=\sum_{i=1}^{k} h_{i}^{T} L h_{i}=\sum_{i=1}^{k}\left(H^{T} L H\right)_{i i}=\operatorname{tr}\left(H^{T} L H\right) RatioCut (A1,A2,…Ak)=i=1∑khiTLhi=i=1∑k(HTLH)ii=tr(HTLH) -
注意到 H T H = I H^{T} H=I HTH=I, 则切图优化目标 为:
arg min ⏟ H tr ( H T L H ) s.t. H T H = I \underbrace{\arg \min }_{H} \operatorname{tr}\left(H^{T} L H\right) \text { s.t. } H^{T} H=I H argmintr(HTLH) s.t. HTH=I -
放宽对向量 h j h_j hj每个分量的限制,只保证两两正交,并取其为单位向量。由于 h i T L h i h^T_iLh_i hiTLhi 的最小值是L的最小特征值,则 H H H就是 L L L的k个最小的特征值对应的特征向量。
-
从 h j h_j hj的设定,可以看出每个向量 h j h_j hj的分量可以看做是每个样本 i i i对于簇 A j A_j Aj的属性值,从每一行即为样本的新特征。
Ncut切图和RatioCut切图很类似,但是把Ratiocut的分母|Ai|换成vol(Ai),从而 H T H ≠ I H^TH≠I HTH=I,而是 H T D H = I H^TDH=I HTDH=I,相应做变换即可。
随机游走和拉普拉斯矩阵
- 图论中的随机游走是一个随机过程,它从一个顶点跳转到另外一个顶点。
- 谱聚类即找到图的一个划分,使得随机游走在相同的簇中停留而几乎不会游走到其他簇。
- 转移矩阵:从顶点
v
i
v_i
vi跳转到顶点
v
j
v_j
vj的概率正比于边的权值
w
i
j
w_{ij}
wij
w i j = w i j d i , P = D − 1 W w_{ij}=\frac{w_{ij}}{d_i},P=D^{-1}W wij=diwij,P=D−1W
标签传递算法Label Propagation Algorithm,LPA
核心思想:相似的数据应该具有相同的label。
LP算法两大步骤:1)构造相似矩阵
W
W
W;2)概率化传播
传播步骤:参考链接
- 定义概率转移矩阵 P = p i j = P ( i → j ) = w i j ∑ j w i j P=p_{ij}=P(i\rightarrow j)=\frac{w_{ij}}{\sum_j w_{ij}} P=pij=P(i→j)=∑jwijwij
- 定义一个 L × C L\times C L×C的label矩阵 Y L Y_L YL,其中 C C C为类别数量和 L L L为labeled的样本数量。每行为样本的标签指示向量, y i j = { 0 i ∉ C j 1 i ∈ C j y_{i j}=\left\{\begin{array}{ll} 0 & i\notin C_j \\ 1 & i\in C_j \end{array}\right. yij={01i∈/Cji∈Cj
- 同样,定义一个 U × C U\times C U×C的unlabel矩阵 Y U Y_U YU,随机设置初始值。
- 合并
Y
L
,
Y
U
Y_L,Y_U
YL,YU,得到一个
N
×
C
N\times C
N×C的soft label矩阵
F = [ Y L Y U ] . F=\left[\begin{array}{l} Y_L\\ Y_U \end{array}\right]. F=[YLYU].
softlabel:保留样本 i i i属于每个类别的概率,而不是互斥性的 - 执行传播: F = P T F F=P^TF F=PTF
- 重置F中labeled样本的标签: F L = Y L F_L=Y_L FL=YL
- 重复步骤5和6直到 F F F收敛。
Mean Shift算法
基本思想
Mean Shift算法是一个迭代的步骤,即先算出当前点的偏移均值,将该点移动到此偏移均值,然后以此为新的起始点,继续移动,直到满足最终的条件。移动的过程不是真正移动元素,而是把该元素与它整个移动过程的元素标记为同一类。
步骤:
- 在未被标记的数据点中随机选择一个点作为center,以此为中心找出距离点center在 b a n d w i d t h bandwidth bandwidth之内的所有点(以center为中心的一个高维球域 S h S_h Sh)。
- 计算点 i i i到集合 M M M中每个元素的向量,并相加取平均: M h ( c e n t e r ) = 1 k ∑ x i ∈ S h ∣ x i − c e n t e r ∣ M_h(center)=\frac{1}{k}\sum_{x_i \in S_h}|x_i-center| Mh(center)=k1xi∈Sh∑∣xi−center∣
- 新的数据点中心center为 c e n t e r ← c e n t e r + M h ( c e n t e r ) center\leftarrow center+M_h(center) center←center+Mh(center)
- 重复步骤2、3,直到
∣
M
h
(
c
e
n
t
e
r
)
∣
|M_h(center)|
∣Mh(center)∣很小,即收敛,记录center。这个迭代过程中遇到的点都应该归类为一个簇
C
i
C_i
Ci,并对这些点关于簇
C
i
C_i
Ci的属性+1(初始值均为0)。
若当前簇 C j C_j Cj的center与已经存在的簇 C i C_i Ci的center距离小于阈值,则对 C j C_j Cj中的点关于 C i C_i Ci的属性+1,同时把两者合并为一簇.否则,把 C j C_j Cj作为新簇,对这些点关于 C j C_j Cj的属性+1。 - 重复1、2、3、4直到所有的点都被标记访问。
- 分类:根据每个点各簇属性值,取大(簇访问频率高)的作为当前点的所属类。
引入了核函数和权重的改进:
对Mean Shift向量进行了优化
M
h
(
x
)
=
∑
i
=
1
n
G
H
(
x
i
−
x
)
w
(
x
i
)
(
x
i
−
x
)
∑
i
=
1
n
G
H
(
x
i
−
x
)
w
(
x
i
)
M_{h}(x)=\frac{\sum_{i=1}^{n} G_{H}\left(x_{i}-x\right) w\left(x_{i}\right)\left(x_{i}-x\right)}{\sum_{i=1}^{n} G_{H}\left(x_{i}-x\right) w\left(x_{i}\right)}
Mh(x)=∑i=1nGH(xi−x)w(xi)∑i=1nGH(xi−x)w(xi)(xi−x)
其中:
G
H
(
x
i
−
x
)
=
∣
H
∣
−
1
2
G
(
H
−
1
2
(
x
i
−
x
)
)
G_{H}\left(x_{i}-x\right)=|H|^{-\frac{1}{2}} G\left(H^{-\frac{1}{2}}\left(x_{i}-x\right)\right)
GH(xi−x)=∣H∣−21G(H−21(xi−x))
G
(
x
)
G(x)
G(x) 是一个单位的核函数。
H
H
H 是一个正定的对称
d
×
d
d \times d
d×d 矩阵, 称为带宽矩阵, 其是一个对角阵。
w
(
x
i
)
⩾
0
w\left(x_{i}\right) \geqslant 0
w(xi)⩾0 是每一个样本的权重。对角阵
H
H
H的形式为:
H
=
(
h
1
2
0
⋯
0
0
h
2
2
⋯
0
⋮
⋮
⋮
0
0
⋯
h
d
2
)
d
×
d
H=\left(\begin{array}{cccc} h_{1}^{2} & 0 & \cdots & 0 \\ 0 & h_{2}^{2} & \cdots & 0 \\ \vdots & \vdots & & \vdots \\ 0 & 0 & \cdots & h_{d}^{2} \end{array}\right)_{d \times d}
H=⎝⎜⎜⎜⎛h120⋮00h22⋮0⋯⋯⋯00⋮hd2⎠⎟⎟⎟⎞d×d
从而上述的Mean Shift向量可以改写成:
∑
i
=
1
n
G
(
x
i
−
x
h
i
)
w
(
x
i
)
(
x
i
−
x
)
∑
i
=
1
n
G
(
x
i
−
x
h
i
)
w
(
x
i
)
\frac{\sum_{i=1}^{n} G\left(\frac{x_{i}-x}{h_{i}}\right) w\left(x_{i}\right)\left(x_{i}-x\right)}{\sum_{i=1}^{n} G\left(\frac{x_{i}-x}{h_{i}}\right) w\left(x_{i}\right)}
∑i=1nG(hixi−x)w(xi)∑i=1nG(hixi−x)w(xi)(xi−x)

















 8208
8208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









