







前提知识
- Jensen不等式
θ 1 + θ 2 + , … , + θ n = 1 , f ( x ) \theta_1+\theta_2+,\dots,+\theta_n=1,f(x) θ1+θ2+,…,+θn=1,f(x) 为凸函数,则有
f ( θ 1 x 1 + ⋯ + θ n x n ) ≤ θ 1 f ( x 1 ) + ⋯ + θ n f ( x n ) f(\theta_1x_1+\dots+\theta_nx_n)\le\theta_1f(x_1)+\dots+\theta_nf(x_n) f(θ1x1+⋯+θnxn)≤θ1f(x1)+⋯+θnf(xn)
i f p ( x ) ≥ 0 o n S ⊂ d o m f , ∫ S p ( x ) = 1 , t h e n f ( ∫ S p ( x ) x d x ) ≤ ∫ S p ( x ) f ( x ) d x if\quad p(x)\ge0\quad on \quad S\subset dom \quad f,\int_Sp(x)=1,\\ then\quad f(\int_Sp(x)xdx)\le\int_Sp(x)f(x)dx ifp(x)≥0onS⊂domf,∫Sp(x)=1,thenf(∫Sp(x)xdx)≤∫Sp(x)f(x)dx - EM算法要解决的问题
模型存在一个不能被观察到的潜变量latent variable,但是该变量会影响其他变量的取值。
GMM高斯混合模型
背景:随机变量
X
X
X是有
k
k
k个高斯分布混合而成,取各个高斯分布的概率为
π
1
,
π
2
.
.
.
π
k
\pi_1,\pi_2...\pi_k
π1,π2...πk。
第
i
i
i个高斯分布的均值为
μ
i
\mu_i
μi,方差为
Σ
i
\Sigma_i
Σi。
设观测到随机变量
X
X
X的一系列样本
x
1
,
x
2
,
…
,
x
n
x_1,x_2,\dots,x_n
x1,x2,…,xn。若得到的观察数据有未观察到的隐含数据
π
1
,
π
2
.
.
.
π
k
\pi_1,\pi_2...\pi_k
π1,π2...πk ,即上文中每个样本属于哪个分布是未知的则极大似然为
L
π
,
μ
,
Σ
(
x
)
=
∏
i
=
1
N
p
(
x
i
)
=
∏
i
=
1
N
∑
k
=
1
K
p
(
x
i
,
π
k
)
=
∏
i
=
1
N
(
∑
k
=
1
K
π
i
N
(
x
i
∣
μ
i
,
Σ
i
)
)
L_{\pi,\mu,\Sigma}(x)=\prod_{i=1}^Np(x_i)=\prod_{i=1}^N\sum_{k=1}^Kp(x_i,\pi_k)=\prod_{i=1}^N\left(\sum_{k=1}^K\pi_iN(x_i|\mu_i,\Sigma_i)\right)
Lπ,μ,Σ(x)=i=1∏Np(xi)=i=1∏Nk=1∑Kp(xi,πk)=i=1∏N(k=1∑KπiN(xi∣μi,Σi))
第二个等号是根据
x
i
x_i
xi的边缘概率为
∑
k
=
1
K
p
(
x
i
,
π
k
)
\sum_{k=1}^Kp(x_i,\pi_k)
∑k=1Kp(xi,πk)计算得来,第三个等号是条件分布
p
(
x
i
,
π
k
)
=
π
i
p
(
x
i
,
∣
π
k
)
p(x_i,\pi_k)=\pi_ip(x_i,|\pi_k)
p(xi,πk)=πip(xi,∣πk)。
从而对数似然则为 l π , μ , Σ ( x ) = ∑ i = 1 N log ∑ k = 1 K π i N ( x i ∣ μ i , Σ i ) l_{\pi,\mu,\Sigma}(x)=\sum_{i=1}^N\log\sum_{k=1}^K\pi_iN(x_i|\mu_i,\Sigma_i) lπ,μ,Σ(x)=i=1∑Nlogk=1∑KπiN(xi∣μi,Σi)
为了解决这个问题,分成两步:
- 估算数据来自的组份E-step
估计数据由每个组份生成的概率:对于每个样本 x i x_i xi,它由第 k k k个组份生成的概率为
γ ( i , k ) = π k N ( x i ∣ μ k , Σ k ) π j N ( x i ∣ μ j , Σ j ) \gamma(i,k)=\frac{\pi_kN(x_i|\mu_k,\Sigma_k)}{\pi_jN(x_i|\mu_j,\Sigma_j)} γ(i,k)=πjN(xi∣μj,Σj)πkN(xi∣μk,Σk)
上式中的 μ \mu μ和 Σ \Sigma Σ同样也是待估计的值。
使用采样迭代法:在计算 γ ( i , k ) \gamma(i,k) γ(i,k)时假定 μ \mu μ和 Σ \Sigma Σ已知,即需要先验给定 μ \mu μ和 Σ \Sigma Σ(对初值选择是敏感的,需要一些其他知识)。 γ ( i , k ) \gamma(i,k) γ(i,k)亦可看成组份 k k k在生成数据 x i x_i xi时所做的贡献。 - 估计每个组份的参数M-step
对于样本点 x i x_i xi而言,可看成是每个组份 k k k生成 { γ ( i , k ) x i } \{\gamma(i,k)x_i\} {γ(i,k)xi}共同组成了 x i x_i xi。其中,组份 k k k是一个标准的高斯分布。
N k = ∑ i = 1 N γ ( i , k ) μ k = 1 N k ∑ i = 1 N γ ( i , k ) x i Σ k = 1 N k ∑ i = 1 N γ ( i , k ) ( x i − μ k ) ( x i − μ k ) T π k = N k N = 1 N ∑ i = 1 N γ ( i , k ) \begin{aligned} N_{k}&=\sum_{i=1}^{N} \gamma(i, k) \\ \mu_{k}&=\frac{1}{N_{k}} \sum_{i=1}^{N} \gamma(i, k) x_{i} \\ \Sigma_{k}&=\frac{1}{N_{k}} \sum_{i=1}^{N} \gamma(i, k)\left(x_{i}-\mu_{k}\right)\left(x_{i}-\mu_{k}\right)^{T} \\ \pi_{k}&=\frac{N_{k}}{N}=\frac{1}{N} \sum_{i=1}^{N} \gamma(i, k) \end{aligned} NkμkΣkπk=i=1∑Nγ(i,k)=Nk1i=1∑Nγ(i,k)xi=Nk1i=1∑Nγ(i,k)(xi−μk)(xi−μk)T=NNk=N1i=1∑Nγ(i,k)
EM算法
令
X
X
X成为观察到的变量,其密度函数为
p
θ
(
x
)
p_{\theta}(x)
pθ(x)。
令
Z
Z
Z成为缺失变量或潜在变量。引入其分布函数为
Q
(
z
)
Q(z)
Q(z),密度函数为
q
(
z
)
q(z)
q(z)。
令
p
θ
(
X
,
Z
)
p_{\theta}(X,Z)
pθ(X,Z)为
(
X
,
Z
)
(X,Z)
(X,Z)的真实联合分布,
p
θ
(
Z
∣
X
)
p_{\theta}(Z|X)
pθ(Z∣X)为给定
X
,
Z
X,Z
X,Z的条件分布。
对数似然函数即为:
l
(
θ
)
=
∑
i
n
log
p
θ
(
x
)
=
∑
i
n
log
∑
z
p
θ
(
x
,
z
)
l(\theta)=\sum_i^n \log p_{\theta}(x)=\sum_i^n \log \sum_z p_{\theta}(x,z)
l(θ)=∑inlogpθ(x)=∑inlog∑zpθ(x,z)
z是隐变量,不方便直接找到参数估计。
策略: 计算
l
(
θ
)
l(θ)
l(θ)下界,求该下界的最大值;重复该过程,直到收敛到局部最大值。这一迭代过程,实质是在不断地提高下界。
计算下界
令
q
i
q_i
qi是
Z
Z
Z的某一个分布 ,
q
i
≥
0
q_i\geq0
qi≥0,有:
l
(
θ
)
=
∑
i
=
1
m
log
∑
z
i
=
1
k
p
(
x
i
,
z
i
;
θ
)
=
∑
i
=
1
m
log
∑
z
i
=
1
k
p
(
x
i
,
z
i
;
θ
)
=
∑
i
=
1
m
log
∑
z
i
=
1
k
q
i
(
z
i
)
p
(
x
i
,
z
i
;
θ
)
q
i
(
z
i
)
(
J
e
n
s
e
n
i
n
e
q
u
a
t
i
o
n
)
≥
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
p
(
x
i
,
z
i
;
θ
)
q
i
(
z
i
)
\begin{aligned} l(\theta)=&\sum_{i=1}^{m} \log \sum_{z_i=1}^k p(x_i, z_i ; \theta)\\ =&\sum_{i=1}^{m} \log \sum_{z_i=1}^k p\left(x_i, z_i ; \theta\right) \\ =&\sum_{i=1}^{m} \log \sum_{z_i=1}^k q_{i}\left(z_i\right) \frac{p\left(x_i, z_i ; \theta\right)}{q_{i}\left(z_i\right)} \\ (Jensen \quad inequation)\geq& \sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}\left(z_i\right) \log \frac{p\left(x_i, z_i ; \theta\right)}{q_{i}\left(z_i\right)} \end{aligned}
l(θ)===(Jenseninequation)≥i=1∑mlogzi=1∑kp(xi,zi;θ)i=1∑mlogzi=1∑kp(xi,zi;θ)i=1∑mlogzi=1∑kqi(zi)qi(zi)p(xi,zi;θ)i=1∑mzi=1∑kqi(zi)logqi(zi)p(xi,zi;θ)
在
p
(
x
i
,
z
i
;
θ
)
q
i
(
z
i
)
=
c
,
∀
i
\frac{p\left(x_i, z_i ; \theta\right)}{q_{i}\left(z_i\right)}=c,\forall i\quad
qi(zi)p(xi,zi;θ)=c,∀i时,等号可以取到。
E-step
由于
p
(
x
i
,
z
i
;
θ
)
q
i
(
z
i
)
=
c
,
∑
z
i
=
1
k
q
i
(
z
i
)
=
1
\frac{p\left(x_i, z_i ; \theta\right)}{q_{i}\left(z_i\right)}=c,\quad \sum_{z_i=1}^k q_{i}\left(z_i\right)=1
qi(zi)p(xi,zi;θ)=c,zi=1∑kqi(zi)=1
可得(更新了
k
×
m
k\times m
k×m个参数)
q
i
(
z
i
)
=
p
(
x
i
,
z
i
;
θ
)
∑
z
i
p
(
x
i
,
z
i
;
θ
)
=
p
(
x
i
,
z
i
;
θ
)
p
(
x
i
;
θ
)
=
p
(
z
i
∣
x
i
;
θ
)
\begin{aligned} q_{i}\left(z_i\right) &=\frac{p\left(x_i, z_i ; \theta\right)}{\sum_{z_i} p\left(x_i, z_i ; \theta\right)} \\ &=\frac{p\left(x_i, z_i; \theta\right)}{p\left(x_i ; \theta\right)} \\ &=p\left(z_i \mid x_i ; \theta\right) \end{aligned}
qi(zi)=∑zip(xi,zi;θ)p(xi,zi;θ)=p(xi;θ)p(xi,zi;θ)=p(zi∣xi;θ)
M-step
将更新的
q
i
(
z
i
)
q_{i}\left(z_i\right)
qi(zi)带入
∑
i
=
1
m
∑
z
i
q
i
(
z
i
)
log
p
(
x
i
,
z
i
;
θ
)
q
i
(
z
i
)
\sum_{i=1}^{m} \sum_{z_i} q_{i}\left(z_i\right) \log \frac{p\left(x_i, z_i ; \theta\right)}{q_{i}\left(z_i\right)}
∑i=1m∑ziqi(zi)logqi(zi)p(xi,zi;θ)在最大化该式的过程中更新参数
θ
\theta
θ(若为GMM模型,
θ
\theta
θ则包含
μ
j
,
Σ
j
,
π
j
\mu_j,\Sigma_j,\pi_j
μj,Σj,πj)。
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
p
(
x
i
,
z
i
;
θ
)
=
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
p
(
x
i
∣
z
i
;
θ
)
p
(
z
i
;
θ
)
=
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
p
(
x
i
∣
z
i
;
θ
)
+
q
i
(
z
i
)
log
p
(
z
i
;
θ
)
\begin{aligned} &\sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}(z_i)\log p\left(x_i, z_i ; \theta\right)\\ =&\sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}(z_i)\log p\left(x_i| z_i ; \theta\right)p(z_i ; \theta)\\ =&\sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}(z_i)\log p\left(x_i| z_i ; \theta\right)+ q_{i}(z_i)\log p(z_i ; \theta) \end{aligned}
==i=1∑mzi=1∑kqi(zi)logp(xi,zi;θ)i=1∑mzi=1∑kqi(zi)logp(xi∣zi;θ)p(zi;θ)i=1∑mzi=1∑kqi(zi)logp(xi∣zi;θ)+qi(zi)logp(zi;θ)
M-step 中的GMM
∑
i
=
1
m
∑
z
i
q
i
(
z
i
)
log
p
(
x
i
,
z
i
;
θ
)
=
∑
i
=
1
m
∑
z
i
q
i
(
z
i
)
log
p
(
x
i
∣
z
i
;
θ
)
+
∑
i
=
1
m
∑
z
i
q
i
(
z
i
)
log
p
(
z
i
;
θ
)
\begin{aligned} &\sum_{i=1}^{m} \sum_{z_i} q_{i}(z_i)\log p\left(x_i, z_i ; \theta\right)\\ =&\sum_{i=1}^{m} \sum_{z_i} q_{i}(z_i)\log p\left(x_i| z_i ; \theta\right)+ \sum_{i=1}^{m} \sum_{z_i}q_{i}(z_i)\log p(z_i ; \theta) \end{aligned}
=i=1∑mzi∑qi(zi)logp(xi,zi;θ)i=1∑mzi∑qi(zi)logp(xi∣zi;θ)+i=1∑mzi∑qi(zi)logp(zi;θ)
注意到,在GMM模型中,加号左边的参数只有
μ
j
,
Σ
j
\mu_j,\Sigma_j
μj,Σj,加号右边的参数只有
π
j
\pi_j
πj,可以分别最大化求解:
(
μ
j
,
Σ
j
)
=
arg max
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
p
(
x
i
∣
z
i
;
θ
)
π
j
=
arg max
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
p
(
z
i
;
θ
)
\begin{aligned} (\mu_j,\Sigma_j)=&\argmax\sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}(z_i)\log p\left(x_i| z_i ; \theta\right)\\ \pi_j=&\argmax\sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}(z_i)\log p(z_i ; \theta) \end{aligned}
(μj,Σj)=πj=argmaxi=1∑mzi=1∑kqi(zi)logp(xi∣zi;θ)argmaxi=1∑mzi=1∑kqi(zi)logp(zi;θ)
第一个式子对
μ
j
,
Σ
j
\mu_j,\Sigma_j
μj,Σj分别求偏导,令导函数为0,可得:
μ
j
=
∑
i
=
1
m
q
i
(
z
j
)
x
i
∑
i
=
1
m
q
i
(
z
j
)
Σ
j
=
∑
i
=
1
m
q
i
(
z
j
)
(
x
i
−
μ
j
)
(
x
i
−
μ
j
)
T
∑
i
=
1
m
q
i
(
z
j
)
\begin{aligned} \mu_j=&\frac{\sum_{i=1}^{m}q_{i}(z_j)x_i}{\sum_{i=1}^{m}q_{i}(z_j)}\\ \Sigma_j=&\frac{\sum_{i=1}^{m}q_{i}(z_j)\left(x_{i}-\mu_{j}\right)\left(x_{i}-\mu_{j}\right)^{T}}{\sum_{i=1}^{m}q_{i}(z_j)} \end{aligned}
μj=Σj=∑i=1mqi(zj)∑i=1mqi(zj)xi∑i=1mqi(zj)∑i=1mqi(zj)(xi−μj)(xi−μj)T
第二个式子
p
(
z
i
;
θ
)
p(z_i ; \theta)
p(zi;θ)求和为0的条件(
≥
0
\ge 0
≥0的条件,由于对数的定义域即大于零,可省略),用拉格朗日乘子法,再求偏导
L
=
∑
i
=
1
m
∑
z
i
=
1
k
q
i
(
z
i
)
log
π
z
i
+
β
(
∑
z
i
=
1
k
π
z
i
−
1
)
L=\sum_{i=1}^{m} \sum_{z_i=1}^k q_{i}(z_i)\log \pi_{z_i}+\beta(\sum_{z_i=1}^k \pi_{z_i}-1 )
L=i=1∑mzi=1∑kqi(zi)logπzi+β(zi=1∑kπzi−1)
可得
∂
L
∂
π
z
i
=
∑
i
=
1
m
q
i
(
z
i
)
π
z
i
+
β
→
β
π
z
i
=
−
∑
i
=
1
m
q
i
(
z
i
)
→
β
=
−
m
π
z
i
=
1
m
∑
i
=
1
m
q
i
(
z
i
)
\frac{\partial L}{\partial \pi_{z_i}}=\sum_{i=1}^{m}\frac{q_{i}(z_i)}{\pi_{z_i}}+\beta\quad\rightarrow\beta\pi_{z_i}=-\sum_{i=1}^{m}q_{i}(z_i)\quad\rightarrow\beta=-m\\ \pi_{z_i}=\frac{1}{m}\sum_{i=1}^{m}q_{i}(z_i)
∂πzi∂L=i=1∑mπziqi(zi)+β→βπzi=−i=1∑mqi(zi)→β=−mπzi=m1i=1∑mqi(zi)
步骤
交替更新,坐标上升的过程。
E-step:
q
n
e
w
(
Z
)
=
p
θ
o
l
d
(
Z
∣
X
)
q_{new}(Z) =p_{\theta_{old}}(Z \mid X)
qnew(Z)=pθold(Z∣X)
M-step:
θ
n
e
w
=
arg max
θ
∑
q
(
Z
)
log
p
θ
(
X
,
Z
)
q
(
Z
)
\theta_{new}= \argmax_{\theta} \sum q(Z) \log \frac{p_{\theta}(X, Z)}{q(Z)}
θnew=θargmax∑q(Z)logq(Z)pθ(X,Z)
对于多个样本
(
X
1
,
Z
1
)
,
(
X
2
,
Z
2
)
,
…
,
(
X
n
,
Z
n
)
(X_1,Z_1),(X_2,Z_2),\dots,(X_n,Z_n)
(X1,Z1),(X2,Z2),…,(Xn,Zn),时,
∑
i
n
log
p
θ
(
X
)
=
∑
i
n
(
∑
j
K
q
(
Z
)
log
p
θ
(
X
,
Z
)
q
(
Z
)
+
D
k
l
(
Q
(
Z
)
∥
P
θ
(
Z
∣
X
)
)
)
\begin{aligned} \sum_i^n \log p_{\theta}(X) =\sum_i^n\left( \sum_j^K q(Z) \log \frac{p_{\theta}(X, Z)}{q(Z)}+D_{\mathrm{kl}}\left(Q(Z) \| P_{\theta}(Z \mid X)\right)\right) \end{aligned}
i∑nlogpθ(X)=i∑n(j∑Kq(Z)logq(Z)pθ(X,Z)+Dkl(Q(Z)∥Pθ(Z∣X)))
E-step:用
p
θ
o
l
d
(
Z
i
=
j
∣
X
i
)
p_{\theta_{old}}(Z_i=j \mid X_i)
pθold(Zi=j∣Xi)更新
q
n
e
w
(
Z
i
=
j
)
q_{new}(Z_i=j)
qnew(Zi=j)
q
n
e
w
(
Z
i
=
j
)
=
p
θ
o
l
d
(
Z
i
=
j
∣
X
i
)
=
p
θ
o
l
d
(
X
i
∣
Z
i
=
j
)
π
j
∑
j
p
θ
o
l
d
(
X
i
∣
Z
i
=
j
)
π
j
q_{new}(Z_i=j) =p_{\theta_{old}}(Z_i=j \mid X_i)=\frac{p_{\theta_{old}}(X_i|Z_i=j)\pi_j}{\sum_j p_{\theta_{old}}(X_i|Z_i=j)\pi_j}
qnew(Zi=j)=pθold(Zi=j∣Xi)=∑jpθold(Xi∣Zi=j)πjpθold(Xi∣Zi=j)πj
M-step:更新
θ
j
,
π
j
\theta_j,\pi_j
θj,πj
θ
n
e
w
=
arg max
θ
∑
i
∑
j
q
n
e
w
(
Z
i
=
j
)
log
p
θ
(
X
,
Z
i
=
j
)
q
n
e
w
(
Z
i
=
j
)
=
arg max
θ
∑
i
∑
j
q
n
e
w
(
Z
i
=
j
)
log
p
θ
o
l
d
(
X
i
∣
Z
i
=
j
)
π
j
q
n
e
w
(
Z
i
=
j
)
\theta_{new}= \argmax_{\theta} \sum_i \sum_j q_{new}(Z_i=j) \log \frac{p_{\theta}(X, Z_i=j)}{q_{new}(Z_i=j)}\\ = \argmax_{\theta} \sum_i \sum_j q_{new}(Z_i=j) \log \frac{p_{\theta_{old}}(X_i|Z_i=j)\pi_j}{q_{new}(Z_i=j)}
θnew=θargmaxi∑j∑qnew(Zi=j)logqnew(Zi=j)pθ(X,Zi=j)=θargmaxi∑j∑qnew(Zi=j)logqnew(Zi=j)pθold(Xi∣Zi=j)πj
KL散度角度的EM算法
令
X
X
X成为观察到的变量,其密度函数为
p
θ
(
x
)
p_{\theta}(x)
pθ(x)。
令
Z
Z
Z成为缺失变量或潜在变量。引入其分布函数为
Q
(
z
)
Q(z)
Q(z),密度函数为
q
(
z
)
q(z)
q(z)。
令
p
θ
(
X
,
Z
)
p_{\theta}(X,Z)
pθ(X,Z)为
(
X
,
Z
)
(X,Z)
(X,Z)的真实联合分布,
p
θ
(
Z
∣
X
)
p_{\theta}(Z|X)
pθ(Z∣X)为给定
X
,
Z
X,Z
X,Z的条件分布。
EM算法的目标是最大化
E
X
(
log
p
θ
(
X
)
)
E_X(\log p_{\theta}(X))
EX(logpθ(X)),引入潜变量
Z
Z
Z可将式子写成
max
θ
E
X
{
log
p
θ
(
X
)
}
=
max
θ
{
∬
p
θ
0
(
X
)
q
(
Z
)
log
p
θ
(
X
)
d
Z
d
X
}
\max _{\theta} E_{X}\left\{\log p_{\theta}(X)\right\}=\max _{\theta}\left\{\iint p_{\theta_{0}}(X) q(Z) \log p_{\theta}(X) d Z d X\right\}
θmaxEX{logpθ(X)}=θmax{∬pθ0(X)q(Z)logpθ(X)dZdX}
理想状态下,
θ
\theta
θ 的最佳选择
θ
0
\theta_{0}
θ0,从而可得
max
θ
E
X
{
log
p
θ
(
X
)
}
=
E
X
{
log
p
θ
0
(
X
)
}
\max _{\theta} E_{X}\left\{\log p_{\theta}(X)\right\}=E_{X}\left\{\log p_{\theta_{0}}(X)\right\}
maxθEX{logpθ(X)}=EX{logpθ0(X)},等号右边可以写成
E
X
{
log
p
θ
0
(
X
)
}
=
∫
p
θ
0
(
X
)
log
p
θ
0
(
X
)
d
X
=
∬
p
θ
0
(
X
)
p
θ
0
(
Z
∣
X
)
d
Z
log
p
θ
0
(
X
)
d
X
=
∬
p
θ
0
(
X
)
p
θ
0
(
Z
∣
X
)
log
p
θ
0
(
X
)
d
Z
d
X
\begin{aligned} E_{X}\left\{\log p_{\theta_{0}}(X)\right\} &=\int p_{\theta_{0}}(X) \log p_{\theta_{0}}(X) d X \\ &=\iint p_{\theta_{0}}(X) p_{\theta_{0}}(Z \mid X) d Z \log p_{\theta_{0}}(X) d X \\ &=\iint p_{\theta_{0}}(X) p_{\theta_{0}}(Z \mid X) \log p_{\theta_{0}}(X) d Z d X \end{aligned}
EX{logpθ0(X)}=∫pθ0(X)logpθ0(X)dX=∬pθ0(X)pθ0(Z∣X)dZlogpθ0(X)dX=∬pθ0(X)pθ0(Z∣X)logpθ0(X)dZdX
可以看出
q
(
Z
)
q(Z)
q(Z) 的最佳替换是
p
θ
0
(
Z
∣
X
)
p_{\theta_{0}}(Z \mid X)
pθ0(Z∣X)。
对于最大化的目标
E
X
(
log
p
θ
(
X
)
)
E_X(\log p_{\theta}(X))
EX(logpθ(X)),引入
p
θ
0
(
Z
∣
X
)
p_{\theta_{0}}(Z \mid X)
pθ0(Z∣X),
E
X
{
log
p
θ
(
X
)
}
=
E
X
{
∫
q
(
Z
∣
X
)
log
p
θ
(
X
)
d
Z
}
(
∫
q
(
Z
∣
X
)
d
Z
=
1
)
=
E
X
{
∫
q
(
Z
∣
X
)
log
p
θ
(
X
,
Z
)
p
θ
(
Z
∣
X
)
d
Z
}
(
p
θ
(
Z
∣
X
)
=
p
θ
(
X
,
Z
)
p
θ
(
X
)
)
=
E
X
{
∫
q
(
Z
∣
X
)
log
p
θ
(
X
,
Z
)
/
q
(
Z
∣
X
)
p
θ
(
Z
∣
X
)
/
q
(
Z
∣
X
)
d
Z
}
=
E
X
{
∫
q
(
Z
∣
X
)
log
p
θ
(
X
,
Z
)
q
(
Z
∣
X
)
d
Z
−
∫
q
(
Z
∣
X
)
log
p
θ
(
Z
∣
X
)
q
(
Z
∣
X
)
d
Z
}
=
E
X
{
∫
q
(
Z
∣
X
)
log
p
θ
(
X
,
Z
)
q
(
Z
∣
X
)
d
Z
+
D
k
l
(
Q
(
Z
∣
X
)
∥
P
θ
(
Z
∣
X
)
}
\begin{aligned} & E_{X}\left\{\log p_{\theta}(X)\right\} \\ =& E_{X}\left\{\int q(Z \mid X) \log p_{\theta}(X) d Z\right\} \quad\left(\int q(Z \mid X) d Z=1\right) \\ =& E_{X}\left\{\int q(Z \mid X) \log \frac{p_{\theta}(X, Z)}{p_{\theta}(Z \mid X)} d Z\right\}\left(p_{\theta}(Z \mid X)=\frac{p_{\theta}(X, Z)}{p_{\theta}(X)}\right) \\ =& E_{X}\left\{\int q(Z \mid X) \log \frac{p_{\theta}(X, Z) / q(Z \mid X)}{p_{\theta}(Z \mid X) / q(Z \mid X)} d Z\right\} \\ =& E_{X}\left\{\int q(Z \mid X) \log \frac{p_{\theta}(X, Z)}{q(Z \mid X)} d Z-\int q(Z \mid X) \log \frac{p_{\theta}(Z \mid X)}{q(Z \mid X)} d Z\right\} \\ =& E_{X}\left\{\int q(Z \mid X) \log \frac{p_{\theta}(X, Z)}{q(Z \mid X)} d Z+D_{\mathrm{kl}}\left(Q(Z \mid X) \| P_{\theta}(Z \mid X)\right\}\right. \end{aligned}
=====EX{logpθ(X)}EX{∫q(Z∣X)logpθ(X)dZ}(∫q(Z∣X)dZ=1)EX{∫q(Z∣X)logpθ(Z∣X)pθ(X,Z)dZ}(pθ(Z∣X)=pθ(X)pθ(X,Z))EX{∫q(Z∣X)logpθ(Z∣X)/q(Z∣X)pθ(X,Z)/q(Z∣X)dZ}EX{∫q(Z∣X)logq(Z∣X)pθ(X,Z)dZ−∫q(Z∣X)logq(Z∣X)pθ(Z∣X)dZ}EX{∫q(Z∣X)logq(Z∣X)pθ(X,Z)dZ+Dkl(Q(Z∣X)∥Pθ(Z∣X)}
给定
θ
old
\theta_{\text {old }}
θold ,E-Step实际做的事情是用
q
(
Z
∣
X
)
q(Z \mid X)
q(Z∣X)替代
P
θ
(
Z
∣
X
)
P_{\theta}(Z \mid X)
Pθ(Z∣X),即在KL散度意义下,用
q
(
Z
∣
X
)
q(Z \mid X)
q(Z∣X)逼近
P
θ
(
Z
∣
X
)
P_{\theta}(Z \mid X)
Pθ(Z∣X)。
在理想状态下
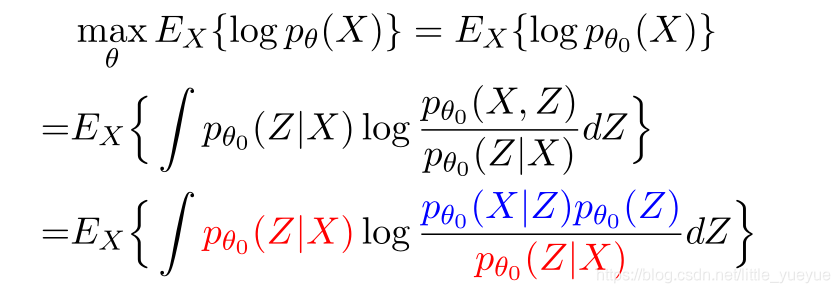
EM算法是一个交替更新的过程,先更新红色部分,再更新蓝色的部分。在更新蓝色部分时,对数中的分母不含需要最大化的参数,可忽略,从而M-step从KL散度看,如下,M-step也是一个KL散度逼近的问题。
argmax
θ
E
X
{
∫
p
θ
old
(
Z
∣
X
)
log
p
θ
(
X
∣
Z
)
p
θ
(
Z
)
d
Z
}
=
argmax
θ
E
X
{
∫
q
new
(
Z
∣
X
)
log
p
θ
(
X
∣
Z
)
p
θ
(
Z
)
p
θ
0
(
X
)
q
new
(
Z
∣
X
)
d
Z
}
=
argmax
θ
{
∫
p
θ
0
(
X
)
q
new
(
Z
∣
X
)
log
p
θ
(
X
,
Z
)
p
θ
0
(
X
)
q
new
(
Z
∣
X
)
d
Z
d
X
}
=
argmin
θ
D
k
l
{
Q
new
(
Z
∣
X
)
P
θ
0
(
X
)
∥
P
θ
(
X
,
Z
)
}
\begin{aligned} & \underset{\theta}{\operatorname{argmax}} E_{X}\left\{\int p_{\theta_{\text {old }}}(Z \mid X) \log p_{\theta}(X \mid Z) p_{\theta}(Z) d Z\right\} \\ =& \underset{\theta}{\operatorname{argmax}} E_{X}\left\{\int q_{\text {new }}(Z \mid X) \log \frac{p_{\theta}(X \mid Z) p_{\theta}(Z)}{p_{\theta_{0}}(X) q_{\text {new }}(Z \mid X)} d Z\right\} \\ =& \underset{\theta}{\operatorname{argmax}}\left\{\int p_{\theta_{0}}(X) q_{\text {new }}(Z \mid X) \log \frac{p_{\theta}(X, Z)}{p_{\theta_{0}}(X) q_{\text {new }}(Z \mid X)} d Z d X\right\} \\ =& \underset{\theta}{\operatorname{argmin}} D_{\mathrm{kl}}\left\{Q_{\text {new }}(Z \mid X) P_{\theta_{0}}(X) \| P_{\theta}(X, Z)\right\} \end{aligned}
===θargmaxEX{∫pθold (Z∣X)logpθ(X∣Z)pθ(Z)dZ}θargmaxEX{∫qnew (Z∣X)logpθ0(X)qnew (Z∣X)pθ(X∣Z)pθ(Z)dZ}θargmax{∫pθ0(X)qnew (Z∣X)logpθ0(X)qnew (Z∣X)pθ(X,Z)dZdX}θargminDkl{Qnew (Z∣X)Pθ0(X)∥Pθ(X,Z)}
总结
-
E-step是一个无约束的优化问题,
Q new ( Z ∣ X ) = argmin Q ( Z ∣ X ) E X [ D k l ( Q ( Z ∣ X ) ∥ P θ old ( Z ∣ X ) ) ] Q_{\text {new }}(Z \mid X)=\underset{Q(Z \mid X)}{\operatorname{argmin}} E_{X}\left[D_{\mathrm{kl}}\left(Q(Z \mid X) \| P_{\theta \text { old }}(Z \mid X)\right)\right] Qnew (Z∣X)=Q(Z∣X)argminEX[Dkl(Q(Z∣X)∥Pθ old (Z∣X))]
给定 θ old \theta^{\text {old }} θold ,直接令 q ( Z ∣ X ) = P θ ( Z ∣ X ) q(Z \mid X)=P_{\theta}(Z \mid X) q(Z∣X)=Pθ(Z∣X)即可。 -
M-step是一个有约束的优化问题。
P θ new ( X ∣ Z ) P_{\theta^{\text {new }}}(X \mid Z) Pθnew (X∣Z)和 P θ new ( Z ) P_{\theta^{\text {new }}}(Z) Pθnew (Z)均为事先确定的分布簇,如 G M M GMM GMM中前者为正态分布,后者为多项分布。所以这里是在优化分布,使得这两个分布的成绩和 Z ∣ X ) P θ 0 ( X ) Z \mid X) P_{\theta_{0}}(X) Z∣X)Pθ0(X)的分布在KL散度意义下很接近。
P θ new ( X ∣ Z ) P θ new ( Z ) = argmin P θ ( X ∣ Z ) P θ ( Z ) ∈ F θ D k l { Q new ( Z ∣ X ) P θ 0 ( X ) ∥ P θ ( X ∣ Z ) P θ ( Z ) } \begin{array}{l} P_{\theta^{\text {new }}}(X \mid Z) P_{\theta^{\text {new }}}(Z) \\ =\underset{P_{\theta}(X \mid Z) P_{\theta}(Z) \in \mathcal{F}_{\theta}}{\operatorname{argmin}} D_{\mathrm{kl}}\left\{Q_{\text {new }}(Z \mid X) P_{\theta_{0}}(X) \| P_{\theta}(X \mid Z) P_{\theta}(Z)\right\} \end{array} Pθnew (X∣Z)Pθnew (Z)=Pθ(X∣Z)Pθ(Z)∈FθargminDkl{Qnew (Z∣X)Pθ0(X)∥Pθ(X∣Z)Pθ(Z)}

















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









