









我发现这个问题经常在深度学习模型训练或部署中遇到,针对多GPU分布式训练时,这关系学习率的设置问题,而学习率非常影响模型的优化过程,这次就让我碰到了,而且就是因为CUDA_VISIBLE_DEVICES生效与不生效导致学习率偏差,从而最终导致准确率相差两个百分点。
1、如何发现问题的?
我训练有个习惯是会保存训练的tensorboard。两次训练参数一致,分两类,唯一不同就是后面一次增加了7w的数据,其他参数均是一模一样,如下:
但是最终的准确率却相差两个百分点,我觉得虽然深度学习模型训练虽然有很多的随机性,但不至于影响这么大。于是打开了tensorboard观察两者的训练曲线区别。这就看到了两则学习率变换完全不一样。
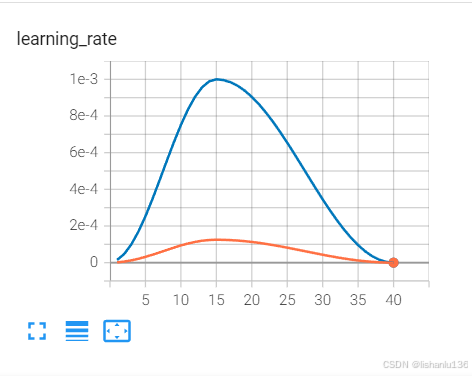
明明参数设置一样,为什么最终优化器出来的学习率却不一样。于是看代码,我代码是这样写的:
import os
import sys
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
from torch.utils.tensorboard import SummaryWriter
from utils.distributed_utils import init_distributed_mode, dist, cleanup # 我的utils里面写了分布式初始化相关函数
from utils.distributed_utils import reduce_value, is_main_process
from utils.utils_logging import init_logging
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "6" # 我这里想只用第7张显卡来训练
os.environ['NCCL_SOCKET_IFNAME'] = 'lo'
args.lr *= args.world_size # 学习率要根据并行GPU的数量进行倍增
if rank == 0:
tb_writer = SummaryWriter(log_dir=args.save_dir)
dataloader = xxxxx
model = resnet18(pretrained=False, num_classes=num_classes)
optimizer = optim.AdamW(model.parameters(), lr=args.lr/torch.cuda.device_count(), betas=(0.9, 0.999), eps=1e-9, weight_decay=args.weight_decay)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=args.lr/torch.cuda.device_count(), steps_per_epoch=len(train_loader), epochs=args.epochs, last_epoch=last_epoch,
pct_start=args.warmup_epochs/args.epochs, div_factor=250, final_div_factor=200)
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(tqdm(dataloader['train'])):
xxxx
# eval
# save models and write to tensorboard
tags = ["train/accuracy", "train/loss", "val/accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], np.mean(train_acc), epoch)
tb_writer.add_scalar(tags[1], mean_loss, epoch)
tb_writer.add_scalar(tags[2], float(Total_Accuracy), epoch)
tb_writer.add_scalar(tags[3], optimizer.param_groups[0]["lr"], epoch)
可以看到,我运行训练sh,传入的参数lr会经过乘以world_size,然后输入优化器optimizer和scheduler都会除以torch.cuda.device_count(),所以差异必定是这里引起的。两次唯一不同就是我在运行sh脚本时是否在终端指定了CUDA_VISIBLE_DEVICES;前一次训练(tensorboard橙色曲线),在终端没有加;而蓝色曲线,由于不加会报错显存不足,分布式初始化失败,我就在运行sh训练脚本的时候加了CUDA_VISIBLE_DEVICES指定GPU序号运行。
2、验证猜想问题点
通过添加print打印.cuda.device_count()和world_size的值
当不在终端命令行加CUDA_VISIBLE_DEVICES指定GPU训练时(tensorboard橙色曲线):

当在终端命令行加CUDA_VISIBLE_DEVICES指定GPU训练时(tensorboard蓝色曲线):

结合两者打印消息可以证明,文件中用CUDA_VISIBLE_DEVICES指定GPU训练没有起作用。
3、修改,如何让CUDA_VISIBLE_DEVICES在文件中起作用
文件中通过CUDA_VISIBLE_DEVICES指定GPU训练失效的原因通常是因为设置和使用顺序搞反了导致的;具体如下:
-
环境变量设置时机:在文件中设置CUDA_VISIBLE_DEVICES时,如果设置的位置不正确,可能会导致环境变量无效。正确的做法是在导入任何与CUDA相关的模块之前设置环境变量。例如,应该在import torch之前设置os.environ[‘CUDA_VISIBLE_DEVICES’]。
-
导入顺序问题:如果在文件中导入了一个包含import torch的模块,且导入该模块在os.environ[‘CUDA_VISIBLE_DEVICES’]设置之前,那么在该模块导入时,os.environ[‘CUDA_VISIBLE_DEVICES’]的设置将不会生效。这是因为Python在执行文件时会优先导入其他包中的模块,如果在这些模块中已经导入了torch,那么在主文件中设置的CUDA_VISIBLE_DEVICES将无法生效。
我在程序中通过os.environ["CUDA_VISIBLE_DEVICES"] = "6"设置环境变量,从我列出来的程序可以看出,应该是设置环境变量和导入torch的顺序导致的,即我先import torch,后使用CUDA_VISIBLE_DEVICES设置显卡,所以这个设置没起作用。
终端设置的优势: 在终端设置环境变量时,通常会在启动一个新的shell会话时生效,这样确保了所有后续的命令都在新的环境变量设置下执行。而在文件中设置环境变量,可能会因为导入顺序或其他脚本的执行顺序问题而无法生效。
解决CUDA_VISIBLE_DEVICES在文件中设置不起作用的问题的方法:
- 确保设置顺序:在文件中设置os.environ[‘CUDA_VISIBLE_DEVICES’]时,确保在导入任何CUDA相关模块之前进行设置。例如:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
import torch
print(torch.cuda.device_count())
- 使用bash脚本:可以通过bash脚本在终端中设置环境变量,然后启动Python脚本。例如:
export CUDA_VISIBLE_DEVICES=0,1
python train.py

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









