







 博客介绍了熵相关概念,包括条件熵、相对熵、互信息及熵的关系。阐述决策树生成算法,如ID3、信息增益率等,还提及决策树做回归和过拟合处理。介绍随机森林的Bagging策略、做法、样本相似度和特征重要度计算等。最后给出样本不均衡的常用处理方法。
博客介绍了熵相关概念,包括条件熵、相对熵、互信息及熵的关系。阐述决策树生成算法,如ID3、信息增益率等,还提及决策树做回归和过拟合处理。介绍随机森林的Bagging策略、做法、样本相似度和特征重要度计算等。最后给出样本不均衡的常用处理方法。
contents
熵
设X是一个取有限个值的离散随机变量,气概率分布为
P ( X = x i ) = p i , i = 1 , 2 , … , n P(X=x_i)=p_i, i=1,2,\dots,n P(X=xi)=pi,i=1,2,…,n
则随机变量X的熵定义为
H
(
X
)
=
−
∑
i
=
1
n
p
i
l
o
g
p
i
H(X)=-\sum_{i=1}^n p_ilog p_i
H(X)=−i=1∑npilogpi
(
∫
f
(
x
)
log
f
(
x
)
d
x
)
\left(\int f(x)\log f(x)dx\right)
(∫f(x)logf(x)dx)
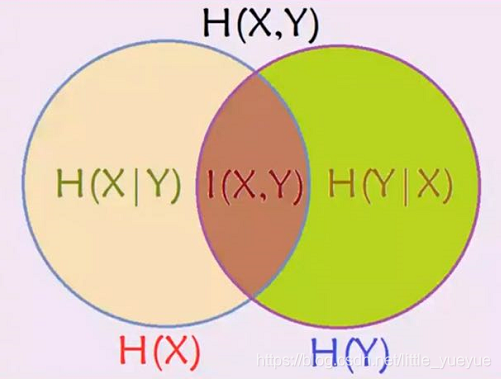
条件熵
H
(
Y
∣
X
)
=
H
(
X
,
Y
)
–
H
(
X
)
H(Y|X)=H(X,Y)–H(X)
H(Y∣X)=H(X,Y)–H(X)
H
(
X
,
Y
)
H(X,Y)
H(X,Y)发生所包含的熵,减去
X
X
X单独发生包含的熵:在
X
X
X发生的前提下,
Y
Y
Y发生“新”带来的熵
H ( Y ∣ X ) = H ( X , Y ) − H ( X ) = − ∑ x , y p ( x , y ) log p ( x , y ) + ∑ x p ( x ) log p ( x ) = − ∑ x , y p ( x , y ) log p ( x , y ) + ∑ x ( ∑ y p ( x , y ) ) log p ( x ) = − ∑ x , y p ( x , y ) log p ( x , y ) + ∑ x , y p ( x , y ) log p ( x ) = − ∑ x , y p ( x , y ) log p ( x , y ) p ( x ) = − ∑ x , y p ( x , y ) log p ( y ∣ x ) = − ∑ x ∑ y p ( x , y ) log p ( y ∣ x ) = − ∑ x ∑ y p ( x ) p ( y ∣ x ) log p ( y ∣ x ) = − ∑ x p ( x ) ∑ y p ( y ∣ x ) log p ( y ∣ x ) = ∑ x p ( x ) ( − ∑ y p ( y ∣ x ) log p ( y ∣ x ) ) = ∑ x p ( x ) H ( Y ∣ X = x ) = E p ( x ) [ H ( Y ∣ X = x ) ] \begin{aligned} H(Y|X)&=H(X, Y)-H(X) \\ &=-\sum_{x, y} p(x, y) \log p(x, y)+\sum_{x} p(x) \log p(x) \\ &=-\sum_{x, y} p(x, y) \log p(x, y)+\sum_{x}\left(\sum_{y} p(x, y)\right) \log p(x) \\ &=-\sum_{x, y} p(x, y) \log p(x, y)+\sum_{x, y} p(x, y) \log p(x) \\ &=-\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x)} \\ &\bm{=-\sum_{x, y} p(x, y) \log p(y \mid x)}\\ &=-\sum_{x} \sum_{y} p(x, y) \log p(y \mid x) \\ &=-\sum_{x} \sum_{y} p(x) p(y \mid x) \log p(y \mid x) \\ &=-\sum_{x} p(x) \sum_{y} p(y \mid x) \log p(y \mid x) \\ &=\sum_{x} p(x)\left(-\sum_{y} p(y \mid x) \log p(y \mid x)\right) \\ &=\sum_{x} p(x) H(Y \mid X=x)\\ &\bm{=E_{p(x)}[H(Y \mid X=x)]} \end{aligned} H(Y∣X)=H(X,Y)−H(X)=−x,y∑p(x,y)logp(x,y)+x∑p(x)logp(x)=−x,y∑p(x,y)logp(x,y)+x∑(y∑p(x,y))logp(x)=−x,y∑p(x,y)logp(x,y)+x,y∑p(x,y)logp(x)=−x,y∑p(x,y)logp(x)p(x,y)=−x,y∑p(x,y)logp(y∣x)=−x∑y∑p(x,y)logp(y∣x)=−x∑y∑p(x)p(y∣x)logp(y∣x)=−x∑p(x)y∑p(y∣x)logp(y∣x)=x∑p(x)(−y∑p(y∣x)logp(y∣x))=x∑p(x)H(Y∣X=x)=Ep(x)[H(Y∣X=x)]
相对熵(KL散度)
p
(
x
)
,
q
(
x
)
p(x),q(x)
p(x),q(x)是X的两个概率分布,则
p
(
x
)
p(x)
p(x)对
q
(
x
)
q(x)
q(x)的相对熵是
D
(
p
∣
∣
q
)
=
∑
x
p
(
x
)
log
p
(
x
)
q
(
x
)
=
E
p
(
x
)
log
p
(
x
)
q
(
x
)
.
D(p||q)=\sum_x p(x)\log \frac{p(x)}{q(x)}=E_{p(x)}\log \frac{p(x)}{q(x)}.
D(p∣∣q)=x∑p(x)logq(x)p(x)=Ep(x)logq(x)p(x).
- 一般 D ( p ∣ ∣ q ) ≠ D ( q ∣ ∣ p ) D(p||q)\neq D(q||p) D(p∣∣q)=D(q∣∣p)
- 若使用 K L ( q ∣ ∣ p ) KL(q||p) KL(q∣∣p),为了距离最小, p ( x ) p(x) p(x)为零时, q ( x ) q(x) q(x)也为0
- 若使用 K L ( p ∣ ∣ q ) KL(p||q) KL(p∣∣q),为了距离最小, p ( x ) p(x) p(x)不为零时, q ( x ) q(x) q(x)也不为0
互信息
两个随机变量
X
,
Y
X,Y
X,Y的互信息,定义为
X
,
Y
X,Y
X,Y的联合分布和独立分布乘积的相对熵。
I
(
X
,
Y
)
=
D
(
P
(
X
,
Y
)
∣
∣
P
(
X
)
P
(
Y
)
)
I(X,Y)=D(P(X,Y)||P(X)P(Y))
I(X,Y)=D(P(X,Y)∣∣P(X)P(Y))
I
(
X
,
Y
)
=
∑
x
,
y
p
(
x
,
y
)
log
p
(
x
,
y
)
p
(
x
)
p
(
y
)
I(X,Y)=\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x)p(y)}
I(X,Y)=x,y∑p(x,y)logp(x)p(y)p(x,y)
若
X
,
Y
X,Y
X,Y独立,则
I
(
X
,
Y
)
=
0
I(X,Y)=0
I(X,Y)=0
H
(
Y
)
−
I
(
X
,
Y
)
=
−
∑
y
p
(
y
)
log
p
(
y
)
−
∑
x
,
y
p
(
x
,
y
)
log
p
(
x
,
y
)
p
(
x
)
p
(
y
)
=
−
∑
y
(
∑
x
p
(
x
,
y
)
)
log
p
(
y
)
−
∑
x
,
y
p
(
x
,
y
)
log
p
(
x
,
y
)
p
(
x
)
p
(
y
)
=
−
∑
x
,
y
p
(
x
,
y
)
log
p
(
y
)
−
∑
x
,
y
p
(
x
,
y
)
log
p
(
x
,
y
)
p
(
x
)
p
(
y
)
=
−
∑
x
,
y
p
(
x
,
y
)
log
p
(
x
,
y
)
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
log
p
(
y
∣
x
)
=
H
(
Y
∣
X
)
\begin{aligned} H(Y)-I(X, Y) &=-\sum_{y} p(y) \log p(y)-\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)} \\ &=-\sum_{y}\left(\sum_{x} p(x, y)\right) \log p(y)-\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)} \\ &=-\sum_{x, y} p(x, y) \log p(y)-\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)} \\ &=-\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x)} \\ &=-\sum_{x, y} p(x, y) \log p(y \mid x) \\ &=H(Y \mid X) \end{aligned}
H(Y)−I(X,Y)=−y∑p(y)logp(y)−x,y∑p(x,y)logp(x)p(y)p(x,y)=−y∑(x∑p(x,y))logp(y)−x,y∑p(x,y)logp(x)p(y)p(x,y)=−x,y∑p(x,y)logp(y)−x,y∑p(x,y)logp(x)p(y)p(x,y)=−x,y∑p(x,y)logp(x)p(x,y)=−x,y∑p(x,y)logp(y∣x)=H(Y∣X)
熵的关系
- H ( Y ∣ X ) = H ( X , Y ) − H ( X ) H(Y|X)=H(X, Y)-H(X) H(Y∣X)=H(X,Y)−H(X)
- H ( Y ∣ X ) = H ( Y ) − I ( X , Y ) H(Y|X)=H(Y)-I(X, Y) H(Y∣X)=H(Y)−I(X,Y),可得 I ( X , Y ) = H ( Y ) − H ( Y ∣ X ) I(X, Y)=H(Y)-H(Y|X) I(X,Y)=H(Y)−H(Y∣X)
- 对偶式
H ( X ∣ Y ) = H ( X , Y ) − H ( Y ) H(X|Y)=H(X, Y)-H(Y) H(X∣Y)=H(X,Y)−H(Y), H ( X ∣ Y ) = H ( X ) − I ( X , Y ) H(X|Y)=H(X)-I(X, Y) H(X∣Y)=H(X)−I(X,Y) - I ( X , Y ) = H ( X ) + H ( Y ) − H ( X , Y ) I(X, Y)=H(X)+H(Y)-H(X,Y) I(X,Y)=H(X)+H(Y)−H(X,Y)
- H ( Y ∣ X ) ≤ H ( X ) , H ( X ∣ Y ) ≤ H ( Y ) H(Y|X)\le H(X),H(X|Y)\le H(Y) H(Y∣X)≤H(X),H(X∣Y)≤H(Y)
-
I
(
X
,
Y
)
=
H
(
X
)
+
H
(
Y
)
−
H
(
X
,
Y
)
I(X, Y)=H(X)+H(Y)-H(X, Y)
I(X,Y)=H(X)+H(Y)−H(X,Y)
I ( X , Y ) = H ( X ) + H ( Y ) − H ( X , Y ) = ( − ∑ x p ( x ) log p ( x ) ) + ( − ∑ y p ( y ) log p ( y ) ) − ( − ∑ x , y p ( x , y ) log p ( x , y ) ) = ( − ∑ x ( ∑ y p ( x , y ) ) log p ( x ) ) + ( − ∑ y ( ∑ x p ( x , y ) ) log p ( y ) ) + ∑ x , y p ( x , y ) log p ( x , y ) = − ∑ x , y p ( x , y ) log p ( x ) − ∑ x , y p ( x , y ) log p ( y ) + ∑ x , y p ( x , y ) log p ( x , y ) = ∑ x , y p ( x , y ) ( log p ( x , y ) − log p ( x ) − log p ( y ) ) = ∑ x , y p ( x , y ) ( log p ( x , y ) p ( x ) p ( y ) ) \begin{aligned} I(X, Y)&=H(X)+H(Y)-H(X, Y) \\ &=\left(-\sum_{x} p(x) \log p(x)\right)+\left(-\sum_{y} p(y) \log p(y)\right)-\left(-\sum_{x, y} p(x, y) \log p(x, y)\right) \\ &=\left(-\sum_{x}\left(\sum_{y} p(x, y)\right) \log p(x)\right)+\left(-\sum_{y}\left(\sum_{x} p(x, y)\right) \log p(y)\right)+\sum_{x, y} p(x, y) \log p(x, y) \\ &=-\sum_{x, y} p(x, y) \log p(x)-\sum_{x, y} p(x, y) \log p(y)+\sum_{x, y} p(x, y) \log p(x, y) \\ &=\sum_{x, y} p(x, y)(\log p(x, y)-\log p(x)-\log p(y)) \\ &=\sum_{x, y} p(x, y)\left(\log \frac{p(x, y)}{p(x) p(y)}\right) \end{aligned} I(X,Y)=H(X)+H(Y)−H(X,Y)=(−x∑p(x)logp(x))+(−y∑p(y)logp(y))−(−x,y∑p(x,y)logp(x,y))=(−x∑(y∑p(x,y))logp(x))+(−y∑(x∑p(x,y))logp(y))+x,y∑p(x,y)logp(x,y)=−x,y∑p(x,y)logp(x)−x,y∑p(x,y)logp(y)+x,y∑p(x,y)logp(x,y)=x,y∑p(x,y)(logp(x,y)−logp(x)−logp(y))=x,y∑p(x,y)(logp(x)p(y)p(x,y))
决策树
决策树学习采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为零,此时每个叶节点中的实例都属于同一类。
决策树生成算法如下:
- ID3 (Iterative Dichotomiser)
信息增益最大化,即 I ( X , Y ) = H ( Y ) − H ( Y ∣ X ) I(X, Y)=H(Y)-H(Y|X) I(X,Y)=H(Y)−H(Y∣X)最大(互信息最大,表明两个特征越相关,据此我们可用树模型对特征排序) - C4.5
- CART(Classification And Regression Tree)
ID3
- 信息增益:得知特征A的信息而使得类X的信息的不确定性减少的程度。
- 当熵和条件熵中的概率由数据估计得到时,所对应的熵和条件熵分别称为经验熵和经验条件熵。
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log ∣ C k ∣ ∣ D ∣ H(D)=-\sum_{k=1}^{K} \frac{\left|C_{k}\right|}{|D|} \log \frac{\left|C_{k}\right|}{|D|} H(D)=−k=1∑K∣D∣∣Ck∣log∣D∣∣Ck∣
H ( D ∣ A ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ k = 1 K ∣ D i k ∣ ∣ D i ∣ log ∣ D i k ∣ ∣ D i ∣ H(D|A)=-\sum_{i=1}^n \frac{|D_i|}{|D|} H(D_i)=-\sum_{i=1}^n \frac{|D_i|}{|D|}\sum_{k=1}^K \frac{|D_{ik}|}{|D_i|} \log \frac{|D_{ik}|}{|D_i|} H(D∣A)=−i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log∣Di∣∣Dik∣ - 特征 A A A 对训练数据集 D D D 的信息增益 g ( D , A ) g(D,A) g(D,A),定义为集合 D D D 的经验熵 H ( D ) H(D) H(D) 与特征 A A A 给定条件下 D D D 的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A) 之差 g ( D , A ) = H ( D ) – H ( D ∣ A ) g(D,A)=H(D)–H(D|A) g(D,A)=H(D)–H(D∣A)即为训练数据集D和特征A的互信息。( I ( X , Y ) = H ( Y ) − H ( Y ∣ X ) I(X, Y)=H(Y)-H(Y|X) I(X,Y)=H(Y)−H(Y∣X))
- 步骤
step1:计算特征A对数据集D的经验条件熵H(D|A)
step2:计算特征A的信息增益:g(D,A)=H(D)–H(D|A)
step3:遍历所有特征,选择信息增益最大的特征作为当前的分裂特征
信息增益率
g r ( D , A ) = g ( D , A ) / H ( A ) g_{\mathrm{r}}(\mathrm{D}, \mathrm{A})=\mathrm{g}(\mathrm{D}, \mathrm{A}) / \mathrm{H}(\mathrm{A}) gr(D,A)=g(D,A)/H(A)
Gini 系数:
Gini
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
=
1
−
∑
k
=
1
K
(
∣
C
k
∣
∣
D
∣
)
2
\begin{aligned} \operatorname{Gini}(p)&=\sum_{k=1}^{K} p_{k}\left(1-p_{k}\right)\\ &=1-\sum_{k=1}^{K} p_{k}^{2} \\ &=1-\sum_{k=1}^{K}\left(\frac{\left|C_{k}\right|}{|D|}\right)^{2} \end{aligned}
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2=1−k=1∑K(∣D∣∣Ck∣)2
(将
f
(
x
)
=
−
log
x
f(x)=-\log x
f(x)=−logx在
x
=
1
x=1
x=1处展开,得到
f
(
x
)
=
1
−
x
f(x)=1-x
f(x)=1−x带入
H
(
X
)
=
−
∑
i
=
1
n
p
i
l
o
g
p
i
≈
−
∑
i
=
1
n
p
i
(
1
−
p
i
)
,
H(X)=-\sum_{i=1}^n p_ilog p_i \approx -\sum_{i=1}^n p_i(1-p_i),
H(X)=−i=1∑npilogpi≈−i=1∑npi(1−pi),从而Gini系数可以作为熵的近似)
分类决策树评价函数
- 各叶结点包含的样本数目不同,可使用样本数加权求熵和作为评价函数
C ( T ) = ∑ t ∈ l e a f N t h ( t ) C(T)=\sum_{t\in leaf} N_t h(t) C(T)=t∈leaf∑Nth(t) - 对所有叶结点的熵求和,该值越小说明对样本的分类越精确。
- 由于该评价函数越小越好,所以,可以称之为“损失函数”。
决策树做回归
用特征
j
j
j对某个节点在
s
s
s处进行分割,小于
s
s
s的分入
R
1
R_{1}
R1子节点,大于
s
s
s的分入
R
2
R_{2}
R2子节点,两个子结点的均值分别为
c
^
1
=
1
N
1
∑
x
i
∈
R
1
(
j
,
s
)
y
i
,
c
^
2
=
1
N
2
∑
x
i
∈
R
2
(
j
,
s
)
y
i
\hat{c}_{1}=\frac{1}{N_{1}} \sum_{x_{i} \in R_{1}(j, s)} y_{i} ,\qquad \hat{c}_{2}=\frac{1}{N_{2}} \sum_{x_{i} \in R_{2}(j, s)} y_{i}
c^1=N11xi∈R1(j,s)∑yi,c^2=N21xi∈R2(j,s)∑yi
计算该过程的损失函数
L
(
j
,
s
)
L(j, s)
L(j,s)为
L
(
j
,
s
)
=
∑
x
i
∈
R
1
(
j
,
s
)
(
y
i
−
c
^
1
)
2
+
∑
x
i
∈
R
2
(
j
,
s
)
(
y
i
−
c
^
2
)
2
\begin{aligned} L(j, s)=\sum_{x_{i} \in R_{1}(j, s)}\left(y_{i}-\hat{c}_{1}\right)^{2}+\sum_{x_{i} \in R_{2}(j, s)}\left(y_{i}-\hat{c}_{2}\right)^{2} \end{aligned}
L(j,s)=xi∈R1(j,s)∑(yi−c^1)2+xi∈R2(j,s)∑(yi−c^2)2
对于阈值
s
s
s的选择,挑选方式如下
- 将特征 j j j的最大值 m a x j max_j maxj和 最小值 m i n j min_j minj,等分来挑选
- 通过总共的 N N N个样本,在 N − 1 N-1 N−1个值中挑选
- 在特征 j j j的最大值 m a x j max_j maxj和 最小值 m i n j min_j minj之间多次随机挑选(效果较好)
决策树的过拟合
剪枝
- 原来的损失函数 C ( T ) = ∑ t ∈ l e a f N t H ( t ) C(T)=\sum_{t\in leaf} N_t H(t) C(T)=∑t∈leafNtH(t),修正为 C α ( T ) = ∑ t ∈ l e a f N t H ( t ) + α ∣ T l e a f ∣ C_{\alpha}(T)=\sum_{t\in leaf} N_t H(t)+_{\alpha}|T_{leaf}| Cα(T)=∑t∈leafNtH(t)+α∣Tleaf∣
- 假定当前对以
r
r
r为根的子树剪枝,剪枝后, 只保留
r
r
r本身而删掉所有的叶子。
剪枝后的损夫函数: C α ( r ) = C ( r ) + α C_{\alpha}(r)=C(r)+\alpha Cα(r)=C(r)+α
剪枝前的损失函数 : C α ( R ) = C ( R ) + α ⋅ ∣ R leaf ∣ : C_{\alpha}(R)=C(R)+\alpha \cdot |R_{\text {leaf }}| :Cα(R)=C(R)+α⋅∣Rleaf ∣
即可求得剪枝系数 α \alpha α: α = C ( r ) − C ( R ) ∣ R leaf ∣ − 1 \alpha=\frac{C(r)-C(R)}{|R_{\text {leaf }}|-1} α=∣Rleaf ∣−1C(r)−C(R) - 对于给定的决策树
T
0
T_0
T0剪枝步骤:
step1:计算所有内部节点的剪枝系数;
step2:查找最小剪枝系数的结点,剪枝得决策树 T k T_k Tk;
step3:重复以上步骤,直到决策树 T k T_k Tk只有1个结点;
step4:得到决策树序列 T 0 , T 1 , T 2 , … , T k T_0,T_1,T_2, \dots ,T_k T0,T1,T2,…,Tk
step5:可以使用评价函数 C ( T ) = ∑ t ∈ l e a f N t H ( t ) C(T)=\sum_{t\in leaf} N_t H(t) C(T)=∑t∈leafNtH(t),通过验证样本集选择最优子树。
随机森林
用树的数量来消除单棵树过拟合带来的问题。
(我们认为分类错误是噪音带来的,而噪音是偶然的,多棵决策树发生的概率小)
随机森林
Bagging的策略
step1. 从总共的
N
N
N样本集中重采样(有放回的)选出
N
N
N个样本。
step2. 在所有属性上,对这n个样本建立分类器(
I
D
3
、
C
4.5
、
C
A
R
T
、
S
V
M
、
L
o
g
i
s
t
i
c
ID3、C4.5、CART、SVM、Logistic
ID3、C4.5、CART、SVM、Logistic回归等,弱分类器效果往往更好)
step3. 重复以上两步m次,即获得了m个分类器
step4. 将数据放在这m个分类器上,最后根据这m个分类器的投票结果,决定数据属于哪一类
note:
- 一次采样中没有被抽到的概率为
1
−
1
N
1-\frac{1}{N}
1−N1,
N
N
N次都没选中的占比为
(
1
−
1
N
)
N
=
1
e
≈
36.8
%
,
(1-\frac{1}{N})^N=\frac{1}{e} \approx 36.8\%,
(1−N1)N=e1≈36.8%,称这部分数据为袋外数据OOB(out of bag),可用于取代测试集计算误差。
同通过设置参数oob_score=True,模型用model.oob_score_可以得到袋外数据上的准确率得分 - 采样不一定要也采 N N N个,可以比样本集少
- 得到的模型参数是无偏的
随机森林做法
随机森林在bagging基础上做了修改。
step1:从样本集中用Bootstrap采样选出
n
n
n个样本;
step2:从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树;
step3:重复以上两步
m
m
m次,即建立了
m
m
m棵
C
A
R
T
CART
CART决策树:
step4:这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类
RF计算样本间相似度
- 原理:若两样本同时出现在相同叶结点的次数越多,则二者越相似。
- 算法过程:
step1:记样本个数为 N N N,初始化 N × N 的 N×N的 N×N的零矩阵 S S S, S [ i , j ] S[i,j] S[i,j]表示样本i和样本j的相似度。
step2:对于 m m m棵决策树形成的随机森林,遍历所有决策树的所有叶子结点:
记该叶结点包含的样本为 s a m p l e [ 1 , 2 , … , k ] sample[1,2,…,k] sample[1,2,…,k],则 S [ i ] [ j ] S[i][j] S[i][j]累加1,即样本 i , j ∈ s a m p l e [ 1 , 2 , … k ] i,j \in sample[1,2,…k] i,j∈sample[1,2,…k]则次数增加1次。
step3:遍历结束,则 S S S为样本间相似度矩阵。
RF计算特征重要度
随机森林是常用的衡量特征重要性的方法。指标可选为:
- selection frequency 特征经过结点的数目
- gini importance 经过结点的gini系数下降程度
- permutation importance 随机替换一列数据,重新建立决策树,计算新模型的正确率变化,从而考虑这一列特征的重要性。
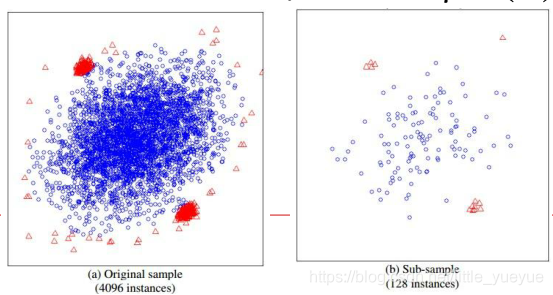
RF做异常检测
- i T R E E iTREE iTREE:随机选择特征、随机选择分割点,生成一定深度的决策树iTree,再由这若干颗iTree组成iForest,计 i T r e e iTree iTree中样本 x x x从根到叶子的长度 f ( x ) f(x) f(x),计 i F o r e s t iForest iForest中 f ( x ) f(x) f(x)的总和 F ( x ) F(x) F(x)
- 原理:若样本x为异常值(偏离大多数样本),它应在大多数iTree中很快从根到达叶子,即F(x)较小。
- 在样本很大的情况,一般先做一下降采样,效果会更好
投票机制
简单投票机制:
- 一票否决(一致表决)
- 少数服从多数(有效多数(加权))
- 阈值表决
贝叶斯投票机制
示例:若样本被采样的次数特别少,可用以下公式光滑处理:
W
R
=
v
v
+
m
R
+
v
v
+
m
C
WR=\frac{v}{v+m}R+\frac{v}{v+m}C
WR=v+mvR+v+mvC
WR:加权得分(weightedrating)
R:对该样本的投票的平均得分(Rating)
C:所有样本的平均得分
v:该样本的投票总数
m:所有样本中最低的投票总数 根据总投票人数
样本不均衡的常用处理方法
假定样本数目A类比B类多,且严重不平衡:
- 对A类欠采样Undersampling 如:
随机欠采样 A类分成若干子类,分别与B类进入ML模型 基于聚类的A类分割 - 对B类过采样Oversampling
可避免欠采样造成的信息丢失 ,但同时不可避免地增加 了B类中的噪音,效果一般不如对A欠采样。 - B类数据合成Synthetic Data Generation 如:
随机插值得到新样本 SMOTE(Synthetic Minority Over-sampling Technique) - 代价敏感学习Cost Sensitive Learning
一般降低A类权值,提高B类权值


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









